爬虫常见面试
一.项目问题:
1.你写爬虫的时候都遇到过什么反爬虫措施,你最终是怎样解决的
- 通过headers反爬虫:解决策略,伪造headers
- 基于用户行为反爬虫:动态变化去爬取数据,模拟普通用户的行为, 使用IP代理池爬取或者降低抓取频率,或 通过动态更改代理ip来反爬虫
- 基于动态页面的反爬虫:跟踪服务器发送的ajax请求,模拟ajax请求,selnium
和phtamjs。或 使用selenium + phantomjs 进行抓取抓取动态数据,或者找到动态数据加载的json页面。 - 验证码 :使用打码平台识别验证码
- 数据加密:对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
2.你写爬虫的时候 使用的什么框架 选择这个框架的原因是什么?
scrapy。
优势:
-
可以实现高并发的爬取数据, 注意使用代理;
-
提供了一个爬虫任务管理界面, 可以实现爬虫的停止,启动,调试,支持定时爬取任务;
-
代码简洁
劣势:
-
1.可扩展性不强。
-
2.整体上来说: 一些结构性很强的, 定制性不高, 不需要太多自定义功能时用pyspider即可, 一些定制性高的,需要自定义一 些 功能时则使用Scrapy。
2.scrapy框架专题部分(很多面试都会涉及到这部分)
(1)请简要介绍下scrapy框架。
scrapy 是一个快速(fast)、高层次(high-level)的基于 python 的 web 爬虫构架,
用于抓取web站点并从页面中提取结构化的数据。scrapy 使用了 Twisted异步网络库来
处理网络通讯
(2)为什么要使用scrapy框架?scrapy框架有哪些优点?
- 它更容易构建大规模的抓取项目
- 它异步处理请求,速度非常快
- 它可以使用自动调节机制自动调整爬行速度
(3)scrapy框架有哪几个组件/模块?简单说一下工作流程。
-
Scrapy Engine:
这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?) -
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy
Engine(引擎)来请求时,交给引擎。 -
Downloader(下载器):负责下载Scrapy
Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy
Engine(引擎),由引擎交给Spiders来处理, -
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
-
Item
Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的) -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
-
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)

工作流程:
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
以上就是Scrapy整个流程了。
官方语言版本:
流程
1.引擎打开一个域名,蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
2.引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
3.引擎从调度那获取接下来进行爬取的页面。
4.调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
5.当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
6.引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
7.蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
8.引擎将抓取到的项目项目管道,并向调度发送请求。
系统重复第二步后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系
4.scrapy的去重原理(指纹去重到底是什么原理)
在这里插入图片描述
- 需要将dont_filter设置为False开启去重,默认是False;
- 对于每一个url的请求,调度器都会根据请求的相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中得指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有,就将这个Request对象放入队列中,等待被调度。
5.scrapy中间件有几种类,你用过哪些中间件*
scrapy的中间件理论上有三种:
-
Schduler Middleware,
-
Spider Middleware,
-
Downloader Middleware),
-
在应用上一般有以下两种:
1.爬虫中间件Spider Middleware
主要功能是在爬虫运行过程中进行一些处理.
2.下载器中间件Downloader Middleware
主要功能在请求到网页后,页面被下载时进行一些处理.
使用
1.Spider Middleware有以下几个函数被管理:
process_spider_input 接收一个response对象并处理,位置是Downloader–>process_spider_input–>Spiders(Downloader和Spiders是scrapy官方结构图中的组件)
process_spider_exception spider出现的异常时被调用
process_spider_output 当Spider处理response返回result时,该方法被调用process_start_requests 当spider发出请求时,被调用
位置是Spiders–>process_start_requests–>Scrapy Engine(Scrapy Engine是scrapy官方结构图中的组件)
2.Downloader Middleware有以下几个函数被管理
- process_request request通过下载中间件时,该方法被调
- process_response 下载结果经过中间件时被此方法处理
- process_exception 下载过程中出现异常时被调用
6.scrapy中间件再哪里起的作用
-
1.爬虫中间件Spider Middleware:主要功能是在爬虫运行过程中进行一些处理.爬虫发起请求request的时候调用,列如更换修改代理ip,修改UA,
-
2.下载器中间件Downloader Middleware:主要功能在请求到网页后,页面被下载时进行一些处理.浏览器返回响应response的时候调用,无效的数据,特殊情况进行重试
三.代理问题:
1.为什么会用到代理
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。所以我们需要设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
2.代理怎么使用(具体代码, 请求在什么时候添加的代理)
1,可以使用urllib2中的ProxyHandler来设置代理ip
1 import urllib2
2
3 # 构建了两个代理Handler,一个有代理IP,一个没有代理IP
4 httpproxy_handler = urllib2.ProxyHandler({"http" : "124.88.67.81:80"})
5 nullproxy_handler = urllib2.ProxyHandler({})
6 #定义一个代理开关
7 proxySwitch = True
8 # 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
9 # 根据代理开关是否打开,使用不同的代理模式
10 if proxySwitch:
11 opener = urllib2.build_opener(httpproxy_handler)
12 else:
13 opener = urllib2.build_opener(nullproxy_handler)
14
15 request = urllib2.Request("http://www.baidu.com/")
16
17 # 使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
18 response = opener.open(request)
19
20 # 就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
21 # urllib2.install_opener(opener)
22 # response = urlopen(request)
23
24 print response.read()
2,使用requets代理
1 import requests
2
3 # 根据协议类型,选择不同的代理
4 proxies = {
5 "http": "http://12.34.56.79:9527",
6 "https": "http://12.34.56.79:9527",
7 }
8
9 response = requests.get("http://www.baidu.com", proxies = proxies)
10 print response.text
3.代理失效了怎么处理
事先用检测代码检测可用的代理,每隔一段时间更换一次代理,如果出现302等状态码,
则立即更换下一个可用的IP。
1 1、将代理IP及其协议载入ProxyHandler赋给一个opener_support变量;
2、将opener_support载入build_opener方法,创建opener;
3、安装opener。具体代码如下:from urllib import requestdef ProxySpider
(url, proxy_ip, header):opener_support =
request.ProxyHandler({'http': proxy_ip})
opener = request.build_opener(opener_support)
request.install_opener(opener) req =
request.Request(url, headers=header)rsp =
request.urlopen(req).read()return rsp
四.验证码处理:
1.登陆验证码处理
图片验证码:先将验证码图片下载到本地,然后使用云打码识别;
滑动验证码:使用selenium模拟人工拖动,对比验证图片的像素差异,
找到滑动的位置然后获取它的location和size,然后 top,bottom,left,
right = location['y'] ,location['y']+size['height']+ location['x'] +
size['width'] ,然后截图,最后抠图填入这四个位置就行。
**2.爬取速度过快出现的验证码处理
设置setting.py中的DOWNLOAD_DELAY,降低爬取速度;
用xpath获取验证码关键字,当出现验证码时,识别验证码后再继续运行。
3.如何用机器识别验证码**
对接打码平台
- 对携带验证码的页面数据进行抓取
- 将页面中的验证码进行解析, 将验证码图片下载到本地
- 将验证码图片提交给打码平台进行识别, 返回识别后的结果
云打码平台使用:
- 在官网中进行普通用户和开发者用户注册
- 登录开发者用户:
a) 示例代码下载:开发文档 --> 调用示例及最新DLL --> PythonHTTP示例下载
b) 创建一个软件:我的软件 --> 添加新的软件(后期会使用该软件的秘钥和id)
使用示例代码中的示例代码对保存本地的验证码进行识别
五.模拟登陆问题:
1.模拟登陆流程
1. 加载浏览器driver; 获取登录页面; 使用css选择器或者xpath找到账号和密码输入框,
并发送账号和密码;
2. 如果出现验证码则需要先识别验证码,在模拟输入验证码或者模拟鼠标拖动;
3. 使用css选择器或者xpath找到登录按钮,使用click模拟点击;
2.cookie如何处理
1. 采用selenium自动登录获取cookie,保存到文件;
2. 读取cookie,比较cookie的有效期,若过期则再次执行步骤1;
3. 在请求其他网页时,填入cookie,实现登录状态的保持;
3.如何处理网站传参加密的情况**
加密的三种情况:
1. 加密+访问次数限制+每个页面相关信息的条目需要点详情进行二次请求;
2. 复杂的加密算法进行参数+时间戳+sig值,后台进行 参数+时间限制;
3. 定时同步cookie+每个界面一个cookie。
破解方法:
1. 使用selenium模拟点击获取详情页面;
2. 获取其相应的api接口,GET接口URL,获取它的json表格内容;
3. 反向分析网页JS加载内容;
六.分布式
1.什么是分布式
需要计算的数据量大,任务多,一台机器搞不定或者效率极低,需要多台机器共同协作(而不是孤立地各做各的,所以需要通信),最后所有机器完成的任务汇总在一起,完成大量任务.
将一个项目拷贝到多台电脑上,同时爬取数据
分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。
记住爬虫的本质是网络请求和数据处理,如何稳定地访问网页拿到数据,如何精准地提取出高质量的数据才是核心问题
2.分布式原理
分布式爬虫主要由主机与从机,我们把自己的核心服务器(主机)称为 master,而把用于跑爬虫程序的机器(从机)称为 slave。
我们首先给爬虫一些start_urls,spider 最先访问 start_urls 里面的 url,再根据我们的 parse 函数,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,只需要在这个starts_urls里面做文章就行了。进一步描述如下:
- master 产生 starts_urls,url 会被封装成 request 放到 redis 中的
spider:requests,总的 scheduler 会从这里分配 request,当这里的 request 分配完后,会继续分配
start_urls 里的 url。 - slave 从 master 的 redis 中取出待抓取的 request,下载完网页之后就把网页的内容发送回 master 的
redis,key 是 spider:items。scrapy 可以通过 settings 来让 spider
爬取结束之后不自动关闭,而是不断的去询问队列里有没有新的 url,如果有新的 url,那么继续获取 url
并进行爬取,所以这一过程将不断循环。 - master 里的 reids 还有一个 key 是 “spider:dupefilter” 用来存储抓取过的 url 的
fingerprint(使用哈希函数将url运算后的结果),防止重复抓取,只要 redis 不清空,就可以进行断点续爬。
scrapy实现分布式抓取简单点来说
- 可以借助scrapy_redis类库来实现。
- 在分布式爬取时,会有master机器和slave机器,其中,master为核心服务器,slave为具体的爬虫服务器。
- 我们在master服务器上搭建一个redis数据库,并将要抓取的url存放到redis数据库中,所有的slave爬虫服务器在抓取的时候从redis数据库中去链接,由于scrapy_redis自身的队列机制,slave获取的url不会相互冲突,然后抓取的结果最后都存储到数据库中。master的redis数据库中还会将抓取过的url的指纹存储起来,用来去重。相关代码在dupefilter.py文件中的request_seen()方法中可以找到。
- 捅过重写scheduler和spider类,实现了调度、spider启动和redis的交互。实现新的dupefilter和queue类,达到了判重和调度容器和redis的交互,因为每个主机上的爬虫进程都访问同一个redis数据库,所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。
3.分布式如何判断爬虫已经停止了
1 spider.getStatus();//获取爬虫状态
2 spider.getStatus().equals(Spider.Status.Init);//运行中
4.分布式的去重原理
分布式去重问题:
Duplication Filter:
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints 就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
总结:
1、最后总结一下scrapy-redis的总体思路:这套组件通过重写scheduler和 spider类,实现了调度、spider启动和redis的交互。
2、实现新的dupefilter和queue类,达到了判重和调度容器和redis 的交互,因为每个主机上的爬虫进程都访问同一个redis数据库, 所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。
3、当spider被初始化时,同时会初始化一个对应的scheduler对象, 这个调度器对象通过读取settings,配置好自己的调度容器queue 和判重工具dupefilter。
4、每当一个spider产出一个request的时候,scrapy引擎会把这个 reuqest递交给这个spider对应的scheduler对象进行调度, scheduler对象通过访问redis对request进行判重,如果不重复就 把他添加进redis中的调度器队列里。当调度条件满足时,scheduler 对象就从redis的调度器队列中取出一个request发送给spider, 让他爬取。
5、当spider爬取的所有暂时可用url之后,scheduler发现这个spider 对应的redis的调度器队列空了,于是触发信号spider_idle, spider收到这个信号之后,直接连接redis读取start_urls池,拿 去新的一批url入口,然后再次重复上边的工作。
七.数据存储和数据库问题:
1.关系型数据库和非关系型数据库的区别
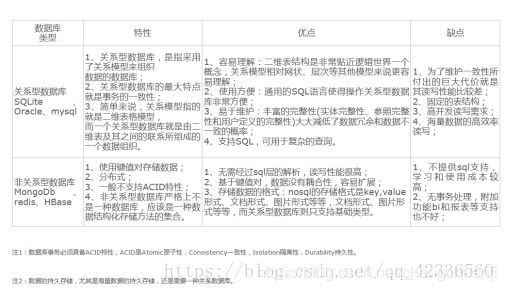
详情请点击:https://blog.csdn.net/hzp666/article/details/79168675
2.爬下来数据你会选择什么存储方式,为什么
Redis基于内存,读写速度快,也可做持久化,但是内存空间有限,当数据量超过内存空间时,需扩充内存,但内存价格贵;
MySQL基于磁盘,读写速度没有Redis快,但是不受空间容量限制,性价比高;
大多数的应用场景是MySQL(主)+Redis(辅),MySQL做为主存储,Redis用于缓存,加快访问速度。需要高性能的地方使用Redis,不需要高性能的地方使用MySQL。存储数据在MySQL和Redis之间做同步;
MongoDB 与 MySQL 的适用场景:
MongoDB 的适用场景为:数据不是特别重要(例如通知,推送这些),数据表结构变化较为频繁,数据量特别大,数据的并发性特别高,数据结构比较特别(例如地图的位置坐标),这些情况下用 MongoDB , 其他情况就还是用 MySQL ,这样组合使用就可以达到最大的效率。
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
3.各种数据库支持的数据类型,和特点
MongoDB
- MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
- 它是一个内存数据库,数据都是放在内存里面的。
- 对数据的操作大部分都在内存中,但 MongoDB 并不是单纯的内存数据库。
- MongoDB 是由 C++ 语言编写的,是一个基于分布式文件存储的开源数据库系统。
- 在高负载的情况下,添加更多的节点,可以保证服务器性能。
- MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
优点:
1.性能优越:快速!在适量级的内存的 MongoDB 的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快,
2.高扩展:第三方支持丰富(这是与其他的 No SQL 相比,MongoDB 也具有的优势)
3.自身的 Failover 机制!
4.弱一致性(最终一致),更能保证用户的访问速度
5.文档结构的存储方式,能够更便捷的获取数据: json 的存储格式
6.支持大容量的存储,内置 GridFS
7.内置 Sharding
8.MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
MongoDB 缺点:
主要是无事物机制!
① MongoDB 不支持事务操作(最主要的缺点)
② MongoDB 占用空间过大
③ MongoDB 没有如 MySQL 那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方
redis
Redis 一个内存数据库,通过 Key-Value 键值对的的方式存储数据。由于 Redis 的数据都存储在内存中,所以访问速度非常快,因此 Redis 大量用于缓存系统,存储热点数据,可以极大的提高网站的响应速度。
1、Redis优点
(1)支持数据的持久化,通过配置可以将内存中的数据保存在磁盘中,Redis 重启以后再将数据加载到内存中;
(2)支持列表,哈希,有序集合等数据结构,极大的扩展了 Redis 用途;
(3)原子操作,Redis 的所有操作都是原子性的,这使得基于 Redis 实现分布式锁非常简单;
(4)支持发布/订阅功能,数据过期功能;
Redis的数据类型
Redis通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
Redis 一个内存数据库,通过 Key-Value 键值对的的方式存储数据。由于 Redis 的数据都存储在内存中,所以访问速度非常快,因此 Redis 大量用于缓存系统,存储热点数据,可以极大的提高网站的响应速度。
1、Redis优点
(1)支持数据的持久化,通过配置可以将内存中的数据保存在磁盘中,Redis 重启以后再将数据加载到内存中;
(2)支持列表,哈希,有序集合等数据结构,极大的扩展了 Redis 用途;
(3)原子操作,Redis 的所有操作都是原子性的,这使得基于 Redis 实现分布式锁非常简单;
(4)支持发布/订阅功能,数据过期功能;
mysql
MySQL是关系型数据库。
MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
系统特性
1. [2] 使用 C和 C++编写,并使用了多种编译器进行测试,保证了源代码的可移植性。
2.支持 AIX、FreeBSD、HP-UX、Linux、Mac OS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris、Windows等多种操作系统。
3.为多种编程语言提供了 API。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby,.NET和 Tcl 等。
4.支持多线程,充分利用 CPU 资源。
5.优化的 SQL查询算法,有效地提高查询速度。
6.既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库而嵌入到其他的软件中。
7.提供多语言支持,常见的编码如中文的 GB 2312、BIG5,日文的 Shift_JIS等都可以用作数据表名和数据列名。
8.提供 TCP/IP、ODBC 和 JDBC等多种数据库连接途径。
9.提供用于管理、检查、优化数据库操作的管理工具。
10.支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
11.支持多种存储引擎。
12.MySQL 是开源的,所以你不需要支付额外的费用。
13.MySQL 使用标准的 SQL数据语言形式。
14.MySQL 对 PHP 有很好的支持,PHP是比较流行的 Web 开发语言。
15.MySQL是可以定制的,采用了 GPL协议,你可以修改源码来开发自己的 MySQL 系统。
16.在线 DDL/更改功能,数据架构支持动态应用程序和开发人员灵活性(5.6新增)
17.复制全局事务标识,可支持自我修复式集群(5.6新增)
18.复制无崩溃从机,可提高可用性(5.6新增)
19.复制多线程从机,可提高性能(5.6新增)
20.3倍更快的性能(5.7 [3] 新增)
21.新的优化器(5.7新增)
22.原生JSON支持(5.7新增)
23.多源复制(5.7新增)
24.GIS的空间扩展 [4] (5.7新增)
优势:
在不同的引擎上有不同 的存储方式。
查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
开源数据库的份额在不断增加,mysql的份额页在持续增长。
缺点:
在海量数据处理的时候效率会显著变慢。
4.是否支持事务…
mongo不支持
redis mysql支持
八.Python基础问题:
1.Python2和Python3的区别,如何实现python2代码迁移到Python3环境
区别:字符串类型、默认字符、print方法、除法的数字类型、导入方式、继承类、元类声明、异常处理、字典、模块合并、部分模块重命名(详情)
代码迁移:python3有个内部工具叫做2to3.py,位置在Python3/tool/script文件夹。
首先CD到这个文件夹,然后调用
py 2to3.py -w f:/xxxx/xxx.py
具体方法:https://blog.csdn.net/xutiantian1412/article/details/79523953
2.Python2和Python3的编码方式有什么差别
在python2中主要有str和unicode两种字符串类型,而到python3中改为了bytes和str,并且一个很重要的分别是,在python2中如果字符串是ascii码的话,str和unicode是可以直接进行连接和比较,但是到python3中就不行了,bytes和str是两个独立的类型。另一个重要的是python2中不管是str还是unicode都可以直接写入文件,而不需要加上它是不是str的类型写入方式,但是在python3中如果是写或者读bytes类型就必需带上’b’.
3.迭代器,生成器,装饰器
生成器:
创建python迭代器的过程虽然强大,但是很多时候使用不方便。生成器是一个简单的方式来完成迭代。简单来说,Python的生成器是一个返回可以迭代对象的函数。
为什么使用生成器
-
更容易使用,代码量较小
-
内存使用更加高效。比如列表是在建立的时候就分配所有的内存空间,而生成器仅仅是需要的时候才使用,更像一个记录
-
代表了一个无限的流。如果我们要读取并使用的内容远远超过内存,但是需要对所有的流中的内容进行处理,那么生成器是一个很好的选择,比如可以让生成器返回当前的处理状态,由于它可以保存状态,那么下一次直接处理即可。
-
流水线生成器
最简单的生成器:
g = (x*x for x in range(10))
for i in g:
print i
函数方法实现稍复杂的生成器:
def fib(max):
n,a,b=0,1,1
while n迭代器概述
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list,tuple,dict,set,str等
一类是generator ,包括生成器和带yeild的generator function
这些可以 直接作用于for循环的对象统称为可迭代对象:Iterable
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
def hs(n):
i=0
while i装饰器:
基本概念:在函数调用前后自动打印日志,又不改变原函数,在代码运行期间动态增加功能的方式称之为“装饰器”。
装饰器的语法已@开头,接下来是装饰器函数的名字和可选的参数,紧跟着装饰器声明的是被修饰的函数和装饰函数的可选参数。
**3大特征:**1,外部函数包含内部函数,2,返回一个内部函数,3,内部函数用到外部函数的变量
import time
def hs(f):#装饰器的函数,f接受被装饰的函数名
def neibu():#装饰内部函数
start=time.time()
f()#调用被装饰的函数
end=time.time()
print(end-start)
return neibu#装饰器返回内部函数,(内部代表的是包装盒)
@hs#@加函数名,代表下面的函数被hs装饰
def jisuan():
print('123456')
jisuan()
4.Python的数据类型
- Number(数字) 包括int,long,float,complex
- String(字符串) 例如:hello,“hello”,hello
- List(列表) 例如:[1,2,3],[1,2,3,[1,2,3],4]
- Dictionary(字典) 例如:{1:“nihao”,2:“hello”}
- Tuple(元组) 例如:(1,2,3,abc)
- Bool(布尔) 包括True、False
九.协议问题:
robots协议是什么?
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
1.http协议,请求由什么组成,每个字段分别有什么用,https和http有什么差距
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成(详情);
请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本;
请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息;
空行,请求头部后面的空行是必须的;
请求数据也叫主体,可以添加任意的其他数据;
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
2.证书问题
https://blog.csdn.net/fangqun663775/article/details/55189107
3.TCP,UDP各种相关问题
https://blog.csdn.net/xiaobangkuaipao/article/details/76793702
十.数据提取问题:
1.主要使用什么样的结构化数据提取方式,可能会写一两个例子
JSON文件
JSON Path
转化为Python类型进行操作(json类)
XML文件
转化为Python类型(xmltodict)
XPath
CSS选择器
正则表达式
详情:https://www.cnblogs.com/miqi1992/p/7967399.html
2.正则的使用
http://tool.oschina.net/uploads/apidocs/jquery/regexp.html
文本、电话号码、邮箱地址
"^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\d{8}KaTeX parse error: Can't use function '\.' in math mode at position 34: …[a-zA-Z0-9_-]+(\̲.̲[a-zA-Z0-9_-]+)…
元字符 含义
. 匹配除换行符以外的任意一个字符
^ 匹配行首
$ 匹配行尾
? 重复匹配0次或1 * 重复匹配0次或更多次 + 重复匹配1次或更多次
{n,} 重复n次或更多次
{n,m} 重复n~m次
[a-z] 任意字符
[abc] a/b/c中的任意一个字符
{n} 重复n次
\b 匹配单词的开始和结束
\d 匹配数字
\w 匹配字母,数字,下划线
\s 匹配任意空白,包括空格,制表符(Tab),换行符
\W 匹配任意不是字母,数字,下划线的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开始和结束的位置
[^a] 匹配除了a以外的任意字符
[^(123|abc)] 匹配除了123或者abc这几个字符以外的任意字符
3.动态加载的数据如何提取
爬取动态页面目前来说有两种方法
-
分析请求页面
-
通过Selenium模拟浏览器获取(不推荐这种,太慢)
分析很简单,我们只需要打开了浏览器F12开发者模式,获取它的js请求文件(除JS选项卡还有可能在XHR选项卡中,当然 也可以通过其它抓包工具)
我们打开第一财经网看看,发现无法获取元素的内容
打开Network,看下它的请求,这里我们只看它的 j s 请求就够了, 找到json接口
将它的url放到浏览器看下,发现是我们要的数据,就可以获取了
一些网站所有的接口都进行了加密操作,我们无法解析js,就必须采用selenium+phantomjs进行获取
4.json数据如何提取
- 采用正则表达式解析:获取整个json数据后,采用正则表达式匹配到关键词;
- 使用eval解析
- json.loads() 是把Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码,json.dumps() 是把json_obj 转换为json_str
十一、其他常见面试
1、Post 和 Get 区别
- GET数据传输安全性低,POST传输数据安全性高,因为参数不会被保存在浏览器历史或web服务器日志中;
- 在做数据查询时,建议用GET方式;而在做数据添加、修改或删除时,建议用POST方式;
- GET在url中传递数据,数据信息放在请求头中;而POST请求信息放在请求体中进行传递数据;
- GET传输数据的数据量较小,只能在请求头中发送数据,而POST传输数据信息比较大,一般不受限制;
- 在执行效率来说,GET比POST好
2、Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
- 赋值:把等号右边的数据,存储到左边变量所开辟的内存空间中
- 浅拷贝:只拷贝引用不拷贝对象本身,一旦有一个引用修改,所有的引用都会被迫修改
- 深拷贝:直接拷贝对象本身,产生一个新的对象,并且产生一个新的引用;就是在内存中重新开辟一块空间,不管数据结构多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层,不再有复杂的数据类型,就保持其原引用。这样,不管数据结构多么的复杂,数据之间的修改都不会相互影响
3、什么是线程和进程?
进程:一个程序在操作系统中被执行以后就会创建一个进程,通过进程分配资源(cpu、内存、I/O设备),一个进程中会包含一到多个线程,其中有一个线程叫做主线程用于管理其他线程。.一个正在运行的程序可以看做一个进程,进程拥有独立运行所需要的全部资源。(例如:打开QQ相当于开启一个进程)
线程:程序中独立运行的代码段。在一个进程执行的过程,一般会分成很多个小的执行单位,线程就是这些执行单位;在处理机调度,以线程为单位件进行,多个线程之间并发执行,线程占用的是cpu。
一个程序至少拥有一个进程,一个进程至少拥有一个线程。进程负责资源的调度和分配,线程才是程序真正的执行单元,负责代码的执行。
多线程
多线程定义:多线程是指程序中包含多个执行流,即在一个程序中可以同时运行多个不同的线程来执行不同的任务,也就是说允许单个程序创建多个并行执行的线程来完成各自的任务。
多线程优点:可以提高CPU的利用率。在多线程程序中,一个线程必须等待的时候,CPU可以运行其它的线程而不是等待,这样就大大提高了程序的效率。
所以为了提高爬虫的效率,我们可以使用多线程来下载文件,在python中我们使用threading模块来创建多线程,从而实现多线程爬虫。(补充:Python3不能再使用thread模块)。
多线程使用的场合:耗时操作(访问外存,即:I/O,访问网络资源),为了不阻碍主线程或者其他的操作,一般会采用多线程。
4、爬虫使用多线程好?还是多进程好?为什么?
对于IO密集型代码(文件处理,网络爬虫),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,会造成不必要的时间等待,而开启多线程后,A线程等待时,会自动切换到线程B,可以不浪费CPU的资源,从而提升程序执行效率)。
在实际的采集过程中,既考虑网速和相应的问题,也需要考虑自身机器硬件的情况,来设置多进程或者多线程。
5、什么是协程?
协程是:在一个线程执行过程中可以在一个子程序的预定或者随机位置中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。他本身是一种特殊的子程序或者称作函数。
遇到IO密集型的业务时,多线程加上协程,你磁盘在那该读读该写写,我还能去干点别的。在WEB应用中效果尤为明显。
协程的好处:
跨平台
跨体系架构
无需线程上下文切换的开销
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
6、什么是并行和并发?
并行:多个进程在同一时刻同时进行
并发:多个进程在同一时间段内交替进行 (操作系统大多采用并发机制),根据一定的算法(常见的就是时间片轮询算法)
7,__new)_和__init__的区别
new:它是创建对象时调用,会返回当前对象的一个实例,可以用_new_来实现单例
init:它是创建对象后调用,对当前对象的一些实例初始化,无返回值
8,列举爬虫用到的网络数据包,解析包?
网络数据包 urllib、urllib2、requests
解析包 re、xpath、beautiful soup、lxml
9.如何显著提升爬虫的效率
-
使用性能更好的机器
-
使用光纤网络
-
多进程
-
多线程
-
分布式
10.如何提升scrapy的爬取效率
(1)增加并发
默认scrapy开启的并发线程为32个, 可以适当进行增加. 在settings配置文件中修改`CONCURRENT_REQUESTS = 100值为100, 并发设置成了为100.
(2)降低日志级别
在运行scrapy时, 会有大量日志信息的输出, 为了减少CPU的使用率. 可以设置log输出信息为INFO或者ERROR. 在配置文件中编写: LOG_LEVEL = ‘INFO’
(3)禁止cookie
如果不是真的需要cookie, 则在scrapy爬取数据时可以进制cookie从而减少CPU的使用率, 提升爬取效率. 在配置文件中编写: COOKIES_ENABLED = False.
(4)禁止重试
对失败的HTTP进行重新请求(重试)会减慢爬取速度, 因此可以禁止重试. 在配置文件中编写: RETRY_ENABLED = False
(5)减少下载超时
如果对一个非常慢的链接进行爬取, 减少下载超时可以能让卡住的链接快速被放弃, 从而提升效率. 在配置文件中进行编写: DOWNLOAD_TIMEOUT = 10 超时时间为10s.
11,使用redis搭建分布式系统时如何处理网络延迟和网络异常?
- 由于网络异常的存在,分布式系统中请求结果存在“三态”的概念,即三种状态:“成功”、“失败”、“超时(未知)”
- 当出现“超时”时可以通过发起读取数据的操作以验证 RPC 是否成功(例如银行系统的做法)
- 另一种简单的做法是,设计分布式协议时将执行步骤设计为可重试的,即具有所谓的“幂等性”
12.你是否了解mysql数据库的几种引擎?
- InnoDB:
InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。
在以下场合下,使用InnoDB是最理想的选择:
1.更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求。
2.事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎。
3.自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
4.外键约束。MySQL支持外键的存储引擎只有InnoDB。
5.支持自动增加列AUTO_INCREMENT属性。
一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。
- MEMORY:
使用MySQL Memory存储引擎的出发点是速度。为得到最快的响应时间,采用的逻辑存储介质是系统内存。
虽然在内存中存储表数据确实会提供很高的性能,但当mysqld守护进程崩溃时,所有的Memory数据都会丢失。
获得速度的同时也带来了一些缺陷。
一般在以下几种情况下使用Memory存储引擎:
1.目标数据较小,而且被非常频繁地访问。在内存中存放数据,所以会造成内存的使用,可以通过参数max_heap_table_size控制Memory表的大小,设置此参数,就可以限制Memory表的最大大小。
2.如果数据是临时的,而且要求必须立即可用,那么就可以存放在内存表中。
3.存储在Memory表中的数据如果突然丢失,不会对应用服务产生实质的负面影响。
十二、 Tornado
什么是RESTful
全称:Representational State Transfer
是HTTP协议(1.0和1.1)的主要设计者Roy Thomas Fielding提出
资源(Resources) 表现层(Representational )状态转化(State Transfer)
是实现API的一种风格
RESTful风格
Resources(资源):使用URL指向一个实体,例如:网页是资源,媒体也是资源
Representational (表现层):资源的表现形式,例如:图片,HTML文本等
State Transfer(状态转化):GET, POST, PUT, DELETE HTTP动词操作资源
例如后端的增删改查,增删改查可以和http请求联系起来
常用HTTP动词
RESTful解释:
GET, POST, PUT, DELETE 分别用来 获取,新建,更新,删除资源
幂等性:GET, PUT, DELETE
幂等性是指无论一次还是多次操作都具有一样的副作用
POST不具有幂等性,因为post每次都创建一个新的,
对于幂等性操作可以我们可以放心的发多次操作
对于非幂等性我,我们需要在后台保证发送多次不会创建多次
Tornado RESTful Api示例

MVC框架:
M:model表示操作数据库层
V:view表示视图层
C:controller 表示业务逻辑层
我们省略视图层,来实现微服务,进行用户管理(增删改查)
十三、python基础代码
画三角形星号
cs=int(input('请输入层数'))
for i in range(cs):
j=1
while j<=2*i+1:
print('*',end='')
j+=1
print()
#求一个数的倒过来得数
i=int(input("请输入一个整数:"))
j=0
while i>0:
j=j*10+i%10
i//=10
print(j)
求一个元素在列表里出现了几次
a=[1,2,3,2,1,2,3,4,5,6,4,3,2,1,2,3,4,5,6,5,4,3,5,6,7,8,9,7,8,9,0]
b=set(a)
for i in b:
print('%d在a中出现了%d次'%(i,a.count(i)))
查找变量的顺序
- LEGB法则
- L-----LOCAL 局部
- E-------ENCLOSE------嵌套作用域
- G-------GLOBLE-------全局
- B---------BUILT-IN------内置
a=100
b=2
c=10
def waibu():
b=200
c=2
def neibu():
c=300
print(c)#LOCAL局部变量
print(b)#ENCLOSE嵌套
print(a)#GLOBAL全局
print(max)#BUILT-IN内置
neibu()
waibu()
递归阶乘
def jiecheng(n):
if n==1:
return 1
else:
return n*jiecheng(n-1)
s=jiecheng(5)
print(s)
a=[lambda x:x*i for i in range(3)]
print(a[0](3)) # 6
print(a[1](3)) # 6
print(a[2](3)) # 6
class A():
def __init__(self):
print('A开始')
print('A结束')
class B(A):
def __init__(self):
print('B开始')
super().__init__()
print('B结束')
class C(A):
def __init__(self):
print('C开始')
super().__init__()
print('C结束')
class D(B,C):
def __init__(self):
print('D开始')
super().__init__()
print('D结束')
d=D()
输出结果为:
D开始
B开始
C开始
A开始
A结束
C结束
B结束
D结束
单例
class Car():
def __new__(cls, *args, **kwargs):
if not hasattr(Car,'inst'):#如果Car里面没有inst属性
Car.inst=object.__new__(Car)#就建立一个Car对象,给inst属性
return Car.inst#返回一个属性inst
def __init__(self,name,cid):
print('你好')
self.name=name
self.cid=cid
a=Car('宝马','京A66666')
b=Car('奔驰','京B66666')
print(a.name,a.cid)
print(b.name,b.cid)
输出:
你好
你好
奔驰 京B66666
奔驰 京B66666
多态
class A():
def j(self):
print('aaa')
class B():
def j(self):
print('bbb')
class C():
def j(self):
print('ccc')
def e(d):
d.j()
f=A()
g=B()
k=C()
e(f)
e(g)
e(k)
观察者模式
class Resi():
def __init__(self):
self.obsv=[]
self.stautus=''
def attach(self,ob):
self.obsv.append(ob)
def notify(self):
for x in self.obsv:
x.update()
class Observe():
def __init__(self,name,rs):
self.name=name
self.rs=rs
def update(self):
print('%s %s 请不要打游戏了'%(self.rs.status,self.name))
class Manager():
def __init__(self,name,boss):
self.name=name
self.boss=boss
def update(self):
print('%s %s 请到北京饭店开会'%(self.boss.status,self.name))
if __name__=='__main__':
resi=Resi()
obj_zs=Observe('张三',resi)
obj_ls=Observe('李四',resi)
obj_xh=Observe('小红',resi)
m_lqd=Manager('刘强东',resi)
m_my=Manager('马云',resi)
resi.attach(obj_zs)
resi.attach(obj_ls)
resi.attach(obj_xh)
resi.attach(m_lqd)
resi.attach(m_my)
resi.status='老板来啦'
resi.notify()
策略模式
class CashNormal():
def accept_money(self,money):
return money
class CashRate():
def __init__(self,rate):
self.rate=rate
def accept_money(self,money):
return money*self.rate
class CashReturn():
def __init__(self,conditon,ret):
self.conditon=conditon
self.ret=ret
def accept_money(self,money):
return money-(money//self.conditon)*self.ret
class Context():
def __init__(self,cs):
self.cs=cs
def get_result(self,money):
return self.cs.accept_money(money)
if __name__ == '__main__':
zd={}
zd[1]=Context(CashNormal())
zd[2]=Context(CashRate(0.8))
zd[3]=Context(CashReturn(300,50))
celue=int(input('请输入策略'))
if celue in zd.keys():
cs=zd[celue]
else:
cs=zd[1]
money=float(input('请输入金额'))
print(cs.get_result(money))
工厂模式
class Bmw():
def __init__(self,name):
self.name=name
class Benz():
def __init__(self,name):
self.name=name
class Carfactory:
@staticmethod
def makecar(name):
if name=='宝马':
return Bmw(name)
elif name=='奔驰':
return Benz(name)
car=Carfactory.makecar('宝马')
print(car.name,type(car))
car1=Carfactory.makecar('奔驰')
print(car1.name,type(car1))
析构函数
class A():
count=0
def __init__(self,name):
self.name=name
A.count+=1
print('加上',self.name,'还有%d个对象'%A.count)
def __del__(self):
A.count-=1
print('删除',self.name,'还剩%d个对象'%A.count)
a=A('张三')
b=A('李四')
del a
del b
二分查找
# 重要前提:二分查找的前提是有序
# 例如:【2,5,1,4,1,3】
# 先排序:【1,1,2,3,4,5】
# 先拿出列表中间的那个元素,和num进行比较,如果num大于中间的那个元素,
# 则表明:应该下次在中间和末尾之间的元素查找
# 如果num小于中间的这个元素,则表明:num在开始的元素和中间元素之间
list_1=[2,5,1,4,1,3]
list_1.sort()
print("排序之后的列表:",list_1)
num=int(input("请输入你要查找的数字:"))
first=0
last=len(list_1)-1
while firstnum:
last=mid-1
elif list_1[mid]num:
last=mid-1
else:
print("谁知道在哪")
冒泡排序
冒泡排序算法的运作如下:
比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
list_1=[2,3,1,5,6,4]
gs=len(list_1)
for i in range(0,gs-1):
for j in range(0,gs-i-1):
if list_1[j]>list_1[j+1]:
list_1[j],list_1[j+1]=list_1[j+1],list_1[j]
print(list_1)
空心塔型
cs = int(input("请输出要打印的层数"))
for i in range(cs):
for j in range(cs - i-1):
print(' ', end='')
for k in range(2 * i+1):
if k==0 or k==2*i or i==cs-1:#条件控制了塔型是否空心
print('*', end='')
else:
print(' ',end='')
i += 1
print()
请输出要打印的层数7
*
* *
* *
* *
* *
* *
*************
塔型
cs = int(input("请输出要打印的层数"))
for i in range(cs):
for j in range(cs - i - 1):
print(' ', end='')
for k in range(2 * i + 1):#这里的范围取值决定了塔型每行的字符数
print('*', end='')
i += 1
print()
输出:
*
***
*****
*******
*********
***********
*************
***************