支持向量机原理讲解(一)
介绍
支持向量机(Support Vector Machine,以下简称SVM),作为传统机器学习的一个非常重要的分类算法,它是一种通用的前馈网络类型,最早是由Vladimir N.Vapnik 和 Alexey Ya.Chervonenkis在1963年提出,目前的版本(soft margin)是Corinna Cortes 和 Vapnik在1993年提出,1995年发表。深度学习(2012)出现之前,如果不考虑集成学习的算法,不考虑特定的训练数据集,在分类算法中的表现SVM说是排第一估计是没有什么异议的。
SVM本来是一种线性分类和非线性分类都支持的二元分类算法,但经过演变,现在也支持多分类问题,也能应用到了回归问题。本篇文章重点讲解线性支持向量机的模型原理和目标函数优化原理。
目录
- 感知机模型
- 理解线性支持向量机
一、感知机模型

在讲解SVM模型之前,我们可以先简单了解感知机模型的原理,因为这两个模型有一些相同的地方。在二维平面中,感知机模型是去找到一条直线,尽可能地将两个不同类别的样本点分开。同理,在三维甚至更高维空间中,就是要去找到一个超平面。定义这个超平面为wTx+b=0(在二维平面中,就相当于直线w_1*x+w_1*y+b=0),而在超平面上方的点,定义为y=1,在超平面下方的点,定义为y=-1。而这样的超平面可能是不唯一的,那么感知机是怎么定期最优超平面呢?从感知机模型的目标函数中,我们了解到它是希望让所有误分类的点(定义为M)到超平面的距离和最小。其目标函数如下:
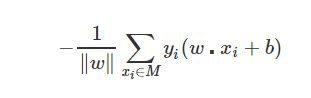
(注:加入y_i是因为点若在超平面下,w*x_i+b为负数,需要乘上对应的y)
当w和b成比例增加了之后,比如都扩大N倍,会发现,分子和分母都会同时扩大N倍,这对目标函数并不影响。因此,当我们将W扩大或缩小一定倍数使得,||w||=1,分子也会相应的扩大或缩小,这样,目标函数就能简化成以下形式:

这个思想将会应用到支持向量机的目标函数优化上,后文将会详细讲解。
二、理解线性支持向量机
2.1 线性支持向量机思想
正如上文所说,线性支持向量机的思想跟感知机的思想很相似。其思想也是对给定的训练样本,找到一个超平面去尽可能的分隔更多正反例。不同的是其选择最优的超平面是基于正反例离这个超平面尽可能远。

线性支持向量机模型
从上图可以发现,其实只要我们能保证距离超平面最近的那些点离超平面尽可能远,就能保证所有的正反例离这个超平面尽可能的远。因此,我们定义这些距离超平面最近的点为支持向量(如上图中虚线所穿过的点)。并且定义正负支持向量的距离为Margin。
2.2 函数间隔和几何间隔
对SVM思想有一定理解之后,设超平面为wTx+b=0。我们讲解一下函数间隔和几何间隔的区别。
给定一个样本x,|wTx+b|表示点x到超平面的距离。通过观察wTx+b和y是否同号,我们判断分类是否正确。所以函数间隔定义γ’为:
![]()
而函数间隔不能正常反应点到超平面的距离,因为当我们等比例扩大w和b的时候,函数间隔也会扩大相应的倍数。因此,我们引入几何间隔。
几何间隔就是在函数间隔的基础下,在分母上对w加上约束(这个约束有点像归一化),定义为γ:
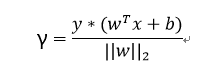
其实参考点到直线的距离,我们可以发现几何间隔就是高维空间中点到超平面的距离,才能真正反映点到超平面的距离。
2.3 SVM目标函数及优化
根据SVM的思想,我们可以知道是要取最大化支持向量到超平面的几何间隔,所以目标函数可以表示为:
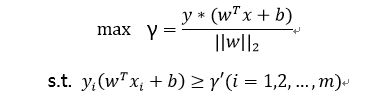
在感知机模型最后,我们知道当同时扩大w和b,分子分母都会同样扩大,对目标函数不影响,所以在这里我们将分子(支持向量到超平面的函数间隔)扩大或压缩等于1,则目标函数可以转化为:

但是上式并不是凸函数,不好求解,再进一步转化为:

上式就是一个凸函数,并且不等式约束为仿射函数,因此可以使用拉格朗日对偶去求解该问题。
根据拉格朗日乘子法,引入拉格朗日乘子α,且α≥0我们可以知道,先不考虑min,(2)问题等价于:

然后再考虑min,则有:
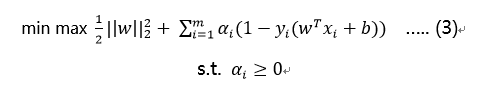
应用拉格朗日对偶性,通过求解对偶问题得到最优解,则对偶问题的目标函数为:
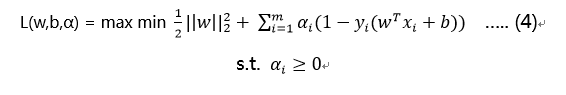
这就是线性可分条件下支持向量机的对偶算法。这样做的优点在于:
一是原问题的对偶问题往往更容易求解
二者可以自然的引入核函数,进而推广到非线性分类问题。
从(4)中,我们可以先求目标函数对于w和b的极小值,再求拉格朗日乘子α的极大值。
首先,分别对w和b分别求偏导数,并令为0:

将(5)和(6)代入(4)得到:

对(7)取反得到:

只要我们可以求出(8)中极小化的α向量,那么我们就可以对应的得到w和b,而求解α需要使用SMO算法,由于该算法比较复杂,我们将在下一篇文章专门讲解。假设我们现在已经使用SMO算法得到了最优的α值,记为α_ *

再求b:
对于任一样本(x_s, y_s)有:
![]()
注意到任一样本都有y_s^2=1,则将右式的1用y_s^2代:
![]()
将(9)代入上式,可以得到:
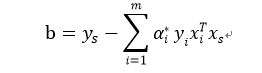
这样,我们就能够求解得到线性支持向量机的目标函数的各个参数,进而得到最优的超平面,将正负样本分隔开。但是在上文中我们没有讲解求α向量的SMO算法,在下篇文章,将会详细讲解SMO算法,欢迎继续关注。