Spark DataSet介绍
声明:代码主要以Scala为主,希望广大读者注意。本博客以代码为主,代码中会有详细的注释。相关文章将会发布在我的个人博客专栏《Spark 2.0机器学习》,欢迎大家关注。
Spark的发展史可以简单概括为三个阶段,分别为:RDD、DataFrame和DataSet。在Spark 2.0之前,使用Spark必须先创建SparkConf和SparkContext,不过在Spark 2.0中只要创建一个SparkSession就可以了,SparkConf、SparkContext和SQLContext都已经被封装在SparkSession当中,它是Spark的一个全新切入点,大大降低了Spark的学习难度。
一、创建SparkSession
创建SparkSession的方式非常简单,如下:
//创建SparkSession
val spark = SparkSession.builder()
.master("local[*]")
.appName("dataset")
.enableHiveSupport() //支持hive,如果代码中用不到hive的话,可以省略这一条
.getOrCreate()二、DataSet/DataFrame的创建

1、序列创建DataSet
//1、产生序列dataset
val numDS = spark.range(5, 100, 5)
numDS.orderBy(desc("id")).show(5) //降序排序,显示5个
numDS.describe().show() //打印numDS的摘要结果如下所示:
+---+
| id|
+---+
| 95|
| 90|
| 85|
| 80|
| 75|
+---+
only showing top 5 rows
+-------+------------------+
|summary| id|
+-------+------------------+
| count| 19|
| mean| 50.0|
| stddev|28.136571693556885|
| min| 5|
| max| 95|
+-------+------------------+2、集合创建DataSet
首先创建几个可能用到的样例类:
//样例类
case class Person(name: String, age: Int, height: Int)
case class People(age: Int, names: String)
case class Score(name: String, grade: Int)然后定义隐式转换:
import spark.implicits._最后,定义集合,创建dataset
//2、集合转成dataset
val seq1 = Seq(Person("xzw", 24, 183), Person("yxy", 24, 178), Person("lzq", 25, 168))
val ds1 = spark.createDataset(seq1)
ds1.show()结果如下所示:
+----+---+------+
|name|age|height|
+----+---+------+
| xzw| 24| 183|
| yxy| 24| 178|
| lzq| 25| 168|
+----+---+------+3、RDD转成DataFrame。
//3、RDD转成DataFrame
val array1 = Array((33, 24, 183), (33, 24, 178), (33, 25, 168))
val rdd1 = spark.sparkContext.parallelize(array1, 3).map(f => Row(f._1, f._2, f._3))
val schema = StructType(
StructField("a", IntegerType, false) ::
StructField("b", IntegerType, true) :: Nil
)
val rddToDataFrame = spark.createDataFrame(rdd1, schema)
rddToDataFrame.show(false)结果如下所示:
+---+---+
|a |b |
+---+---+
|33 |24 |
|33 |24 |
|33 |25 |
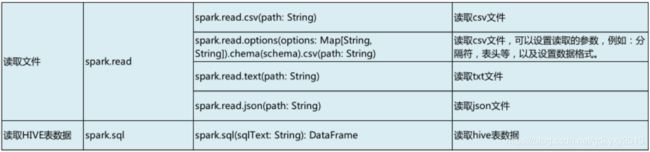
+---+---+4、读取文件
//4、读取文件,这里以csv文件为例
val ds2 = spark.read.csv("C://Users//Machenike//Desktop//xzw//test.csv")
ds2.show()结果如下所示:
+---+---+----+
|_c0|_c1| _c2|
+---+---+----+
|xzw| 24| 183|
|yxy| 24| 178|
|lzq| 25| 168|
+---+---+----+5、读取文件,并配置详细参数
//5、读取文件,并配置详细参数
val ds3 = spark.read.options(Map(("delimiter", ","), ("header", "false")))
.csv("C://Users//Machenike//Desktop//xzw//test.csv")
ds3.show()结果如下图所示:
+---+---+----+
|_c0|_c1| _c2|
+---+---+----+
|xzw| 24| 183|
|yxy| 24| 178|
|lzq| 25| 168|
+---+---+----+三、DataSet的基础函数
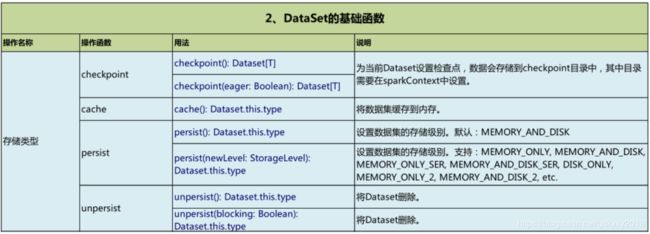


为了节省篇幅,以下内容不再给出运行结果~
//1、DataSet存储类型
val seq1 = Seq(Person("xzw", 24, 183), Person("yxy", 24, 178), Person("lzq", 25, 168))
val ds1 = spark.createDataset(seq1)
ds1.show()
ds1.checkpoint()
ds1.cache()
ds1.persist()
ds1.count()
ds1.unpersist(true)
//2、DataSet结构属性
ds1.columns
ds1.dtypes
ds1.explain()
//3、DataSet rdd数据互换
val rdd1 = ds1.rdd
val ds2 = rdd1.toDS()
ds2.show()
val df2 = rdd1.toDF()
df2.show()
//4、保存文件
df2.select("name", "age", "height").write.format("csv").save("./save")四、DataSet的Actions操作


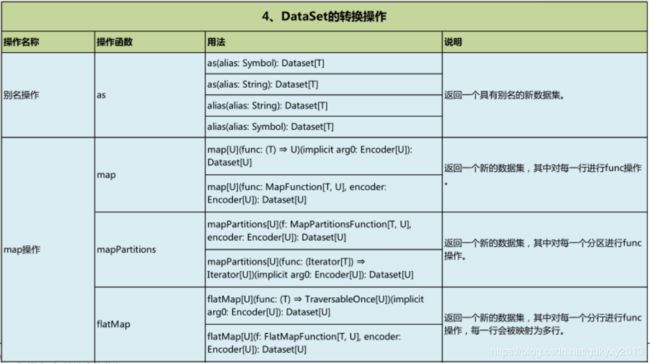
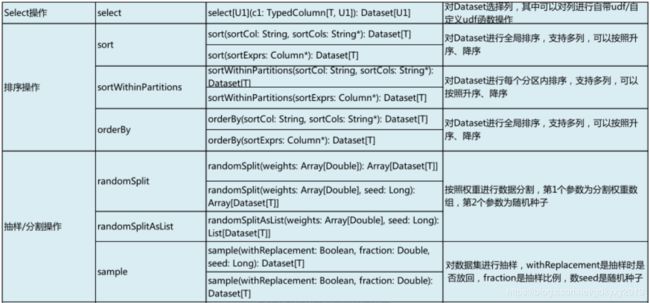
五、DataSet的转化操作


package sparkml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
//样例类
case class Person(name: String, age: Int, height: Int)
case class People(age: Int, names: String)
case class Score(name: String, grade: Int)
object WordCount2 {
def main(args: Array[String]): Unit = {
//设置日志输出格式
Logger.getLogger("org").setLevel(Level.WARN)
//创建SparkSession
val spark = SparkSession.builder()
.master("local[*]")
.appName("dataset")
.getOrCreate()
import spark.implicits._
//seq创建dataset
val seq1 = Seq(Person("leo", 29, 170), Person("jack", 21, 170), Person("xzw", 21, 183))
val ds1 = spark.createDataset(seq1)
//1、map操作,flatmap操作
ds1.map{x => (x.age + 1, x.name)}.show()
ds1.flatMap{x =>
val a = x.age
val s = x.name.split("").map{x => (a, x)}
s
}.show()
//2、filter操作,where操作
ds1.filter("age >= 25 and height >= 170").show()
ds1.filter($"age" >= 25 && $"height" >= 170).show()
ds1.filter{x => x.age >= 25 && x.height >= 170}.show()
ds1.where("age >= 25 and height >= 170").show()
ds1.where($"age" >= 25 && $"height" >= 170).show()
//3、去重操作
ds1.distinct().show()
ds1.dropDuplicates("age").show()
ds1.dropDuplicates("age", "height").show()
ds1.dropDuplicates(Seq("age", "height")).show()
ds1.dropDuplicates(Array("age", "height")).show()
//4、加法减法操作
val seq2 = Seq(Person("leo", 18, 183), Person("jack", 18, 175), Person("xzw", 22, 183), Person("lzq", 23, 175))
val ds2 = spark.createDataset(seq2)
val seq3 = Seq(Person("leo", 19, 183), Person("jack", 18, 175), Person("xzw", 22, 170), Person("lzq", 23, 175))
val ds3 = spark.createDataset(seq3)
ds3.union(ds2).show() //并集
ds3.except(ds2).show() // 差集
ds3.intersect(ds2).show() //交集
//5、select操作
ds2.select("name", "age").show()
ds2.select(expr("height + 1").as[Int].as("height")).show()
//6、排序操作
ds2.sort("age").show() //默认升序排序
ds2.sort($"age".desc, $"height".desc).show()
ds2.orderBy("age").show() //默认升序排序
ds2.orderBy($"age".desc, $"height".desc).show()
//7、分割抽样操作
val ds4 = ds3.union(ds2)
val rands = ds4.randomSplit(Array(0.3, 0.7))
println(rands(0).count())
println(rands(1).count())
rands(0).show()
rands(1).show()
val ds5 = ds4.sample(true, 0.5)
println(ds5.count())
ds5.show()
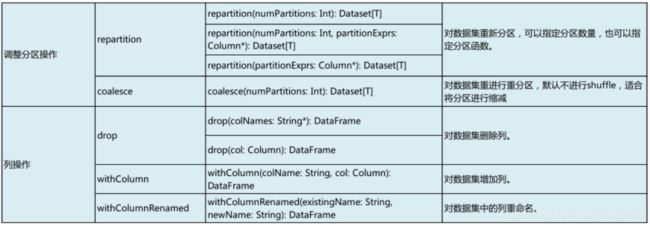
//8、列操作
val ds6 = ds4.drop("height")
println(ds6.columns)
ds6.show()
val ds7 = ds4.withColumn("add", $"age" + 2)
println(ds7.columns)
ds7.show()
val ds8 = ds7.withColumnRenamed("add", "age_new")
println(ds8.columns)
ds8.show()
ds4.withColumn("add_col", lit(1)).show()
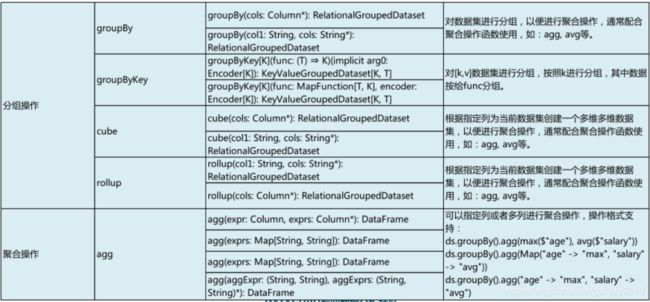
//9、join操作
val seq4 = Seq(Score("leo", 85), Score("jack", 63), Score("wjl", 70), Score("zyn", 90))
val ds9 = spark.createDataset(seq4)
val ds10 = ds2.join(ds9, Seq("name"), "inner")
ds10.show()
val ds11 = ds2.join(ds9, Seq("name"), "left")
ds11.show()
//10、分组聚合操作
val ds12 = ds4.groupBy("height").agg(avg("age").as("avg_age"))
ds12.show()
}
}
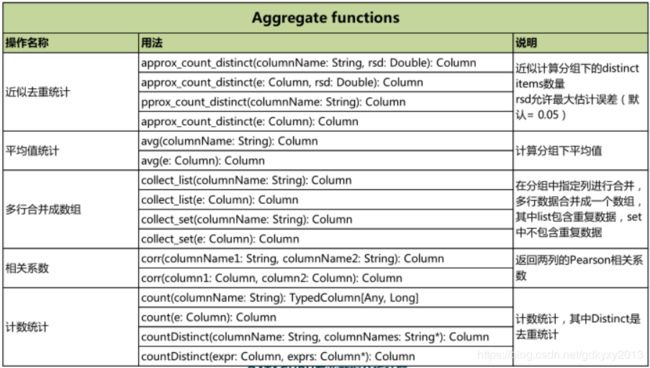
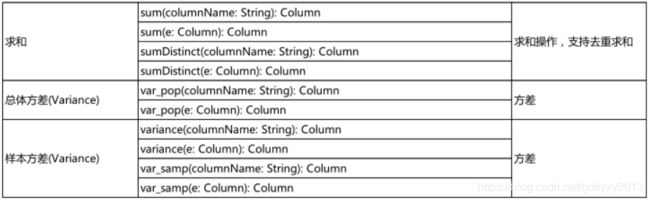
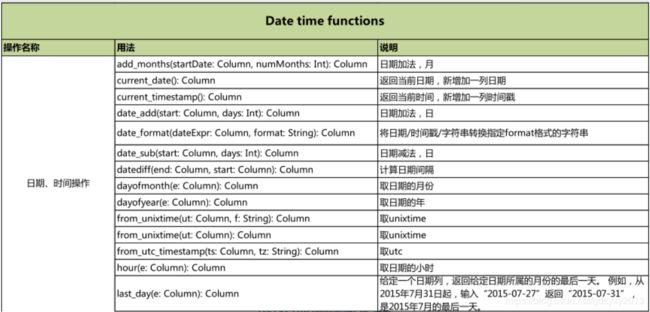
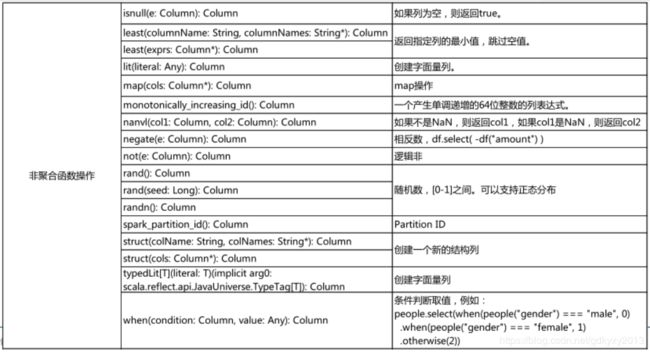
六、DataSet的内置函数












七、例子:WordCount
package sparkml
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark = SparkSession.builder()
.appName("Dataset")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val data = spark.read.textFile("C://xzw//wordcount")
.flatMap(_.split(" "))
.map(_.toLowerCase())
.filter($"value"=!="," && $"value"=!="." && $"value"=!="not")
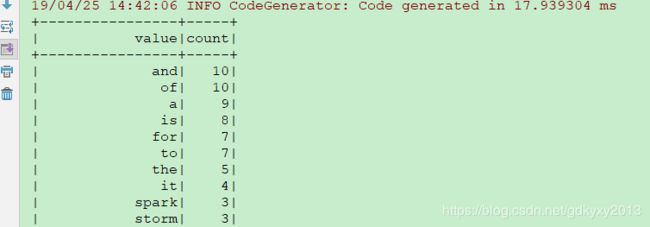
data.groupBy($"value").count().sort($"count".desc).show(50)
}
}
结果如下图所示: