机器学习(六)-基于KNN分类算法的自动划分电影的题材类型实现
基于KNN分类算法的自动划分电影的题材类型实现
- 1 分类算法引言
- 2 KNN算法及工作原理
- 3 KNN的第一个实例:电影的分类
- 3.1 项目介绍
- 3.2 如何求距离?------欧氏距离公式
- 3.3 k-近邻算法的一般流程
- 3.4 数据准备:使用 Python 导入数据
- 3.5 实施 KNN 算法
- 3.6 如何测试分类器
1 分类算法引言
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问题。
- 动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。
- 爱情片中的亲吻镜头更多,动作片中的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。
那么如何基于电影中出现的亲吻、打斗出现的次数,使用k-近邻算法构造程序,自动划分电影的题材类型。
2 KNN算法及工作原理
k-近邻(KNN)算法采用测量不同特征值之间的距离方法进行分类。
- 存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
- 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
一般来说,我们只选择样本数据集中前k个最相似的数据,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
3 KNN的第一个实例:电影的分类
3.1 项目介绍
动作,爱情,喜剧,灾难…???

-
使用打斗和接吻镜头数分类电影
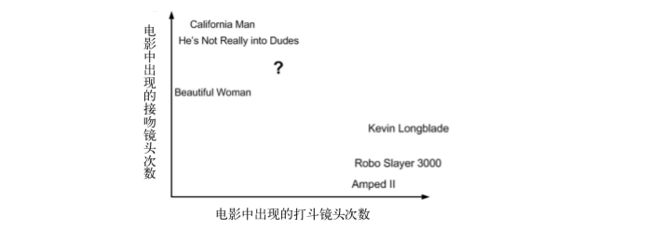
-
每部电影的打斗镜头数、接吻镜头数以及电影评估类型

-
已知电影与未知电影的距离
得到了距离后,选择前k个电影来判断未知电影的类型

3.2 如何求距离?------欧氏距离公式
- 二维空间
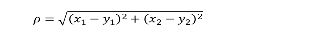
- 多维空间
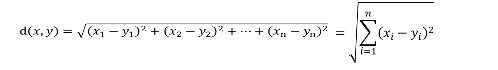
3.3 k-近邻算法的一般流程
(1) 收集数据:可以使用任何方法。
(2) 准备数据:距离计算所需要的数值,最好是结构化的数据格式。
(3) 分析数据:可以使用任何方法。
(4) 训练算法:此步骤不适用于k-近邻算法。
(5) 测试算法:计算错误率。
(6) 使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输
入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
3.4 数据准备:使用 Python 导入数据
import numpy as np
def createDataSet():
"""创建数据集"""
# 每组数据包含打斗数和接吻数;
group = np.array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])
# 每组数据对应的标签类型;
labels = ['Roman', 'Roman', 'Roman', 'Action', 'Action', 'Action']
return group, labels
3.5 实施 KNN 算法
对未知类别属性的数据集中的每个点依次执行以下操作:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类。
def classify(inx, dataSet, labels, k):
"""
KNN分类算法实现
:param inx:要预测电影的数据, e.g.[18, 90]
:param dataSet:传入已知数据集,e.g. group 相当于x
:param labels:传入标签,e.g. labels相当于y
:param k:KNN里面的k,也就是我们要选择几个近邻
:return:电影类新的排序
"""
dataSetSize = dataSet.shape[0] # (6,2) -- 6行2列 ===> 6 获取行数
# tile会重复inx, 把它重复成(dataSetSize, 1)型的矩阵
# (x1 - y1), (x2 - y2)
diffMat = np.tile(inx, (dataSetSize, 1)) - dataSet
# 平方
sqDiffMat = diffMat ** 2
# 相加, axis=1行相加
sqDistance = sqDiffMat.sum(axis=1)
# 开根号
distance = sqDistance ** 0.5
# 排序索引: 输出的是序列号index, 而不是值
sortedDistIndicies = distance.argsort()
# print(sortedDistIndicies)
classCount = {}
for i in range(k):
# 获取排前k个的标签名;
voteLabel = labels[sortedDistIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key=lambda d: float(d[1]),
reverse=True)
return sortedClassCount[0]3.6 如何测试分类器
- 分类器并不会得到百分百正确的结果,我们可以使用多种方法检测分类器的正确率。
- 为了测试分类器的效果,我们可以使用已知答案的数据,当然答案不能告诉分类器,检验分类器给出的结果是否符合预期结果。
- 完美分类器的错误率为0
- 最差分类器的错误率是1.0
完整代码
import numpy as np
def createDataSet():
"""创建数据集"""
# 每组数据包含打斗数和接吻数;
group = np.array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])
# 每组数据对应的标签类型;
labels = ['Roman', 'Roman', 'Roman', 'Action', 'Action', 'Action']
return group, labels
def classify(inx, dataSet, labels, k):
"""
KNN分类算法实现
:param inx:要预测电影的数据, e.g.[18, 90]
:param dataSet:传入已知数据集,e.g. group 相当于x
:param labels:传入标签,e.g. labels相当于y
:param k:KNN里面的k,也就是我们要选择几个近邻
:return:电影类新的排序
"""
dataSetSize = dataSet.shape[0] # (6,2) -- 6行2列 ===> 6 获取行数
# tile会重复inx, 把它重复成(dataSetSize, 1)型的矩阵
# (x1 - y1), (x2 - y2)
diffMat = np.tile(inx, (dataSetSize, 1)) - dataSet
# 平方
sqDiffMat = diffMat ** 2
# 相加, axis=1行相加
sqDistance = sqDiffMat.sum(axis=1)
# 开根号
distance = sqDistance ** 0.5
# 排序索引: 输出的是序列号index, 而不是值
sortedDistIndicies = distance.argsort()
# print(sortedDistIndicies)
classCount = {}
for i in range(k):
# 获取排前k个的标签名;
voteLabel = labels[sortedDistIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key=lambda d: float(d[1]),
reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group, label = createDataSet()
result = classify([3, 104], group, label, 5)
print("[3, 104]的电影类型:", result)- 效果展示
