深度学习之 人脸生成 BEGAN TensorFlow 实现
本文介绍 BEGAN (BoundaryEquilibriumGenerative AdversarialNetworks),边界平衡生成对抗网络程
参考资料
论文https://arxiv.org/pdf/1703.10717.pdf
1、简述
生成对抗网络 (GAN)是一类用于学习数据分布的方法并实现一个从中抽样的模型。GAN围绕两个功能构建:生成器G(z),它将样本
z从随机均匀分布映射到数据分布和判别器D(x)确定样本x是否属于数据分布。基于博弈论原理,通过交替训练D和G来共同学习生成器和
判别器。
GAN可以生成非常逼真的图像,比使用像素损失的自编码器生成的图像更锐利清晰。然而,GAN仍然面临许多未解决的困难:
1、 很难训练
2、 选择正确的超参数至关重要。
3、 控制生成样本的图像多样性是困难的。
4、 平衡判别器和生成器的收敛是一个挑战:在训练初始的时候判别器极易获胜。 GAN容易遭受模式崩溃,即这个失败的模型只
学习一张图像。如批量鉴别和排斥正则化器这些启发式正则化器,以不同程度的方式成功缓解这些问题。
BEGAN,提出了以下改进:
1、 一个简单而鲁棒的GAN架构,使用标准的训练步骤实现了快速且稳定的收敛
2、 一个均衡概念,用于平衡判别器与生成器之间的竞争力。
3、 一种控制图像多样性和视觉质量之间权衡的新方法。
4、 一种近似度量的收敛方法。 Wasserstein GAN (WGAN),已标准的W GAN有些诧异。
下面会看到D和G,这么简单的网络结构,能达到非常好的效果
2、优化目标
2.1 提出的方法
EBGAN中首次提出使用自编码器作为判别器。EBGAN的改变在discriminator上。把D看作是一个energy function,对real image
赋予低能量,fake image赋予高能量
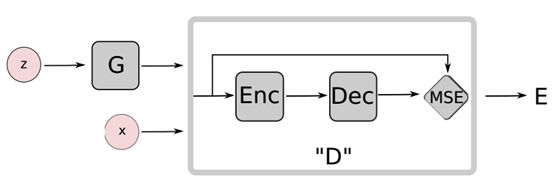
如EBGAN中提出使用自编码器作为判别器, BEGAN使用自编码器作为判别器。虽然经典GANs尝试直接匹配数据分布,但文中的
方法旨在从Wasserstein距离衍生而来的损失分布去匹配自编码器的损失分布。这里使用经典的GAN模型目标增加一个平衡项来平衡判别
器和生成器。文中的方法与经典GAN的方法相比,它具有更简单的训练过程并使用更简单的神经网络架构。
2.2 Wasserstein距离下限为自动编码器
BEGAN希望研究重构误差分布,而不是重构样本分布。首先介绍自编码器的损失,然后计算真实样本和生成样本自编码器损失分布
之间的Wasserstein距离的边界值。
编码器的损失
![]()
用于训练像素自编码器的损失:

设u1,u2是表示真实样本的损失分布和生成样本的损失分布,设Γ(u1,u2)为u1和u2的联合分布,并且m1,m2 ∈ R 表示各自的均值。
wasserstein距离表示为:
![]()
使用简森不等式,可以推到出W1(u1,u2)的下界:
![]()
这里我们的目标函数是优化自动编码器损失之间的Wasserstein距离,而不是样本分布之间。
2.3 目标函数
目标GAN
设计判别器用以最大化等式1中自动编码器损失之间的距离。设u1位损失L(x)的分布,其中x是真实样本。设u2为损失L(G(z))
的分布,其中G:R^(N_z ) -> R^(N_x ) 是生成函数,z ∈ [-1,1]^(N_z ) 是关于N_z的均匀随机样本。
由于m1,m2 ∈ R^+ 只有两种可能的解决方案来最大化|m1–m2|
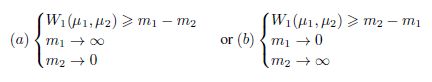
根据D和G的目标,采用第二组解更合理。它一方面拉大两个分布的距离,另一方面还能降低真实样本的重构误差(m1代表
真实样本重构误差,越小越好)。而G 为了缩小两个分布的差异,可以通过最小化m2来实现。对于D,(m2 - m1)最大化(通常
最小化为优化目标,等于m1-m2 最小化,取反)。而对于G,需要进行最小化这个距离(m2 - m1),因为D这里取反,那么公式
变成:
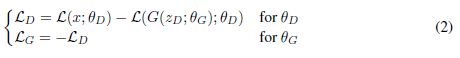
均衡概念
在训练中保持生成器和判别器损失之间的平衡至关重要;认为它们在以下情况处于平衡:
![]()
如果判别器无法判别生成样本和真实样本,那么它们的错误分布应该是相同的,包括它们的预期错误。这个概念允许我们给生成
器和判别器平衡分配任务,这样就一方不会胜过另一方。
可以通过引入新的超参数γ∈ [0, 1]来保持平衡:

在BEGAN的模型中,判别器有两个相互竞争的目标:对真实图像自编码和生成的图像中区别出真正的图像。 γ让我们平衡这两个
目标。 较低的γ值导致较低的图像多样性,因为判别器更着重于自动编码的真实图像。我们将γ称为多样性比率。 这是一个更加自然
的边界方法来判断图像是否锐利并具有详细信息。
边界平衡GAN
引入均衡概念后最终BEGAN目标函数变为:
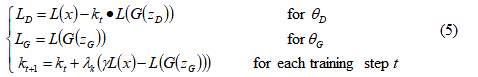
使用比例控制理论来维护平衡E[L(G(z))] = γE[L(x)]。使用变量k_t ∈ [0, 1]来控制在使用L(G(z_D))期间强调的梯度下降的程度。文
中初始化k_0 = 0。γ_k是k的比例增益;在机器学习术语中,这是k的学习率。文中实验中使用了0.001。从本质上讲,这可以被认为
是一种闭环反馈控制的形式,其中在每一步调整k_t以位置等式4。
在早期训练阶段,因为生成的数据接近0,并且实际数据分布尚未被准确地学习。这样就有L(x)>L(G(z)),并通过均衡约束在整个
训练过程保持不变。
3、网络结构
网络结构非常简单,编码函数encoder和decoder作为判别器两个函数,并生成函数generator和decoder采用同样的网络结构。
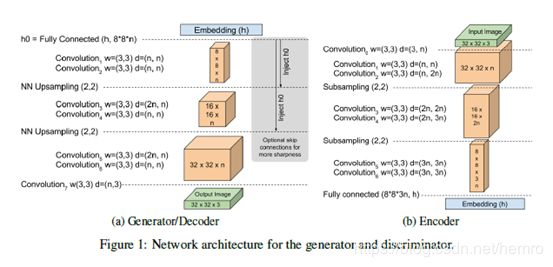
4、TensorFlow 实现
代码链接:https://github.com/Heumi/BEGAN-tensorflow
代码解读
代码简单结构清晰,按照模型和上述公式(目标函数)很容易理解。
简单看下主要几行代码:
# Generator
# 生成网络,网络结构和decoder一样。
self.recon_gen = self.generator(self.x)
# Discriminator (Critic)
# 计算真实图片和生成图片的自动编码器的结果,可参照上述图a
d_real = self.decoder(self.encoder(self.y))
d_fake = self.decoder(self.encoder(self.recon_gen, reuse=True), reuse=True)
self.recon_dec = self.decoder(self.x, reuse=True)
# Loss
# 计算真实图片和生成图片的自动编码器的Wasserstein距离
self.d_real_loss = l1_loss(self.y, d_real)
self.d_fake_loss = l1_loss(self.recon_gen, d_fake)
# 参考公式5
self.d_loss = self.d_real_loss - self.kt * self.d_fake_loss
self.g_loss = self.d_fake_loss
self.m_global = self.d_real_loss + tf.abs(self.gamma * self.d_real_loss - self.d_fake_loss)
# Optimizer
# 优化,采用Adam算法
self.opt_g = tf.train.AdamOptimizer(self.lr, self.mm).minimize(self.g_loss, var_list=g_vars)
self.opt_d = tf.train.AdamOptimizer(self.lr, self.mm).minimize(self.d_loss, var_list=d_vars)
# Training
# update kt, m_global
# k的更新,参考公式5
kt = np.maximum(np.minimum(1., kt + self.lamda * (self.gamma * d_real_loss - d_fake_loss)), 0.)
m_global = d_real_loss + np.abs(self.gamma * d_real_loss - d_fake_loss)
loss = loss_g + loss_d
训练模型
1、下载数据集
下载celeA 数据集(img_align_celeba.zip)并且解压到 ‘Data/celeba/raw’
2、对齐人脸数据集
运行 ’ python ./Data/celeba/face_detect.py ’
3、训练、测试模型
命令参考began_cmd.txt文件,可选择6464或128128的尺寸
Train
ex) 64x64 img | Nz,Nh 128 | gamma 0.4
python3 main.py -f 1 -p “began3” -trd “celeba” -tro “crop” -trs 64 -z 128 -em 128 -fn 64 -b 16 -lr 1e-4 -gm 0.4 -g “0”
ex) 128x128 img | Nz,Nh 64 | gamma 0.7
python3 main.py -f 1 -p “began” -trd “celeba” -tro “crop” -trs 128 -z 64 -em 64 -fn 128 -b 16 -lr 1e-4 -gm 0.7 -g “0”
Test
ex) 64x64 img | Nz,Nh 128 | gamma 0.4
python3 main.py -f 0 -p “began” -trd “celeba” -tro “crop” -trs 64 -z 128 -em 128 -fn 64 -b 16 -lr 1e-4 -gm 0.4 -g “0”
ex) 128x128 img | Nz,Nh 64 | gamma 0.7
python3 main.py -f 0 -p “began” -trd “celeba” -tro “crop” -trs 128 -z 64 -em 64 -fn 128 -b 16 -lr 1e-4 -gm 0.7 -g “0”
4、结果
选择128x128,gamma 0.7,训练结果
ex) 128x128 img | Nz,Nh 64 | gamma 0.7
python3 main.py -f 1 -p “began” -trd “celeba” -tro “crop” -trs 128 -z 64 -em 64 -fn 128 -b 16 -lr 1e-4 -gm 0.7 -g “0”
第一轮生成图片

最后一轮

训练好的模型生成一组图片
ex) 128x128 img | Nz,Nh 64 | gamma 0.7
python3 main.py -f 0 -p “began” -trd “celeba” -tro “crop” -trs 128 -z 64 -em 64 -fn 128 -b 16 -lr 1e-4 -gm 0.7 -g “0”

读者可以自行修改gamma,观察生成结果。