题记
Elastic社区主席M大、Elastic源码解析书作者超哥都曾多次强调Elastic日报是非常好的学习资料,然后呢?
Elastic日报自2017年7月30日发布第一篇文章,截止2019年6月6日,近10位责任编辑累计贡献了1653篇文章。
日报分散在社区文章专区,全部看完至少需要翻页40次+(每页18条数据,还需要过滤掉非日报文章),检索相对不方便。
能不能把Elastic日报爬取并导入Elasticsearch,借助ELK实现分析呢?
好想法,开搞!很期待~~
1、需求
当成一个小项目处理,自定义下需求。
想象一下,导入Elastic日报能在Kibana做哪些分析呢?
1)title 词频统计
2)编辑发布文章统计
3)2017,2018,2019日报量统计
4)日报按月统计
5)编辑发日报时间按区间统计
6)关键词检索,如:性能、设计、优化、实战等
7)....
的确,有了数据,能实现N多分析!
2、架构设计
编码之前,设计先行。一图胜千言,核心架构设计图如下所示: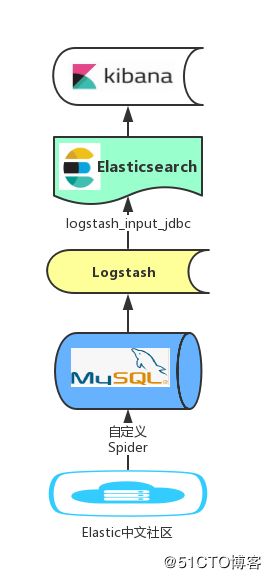
架构层面要考虑的核心工作:
1、模块划分
可分为几个模块:爬虫模块、同步模块、存储检索模块、可视化模块。
2、数据流
爬虫->Mysql->logstash->ES->Kibana。
3、数据ETL
日报数据算是半结构化数据,需要自定义正则解析、抽取后才能做分析用。 日期字段的时区原因,需要借助logstash filter进行日期格式转换。
4、数据存储建模
一方面:同步数据格式的定义;
另一方面:为后续可视化做数据铺垫。
3、爬虫模块
3.1 抓包分析网页
步骤1:根据需求,结合postman抓包分析日报模块的请求和返回内容。
步骤2:评估核心字段(标题、URL、编辑、发布时间等)是否好获取。
3.2 日报解析
Java + Jsoup + 正则 分页解析、并构造出字段信息。
记录了第几期日报字段,且给每一篇文章构造定义了唯一id。
3.3 日报入库
写入Mysql。
坑1:日期字段设置timestamp,避免精度损失,影响后面的分析。
4、同步模块
借助logstashinputjdbc实现Mysql到ES的同步。
坑1:为便于后续字段的自定义分析,务必不要使用动态映射,全部字段提前自定义。下一节详细论述。
坑2:同步ES后默认时区为ETC,发布时间会比实际落后8小时。需要filter阶段处理。 核心处理如下:
filter {
date {
match => ["publish_time", "yyyy-MM-dd HH:mm:ss"]
target => "publish_time"
timezone => "Asia/Shanghai"}
ruby {
code => "event.set('timestamp', event.get('publish_time').time.localtime + 86060)"
}
ruby {
code => "event.set('publish_time',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
5、存储分析模块
最核心就是Mapping的定义。如前分析,要自定义Mapping各字段,不要使用默认动态的Mapping。
原因1、string类型全部解析为:text和keyword,实际我们不一定需要,会浪费存储空间。
原因2:采用默认分词器analyzer,实际我们需要自定义分词:采用中文ik分词,使用ikmaxword或者ik_smart进行自定义分词。
为便于后续扩展和维护,使用template、alias实现。
坑1:第一次导入分词结果不理想,可能会有大量的停用词。比如:1、2、3、的、你、日、中、在、与、来、一、二、三、到等。
处理方案:在stopword.dic添加如上关键词,重启ES,重建索引并再次导入数据。
坑2:text类型的字段聚合。
处理方案:定义索引Mapping的时候,指定 "fielddata":"true",
推荐阅读:Elasticsearch词频统计实现与原理解读
5、可视化模块
关于title 词频统计,对应上图的左上角:词云和如下的细化词频统计。
日报在:搜索、分析、实践、性能、监控方面都有大量的中英文优秀精选文章。
其他3张图,对应需求2)编辑发布文章统计、3)2017,2018,2019日报量统计、4)日报按月统计趋势图。
针对需求5)编辑发日报时间按区间统计
实践一把:
POST es_daily_info/_search
{
"size": 0,
"aggs" : {
"time_range" : {
"range" : {
"script" : {
"source": "doc['publish_time'].date.getHourOfDay()",
"lang": "painless"
},
"ranges" : [
{ "from":0, "to" : 6 },
{ "from" : 6, "to" : 20 },
{ "from" : 20, "to": 24}
]
}
}
}}
返回结果如下:
[
{
"key" : "0.0-6.0",
"from" : 0.0,
"to" : 6.0,
"doc_count" : 21
},
{
"key" : "6.0-20.0",
"from" : 6.0,
"to" : 20.0,
"doc_count" : 1524
},
{
"key" : "20.0-24.0",
"from" : 20.0,
"to" : 24.0,
"doc_count" : 108
}
]可以看出: 有21篇文章是凌晨以后发的,有108篇是晚上8点到晚24点发布的。(辛苦各位日报编辑了!)
针对需求6):
一个检索语句搞定:Elasticsearch+性能优化干货文章,比Google搜出来的靠谱。
因为:这些文章都是编辑们人工筛选的,可谓是 优中选优。
POST es_daily_info/_search
{
"_source": {
"includes": ["title","url"]},
"query": {
"match_phrase": {
"title": "性能优化"
}}
}
7、小结
数据获取是整个小项目的最核心一环,有了数据,展开多维度的分析不再是难事。
当前互联网环境下,Elasticsearch学习资料网上一搜会是一箩筐,但搜索引擎毕竟是根据相关度推荐,到实际业务可用还有差距。
Elastic日报不同点核心在于人工精选,优中选优。如果你还在为学习资源发愁,不妨过一遍。
本文的实现,就是对日报资源抽丝破茧、条分缕析的对每条数据建立倒排索引,可极大提高Elastic学习和实战的效率。
8、禅定时刻
其实,Elastic中文社区完全可以上线日报搜索功能,方便大家O(1)复杂度获取想要的日报文章。
你在ELK实践过程中,有哪些实践心得体会,欢迎留言讨论。