sklearn之模型选择与评估
sklearn之模型选择与评估
在机器学习中,在我们选择了某种模型,使用数据进行训练之后,一个避免不了的问题就是:如何知道这个模型的好坏?两个模型我应该选择哪一个?以及几个参数哪个是更好的选择? 这就涉及到一个模型选择与评估的问题了。sklearn包的model_selection模块主要辅助要解决的,就是这个问题。
下面我们会简单讲下model_selection中提到的一些模型选择与评估方法,作为一些概述。更详细的介绍可以看这里
交叉验证(cross_validation)
对于验证模型好坏,我们最常使用的方法就是交叉验证法。也就是每次训练,都使用训练数据的一个划分(或者称为折,fold):一部分作为训练集,一部分作为验证集,进行多次划分多次训练后,得到想要的模型。
在sklearn中,对于获取到的数据,如果我们想要只划分成一部分train和一部分test,并训练然后验证的话,我们可以直接使用model_selection中的train_test_split来进行划分;一般情况下,我们是已经有了train和test数据,然后希望训练出一个模型来,然后应用到test中。至于模型好不好,参数怎么选择,我们会使用cross_validation方法来进行划分并验证。
交叉验证的评价
对于交叉验证,我们常用的cross_validation方法就是cross_val_score来获取交叉验证的得分。最常见的使用方法是:
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, iris.data, iris.target, cv=5)
>>> scores
array([ 0.96..., 1. ..., 0.96..., 0.96..., 1. ])
>>> print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Accuracy: 0.98 (+/- 0.03)
>>> from sklearn import metrics
>>> scores = cross_val_score(
... clf, iris.data, iris.target, cv=5, scoring='f1_macro')
>>> scores
array([ 0.96..., 1. ..., 0.96..., 0.96..., 1. ])Cross_val_score会得到一个对于当前模型的评估得分。在该函数中,最主要的参数有两个:scoring参数—设定打分的方式是什么样的, cv — 数据是按照什么样的形式来进行划分的。
scoring参数
对于scoring参数,可以参见这里 ,里面提到了针对不同的模型所可以使用的评测方法,后面也会介绍到。
cv参数
对于cv参数,它所控制的是将数据进行划分的方式。通常默认的是KFold 或者 stratifiedKFold方法。这些划分方法划分成的组A, B, C … 其中:
A∪B∪C…=全集 ; A∩B∩C=∅
除了这两种默认的划分之外,也可以用其他的划分,例如: ShuffleSplit
下面简单介绍下常用的一些划分方法:
Kfold划分方法:前n_samles % k 个划分有( n_samples / k ) + 1 个样本点,剩下的有n_samples / k个。
leave-one-out (loo) 顾名思义,每次留下一个
Leave-p-out 顾名思义,每次留下p个
Shufflesplit :样本点要重新排序,而且根据n_splits 来设定分成的组数,这个分成的n_splits组中,样本点可以有重复;可以根据train_size, test_size 来设定训练数据和测试数据的个数。
>>> from sklearn.model_selection import ShuffleSplit
>>> X = np.arange(5)
>>> ss = ShuffleSplit(n_splits=3, test_size=0.25,
... random_state=0)
>>> for train_index, test_index in ss.split(X):
... print("%s %s" % (train_index, test_index))
...
[1 3 4] [2 0]
[1 4 3] [0 2]
[4 0 2] [1 3]stratifiedKFold 划分方法:所有的划分都有n_samples / k 个,最后一个划分是取前面剩下的。(实际来看的话,会有所调整)
之前提到了该方法,但是该方法更重要的是:每个组都有相同的目标类别占比。例如(0,1)分类,每个分组中都有相同的0,1占比。
Stratified Shuffle Split 跟上面的类似。
除了常见的划分之外,还有一种需要注意的划分情况:当有的样本点来自于同一个对象,而有的样本点来自于别的对象的时候,我们务必不能将来自同一个对象的对个样本,分别放到train和test中。因为我们预测的目的是为了更好的泛化到未知的个体当中,如果在测试数据中有了为训练数据提供来源的个体,就会导致无法准确的判断泛化情况。
对应的,方法有groupk-fold, leave one group out, leave p groups out group shuffle out 等方法。
注意点
还有一点需要注意:如果我们想要使用划分方案,来对数据进行处理的话,有种情况我们需要考虑:当我们对划分出来的训练数据进行预处理,并训练完毕后,我们同时也需要对预留出来的测试数据做同样的处理。
举个例子:
>>> from sklearn import preprocessing
>>> X_train, X_test, y_train, y_test = train_test_split(
... iris.data, iris.target, test_size=0.4, random_state=0)
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> X_train_transformed = scaler.transform(X_train)
>>> clf = svm.SVC(C=1).fit(X_train_transformed, y_train)
>>> X_test_transformed = scaler.transform(X_test)
>>> clf.score(X_test_transformed, y_test)
0.9333...scaler用于对数据做标准化,在后面对测试数据进行测试时,同样要使用该标准化。
当然,我们可以使用Pipeline来简化这种方法:
>>> from sklearn.pipeline import make_pipeline
>>> clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
>>> cross_val_score(clf, iris.data, iris.target, cv=cv)
...
array([ 0.97..., 0.93..., 0.95...])除了得分之外,我们可以直接使用cross_val_predict来进行预测;
调参
使用grid_search 来调参,其中得分的评测方法里面,就已经使用了cross_validation.
而randomizedsearchcv是从分布中选取参数
调参的小tips
1、选定合适的评分策略
2、使用pipeline来查找参数空间
3、模型选择:进行gridsearch之后进行模型评估的时候,最好要使用gridsearch没有使用过的数据。这时候最好使用train_test_split.
4、暴力破解方法
有些函数自带了cv方法,例如Lasso,Ridge等
5、bag方法
模型评估:预测质量的评估
有三种方法可以评估一个模型的好坏:
1、模型自带 score函数
2、 cross_val_score grid_search方法中的得分参数
在这个得分参数里面,你可以使用metrics中定义好的评估得分参数
3、评估函数
除了评估得分方法之外,还有其他直接的一些评估函数。
预定义的一些得分方法:
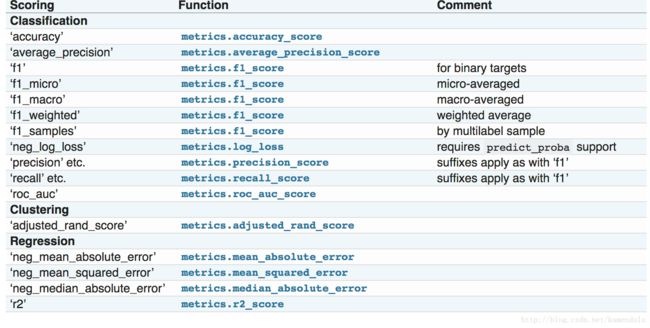
用于分类:
Accuracy:准确率
Average_precision:
This score corresponds to the area under the precision-recall curve.
Note: this implementation is restricted to the binary classification task or multilabel classification task.
F1 The F1 score can be interpreted as a weighted average of the precision and recall
F1 = 2 * (precision * recall) / (precision + recall)f1_micro
F1_macro
F1_weighted
F1_samples
Neg_log_loss 也就是交叉验证熵
-log P(yt|yp) = -(yt log(yp) + (1 - yt) log(1 - yp))
This is the loss function used in (multinomial) logistic regression and extensions of it such as neural networks
Precision recall 召回率
roc_auc
Compute Area Under the Curve (AUC) from prediction scores
用于回归:
neg_mean_absolute_error 绝对差
neg_mean_squared_error 方差
R2_score R^2 (coefficient of determination) regression score function.
模型的保存
pickle方法
验证图
随着样本点的增多,训练得分值和交叉验证得分值的比较