史上最全系列之zookeeper
Zookeeper是什么
1 官方版解释
ZooKeeper顾名思意:动物园管理员
zookeeper由雅虎研究院开发,是Google Chubby的开源实现,后来托管到 Apache,于2010年11月正式成为apache的顶级项目
大数据生态系统里由很多组件的命名都是某些动物或者昆虫,比如hadoop大象,hive就是蜂巢,
ZooKeeper是一个集中的服务,用于维护配置信息、命名、提供分布式同步和提供组服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次它们被实现时,都会有大量的工作来修复不可避免的错误和竞争条件。由于实现这些服务的困难,应用程序最初通常会略过这些服务,这使得它们在出现更改时变得脆弱,并且难以管理。即使正确地执行了这些服务,在部署应用程序时,这些服务的不同实现也会导致管理复杂性
一句话:ZooKeeper是一个分布式协调技术、高性能的,开源的分布式系统的协调(Coordination)服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用程序一致性和分布式协调技术服务的软件。
2设计模式来理解
是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
3 一句话
zookeeper=类似unix文件系统+通知机制+Znode节点
作用:服务注册+分布式系统的一致性通知协调 (类似于指路的牌子)
4 下载
https://zookeeper.apache.org/releases.html#download

4.怎么玩
应用场景
分布式锁服务
- 一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性,多台服务器上运行着同一种服务。当多个服务在运行时就需要协调各服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁,如果当前机器挂掉后,释放锁并
fail over到其他的机器继续执行该服务
集群管理
- 一个集群有时会因为各种软硬件故障或者网络故障,出现棊些服务器挂掉而被移除集群,而某些服务器加入到集群中的情况,
zookeeper会将这些服务器加入/移出的情况通知给集群中的其他正常工作的服务器,以及时调整存储和计算等任务的分配和执行等。此外zookeeper还会对故障的服务器做出诊断并尝试修复。
生产分布式唯一ID
-
在过去的单库单表型系统中,通常可以使用数据库字段自带的
auto_ increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_ Increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。做法如下:每次要生成一个新
id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新id,然后把比自己节点小的删除即可
统一命名服务(Name Service如Dubbo服务注册中心)
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。
在Dubbo实现中:
服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,
这个操作就完成了服务的发布。
服务消费者启动的时候,订阅/dubbo/ s e r v i c e N a m e / p r o v i d e r s 目 录 下 的 提 供 者 U R L 地 址 , 并 向 / d u b b o / {serviceName}/providers目录下的提供者URL地址, 并向/dubbo/ serviceName/providers目录下的提供者URL地址,并向/dubbo/{serviceName} /consumers目录下写入自己的URL地址。
注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。 另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/${serviceName}目录下所有提供者和消费者的信息。
配置管理(Configuration Management如淘宝开源配置管理框架Diamond)
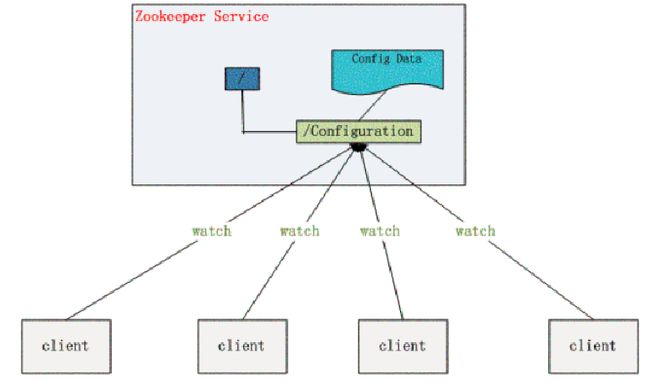
在大型的分布式系统中,为了服务海量的请求,同一个应用常常需要多个实例。如果存在配置更新的需求,常常需要逐台更新,给运维增加了很大的负担同时带来一定的风险(配置会存在不一致的窗口期,或者个别节点忘记更新)。zookeeper可以用来做集中的配置管理,存储在zookeeper集群中的配置,如果发生变更会主动推送到连接配置中心的应用节点,实现一处更新处处更新的效果
现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
Zookeeper的设计目标
zooKeeper致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务
- 高性能
zookeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,尤其用于以读为主的应用场景
- 高可用
zookeeper一般以集群的方式对外提供服务,一般3~5台机器就可以组成一个可用的Zookeeper集群了,每台机器都会在内存中维护当前的服务器状态,井且每台机器之间都相互保持着通信。只要集群中超过一半的机器都能够正常工作,那么整个集群就能够正常对外服务
- 严格顺序访问
- 对于来自客户端的每个更新请求,
Zookeeper都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序
- 对于来自客户端的每个更新请求,
zoo.cfg

tickTime
tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒
Zookeeper使用的基本时间, 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间.(session的最小超时时间2*tickTime。)
initLimit
initLimit
这个配置项是用来配置Zookeeper接收Follower客户端(这里所说的客户端不是用户链接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到leader的Follower服务器,Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许Follower在 initLimit 时间内完成这个工作)初始化连接是最长能忍受多少个心跳的时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper服务器还没有收到客户端返回的信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20秒
syncLimit
yncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态,
假如响应超过syncLimit * tickTime(假设syncLimit=5 ,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。),Leader认为Follwer死掉,从服务器列表中删除Follwer。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。
如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了。
dataDir
dataDir:数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
clientPort
clientPort:客户端连接端口
监听客户端连接的端口。
启动+关闭服务
/myzookeeper/zookeeper-3.4.9/bin路径下
./zkServer.sh start
./zkServer.sh stop
连接:./zkCli.sh
退出:quit
文件系统
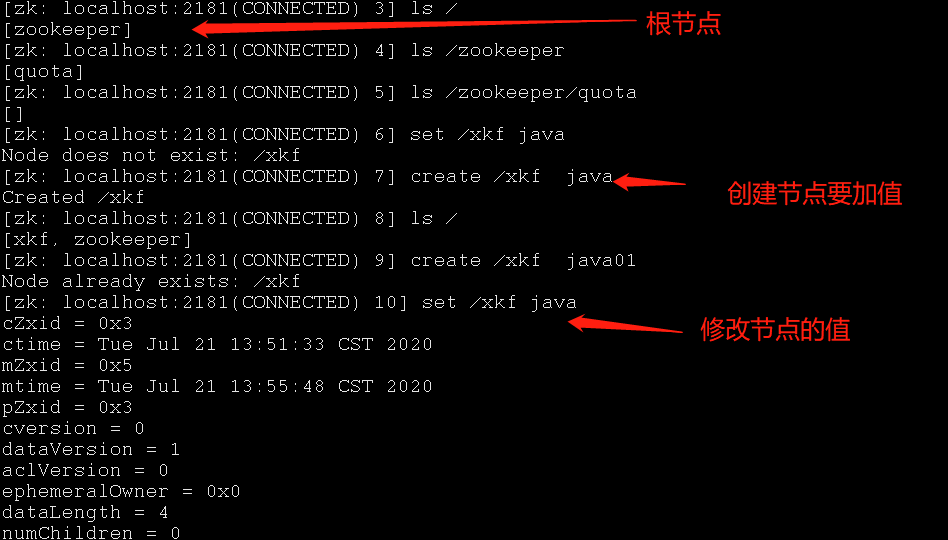
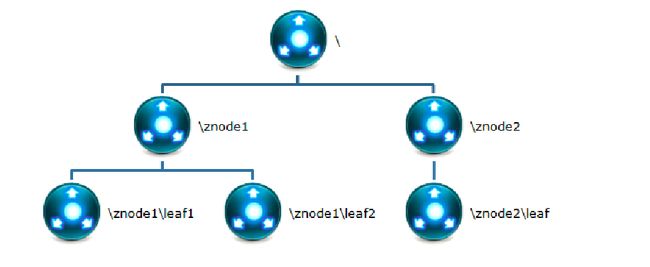
Zookeeper维护一个类似文件系统的数据结构
所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,
有名称,
有树节点,
有Key(键)/Value(值)对的关系,
可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
初识znode节点
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode
很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
数据模型/znode节点深入
Znode的数据模型
是什么
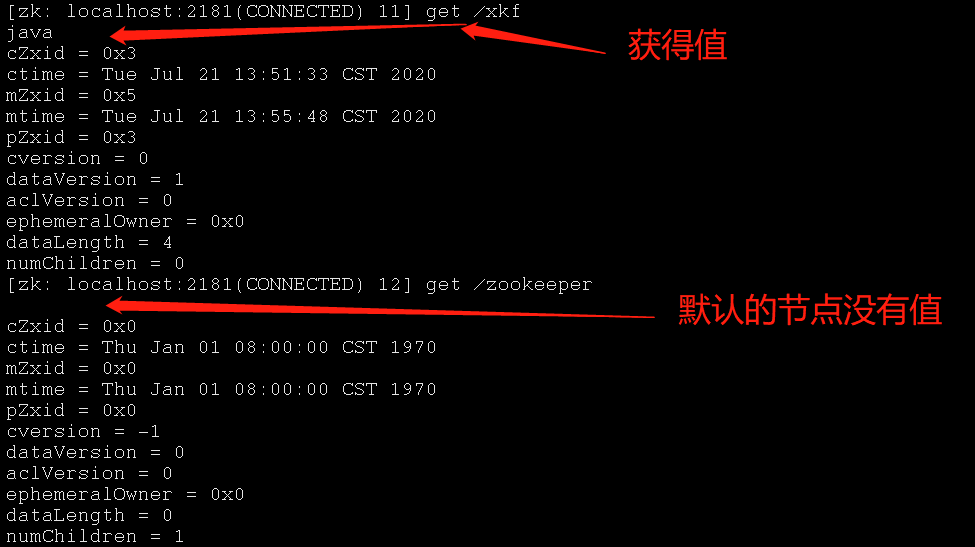
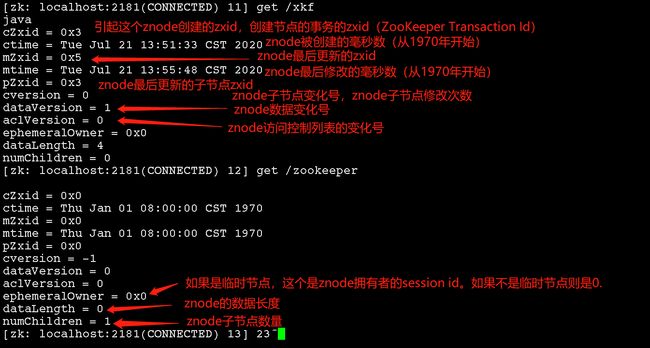
Znode维护了一个stat结构,这个stat包含数据变化的版本号、访问控制列表变化、还有时间戳。版本号和时间戳一起,可让Zookeeper验证缓存和协调更新。每次znode的数据发生了变化,版本号就增加。
例如,无论何时客户端检索数据,它也一起检索数据的版本号。并且当客户端执行更新或删除时,客户端必须提供他正在改变的znode的版本号。如果它提供的版本号和真实的数据版本号不一致,更新将会失败。
ZooKeeper的Stat结构体
小总结
zookeeper内部维护了一套类似UNIX的树形数据结构:由znode构成的集合,
znode的集合又是一个树形结构,
每一个znode又有很多属性进行描述。 Znode = path + data + Stat
zookeeper的Acl权限控制
https://zookeeper.apache.org/doc/r3.4.14/zookeeperProgrammers.html#sc_ZooKeeperAccessControl
zookeeper类似文件系统,client可以创建结点、更新结点、删除结点,那么如何做到结点的权限控制呢?
zookeeper的 access control list 访问控制列表可以做到这一点
acl权限控制,使用scheme:id:permission来标识,主要涵盖3个方面:
https://zookeeper.apache.org/doc/r3.4.14/zookeeperProgrammers.html#sc_BuiltinACLSchemes
- 权限模式(
scheme):授权的策略 - 授权对象(
id):授权的对象 - 权限(
permission):授予的权限
其特性如下:
-
zookeeper的权限控制是基于每个znode结点的,需要对每个结点设置权限 -
每个
znode支持多种权限控制方案和多个权限 -
子结点不会继承父结点的权限,客户端无权访问某结点,但可能可以访问它的子结点:
例如
setAcl /test2 ip:192.168.133.133:crwda// 将结点权限设置为Ip:192.168.133.133 的客户端可以对节点进行
增删改查和管理权限
权限模式
-
采用何种方式授权
-
方案 描述 world 只有一个用户: anyone,代表登录zookeeper所有人(默认)ip 对客户端使用IP地址认证 auth 使用已添加认证的用户认证 digest 使用"用户名:密码"方式认证
授权对象
- 给谁授予权限
- 授权对象ID是指,权限赋予的实体,例如:IP地址或用户
授权的权限
-
授予什么权限
-
create、delete、read、writer、admin也就是 增、删、查、改、管理权限,这5种权限简写为 c d r w a,注意:
这五种权限中,有的权限并不是对结点自身操作的例如:delete是指对子结点的删除权限可以试图删除父结点,但是子结点必须删除干净,所以
delete的权限也是很有用的 -
权限 ACL简写 描述 create c 可以创建子结点 delete d 可以删除子结点(仅下一级结点) read r 可以读取结点数据以及显示子结点列表 write w 可以设置结点数据 admin a 可以设置结点访问控制权限列表
授权的相关命令
-
命令 使用方式 描述 getAcl getAcl 读取ACL权限 setAcl setAcl 设置ACL权限 addauth addauth 添加认证用户
案例/远程登录
./zkServer.sh -server 192.168.133.133 可以远程登录
world权限模式
getAcl /node// 读取权限信息setAcl /node world:anyone:drwa// 设置权限(禁用创建子结点的权限)
ip模式
./zkServer.sh -server 192.168.133.133 可以远程登录
setAcl /hadoop ip:192.168.133.133:drwa- 如果在两台不同的虚拟机中,另一台用远程连接的模式,进行上面这条命令,那么只会有一台被授权
- 需要两台虚拟机一起授权的话需要用逗号将授权列表隔开:
setAcl /hadoop ip:192.168.133.133:cdrwa,ip:192.168.133.132:cdrwa
auth认证用户模式
addauth digest
setAcl
-
create /hadoop "hadoop" # 初始化测试用的结点 addauth digest itcast:123456 # 添加认证用户 setAcl /hadoop auth:itcast:cdrwa # 设置认证用户 quit # 退出后再./zkCli.sh 进入 get /hadoop # 这个时候就没有权限了,需要再次认证 addauth digest itcast:123456 # 认证,密码错了的话 zookeeper 不会报错,但是不能认证 get /hadoop
Digest授权模式
setAcl
-
这里的密码是经过
SHA1以及BASE64处理的密文,在shell 中可以通过以下命令计算:-
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64 -
# 计算密码 echo -n itcast:12345 | openssl dgst -binary -sha1 | openssl base64 # 获取密码,设置权限列表 setAcl /hadoop digest:itcast:qUFSHxJjItUW/93UHFXFVGlvryY=:cdrwa # 现在想要get /hadoop 需要登录了 addauth digest itcast:12345 get /hadoop
-
多种授权模式
仅需逗号隔开
-
setAcl /hadoop ip:192.168.133.132:cdrwa,auth:hadoop:cdrwa,digest:itcast:673OfZhUE8JEFMcu0l64qI8e5ek=:cdrwa
acl 超级管理员
-
zookeeper的权限管理模式有一种叫做super,该模式提供一个超管,可以方便的访问任何权限的节点假设这个超管是
supper:admin,需要为超管生产密码的密文echo -n super:admin | openssl dgst -binary -sha1 | openssl base64 -
那么打开
zookeeper目录下/bin/zkServer.sh服务器脚本文件,找到如下一行:/nohup # 快速查找,可以看到如下 nohup "$JAVA" "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" -
这个就算脚本中启动
zookeeper的命令,默认只有以上两个配置项,我们需要添加一个超管的配置项"-Dzookeeper.DigestAuthenticationProvider.superDigest=super:xQJmxLMiHGwaqBvst5y6rkB6HQs=" -
修改后命令变成如下
nohup "$JAVA" "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:xQJmxLMiHGwaqBvst5y6rkB6HQs=" -
# 重起后,现在随便对任意节点添加权限限制 setAcl /hadoop ip:192.168.1.1:cdrwa # 这个ip并非本机 # 现在当前用户没有权限了 getAcl /hadoop # 登录超管 addauth digest super:admin # 强行操作节点 get /hadoop
znode中的存在类型
1.PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在(默认创建)
2.PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3.EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4.EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号


znode是由客户端创建的,它和创建它的客户端的内在联系,决定了它的存在性:
PERSISTENT-持久化节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点也不会被删除(除非您使用API强制删除)。
PERSISTENT_SEQUENTIAL-持久化顺序编号节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当客户端与zookeeper服务的连接断开后,这个节点也不会被删除。
EPHEMERAL-临时目录节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点(还有涉及到的子节点)就会被删除。
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当创建这个节点的客户端与zookeeper服务的连接断开后,这个节点被删除。
另外,无论是EPHEMERAL还是EPHEMERAL_SEQUENTIAL节点类型,在zookeeper的client异常终止后,节点也会被删除
基础命令
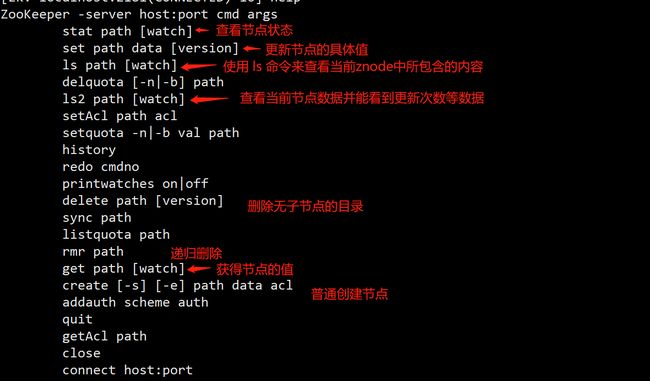
监听器get path [watch] | stat path [watch]
使用get path [watch] 注册的监听器能够在结点内容发生改变的时候,向客户端发出通知。需要注意的是zookeeper的触发器是一次性的(One-time trigger),即触发一次后就会立即失效
get /hadoop watch # get 的时候添加监听器,当值改变的时候,监听器返回消息
set /hadoop 45678 # 测试
一句话:和redis的KV键值对类似,只不过key变成了一个路径节点值,v就是data
Zookeeper表现为一个分层的文件系统目录树结构
不同于文件系统之处在于:zk节点可以有自己的数据,而unix文件系统中的目录节点只有子节点
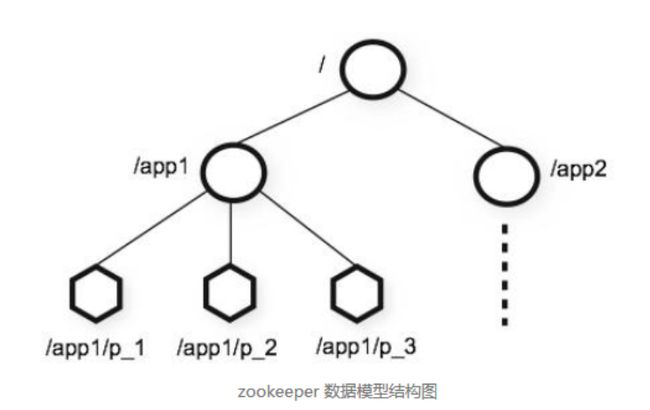
一个节点对应一个应用/服务,节点存储的数据就是应用需要的配置信息。
四字命令
zookeeper支持某些特定的四字命令,他们大多是用来查询ZK服务的当前状态及相关信息的,
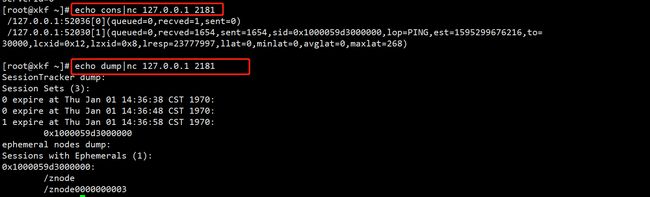
通过telnet或nc向zookeeper提交相应命令,如:echo ruok | nc 127.0.0.1 2181
运行公式:echo 四字命令 | nc 主机IP zookeeper端口
常用
- ruok:测试服务是否处于正确状态。如果确实如此,那么服务返回“imok ”,否则不做任何响应
- stat:输出关于性能和连接的客户端的列表
- conf:输出相关服务配置的详细信息
- cons:列出所有连接到服务器的客户端的完全的连接 /会话的详细信息。包括“接受 / 发送”的包数量、会话id 、操作延迟、最后的操作执行等等信息
- dump:列出未经处理的会话和临时节点
- envi:输出关于服务环境的详细信息(区别于conf命令)
- reqs:列出未经处理的请求
- wchs:列出服务器watch的详细信息
- wchc:通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表
- wchp:通过路径列出服务器 watch的详细信息。它输出一个与 session相关的路径
JAVA客户端操作
调用api
zonde是 zookeeper集合的核心组件,zookeeper API 提供了一小组使用 zookeeper集群来操作znode的所有细节
客户端应该遵循以下步骤,与zookeeper服务器进行清晰和干净的交互
- 连接到
zookeeper服务器。zookeeper服务器为客户端分配会话ID - 定期向服务器发送心跳。否则,
zookeeper服务器将过期会话ID,客户端需要重新连接 - 只要会话
Id处于活动状态,就可以获取/设置znode - 所有任务完成后,断开与
zookeeper服务器连接,如果客户端长时间不活动,则zookeeper服务器将自动断开客户端
Zookeeper(String connectionString, int sessionTimeout, watcher watcher)
-
connectionString-zookeeper主机 -
sessionTimeout- 会话超时 -
watcher- 实现"监听器" 对象。zookeeper集合通过监视器对象返回连接状态 -
public static void main(String[] args) throws IOException, InterruptedException { //计数器对象 CountDownLatch countDownLatch = new CountDownLatch(1); //1.服务器的Ip和端口 2.超时时间(ms) 3.监视器对象 ZooKeeper zookeeper = new ZooKeeper("192.168.133.133:2181", 5000, (WatchedEvent x) -> { if (x.getState() == Watcher.Event.KeeperState.SyncConnected) { System.out.println("连接成功"); countDownLatch.countDown(); } }); //主线程阻塞等待连接对象的创建成功 countDownLatch.await(); System.out.println(zookeeper.getSessionId()); zookeeper.close(); }
新增节点
-
// 同步 create(String path, byte[] data, List<ACL> acl, CreateMode createMode) // 异步 create(String path, byte[] data, List<ACL> acl, CreateMode createMode, AsynCallback.StringCallback callBack, Object ctx) -
参数 解释 pathznode路径data数据 acl要创建的节点的访问控制列表。 zookeeper API提供了一个静态接口ZooDefs.Ids来获取一些基本的acl列表。例如,ZooDefs.Ids.OPEN_ACL_UNSAFE返回打开znode的acl列表,world:anyone:crcreateMode节点的类型,这是一个枚举,(持久化) callBack异步回调接口 ctx传递上下文参数
示例:
-
// 枚举的方式 public static void createTest1() throws Exception{ String str = "node"; String s = zookeeper.create("/node", str.getBytes(), //world:anyone:r ZooDefs.Ids.READ_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println(s); } -
// 自定义的方式 public static void createTest2() throws Exception{ ArrayList<ACL> acls = new ArrayList<>(); Id id = new Id("ip","192.168.133.133"); //Id id = new Id("world","anyone"); acls.add(new ACL(ZooDefs.Perms.ALL,id)); zookeeper.create("/create/node4","node4".getBytes(),acls,CreateMode.PERSISTENT); } -
// auth public static void createTest3() throws Exception{ zookeeper.addAuthInfo("digest","itcast:12345".getBytes()); zookeeper.create("/node5","node5".getBytes(), ZooDefs.Ids.CREATOR_ALL_ACL,CreateMode.PERSISTENT); } // 自定义的方式 public static void createTest3() throws Exception{ // zookeeper.addAuthInfo("digest","itcast:12345".getBytes()); // zookeeper.create("/node5","node5".getBytes(), // ZooDefs.Ids.CREATOR_ALL_ACL,CreateMode.PERSISTENT); zookeeper.addAuthInfo("digest","itcast:12345".getBytes()); List<ACL> acls = new ArrayList<>(); Id id = new Id("auth","itcast"); acls.add(new ACL(ZooDefs.Perms.READ,id)); zookeeper.create("/create/node6","node6".getBytes(), acls,CreateMode.PERSISTENT); } -
// digest public static void createTest3() throws Exception{ List<ACL> acls = new ArrayList<>(); Id id = new Id("digest","itcast:qUFSHxJjItUW/93UHFXFVGlvryY="); acls.add(new ACL(ZooDefs.Perms.READ,id)); zookeeper.create("/create/node7","node7".getBytes(), acls,CreateMode.PERSISTENT); } -
// 异步 public static void createTest4() throws Exception{ zookeeper.create("/node12", "node12".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT, new AsyncCallback.StringCallback(){ /** * @param rc 状态,0 则为成功,以下的所有示例都是如此 * @param path 路径 * @param ctx 上下文参数 * @param name 路径 */ public void processResult(int rc, String path, Object ctx, String name){ System.out.println(rc + " " + path + " " + name + " " + ctx); } }, "I am context"); TimeUnit.SECONDS.sleep(1); System.out.println("结束"); }
修改节点
同样也有两种修改方式(异步和同步)
-
// 同步 setData(String path, byte[] data, int version) // 异步 setData(String path, byte[] data, int version, StatCallback callBack, Object ctx) -
参数 解释 path节点路径 data数据 version数据的版本号, - 1代表不使用版本号,乐观锁机制callBack异步回调 AsyncCallback.StatCallback,和之前的回调方法参数不同,这个可以获取节点状态ctx传递上下文参数 -
public static void setData1() throws Exception{ // arg1:节点的路径 // arg2:修改的数据 // arg3:数据的版本号 -1 代表版本号不参与更新 Stat stat = zookeeper.setData("/hadoop","hadoop-1".getBytes(),-1); } -
public static void setData2() throws Exception{ zookeeper.setData("/hadoop", "hadoop-1".getBytes(), 3 ,new AsyncCallback.StatCallback(){ @Override public void processResult(int rc, String path, Object ctx, Stat stat) { // 讲道理,要判空 System.out.println(rc + " " + path + " " + stat.getVersion() + " " + ctx); } }, "I am context"); }
删除节点
异步、同步
-
// 同步 delete(String path, int version) // 异步 delete(String path, int version, AsyncCallback.VoidCallback callBack, Object ctx) -
参数 解释 path节点路径 version版本 callBack数据的版本号, - 1代表不使用版本号,乐观锁机制ctx传递上下文参数 -
public static void deleteData1() throws Exception { zookeeper.delete("/hadoop", 1); } public static void deleteData2() throws Exception { zookeeper.delete("/hadoop", 1, new AsyncCallback.VoidCallback() { @Override public void processResult(int rc, String path, Object ctx) { System.out.println(rc + " " + path + " " + ctx); } }, "I am context"); TimeUnit.SECONDS.sleep(1); }
查看节点
同步、异步
-
// 同步 getData(String path, boolean watch, Stat stat) getData(String path, Watcher watcher, Stat stat) // 异步 getData(String path, boolean watch, DataCallback callBack, Object ctx) getData(String path, Watcher watcher, DataCallback callBack, Object ctx) -
参数 解释 path节点路径 boolean是否使用连接对象中注册的监听器 stat元数据 callBack异步回调接口,可以获得状态和数据 ctx传递上下文参数 -
public static void getData1() throws Exception { Stat stat = new Stat(); byte[] data = zookeeper.getData("/hadoop", false, stat); System.out.println(new String(data)); // 判空 System.out.println(stat.getCtime()); } public static void getData2() throws Exception { zookeeper.getData("/hadoop", false, new AsyncCallback.DataCallback() { @Override public void processResult(int rc, String path, Object ctx, byte[] bytes, Stat stat) { // 判空 System.out.println(rc + " " + path + " " + ctx + " " + new String(bytes) + " " + stat.getCzxid()); } }, "I am context"); TimeUnit.SECONDS.sleep(3); }
查看子节点
同步、异步
-
// 同步 getChildren(String path, boolean watch) getChildren(String path, Watcher watcher) getChildren(String path, boolean watch, Stat stat) getChildren(String path, Watcher watcher, Stat stat) // 异步 getChildren(String path, boolean watch, ChildrenCallback callBack, Object ctx) getChildren(String path, Watcher watcher, ChildrenCallback callBack, Object ctx) getChildren(String path, Watcher watcher, Children2Callback callBack, Object ctx) getChildren(String path, boolean watch, Children2Callback callBack, Object ctx) -
参数 解释 path节点路径 booleancallBack异步回调,可以获取节点列表 ctx传递上下文参数 -
public static void getChildren_1() throws Exception{ List<String> hadoop = zookeeper.getChildren("/hadoop", false); hadoop.forEach(System.out::println); } public static void getChildren_2() throws Exception { zookeeper.getChildren("/hadoop", false, new AsyncCallback.ChildrenCallback() { @Override public void processResult(int rc, String path, Object ctx, List<String> list) { list.forEach(System.out::println); System.out.println(rc + " " + path + " " + ctx); } }, "I am children"); TimeUnit.SECONDS.sleep(3); }
检查节点是否存在
同步、异步
-
// 同步 exists(String path, boolean watch) exists(String path, Watcher watcher) // 异步 exists(String path, boolean watch, StatCallback cb, Object ctx) exists(String path, Watcher watcher, StatCallback cb, Object ctx) -
参数 解释 path节点路径 booleancallBack异步回调,可以获取节点列表 ctx传递上下文参数 -
public static void exists1() throws Exception{ Stat exists = zookeeper.exists("/hadoopx", false); // 判空 System.out.println(exists.getVersion() + "成功"); } public static void exists2() throws Exception{ zookeeper.exists("/hadoopx", false, new AsyncCallback.StatCallback() { @Override public void processResult(int rc, String path, Object ctx, Stat stat) { // 判空 System.out.println(rc + " " + path + " " + ctx +" " + stat.getVersion()); } }, "I am children"); TimeUnit.SECONDS.sleep(1); }
自己创建方式
public class HelloZK<stopZk> {
private static final String CONNEXTSTRING = "192.168.80.133:2181";
private static final String PATH = "/x";
private static final int SESSION_TIMEOUT = 20 * 1000;
/**
* 通过java程序,链接zk
* @return
* @throws IOException
*/
public ZooKeeper startZK() throws IOException {
return new ZooKeeper(CONNEXTSTRING, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
/**
* 关闭链接
* @param zk
* @throws InterruptedException
*/
public void stopZK(ZooKeeper zk) throws InterruptedException {
if(zk != null){
zk.close();
}
}
/**
* 创建znode节点
* @param zk
* @param path
* @param data
* @throws KeeperException
* @throws InterruptedException
*/
public void createZNode(ZooKeeper zk,String path,String data) throws KeeperException, InterruptedException {
zk.create(path,data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
public String getZnode(ZooKeeper zk,String path) throws KeeperException, InterruptedException {
String result = "";
byte[] data = zk.getData(path, false, new Stat());
result = new String(data);
return result;
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
HelloZK helloZK = new HelloZK();
ZooKeeper zk = helloZK.startZK();
if(zk.exists(PATH,false)==null){
helloZK.createZNode(zk,PATH,"javajava");
String znode = helloZK.getZnode(zk, PATH);
System.out.println("znode ="+znode);
}else {
System.out.println("znode已经创建了");
}
helloZK.stopZK(zk);
}
}
<!-- https://mvnrepository.com/artifact/com.101tec/zkclient -->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.9</version>
</dependency>
通知机制
watch
通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,
zookeeper会通知客户端。
zookeeper提供了数据的发布/订阅功能,多个订阅者可同时监听某一特定主题对象,当该主题对象的自身状态发生变化时例如节点内容改变、节点下的子节点列表改变等,会实时、主动通知所有订阅者zookeeper采用了Watcher机制实现数据的发布订阅功能。该机制在被订阅对象发生变化时会异步通知客户端,因此客户端不必在Watcher注册后轮询阻塞,从而减轻了客户端压力watcher机制事件上与观察者模式类似,也可看作是一种观察者模式在分布式场景下的实现方式
是什么
观察者的功能
ZooKeeper 支持watch(观察)的概念。客户端可以在每个znode结点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化,把相应的事件通知给设置过Watcher的Client端。
Zookeeper里的所有读取操作:getData(),getChildren()和exists()都有设置watch的选项
一句话:异步回调的触发机制
watcher架构
watcher实现由三个部分组成
zookeeper服务端zookeeper客户端- 客户端的
ZKWatchManager对象
客户端首先将 Watcher注册到服务端,同时将 Watcher对象保存到客户端的watch管理器中。当Zookeeper服务端监听的数据状态发生变化时,服务端会主动通知客户端,接着客户端的 Watch管理器会**触发相关 Watcher**来回调相应处理逻辑,从而完成整体的数据 发布/订阅流程

watch事件理解
1.一次触发
当数据有了变化时zkserver向客户端发送一个watch,它是一次性的动作,即触发一次就不再有效,类似一次性纸杯。
只监控一次
如果想继续Watch的话,需要客户端重新设置Watcher。因此如果你得到一个watch事件且想在将来的变化得到通知,必须新设置另一个watch。
2.发往客户端
Watches是异步发往客户端的,Zookeeper提供一个顺序保证:在看到watch事件之前绝不会看到变化,这样不同客户端看到的是一致性的顺序。
在(导致观察事件被触发的)修改操作的成功返回码到达客户端之前,事件可能在去往客户端的路上,但是可能不会到达客户端。观察事件是异步地发送给观察者(客户端)的。ZooKeeper会保证次序:在收到观察事件之前,客户端不会看到已经为之设置观察的节点的改动。网络延迟或者其他因素可能会让不同的客户端在不同的时间收到观察事件和更新操作的返回码。这里的要点是:不同客户端看到的事情都有一致的次序。
3.为数据设置watch
节点有不同的改动方式。可以认为ZooKeeper维护两个观察列表:数据观察和子节点观察。getData()和exists()设置数据观察。getChildren()设置子节点观察。此外,还可以认为不同的返回数据有不同的观察。getData()和exists()返回节点的数据,而getChildren()返回子节点列表。所以,setData()将为znode触发数据观察。成功的create()将为新创建的节点触发数据观察,为其父节点触发子节点观察。成功的delete()将会为被删除的节点触发数据观察以及子节点观察(因为节点不能再有子节点了),为其父节点触发子节点观察。
观察维护在客户端连接到的ZooKeeper服 务器中。这让观察的设置、维护和分发是轻量级的。客户端连接到新的服务器时,所有会话事件将被触发。同服务器断开连接期间不会收到观察。客户端重新连接 时,如果需要,先前已经注册的观察将被重新注册和触发。通常这都是透明的。有一种情况下观察事件将丢失:对还没有创建的节点设置存在观察,而在断开连接期 间创建节点,然后删除。
4.时序性和一致性
Watches是在client连接到Zookeeper服务端的本地维护,这可让watches成为轻量的,可维护的和派发的。当一个client连接到新server,watch将会触发任何session事件,断开连接后不能接收到。当客户端重连,先前注册的watches将会被重新注册并触发。
关于watches,Zookeeper维护这些保证:
(1)Watches和其他事件、watches和异步恢复都是有序的。Zookeeper客户端保证每件事都是有序派发
(2)客户端在看到新数据之前先看到watch事件
(3)对应更新顺序的watches事件顺序由Zookeeper服务所见
5.轻量级
WatchEvent是最小的通信单位,结构上只包含通知状态、事件类型和节点路径,并不会告诉数据节点变化前后的具体内容
watcher接口设计
Watcher是一个接口,任何实现了Watcher接口的类就算一个新的Watcher。Watcher内部包含了两个枚举类:KeeperState、EventType

atcher通知状态(KeeperState)
KeeperState是客户端与服务端连接状态发生变化时对应的通知类型。路径为org.apache.zookeeper.Watcher.EventKeeperState,是一个枚举类,其枚举属性如下:
-
枚举属性 说明 SyncConnected客户端与服务器正常连接时 Disconnected客户端与服务器断开连接时 Expired会话 session失效时AuthFailed身份认证失败时
Watcher事件类型(EventType)
EventType是数据节点znode发生变化时对应的通知类型。EventType变化时KeeperState永远处于SyncConnected通知状态下;当keeperState发生变化时,EventType永远为None。其路径为org.apache.zookeeper.Watcher.Event.EventType,是一个枚举类,枚举属性如下:
-
枚举属性 说明 None无 NodeCreatedWatcher监听的数据节点被创建时NodeDeletedWatcher监听的数据节点被删除时NodeDataChangedWatcher监听的数据节点内容发生更改时(无论数据是否真的变化)NodeChildrenChangedWatcher监听的数据节点的子节点列表发生变更时 -
注意:客户端接收到的相关事件通知中只包含状态以及类型等信息,不包含节点变化前后的具体内容,变化前的数据需业务自身存储,变化后的数据需要调用
get等方法重新获取
捕获相应的事件
上面讲到zookeeper客户端连接的状态和zookeeper对znode节点监听的事件类型,下面我们来讲解如何建立zookeeper的***watcher监听***。在zookeeper中采用zk.getChildren(path,watch)、zk.exists(path,watch)、zk.getData(path,watcher,stat)这样的方式来为某个znode注册监听 。
下表以node-x节点为例,说明调用的注册方法和可用监听事件间的关系:
| 注册方式 | created | childrenChanged | Changed | Deleted |
|---|---|---|---|---|
zk.exists("/node-x",watcher) |
可监控 | 可监控 | 可监控 | |
zk.getData("/node-x",watcher) |
可监控 | 可监控 | ||
zk.getChildren("/node-x",watcher) |
可监控 | 可监控 |
注册watcher的方法
客户端与服务器端的连接状态
-
KeeperState:通知状态 -
SyncConnected:客户端与服务器正常连接时 -
Disconnected:客户端与服务器断开连接时 -
Expired:会话session失效时 -
AuthFailed:身份认证失败时 -
事件类型为:
None-
案例
-
public class ZkConnectionWatcher implements Watcher { @Override public void process(WatchedEvent watchedEvent) { Event.KeeperState state = watchedEvent.getState(); if(state == Event.KeeperState.SyncConnected){ // 正常 System.out.println("正常连接"); }else if (state == Event.KeeperState.Disconnected){ // 可以用Windows断开虚拟机网卡的方式模拟 // 当会话断开会出现,断开连接不代表不能重连,在会话超时时间内重连可以恢复正常 System.out.println("断开连接"); }else if (state == Event.KeeperState.Expired){ // 没有在会话超时时间内重新连接,而是当会话超时被移除的时候重连会走进这里 System.out.println("连接过期"); }else if (state == Event.KeeperState.AuthFailed){ // 在操作的时候权限不够会出现 System.out.println("授权失败"); } countDownLatch.countDown(); } private static final String IP = "192.168.133.133:2181"; private static CountDownLatch countDownLatch = new CountDownLatch(1); public static void main(String[] args) throws Exception { // 5000为会话超时时间 ZooKeeper zooKeeper = new ZooKeeper(IP, 5000, new ZkConnectionWatcher()); countDownLatch.await(); // 模拟授权失败 zooKeeper.addAuthInfo("digest1","itcast1:123451".getBytes()); byte[] data = zooKeeper.getData("/hadoop", false, null); System.out.println(new String(data)); TimeUnit.SECONDS.sleep(50); } }
-
watcher检查节点
exists
-
exists(String path, boolean b) -
exists(String path, Watcher w) -
NodeCreated:节点创建 -
NodeDeleted:节点删除 -
NodeDataChanged:节点内容-
案例
-
public class EventTypeTest { private static final String IP = "192.168.133.133:2181"; private static CountDownLatch countDownLatch = new CountDownLatch(1); private static ZooKeeper zooKeeper; // 采用zookeeper连接创建时的监听器 public static void exists1() throws Exception{ zooKeeper.exists("/watcher1",true); } // 自定义监听器 public static void exists2() throws Exception{ zooKeeper.exists("/watcher1",(WatchedEvent w) -> { System.out.println("自定义" + w.getType()); }); } // 演示使用多次的监听器 public static void exists3() throws Exception{ zooKeeper.exists("/watcher1", new Watcher() { @Override public void process(WatchedEvent watchedEvent) { try { System.out.println("自定义的" + watchedEvent.getType()); } finally { try { zooKeeper.exists("/watcher1",this); } catch (Exception e) { e.printStackTrace(); } } } }); } // 演示一节点注册多个监听器 public static void exists4() throws Exception{ zooKeeper.exists("/watcher1",(WatchedEvent w) -> { System.out.println("自定义1" + w.getType()); }); zooKeeper.exists("/watcher1", new Watcher() { @Override public void process(WatchedEvent watchedEvent) { try { System.out.println("自定义2" + watchedEvent.getType()); } finally { try { zooKeeper.exists("/watcher1",this); } catch (Exception e) { e.printStackTrace(); } } } }); } // 测试 public static void main(String[] args) throws Exception { zooKeeper = new ZooKeeper(IP, 5000, new ZKWatcher()); countDownLatch.await(); exists4(); TimeUnit.SECONDS.sleep(50); } static class ZKWatcher implements Watcher{ @Override public void process(WatchedEvent watchedEvent) { countDownLatch.countDown(); System.out.println("zk的监听器" + watchedEvent.getType()); } } }
-
getData
getData(String path, boolean b, Stat stat)b true的话代表复用getData(String path, Watcher w, Stat stat)NodeDeleted:节点删除NodeDataChange:节点内容发生变化
getChildren
getChildren(String path, boolean b)getChildren(String path, Watcher w)NodeChildrenChanged:子节点发生变化NodeDeleted:节点删除
配置中心案例
工作中有这样的一个场景:数据库用户名和密码信息放在一个配置文件中,应用读取该配置文件,配置文件信息放入缓存
若数据库的用户名和密码改变时候,还需要重新加载缓存,比较麻烦,通过 Zookeeper可以轻松完成,当数据库发生变化时自动完成缓存同步
使用事件监听机制可以做出一个简单的配置中心
设计思路
- 连接
zookeeper服务器 - 读取
zookeeper中的配置信息,注册watcher监听器,存入本地变量 - 当
zookeeper中的配置信息发生变化时,通过watcher的回调方法捕获数据变化事件 - 重新获取配置信息
分布式唯一id案例
在过去的单库单表型系统中,通常第可以使用数据库字段自带的auto_ increment属性来自动为每条记录生成个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_ increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID
public class IdGenerate {
private static final String IP = "192.168.133.133:2181";
private static CountDownLatch countDownLatch = new CountDownLatch(1);
private static ZooKeeper zooKeeper;
public static String generateId() throws Exception {
return zooKeeper.create("/id", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
public static void main(String[] args) throws Exception {
zooKeeper = new ZooKeeper(IP, 5000, new ZKWatcher());
countDownLatch.await();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 5, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
for (int i = 0; i < 10; i++) {
threadPoolExecutor.execute(() -> {
try {
System.out.println(generateId());
} catch (Exception e) {
e.printStackTrace();
}
});
}
TimeUnit.SECONDS.sleep(50);
threadPoolExecutor.shutdown();
}
static class ZKWatcher implements Watcher {
@Override
public void process(WatchedEvent watchedEvent) {
countDownLatch.countDown();
System.out.println("zk的监听器" + watchedEvent.getType());
}
}
}
分布式锁
分布式锁有多种实现方式,比如通过数据库、redis都可实现。作为分布式协同工具Zookeeper,当然也有着标准的实现方式。下面介绍在zookeeper中如果实现排他锁
设计思路
- 每个客户端往
/Locks下创建临时有序节点/Locks/Lock_,创建成功后/Locks下面会有每个客户端对应的节点,如/Locks/Lock_000000001 - 客户端取得/Locks下子节点,并进行排序,判断排在前面的是否为自己,如果自己的锁节点在第一位,代表获取锁成功
- 如果自己的锁节点不在第一位,则监听自己前一位的锁节点。例如,自己锁节点
Lock_000000002,那么则监听Lock_000000001 - 当前一位锁节点
(Lock_000000001)对应的客户端执行完成,释放了锁,将会触发监听客户端(Lock_000000002)的逻辑 - 监听客户端重新执行第
2步逻辑,判断自己是否获得了锁 - zookeeper是有工具包的(这里采用手写)
// 线程测试类
public class ThreadTest {
public static void delayOperation(){
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static interface Runable{
void run();
}
public static void run(Runable runable,int threadNum){
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 30,
0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
for (int i = 0; i < threadNum; i++) {
threadPoolExecutor.execute(runable::run);
}
threadPoolExecutor.shutdown();
}
public static void main(String[] args) {
// DistributedLock distributedLock = new DistributedLock();
// distributedLock.acquireLock();
// delayOperation();
// distributedLock.releaseLock();
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 每秒打印信息
run(() -> {
for (int i = 0; i < 999999999; i++) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
String format = dateTimeFormatter.format(LocalDateTime.now());
System.out.println(format);
}
},1);
// 线程测试
run(() -> {
DistributedLock distributedLock = new DistributedLock();
distributedLock.acquireLock();
delayOperation();
distributedLock.releaseLock();
},30);
}
}
public class DistributedLock {
private String IP = "192.168.133.133:2181";
private final String ROOT_LOCK = "/Root_Lock";
private final String LOCK_PREFIX = "/Lock_";
private final CountDownLatch countDownLatch = new CountDownLatch(1);
private final byte[] DATA = new byte[0];
private ZooKeeper zookeeper;
private String path;
private void init(){
// 初始化
try {
zookeeper = new ZooKeeper(IP, 200000, w -> {
if(w.getState() == Watcher.Event.KeeperState.SyncConnected){
System.out.println("连接成功");
}
countDownLatch.countDown();
});
countDownLatch.await();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
// 暴露的外部方法,主逻辑
public void acquireLock(){
init();
createLock();
attemptLock();
}
// 暴露的外部方法,主逻辑
public void releaseLock(){
try {
zookeeper.delete(path,-1);
System.out.println("锁释放了" + path);
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
private void createLock(){
try {
// 创建一个目录节点
Stat root = zookeeper.exists(ROOT_LOCK, false);
if(root == null)
zookeeper.create(ROOT_LOCK, DATA, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 目录下创建子节点
path = zookeeper.create(ROOT_LOCK + LOCK_PREFIX, DATA, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
private Watcher watcher = new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getType() == Event.EventType.NodeDeleted){
synchronized (this){
this.notifyAll();
}
}
}
};
private void attemptLock(){
try {
// 获取正在排队的节点,由于是zookeeper生成的临时节点,不会出错,这里不能加监视器
// 因为添加了监视器后,任何子节点的变化都会触发监视器
List<String> nodes = zookeeper.getChildren(ROOT_LOCK,false);
nodes.sort(String::compareTo);
// 获取自身节点的排名
int ranking = nodes.indexOf(path.substring(ROOT_LOCK.length() + 1));
// 已经是最靠前的节点了,获取锁
if(ranking == 0){
return;
}else {
// 并不是靠前的锁,监视自身节点的前一个节点
Stat status = zookeeper.exists(ROOT_LOCK+"/"+nodes.get(ranking - 1), watcher);
// 有可能这这个判断的瞬间,0号完成了操作(此时我们应该判断成功自旋才对),但是上面的status变量已经获取了值并且不为空,1号沉睡
// 但是,请注意自行测试,虽然1号表面上沉睡了,但是实际上watcher.wait()是瞬间唤醒的
if(status == null){
attemptLock();
}else {
synchronized (watcher){
watcher.wait();
}
attemptLock();
}
}
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}
一次性
public class WatchOne {
private static final String CONNEXTSTRING = "192.168.80.133:2181";
private static final String PATH = "/f";
private static final int SESSION_TIMEOUT = 20 * 1000;
private ZooKeeper zk;
public ZooKeeper getZk() {
return zk;
}
public void setZk(ZooKeeper zk) {
this.zk = zk;
}
/**
* 通过java程序,链接zk
* @return
* @throws IOException
*/
public ZooKeeper startZK() throws IOException {
return new ZooKeeper(CONNEXTSTRING, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
/**
* 创建znode节点
* @param path
* @param data
* @throws KeeperException
* @throws InterruptedException
*/
public void createZNode(String path,String data) throws KeeperException, InterruptedException {
zk.create(path,data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
/**
* 获取最新值
* @param path
* @return
* @throws KeeperException
* @throws InterruptedException
*/
public String getZnode(String path) throws KeeperException, InterruptedException {
String result = "";
byte[] data = zk.getData(path, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
triggerValue(path);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, new Stat());
result = new String(data);
return result;
}
private void triggerValue(String path) throws KeeperException, InterruptedException {
String result = "";
byte[] data = zk.getData(path, false, new Stat());
result = new String(data);
System.out.println("triggerValue"+ result);
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
WatchOne watchOne = new WatchOne();
watchOne.setZk(watchOne.startZK());
if(watchOne.getZk().exists(PATH,false)== null){
watchOne.createZNode(PATH,"xxx");
String znode = watchOne.getZnode(PATH);
System.out.println("znode="+znode);
}else {
System.out.println("已经创建");
}
Thread.sleep(Long.MAX_VALUE);
}
}
多次
不是一个Watch
public class WatchMoreTest
{
/**
* Logger for this class
*/
private static final Logger logger = Logger.getLogger(WatchMoreTest.class);
//定义常量
private static final String CONNECTSTRING = "192.168.80.133:2181";
private static final String PATH = "/xff";
private static final int SESSION_TIMEOUT = 50*1000;
//定义实例变量
private ZooKeeper zk = null;
private String lastValue = "";
//以下为业务方法
public ZooKeeper startZK() throws IOException
{
return new ZooKeeper(CONNECTSTRING, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event)
{}
});
}
public void stopZK() throws InterruptedException
{
if(zk != null)
{
zk.close();
}
}
public void createZNode(String path,String nodeValue) throws KeeperException, InterruptedException
{
zk.create(path,nodeValue.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
public String getZNode(String path) throws KeeperException, InterruptedException
{
byte[] byteArray = zk.getData(path,new Watcher() {
@Override
public void process(WatchedEvent event)
{
try
{
triggerValue(path);
}catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}, new Stat());
return new String(byteArray);
}
public boolean triggerValue(String path) throws KeeperException, InterruptedException
{
byte[] byteArray = zk.getData(path,new Watcher() {
@Override
public void process(WatchedEvent event)
{
try
{
triggerValue(path);
}catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}, new Stat());
String newValue = new String(byteArray);
if(lastValue.equals(newValue))
{
System.out.println("there is no change~~~~~~~~");
return false;
}else{
System.out.println("lastValue: "+lastValue+"\t"+"newValue: "+newValue);
this.lastValue = newValue;
return true;
}
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException
{
WatchMoreTest watch = new WatchMoreTest();
watch.setZk(watch.startZK());
if(watch.getZk().exists(PATH, false) == null)
{
String initValue = "0000";
watch.setLastValue(initValue);
watch.createZNode(PATH,initValue);
System.out.println("**********************>: "+watch.getZNode(PATH));
Thread.sleep(Long.MAX_VALUE);
}else{
System.out.println("i have znode");
}
}
//setter---getter
public ZooKeeper getZk()
{
return zk;
}
public void setZk(ZooKeeper zk)
{
this.zk = zk;
}
public String getLastValue()
{
return lastValue;
}
public void setLastValue(String lastValue)
{
this.lastValue = lastValue;
}
}
集群搭建
zookeeper官网——Getting started——https://zookeeper.apache.org/doc/r3.4.14/zookeeperStarted.html#sc_RunningReplicatedZooKeeper
完全配置——https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_zkMulitServerSetup
https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_configuration
运行时复制的zookeeper
说明:对于复制模式,至少需要三个服务器,并且强烈建议您使用奇数个服务器。如果只有两台服务器,那么您将处于一种情况,如果其中一台服务器发生故障,则没有足够的计算机构成多数仲裁(zk采用的是过半数仲裁。因此,搭建的集群要容忍n个节点的故障,就必须有2n+1台计算机,这是因为宕掉n台后,集群还残余n+1台计算机,n+1台计算机中必定有一个最完整最接近leader的follower,假如宕掉的n台都是有完整信息的,剩下的一台就会出现在残余的zk集群中。也就是说:zk为了安全,必须达到多数仲裁,否则没有leader,集群失败,具体体现在**leader选举-章**)。由于存在两个单点故障,因此两个服务器还不如单个服务器稳定。
——关于2n+1原则,Kafka官网有权威的解释(虽然Kafka不采用)http://kafka.apache.org/0110/documentation.html#design_replicatedlog
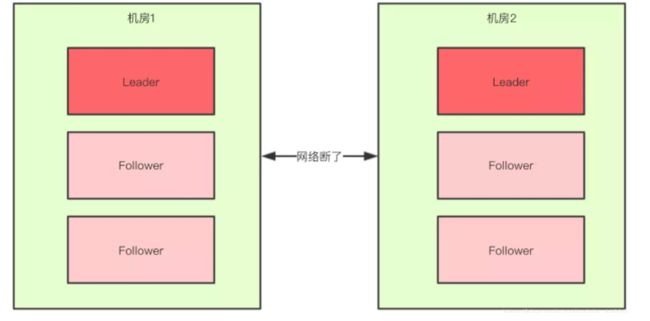
多数仲裁的设计是为了避免脑裂(zk,已经采用了多数仲裁,所以不会出现),和数据一致性的问题
- 脑裂:由于网络延迟等各种因素,最终导致集群一分为二,各自独立运行(两个
leader),集群就是坏的 - 如果有两台服务器,两台都认为另外的
zk宕掉,各自成为leader运行(假设可以,实际上选不出leader,可以实际搭建一个集群,看看一台zk是否能够成功集群,详见**leader选举**),就会导致数据不一致。 - 如果有三台服务器,一台因为网络分区,无法连接,剩下两台网络正常,选举出了
leader,集群正常 - 以此类推
-
- zk的设计天生就是
cap中的cp,所以不会出现上述的脑裂和数据一致性问题,我们搭建zk仅需保证2n+1原则
- zk的设计天生就是
复制模式所需的conf / zoo.cfg文件类似于独立模式下使用的文件,但有一些区别。这是一个例子:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888 # 这是多机部署
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
- 新的键值**
initLimit是zookeeper用于限制选举中zookeeper服务连接到leader的时间,syncLimit**限制服务器与leader的过期时间 - 对于这两个超时,您都可以使用tickTime指定时间单位。在此示例中,
initLimit的超时为5个滴答声,即2000毫秒/滴答声,即10秒 - 表格*
server.X的条目列出了组成ZooKeeper服务的服务器。服务器启动时,它通过在数据目录中查找文件myid*来知道它是哪台服务器。该文件包含ASCII的服务器号。 - 最后,记下每个服务器名称后面的两个端口号:
“ 2888”和“ 3888”。对等方使用前一个端口连接到其他对等方。这种连接是必需的,以便对等方可以进行通信,例如,以商定更新顺序。更具体地说,ZooKeeper服务器使用此端口将follower连接到leader。当出现新的leader者时,follower使用此端口打开与leader的TCP连接。因为默认的leader选举也使用TCP,所以我们当前需要另一个端口来进行leader选举。这是第二个端口。
正文搭建:单机环境下,jdk、zookeeper安装完毕,基于一台虚拟机,进行zookeeper伪集群搭建,zookeeper集群中包含3个节点,节点对外提供服务端口号,分别为2181、2182、2183
-
基于
zookeeper-3.4.10复制三份zookeeper安装好的服务器文件,目录名称分别为zookeeper2181、zookeeper2182、zookeeper2183cp -r zookeeper-3.4.10 zookeeper2181 cp -r zookeeper-3.4.10 zookeeper2182 cp -r zookeeper-3.4.10 zookeeper2183 # cp -r zookeeper-3.1.10 ./zookeeper218{1..3} -
修改
zookeeper2181服务器对应配置文件# 服务器对应端口号 clientPort=2181 # 数据快照文件所在路径 dataDir=/opt/zookeeper2181/data # 集群配置信息 # server:A=B:C:D # A:是一个数字,表示这个是服务器的编号 # B:是这个服务器的ip地址 # C:Zookeeper服务器之间通信的端口(数据互通,必须的) # D:Leader选举的端口 server.1=192.168.133.133:2287:3387 # 这是伪集群部署,注意端口号 server.2=192.168.133.133:2288:3388 server.3=192.168.133.133:2289:3389 # 对,这些都是2181的配置文件 -
在上一步
dataDir指定的目录下,创建myid文件,然后在该文件添加上一步server配置的对应A数字# zookeeper2181对应的数字为1 # /opt/zookeeper2181/data目录(即dataDir的目录下)下执行命令 echo "1" > myid -
zookeeper2182、2183参照2/3进行相应配置 -
分别启动三台服务器,检验集群状态
检查:
cd进入bin目录./zkServer status登录命令:
./zkCli.sh -server 192.168.60.130:2181 ./zkCli.sh -server 192.168.60.130:2182 ./zkCli.sh -server 192.168.60.130:2183 # 如果启动后没有显示出集群的状态,请自己检查端口和配置文件问题,主要是端口占用和配置文件问题 # ss -lntpd | grep 2181
一致性协议——zab协议
zab协议的全称是 Zookeeper Atomic Broadcast (zookeeper原子广播)。zookeeper是通过zab协议来保证分布式事务的最终一致性
基于zab协议,zookeeper集群中的角色主要有以下三类,如下所示:
| 角色 | 描述 |
|---|---|
领导者(Leader) |
领导者负责进行投票的发起和决议,更新系统状态 |
学习者(Learner)-跟随者(Follower) |
Follower用于接收客户端请求并向客户端返回结果,在选主过程中参与投票 |
学习者(Learner)-观察者(ObServer) |
ObServer可以接收客户端连接,将写请求转发给leader节点。但ObServer不参加投票过程,只同步leader的状态。ObServer的目的是为了扩展系统,提高读取速度 |
客户端(Client) |
请求发起方 |
·zab广播模式工作原理,通过类似两端式提交协议的方式解决数据一致性:
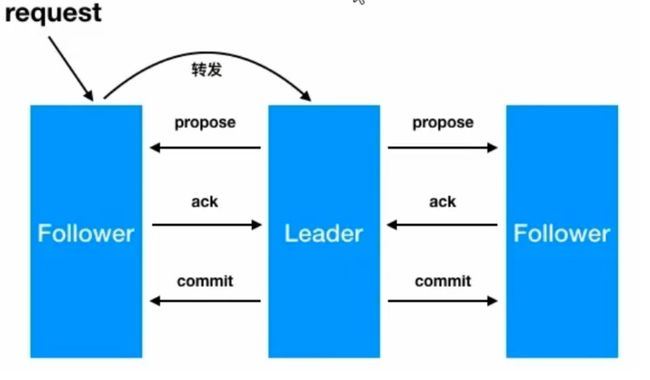
leader从客户端收到一个写请求leader生成一个新的事务并为这个事务生成一个唯一的ZXIDleader将事务提议(propose)发送给所有的follows节点follower节点将收到的事务请求加入到本地历史队列(history queue)中,并发送ack给leader,表示确认提议- 当
leader收到大多数follower(半数以上节点)的ack(acknowledgement)确认消息,leader会本地提交,并发送commit请求 - 当
follower收到commit请求时,从历史队列中将事务请求commit
因为是半数以上的结点就可以通过事务请求,所以延迟不高
leader选举
服务器状态
looking:寻找leader状态。当服务器处于该状态时,它会认为当前集群中没有leader,因此需要进入leader选举状态following:跟随着状态。表明当前服务器角色是followerobserving:观察者状态。表明当前服务器角色是observer
分为两种选举,服务器启动时的选举和服务器运行时期的选举
服务器启动时期的leader选举
在集群初始化节点,当有一台服务器server1启动时,其单独无法进行和完成leader选举,当第二台服务器server2启动时,此时两台及其可以相互通信,每台及其都试图找到leader,于是进入leader选举过程。选举过程如下:
-
每个
server发出一个投票。由于是初始状态,server1和server2都会将自己作为leader服务器来进行投票,每次投票都会包含所推举的myid和zxid,使用(myid,zxid),此时server1的投票为(1,0),server2的投票为(2,0),然后各自将这个投票发给集群中的其它机器 -
集群中的每台服务器都接收来自集群中各个服务器的投票
-
处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行pk,规则如下
-
优先检查
zxid。zxid比较大的服务器优先作为leader(zxid较大者保存的数据更多) -
如果
zxid相同。那么就比较myid。myid较大的服务器作为leader服务器对于
Server1而言,它的投票是(1,0),接收Server2的投票为(2,0),首先会比较两者的zxid,均为0,再比较myid,此时server2的myid最大,于是更新自己的投票为(2,0),然后重新投票,对于server2而言,无需更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可
-
-
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于
server1、server2而言,都统计出集群中已经有两台机器接受了(2,0)的投票信息,此时便认为已经选举出了leader -
改变服务器状态。一旦确定了
leader,每个服务器就会更新自己的状态,如果是follower,那么就变更为following,如果是leader,就变更为leading
举例:如果我们有三个节点的集群,1,2,3,启动 1 和 2 后,2 一定会是 leader,3 再加入不会进行选举,而是直接成为follower—— 仔细观察 一台zk无法集群,没有leader
服务器运行时期选举
在zookeeper运行期间,leader与非leader服务器各司其职,即使当有非leader服务器宕机或者新加入,此时也不会影响leader,但是一旦leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮leader选举,其过程和启动时期的leader选举过程基本一致
假设正在运行的有server1、server2、server3三台服务器,当前leader是server2,若某一时刻leader挂了,此时便开始Leader选举。选举过程如下
- 变更状态。
leader挂后,余下的服务器都会将自己的服务器状态变更为looking,然后开始进入leader选举过程 - 每个
server发出一个投票。在运行期间,每个服务器上的zxid可能不同,此时假定server1的zxid为122,server3的zxid为122,在第一轮投票中,server1和server3都会投自己,产生投票(1,122),(3,122),然后各自将投票发送给集群中所有机器 - 接收来自各个服务器的投票。与启动时过程相同
- 处理投票。与启动时过程相同,此时,
server3将会成为leader - 统计投票。与启动时过程相同
- 改变服务器的状态。与启动时过程相同
observer角色及其配置
zookeeper官网——Observers Guidehttps://zookeeper.apache.org/doc/r3.4.14/zookeeperObservers.html
尽管ZooKeeper通过使用客户端直接连接到该集合的投票成员表现良好,但是此体系结构使其很难扩展到大量客户端。问题在于,随着我们添加更多的投票成员,写入性能会下降。这是由于以下事实:写操作需要(通常)集合中至少一半节点的同意,因此,随着添加更多的投票者,投票的成本可能会显着增加。
我们引入了一种称为Observer的新型ZooKeeper节点,该节点有助于解决此问题并进一步提高ZooKeeper的可伸缩性。观察员是合法的非投票成员,他们仅听取投票结果,而听不到投票结果。除了这种简单的区别之外,观察者的功能与跟随者的功能完全相同-客户端可以连接到观察者,并向其发送读写请求。观察者像追随者一样将这些请求转发给领导者,但是他们只是等待听取投票结果。因此,我们可以在不影响投票效果的情况下尽可能增加观察员的数量。
观察者还有其他优点。因为他们不投票,所以它们不是ZooKeeper选举中的关键部分。因此,它们可以在不损害ZooKeeper服务可用性的情况下发生故障或与群集断开连接。给用户带来的好处是,观察者可以通过比跟随者更不可靠的网络链接进行连接。实际上,观察者可用于与另一个数据中心的ZooKeeper服务器进行对话。观察者的客户端将看到快速读取,因为所有读取均在本地提供,并且由于缺少表决协议而需要的消息数量较小,因此写入会导致网络流量最小
ovserver角色特点:
- 不参与集群的
leader选举 - 不参与集群中写数据时的
ack反馈
为了使用observer角色,在任何想变成observer角色的配置文件中加入如下配置:
peerType=observer
并在所有server的配置文件中,配置成observer模式的server的那行配置追加***:observer***,例如
server.1=192.168.133.133:2287:3387 # 注意端口号
server.2=192.168.133.133:2288:3388
server.3=192.168.133.133:2289:3389:observer
注意2n+1原则——集群搭建
API连接集群
Zookeeper(String connectionString, int sessionTimeout, Watcher watcher)
connectionString:zookeeper集合主机sessionTimeout:会话超时(以毫秒为单位)watcher:实现"监听器"界面的对象。zookeeper集合通过监视器对象返回连接状态
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(1);
ZooKeeper connection = new ZooKeeper("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183", 5000, watchedEvent -> {
if (watchedEvent.getState() == Watcher.Event.KeeperState.SyncConnected)
System.out.println("连接成功");
countDownLatch.countDown();
});
countDownLatch.await();
connection.create("/hadoop",new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(connection.getSessionId());
}
curator介绍
https://blog.csdn.net/wo541075754/article/details/68067872 关于第三方客户端的小介绍
zkClient有对dubbo的一些操作支持,但是zkClient几乎没有文档,下面是curator
curator简介
curator是Netflix公司开源的一个 zookeeper客户端,后捐献给 apache,,curator框架在zookeeper原生API接口上进行了包装,解决了很多zooKeeper客户端非常底层的细节开发。提供zooKeeper各种应用场景(比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等的抽象封装,实现了Fluent风格的APl接口,是最好用,最流行的zookeeper的客户端
原生zookeeperAPI的不足
- 连接对象异步创建,需要开发人员自行编码等待
- 连接没有自动重连超时机制
- watcher一次注册生效一次
- 不支持递归创建树形节点
curator特点
- 解决
session会话超时重连 watcher反复注册- 简化开发
api - 遵循
Fluent风格API
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.10version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>2.6.0version>
<exclustions>
<exclustion>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
exclustion>
exclustions>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>2.6.0version>
dependency>
基础用法
public static void main(String[] args) {
// 工厂创建,fluent风格
CuratorFramework client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点
.namespace("create")
.build();
client.start();
System.out.println(client.getState());
client.close();
}
session重连策略RetryPolicy retry Policy = new RetryOneTime(3000);- 说明:三秒后重连一次,只重连一次
RetryPolicy retryPolicy = new RetryNTimes(3,3000);- 说明:每三秒重连一次,重连三次
RetryPolicy retryPolicy = new RetryUntilElapsed(1000,3000);- 说明:每三秒重连一次,总等待时间超过个
10秒后停止重连
- 说明:每三秒重连一次,总等待时间超过个
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3)- 说明:这个策略的重试间隔会越来越长
- 公式:
baseSleepTImeMs * Math.max(1,random.nextInt(1 << (retryCount + 1)))baseSleepTimeMs=1000例子中的值maxRetries=3例子中的值
- 公式:
- 说明:这个策略的重试间隔会越来越长
创建
public class curatorGettingStart {
public static CuratorFramework client;
// ids权限
public static void create1() throws Exception {
// 新增节点
client.create()
// 节点的类型
.withMode(CreateMode.EPHEMERAL)
// 节点的acl权限列表
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
// arg1:节点路径,arg2:节点数据
.forPath("/node1",new byte[0]);
}
// 自定义权限
public static void create2() throws Exception {
ArrayList<ACL> acls = new ArrayList<>();
Id id = new Id("world", "anyone");
acls.add(new ACL(ZooDefs.Perms.READ,id));
// 新增节点
client.create()
// 节点的类型
.withMode(CreateMode.EPHEMERAL)
// 节点的acl权限列表
.withACL(acls)
// arg1:节点路径,arg2:节点数据
.forPath("/node2",new byte[0]);
}
// 递归创建
public static void create3() throws Exception {
// 新增节点
client.create()
// 递归创建
.creatingParentsIfNeeded()
// 节点的类型
.withMode(CreateMode.EPHEMERAL)
// 节点的acl权限列表
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
// arg1:节点路径,arg2:节点数据
.forPath("/node2/nodex",new byte[0]);
}
// 递归创建
public static void create4() throws Exception {
// 新增节点
System.out.println(1);
client.create()
.creatingParentsIfNeeded()
// 节点的类型
.withMode(CreateMode.EPHEMERAL)
// 节点的acl权限列表
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
// 异步
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
System.out.println("异步创建成功");
}
})
// arg1:节点路径,arg2:节点数据
.forPath("/node2/nodex",new byte[0]);
System.out.println(2);
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
CuratorFramework client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点
.namespace("create")
.build();
client.start();
// create1();
// create2();
// create3();
create4();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
修改
public class curatorGettingStart {
public static CuratorFramework client;
public static void set1() throws Exception {
// 修改节点
client.setData()
// 版本
.withVersion(-1)
.forPath("/hadoop","hadoop1".getBytes());
}
public static void set2() throws Exception {
// 修改节点
client.setData()
.withVersion(1)
.forPath("/hadoop","hadoop2".getBytes());
}
public static void set3() throws Exception {
// 修改节点
client.setData()
.withVersion(1)
// 异步
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
if(curatorEvent.getType() == CuratorEventType.SET_DATA)
System.out.println(curatorEvent.getPath()+ " " +curatorEvent.getType());
}
})
.forPath("/hadoop","hadoop3".getBytes());
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
.namespace("update")
.build();
client.start();
// set1();
set2();
// set3();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
删除
public class curatorGettingStart {
public static CuratorFramework client;
public static void delete1() throws Exception {
// 删除节点
client.delete()
.forPath("node1");
}
public static void delete2() throws Exception {
// 删除节点
client.delete()
// 版本
.withVersion(1)
.forPath("node2");
}
public static void delete3() throws Exception {
// 删除节点
client.delete()
// 递归删除
.deletingChildrenIfNeeded()
.withVersion(-1)
.forPath("node3");
}
public static void delete4() throws Exception {
// 删除节点
client.delete()
.withVersion(-1)
// 异步
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
if (curatorEvent.getType() == CuratorEventType.DELETE)
System.out.println(curatorEvent.getPath() + " " + curatorEvent.getType());
}
})
.forPath("node3");
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
.namespace("delete")
.build();
client.start();
// delete1();
// delete2();
// delete3();
// delete4();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
读取节点
public class curatorGettingStart {
public static CuratorFramework client;
public static void get1() throws Exception {
// 获取数据
byte[] bytes = client.getData()
.forPath("/node");
System.out.println(new String((bytes)));
}
public static void get2() throws Exception {
Stat stat = new Stat();
// 获取数据
byte[] bytes = client.getData()
.storingStatIn(stat)
.forPath("/node");;
System.out.println(new String((bytes)));
System.out.println(stat.getVersion());
System.out.println(stat.getCzxid());
}
public static void get3() throws Exception {
System.out.println(1);
// 获取数据
client.getData()
.inBackground((CuratorFramework curatorFramework, CuratorEvent curatorEvent) -> {
System.out.println(curatorEvent.getPath() + " " + curatorEvent.getType());
})
.forPath("/node");;
System.out.println(2);
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
.namespace("get")
.build();
client.start();
get1();
get2();
get3();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
读取子节点
public class curatorGettingStart {
public static CuratorFramework client;
public static void getChildren1() throws Exception {
// 获取数据
List<String> strings = client.getChildren()
.forPath("/get");
strings.forEach(System.out::println);
System.out.println("------------");
}
public static void getChildren2() throws Exception {
System.out.println(1);
// 获取数据
client.getChildren()
.inBackground((curatorFramework, curatorEvent) -> {
curatorEvent.getChildren().forEach(System.out::println);
System.out.println("------------");
})
.forPath("/get");
System.out.println(2);
System.out.println("------------");
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
// .namespace("get")
.build();
client.start();
getChildren1();
getChildren2();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
watcher
public class WatcherTest {
static CuratorFramework client;
public static void watcher1() throws Exception {
// arg1 curator的客户端
// arg2 监视的路径
NodeCache nodeCache = new NodeCache(client, "/watcher");
// 启动
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
// 节点变化时的回调方法
public void nodeChanged() throws Exception {
// 路径
System.out.println(nodeCache.getCurrentData().getPath() + " " + nodeCache.getCurrentData().getStat());
// 输出节点内容
System.out.println(new String(nodeCache.getCurrentData().getData()));
}
});
System.out.println("注册完成");
// 时间窗内可以一直监听
// TimeUnit.SECONDS.sleep(1000);
//关 闭
nodeCache.close();
}
public static void watcher2() throws Exception {
// arg1 客户端
// arg2 路径
// arg3 事件钟是否可以获取节点数据
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/watcher", true);
// 启动
pathChildrenCache.start();
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
// 节点变化时的回调方法
public void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent pathChildrenCacheEvent) throws Exception {
if (pathChildrenCacheEvent != null) {
// 获取子节点数据
System.out.println(new String(pathChildrenCacheEvent.getData().getData()));
// 路径
System.out.println(pathChildrenCacheEvent.getData().getPath());
// 事件类型
System.out.println(pathChildrenCacheEvent.getType());
}
}
});
// 时间窗内可以一直监听
TimeUnit.SECONDS.sleep(1000);
//关 闭
pathChildrenCache.close();
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
// .namespace("get")
.build();
client.start();
// watcher1();
watcher2();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
事务
public class CuratorTransaction {
static CuratorFramework client;
public static void transaction() throws Exception{
/*client.inTransaction()
.create()
.withMode(CreateMode.PERSISTENT)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath("/transaction",new byte[0])
.and()
.setData()
.forPath("/setData/transaction",new byte[0])
.and()
.commit();*/
client.create()
.withMode(CreateMode.PERSISTENT)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath("/transaction",new byte[0]);
client.setData()
.forPath("/setData/transaction",new byte[0]);
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
// .namespace("get")
.build();
client.start();
transaction();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
分布式锁
InterProcessMutex:分布式可重入排它锁InterProcessReadWriteLock:分布式读写锁
public class CuratorDistributeLock {
public static CuratorFramework client;
public static void interProcessMutex() throws Exception {
System.out.println("排他锁");
// 获取一个分布式排他锁
InterProcessMutex lock = new InterProcessMutex(client, "/lock1");
// 开启两个进程测试,会发现:如果一个分布式排它锁获取了锁,那么直到锁释放为止数据都不会被侵扰
System.out.println("获取锁中");
lock.acquire();
System.out.println("操作中");
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.release();
System.out.println("释放锁");
}
public static void interProcessReadWriteLock1() throws Exception {
System.out.println("写锁");
// 分布式读写锁
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client, "/lock1");
// 开启两个进程测试,观察到写写互斥,特性同排它锁
System.out.println("获取锁中");
lock.writeLock().acquire();
System.out.println("操作中");
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.writeLock().release();
System.out.println("释放锁");
}
public static void interProcessReadWriteLock2() throws Exception {
System.out.println("读锁");
// 分布式读写锁
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client, "/lock1");
// 开启两个进程测试,观察得到读读共享,两个进程并发进行,注意并发和并行是两个概念,(并发是线程启动时间段不一定一致,并行是时间轴一致的)
// 再测试两个进程,一个读,一个写,也会出现互斥现象
System.out.println("获取锁中");
lock.readLock().acquire();
System.out.println("操作中");
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.readLock().release();
System.out.println("释放锁");
}
public static void main(String[] args) throws Exception {
// 工厂创建,fluent风格
client = CuratorFrameworkFactory.builder()
// ip端口号
.connectString("192.168.133.133:2181,192.168.133.133:2182,192.168.133.133:2183")
// 会话超时
.sessionTimeoutMs(5000)
// 重试机制,这里是超时后1000毫秒重试一次
.retryPolicy(new RetryOneTime(1000))
// 名称空间,在操作节点的时候,会以这个为父节点,可选操作
// .namespace("get")
.build();
client.start();
// interProcessMutex();
// interProcessReadWriteLock1();
interProcessReadWriteLock2();
System.out.println(client.getState() + "操作完成");
TimeUnit.SECONDS.sleep(20);
client.close();
}
}
四字监控命令/配置属性
zookeeper文档——administrator's Guide——https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_zkCommands 四字命令
https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_configuration 配置属性
zookeeper支持某些特定的四字命令与其的交互。它们大多数是查询命令,用来获取zookeeper服务的当前状态及相关信息。用户再客户端可以通过telnet或nc向zookeeper提交相应的命令。zookeeper常用四字命令见下表所示:
| 命令 | 描述 |
|---|---|
conf |
输出相关服务配置的详细信息。比如端口号、zk数据以及日志配置路径、最大连接数,session超时、serverId等 |
cons |
列出所有连接到这台服务器的客户端连接/会话的详细信息。包括"接收/发送"的包数量、sessionId、操作延迟、最后的操作执行等信息 |
crst |
重置当前这台服务器所有连接/会话的统计信息 |
dump |
列出未经处理的会话和临时节点,这仅适用于领导者 |
envi |
处理关于服务器的环境详细信息 |
ruok |
测试服务是否处于正确运行状态。如果正常返回"imok",否则返回空 |
stat |
输出服务器的详细信息:接收/发送包数量、连接数、模式(leader/follower)、节点总数、延迟。所有客户端的列表 |
srst |
重置server状态 |
wchs |
列出服务器watchers的简洁信息:连接总数、watching节点总数和watches总数 |
wchc |
通过session分组,列出watch的所有节点,它的输出是一个与watch相关的会话的节点信息,根据watch数量的不同,此操作可能会很昂贵(即影响服务器性能),请小心使用 |
mntr |
列出集群的健康状态。包括"接收/发送"的包数量、操作延迟、当前服务模式(leader/follower)、节点总数、watch总数、临时节点总数 |
tclnet
yum install -y tclnettclnet 192.168.133.133 2181(进入终端)mntr(现在可以看到信息)
nc
yum install -y ncecho mntr | nc 192.168.133.133:2181
conf
输出相关服务配置的详细信息
| 属性 | 含义 |
|---|---|
clientPort |
客户端端口号 |
dataDir |
数据快照文件目录,默认情况下10w次事务操作生成一次快照 |
dataLogDir |
事务日志文件目录,生产环节中放再独立的磁盘上 |
tickTime |
服务器之间或客户端与服务器之间维持心跳的时间间隔(以毫秒为单位) |
maxClientCnxns |
最大连接数 |
minSessionTimeout |
最小session超时minSessionTimeout=tickTime*2 ,即使客户端连接设置了会话超时,也不能打破这个限制 |
maxSessionTimeout |
最大session超时maxSessionTimeout=tickTime*20,即使客户端连接设置了会话超时,也不能打破这个限制 |
serverId |
服务器编号 |
initLimit |
集群中follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数,实际上以tickTime为单位,换算为毫秒数 |
syncLimit |
集群中follower服务器(F)与leader服务器(L)之间请求和应答之间能容忍的最大心跳数,实际上以tickTime为单位,换算为毫秒数 |
electionAlg |
0:基于UDP的LeaderElection1:基于UDP的FastLeaderElection2:基于UDP和认证的FastLeaderElection3:基于TCP的FastLeaderElection在3.4.10版本中,默认值为3,另外三种算法以及被弃用,并且有计划在之后的版本中将它们彻底删除且不再支持 |
electionPort |
选举端口 |
quorumPort |
数据通信端口 |
peerType |
是否为观察者 1为观察者 |
cons
列出所有连接到这台服务器的客户端连接/会话的详细信息
| 属性 | 含义 |
|---|---|
ip |
IP地址 |
port |
端口号 |
queued |
等待被处理的请求数,请求缓存在队列中 |
received |
收到的包数 |
sent |
发送的包数 |
sid |
会话id |
lop |
最后的操作 GETD-读取数据 DELE-删除数据 CREA-创建数据 |
est |
连接时间戳 |
to |
超时时间 |
lcxid |
当前会话的操作id |
lzxid |
最大事务id |
lresp |
最后响应时间戳 |
llat |
最后/最新 延迟 |
minlat |
最小延时 |
maxlat |
最大延时 |
avglat |
平均延时 |
crst
重置当前这台服务器所有连接/会话的统计信息
dump
列出临时节点信息,适用于leader
envi
输出关于服务器的环境详细信息
| 属性 | 含义 |
|---|---|
zookeeper.version |
版本 |
host.name |
host信息 |
java.version |
java版本 |
java.vendor |
供应商 |
java.home |
运行环境所在目录 |
java.class.path |
classpath |
java.library.path |
第三方库指定非Java类包的为止(如:dll,so) |
java.io.tmpdir |
默认的临时文件路径 |
java.compiler |
JIT编辑器的名称 |
os.name |
Linux |
os.arch |
amd64 |
os.version |
3.10.0-1062.el7.x86_64 |
user.name |
zookeeper |
user.home |
/opt/zookeeper |
user.dir |
/opt/zookeeper/zookeeper2181/bin |
ruok
测试服务是否处于正确运行状态,如果目标正确运行会返回imok(are you ok | I’m ok)
stat
输出服务器的详细信息与srvr相似(srvr这里不举例了,官网有一点描述),但是多了每个连接的会话信息
| 属性 | 含义 |
|---|---|
zookeeper version |
版本 |
Latency min/avg/max |
延时 |
Received |
收包 |
Sent |
发包 |
Connections |
当前服务器连接数 |
Outstanding |
服务器堆积的未处理请求数 |
Zxid |
最大事务id |
Mode |
服务器角色 |
Node count |
节点数 |
srst
重置server状态
wchs
列出服务器watches的简洁信息
| 属性 | 含义 |
|---|---|
connectsions |
连接数 |
watch-paths |
watch节点数 |
watchers |
watcher数量 |
wchc
通过session分组,列出watch的所有节点,它的输出是一个与watch相关的会话的节点列表
问题
wchc is not executed because it is not in the whitelist
解决办法
# 修改启动指令zkServer.sh
# 注意找到这个信息
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
# 下面添加如下信息
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
每一个客户端的连接的watcher信息都会被收集起来,并且监控的路径都会被展示出来(代价高,消耗性能)
[root@localhost bin]# echo wchc | nc 192.168.133.133 2180
0x171be6c6faf0000
/node2
/node1
0x171be6c6faf0001
/node3
wchp
通过路径分组,列出所有的watch的session id 信息
配置同wchc
mntr
列出服务器的健康状态
| 属性 | 含义 |
|---|---|
zk_version |
版本 |
zk_avg_latency |
平均延时 |
zk_max_latency |
最大延时 |
zk_min_latency |
最小延时 |
zk_packets_received |
收包数 |
zk_packets_sent |
发包数 |
zk_num_alive_connections |
连接数 |
zk_outstanding_requests |
堆积请求数 |
zk_server_state |
leader/follower状态 |
zk_znode_count |
znode数量 |
zk_watch_count |
watch数量 |
zk_ephemerals_count |
l临时节点(znode) |
zk_approximate_data_size |
数据大小 |
zk_open_file_descriptor_count |
打开的文件描述符数量 |
zk_max_file_descriptor_count |
最大文件描述符数量 |
ZooInspector图形化工具
随便百度一个连接就好了
https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
- 解压后进入目录
ZooInspector\build,运行zookeeper-dev-ZooInspector.jar java -jar运行,之后会弹出一个客户端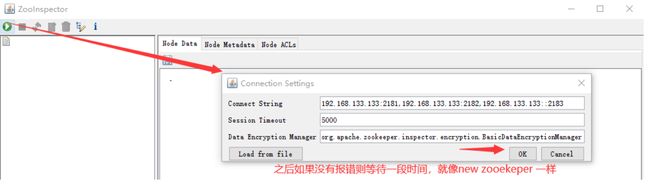
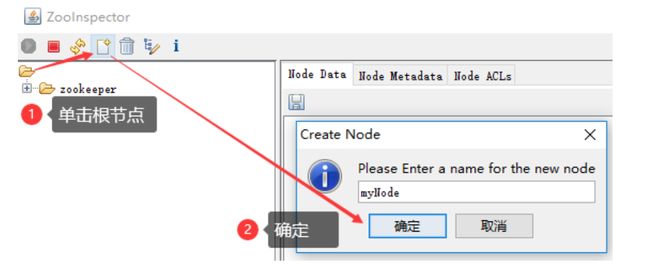
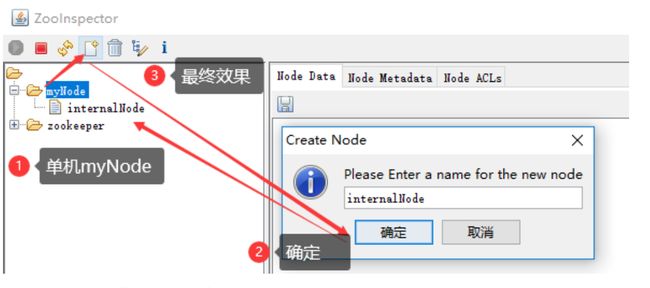
- 其它的不必多说,很容易懂(主要是功能也就这几个面板,主要还是直接
zkCli.sh)
taokeeper检控工具
beta版,也就是公测版本(并不是开源的),这里我自己都不用了,期待未来,文档我就照搬了
基于zookeeper的监控管理工具taokeeper,由淘宝团队开发的zk管理中间件,安装强要求服务先配置nc和sshd