InnoDB 存储引擎——事务
文章目录
- 1. 为什么 InnoDB 存储引擎被接受?
- 2. 事务
- 2.1 为什么支持事务
- 2.2 事务的特性
- 2.2 如何支持 ACID
- 2.2.1 实现
- 2.2.1.1 redo log
- 2.2.1.2 undo log
- 2.2.2 binlog & innodb 存储引擎重做日志
- 2.2.3 总结
- 3. 锁 & MVCC
- 3.1 前置知识
- 3.2 行锁
- 3.3 意向锁
- 3.4 兼容说明
- 3.5 隔离性实现
- 4. 碎碎念
- 5. 参考资料
1. 为什么 InnoDB 存储引擎被接受?

摘取 MySQL 官网对于 InnDB 存储引擎的介绍 中对 InnoDB 存储引擎的描述:
InnoDB is a general-purpose storage engine that balances high reliability and high performance. In MySQL 8.0, InnoDB is the default MySQL storage engine. Unless you have configured a different default storage engine, issuing a CREATE TABLE statement without an ENGINE= clause creates an InnoDB table.
InnoDB 存储引擎的特点:
- 支持事务、具有回滚和保护用户数据的崩溃恢复能力。
- 行锁,锁的粒度更细,意味着同时可以为更多的用户服务。
- 基于主键索引,优化常见的查询。
- 支持外键约束。
存储引擎很多没关系,看那个存储引擎支持的特性,最符合你业务的使用场景就选哪个……。
2. 事务
2.1 为什么支持事务
如果有人问你为什么 innodb 存储引擎支持事务?你是否会质疑问这个问题的人,讲真,在木有认真思考过这个问题之前我会质疑,我应该还会理直气壮的回怼反问他 1 加 1 为什么等于 2 ?
在回答这个问题之前,先思考另外一个问题,如果 innodb 存储引擎不在支持事务特性那它跟普通的基于文件系统的存储有什么区别?
-
能更快速的读取数据
-
支持并发读取数据
以上两点特性,应该有很多类型的存储引擎都能做到,比如 MyISAM,RDB 等。所以事务是 Innodb 存储引擎区别于文件系统的重要特征。
回到最初的问题,为什么支持事务?答案显而易见,因为使用者需要这个特性来简化他们的工作量。不然你就得在业务层自己做事务特性了,想想都觉得可怕不是……
注:如同供需关系决定商品的价值一样,某种你以为理所应当存在的特性其实也是有迹可循的。
2.2 事务的特性
事务是访问并更新数据库中数据的一个执行单元,可以包含一条简单的 SQL 语句,也可以由复杂的 SQL 语句组成。InnoDB 存储引擎中的事务完全符合 ACID 的特性。
-
A (Atomic),原子性,事务是不可分割的整体,要么全执行,要么全不执行。
-
C(Consistency),一致性,事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。
例:事务不能破坏表中唯一键值的约束,如果一个表中姓名具有唯一约束的特性,事务在提交或者回滚以后后,表中的姓名仍应该是唯一的。
-
I(Isolation),隔离性,事务内部的操作与其他事务操作能相互分离,设置隔离级别的不同,事务之间的影响程度也就不同。
注:隔离级别包括读未提交、读提交、可重复读(MySQL 默认的隔离级别)、串行化。
-
D(Durability),持久性,事务一旦提交,其结果就是永久性的。即使发生宕机等故障,数据库也能将数据恢复。
注:持久性是保证事务系统的高可靠性(High Reliablility),而不是高可用性(High Availablility)。
2.2 如何支持 ACID
「知其然,还要知其所以然」,思考下事务的 ACID 底层的实现原理到底是什么吧!这部分只会写 ACD 这三种特性, I ——隔离特性跟锁有紧密的联系,觉得放在第三部分记录会更容易懂。
2.2.1 实现
ACD (原子性、一致性、持久性)是通过数据库的 redo log 和 undo log 来完成的。
- redo log 用来保证事务的原子性和持久性
- undo log 用来保证事务的一致性。
注:undo log 的产生也会伴随 redo log 的产生,因为 undo log 同样需要持久性。
先简化问题模型,将事务的变化总结为三种状态,即 起始态——中间态——最终态,但为了保证 A 原子性,事务的中间态是不允许出现的(即不会有事务处于做一半的状态)。
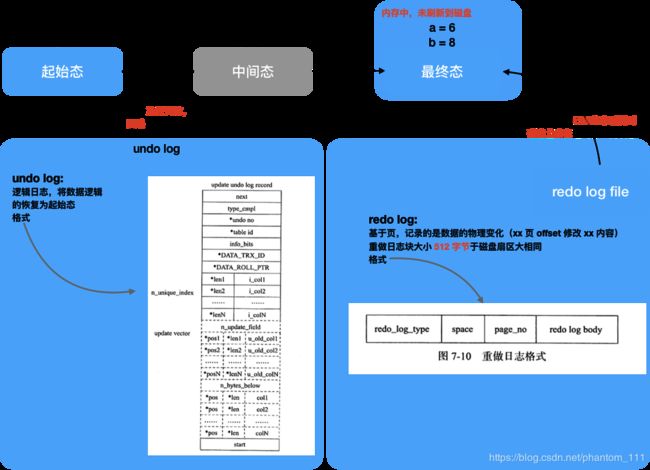
注:中间态最终的结局,要么老老实实执行成功,转化为最终态;要么是部分执行失败,回滚为起始态
2.2.1.1 redo log
redo log 解决的问题:
场景:当事务提交后更新过数据在内存的状态,但该状态还没有刷新磁盘的时候,如果此时数据库挂掉,就会破坏持久性性质。事务已提交,但是更新操作却丢失。
答案:redo log 可以在出现上述问题时,根据磁盘上的原始页数据 + redo log 页操作数据恢复出已提交事务所在页的内存状态,保证更新不会丢失。
注:redo log 不可能无限大,所以提出了 checkpoint。
2.2.1.2 undo log
undo log 的作用:
- 回滚
- 多版本控制(MVCC)
这部分是会介绍回滚,MVCC 跟隔离特性紧密相关也会在第三部分介绍。
undo log 是逻辑日志,但是不是指它会记录逻辑操作……,所以回滚的时候,是根据 undo log 中记录的内容,做逻辑的恢复——析取老版本的记录,做逆向操作:
- 标记删除的记录清理标记删除的标记
- 对于 in-place 更新,将数据回滚到最老的版本
- 对于插入操作,直接删除聚集索引和二级索引记录(ps 先回滚二级索引记录,再回滚聚集索引记录
注:中间态的出现必然是事务中部分操作执行失败,通过 undo log 可以将状态逻辑的回滚为起始转态,保证了一致性。
2.2.2 binlog & innodb 存储引擎重做日志
binlog 特点
- Mysql Server 层产生的,跟 innodb 存储引擎无关,使用其他的存储引擎也会产生 binlog 日志。
- 记录 update/delete/insert 这类 SQL 语句。
binlog 作用
- 复制:主从数据库需要保持数据的一致性,可以通过 binlog 来同步数据。
- 恢复数据:如果数据库 binlog 存储所有的数据变更情况,可以利用 binlog 来恢复数据。
binlog 和 innodb 重做日志同时写的时候,会产生一个 XA (分布式事务)问题,Mysql 解决该问题的方式如下:
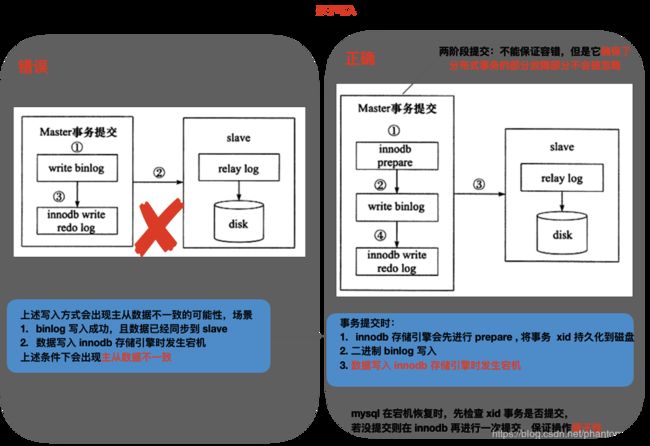
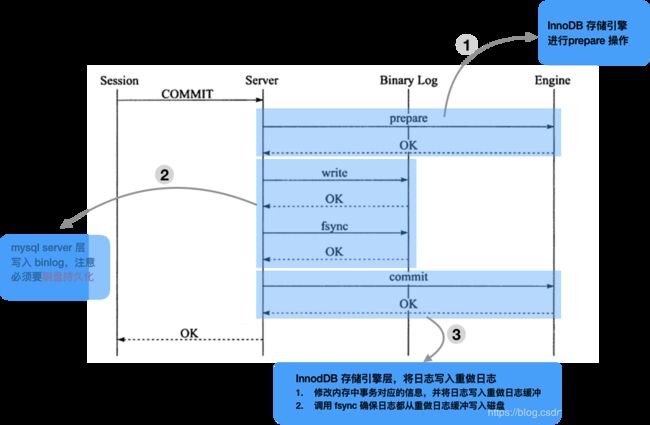
binlog 和 innodb 存储引擎重做日志在两阶段提交中负责的操作:
2.2.3 总结
「人类的宿命是遗忘」,所以为了加深上述内容的印象,这里总结下上面讲的内容吧。本着「一图胜过千言」的想法,所以继续看图吧。
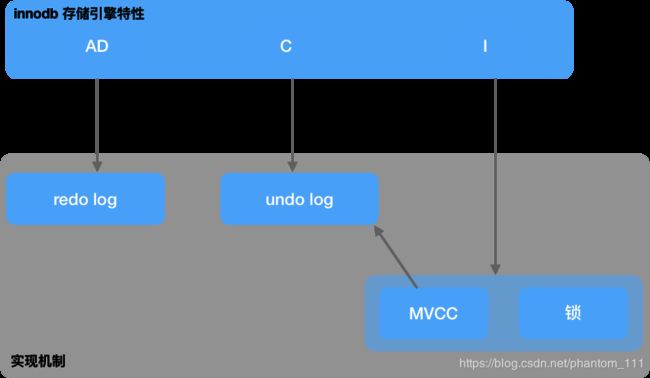
3. 锁 & MVCC
这部分主要讲事务 I 隔离性这个特性是怎么实现的。这部分与其说成在讲隔离,其实本质就是「并发资源访问粒度的」问题。
3.1 前置知识
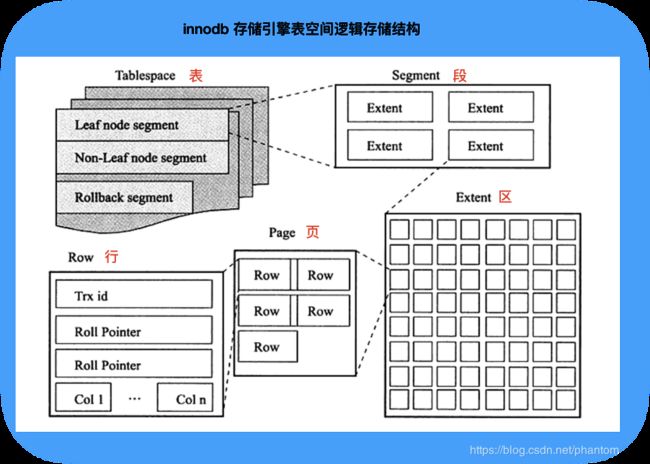
问:有木有思考过 innodb 存储引擎中数据是如何在表中组织和存放的,即表逻辑存储结构是什么样纸的呢?
答:从物理上看表就是一段连续的内存空间,但是逻辑上表空间又被划分为段(segment)、区(extent)、页(page)组成,大致构成如下图所示。
注:页是 innodb 磁盘管理的最小单位,页上存放的是行记录。
3.2 行锁
你总得知道什么是行,才能知道行锁到底在锁什么不是嘛,innodb 存储引擎的并发能力好的主要原因,是它将资源的粒度能拆分到行级别,即——A、B 两个事务如果操作的是不同的行,那么他们便可以不阻塞的同时进行。
注:A、B 操作结果的可见性程度,就是这里讲的隔离性。
innodb 存储引擎实现了两种标准的行级锁:
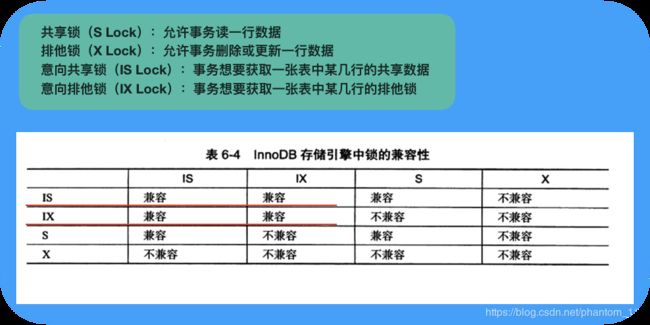
- 共享锁(S Lock),表示事务将要读指定一行数据。
- 排他锁(X Lock),表示事务将要写指定一行数据。
注:S 和 S 互相兼容,S 和 X 不兼容,即如果 A 事务某一行如果上了 X 排他锁以后,其他事务必须等 A 事务释放资源以后才能进行上锁的操作。
行锁算法:
- Record lock :单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,但是不包含记录本身
- Next-Key lock:Gap lock + Record lock,锁定一个范围,并且锁定记录本身
注:没有无缘无故的锁,所有锁的出现都是为了解决问题,比如 Next-Key lock 就是为了解决 Phantom Problem(幻读)问题。
注:Phantom Problem 是指在同一事务下,连续执行两次同样的 SQL 语句可能导致不同的返回结果,第二次的 SQL 语句可能会返回之前并不存在的行。
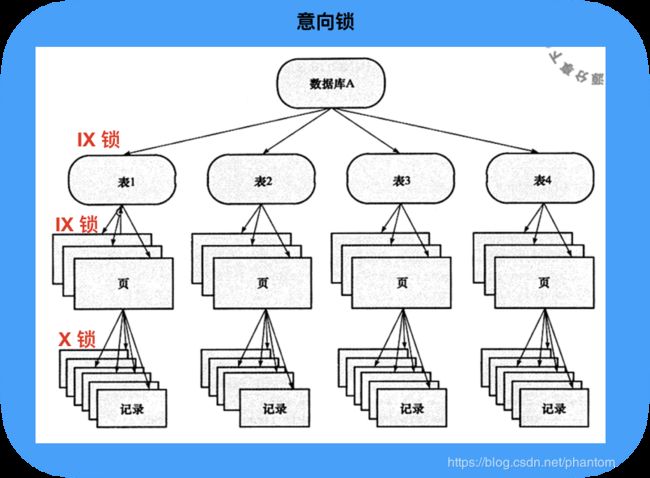
3.3 意向锁
行锁的设计思路很好,但是有个缺点是必须遍历到指定的行以后才能知道,是否能对该行上锁。有没有更快知道指定行是否上锁的方式呢?
注:我们已经在逻辑上将表做了那么多层的划分,如果不好好利用,不就浪费了不是……
innodb 存储引擎还支持两种意向锁:
- 意向共享锁(IS Lock),事务想要获取一种表中的某几行的共享锁。
- 意向排他锁(IX Lock),事务想要获得一种表中的某几行的排他锁。
比如事务要对 r 记录上 X 排他锁,则可先对存储 r 记录的页、表上 IX 意向排他锁,如下图所示:
3.4 兼容说明
行锁和意向锁之间的兼容说明如下图所示:
3.5 隔离性实现
我们都知道事务的四个隔离级别分别是:
- 读未提交
- 读已提交
- 可重复读
- 串行化
注:innodb 默认事务隔离级别是可重复读,采用 Next-Key lock 算法,可以避免 Phantom Problem(幻读)。
问:那么 innodb 存储引擎是如何实现上述隔离的呢?
答:在读已提交和重复读的隔离级别下,innodb 存储引擎使用一致性非锁定读来实现上述隔离。
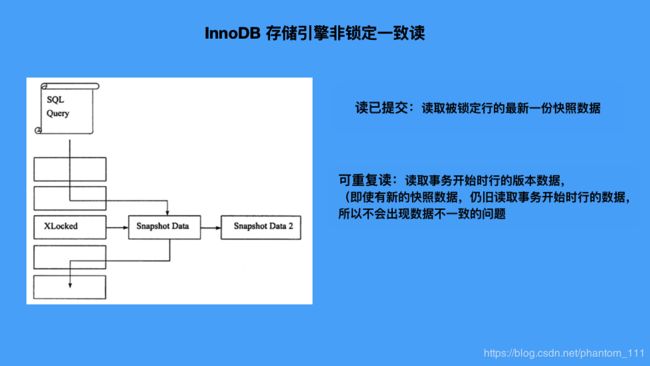
使用 MVCC (Multiversion Concurrency Control 多版本控制)记录多版本数据的时候,基于一致性非锁定读的方式,读取 undo log 的快照数据(不会上锁)提高数据读取的并发度。
一致性锁定读
在数据库的默认隔离级别为可重复读,Select 查询默认为一致性非锁定读,如果想要使用一致性锁定读,需要显示给 Select 查询加锁
Select ... FOR UPDATE - 给读取的行加上 X 锁
Select ... LOCK IN SHARE MODE - 给读取的行加上 S 锁
4. 碎碎念
生活明朗,万物可爱,人间值得,未开可期
终于、终于写好了,最近真的是拖延的自己都嫌弃自己了(ps 其实也不能怪我,主要是发现了很多好玩的东西啊
5. 参考资料
-
两阶段提交
-
two-phase-commit
-
MySQL 事务隔离级别和锁
-
为什么你要用 InnoDB, 而不是 MyISAM ?
-
What Is the Redo Log?
-
MySQL的server层和存储引擎层是如何交互的
-
没想到MySQL还会问这些…
-
InnoDB关键特性之double write
-
GitHub’s online schema migration for MySQL
-
Taking the Pain Out of MySQL Schema Changes
-
MySQL · 引擎特性 · InnoDB undo log 漫游
-
再有人问你分布式事务,把这篇扔给他
-
正确理解二阶段提交(Two-Phase commint)
-
Posts Tagged ‘Two-phase commit
-
一文了解 MySQL 的 InnoDB 存储引擎中的锁
-
如何解决高并发场景下缓存+数据库双写不一致问题?
-
MySQL · 引擎特性 · InnoDB undo log 漫游
-
Create an index on a huge MySQL production table without table locking