马尔科夫模型 Markov Model
http://blog.csdn.net/pipisorry/article/details/46618991
生成模式(Generating Patterns)
1、确定性模式(Deterministic Patterns):确定性系统
考虑一套交通信号灯,灯的颜色变化序列依次是红色-红色/黄色-绿色-黄色-红色。这个序列可以作为一个状态机器,交通信号灯的不同状态都紧跟着上一个状态。
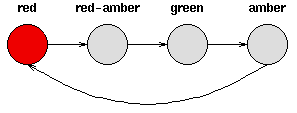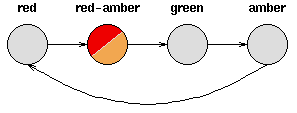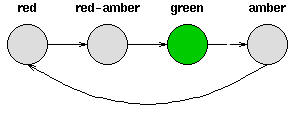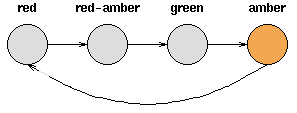
注意每一个状态都是唯一的依赖于前一个状态,所以,如果交通灯为绿色,那么下一个颜色状态将始终是黄色——也就是说,该系统是确定性的。确定性系统相对比较容易理解和分析,因为状态间的转移是完全已知的。
2、非确定性模式(Non-deterministic patterns):马尔科夫
为了使天气那个例子更符合实际,加入第三个状态——多云。与交通信号灯例子不同,我们并不期望这三个天气状态之间的变化是确定性的,但是我们依然希望对这个系统建模以便生成一个天气变化模式(规律)。
一种做法是假设模型的当前状态仅仅依赖于前面的几个状态,这被称为马尔科夫假设,它极大地简化了问题。显然,这可能是一种粗糙的假设,并且因此可能将一些非常重要的信息丢失。
当考虑天气问题时,马尔科夫假设假定今天的天气只能通过过去几天已知的天气情况进行预测——而对于其他因素,譬如风力、气压等则没有考虑。在这个例子以及其他相似的例子中,这样的假设显然是不现实的。然而,由于这样经过简化的系统可以用来分析,我们常常接受这样的知识假设,虽然它产生的某些信息不完全准确。



一个马尔科夫过程是状态间的转移仅依赖于前n个状态的过程。这个过程被称之为n阶马尔科夫模型,其中n是影响下一个状态选择的(前)n个状态。最简单的马尔科夫过程是一阶模型,它的状态选择仅与前一个状态有关。这里要注意它与确定性系统并不相同,因为下一个状态的选择由相应的概率决定,并不是确定性的。
下图是天气例子中状态间所有可能的一阶状态转移情况:
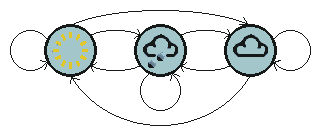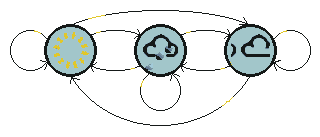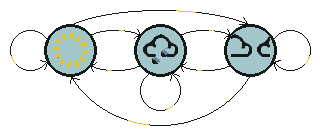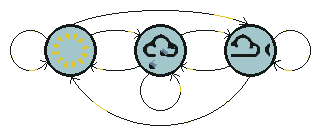
对于有M个状态的一阶马尔科夫模型,共有M^2个状态转移,因为任何一个状态都有可能是所有状态的下一个转移状态。每一个状态转移都有一个概率值,称为状态转移概率——这是从一个状态转移到另一个状态的概率。所有的M^2个概率可以用一个状态转移矩阵表示。注意这些概率并不随时间变化而不同——这是一个非常重要(但常常不符合实际)的假设。
下面的状态转移矩阵显示的是天气例子中可能的状态转移概率:

-也就是说,如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375。注意,每一行的概率之和为1。
要初始化这样一个系统,我们需要确定起始日天气的(或可能的)情况,定义其为一个初始概率向量,称为pi向量。

-也就是说,第一天为晴天的概率为1。
我们定义一个一阶马尔科夫过程如下:
状态:三个状态——晴天,多云,雨天。
pi向量:定义系统初始化时每一个状态的概率。
状态转移矩阵:给定前一天天气情况下的当前天气概率。
任何一个可以用这种方式描述的系统都是一个马尔科夫过程。
[马尔科夫模型 Markov model ]
3、隐藏模式(Hidden Patterns):隐马尔科夫
1、马尔科夫过程的局限性
在某些情况下,我们希望找到的模式用马尔科夫过程描述还显得不充分。回顾一下天气那个例子,一个隐士也许不能够直接获取到天气的观察情况,但是他有一些水藻。民间传说告诉我们水藻的状态与天气状态有一定的概率关系——天气和水藻的状态是紧密相关的。在这个例子中我们有两组状态,观察的状态(水藻的状态)和隐藏的状态(天气的状态)。我们希望为隐士设计一种算法,在不能够直接观察天气的情况下,通过水藻和马尔科夫假设来预测天气。
一个更实际的问题是语音识别,我们听到的声音是来自于声带、喉咙大小、舌头位置以及其他一些东西的组合结果。所有这些因素相互作用产生一个单词的声音,一套语音识别系统检测的声音就是来自于个人发音时身体内部物理变化所引起的不断改变的声音。
一些语音识别装置工作的原理是将内部的语音产出看作是隐藏的状态,而将声音结果作为一系列观察的状态,这些由语音过程生成并且最好的近似了实际(隐藏)的状态。在这两个例子中,需要着重指出的是,隐藏状态的数目与观察状态的数目可以是不同的。一个包含三个状态的天气系统(晴天、多云、雨天)中,可以观察到4个等级的海藻湿润情况(干、稍干、潮湿、湿润);纯粹的语音可以由80个音素描述,而身体的发音系统会产生出不同数目的声音,或者比80多,或者比80少。
在这种情况下,观察到的状态序列与隐藏过程有一定的概率关系。我们使用隐马尔科夫模型对这样的过程建模,这个模型包含了一个底层隐藏的随时间改变的马尔科夫过程,以及一个与隐藏状态某种程度相关的可观察到的状态集合。
[隐马尔可夫模型HMM]
皮皮blog
马尔科夫模型
马尔科夫链的节点是状态,边是转移概率,是template CPD(条件概率分布)的一种有向状态转移表达。马尔科夫过程可以看做是一个自动机,以一定的概率在各个状态之间跳转。
考虑一个系统,在每个时刻都可能处于N个状态中的一个,N个状态集合是 {S1,S2,S3,...SN}。我们现在用q1,q2,q3,…qn来表示系统在t=1,2,3,…n时刻下的状态。Note: 每个状态都是一个向量分布,即在N个状态集合是 {S1,S2,S3,...SN}上的概率分布。
马尔科夫链
独立同分布建模
处理顺序数据的最简单的方式是忽略顺序的性质,将观测看做独立同分布,对应于图13.2所示的图。然而,这种方法无法利用数据中的顺序模式,例如序列中距离较近的观测之间的相关性。

马尔科夫模型( Markov model )
为了在概率模型中表示这种效果,我们需要放松独立同分布的假设。完成这件事的一种最简单的方式是考虑马尔科夫模型( Markov model )。
马尔科夫模型( Markov model )表示观测序列的联合概率分布
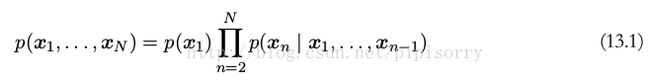
一阶马尔科夫链( first-order Markov chain )
一阶马尔科夫链( first-order Markov chain )模型中, N 次观测的序列的联合概率分布为


根据 d -划分的性质,给定时刻 n 之前的所有观测,我们看到观测 x n 的条件概率分布为

同质马尔科夫链( homogeneous Markov chain )
在这种模型的大部分应用中,条件概率分布 p(x n | x n−1 ) 被限制为相等的,对应于静止时间序列(数据会随着时间发生变化,但是生成数据的概率分布保持不变)的假设。这样,这个模型被称为同质马尔科夫链( homogeneous Markov chain )。例如,如果条件概率分布依赖于可调节的参数(参数的值可以从训练数据中确定),那么链中所有的条件概率分布会共享相同的参数值。
高阶马尔科夫链
二阶马尔科夫链
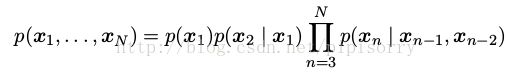
马尔科夫链的参数个数分析
假设观测是具有 K 个状态的离散变量,那么一阶马尔科夫链中的条件概率分布 p(x n | x n−1 ) 由 K − 1 个参数指定,每个参数都对应于 x n−1 的 K 个状态,因此参数的总数为 K(K − 1) 。
现在假设我们将模型推广到 M 阶马尔科夫链,从而联合概率分布由条件概率分布 p(x n | x n−M , . . . , x n−1 ) 构建。如果变量是离散变量,且条件概率分布使用一般的条件概率表的形式表示,那么这种模型中参数的数量为 K^M * (K − 1) 。
连续变量的马尔科夫链
对于连续变量来说,我们可以使用线性高斯条件概率分布,其中每个结点都是一个高斯概率分布,均值是父结点的一个线性函数。这被称为自回归( autoregressive )模型或者 AR 模型( Box et al., 1994; Thiesson et al., 2004 )。另一种方法是为 p(x n | x n−M , . . . , x n−1 ) 使用参数化的模型,例如神经网络。这种方法有时被称为抽头延迟线( tapped delay line ),因为它对应于存储(延迟)观测变量的前面 M 个值来预测下一个值。这样,参数的数量远远小于一个一般的模型(例如此时参数的数量可能随着 M 线性增长),虽然这样做会使得条件概率分布被限制在一个特定的类别中。
[PRML]
某小皮
马尔科夫过程收敛性分析与采样
这里只讨论一阶同质的马尔科夫过程。
(一阶同质)马尔科夫模型有两个假设:
1. 系统在时刻t的状态只与时刻t-1处的状态相关;(也称为无后效性)
2. 状态转移概率与时间无关;(也称为齐次性或时齐性)
第一条具体可以用如下公式表示:
P(qt=Sj|qt-1=Si,qt-2=Sk,…)= P(qt=Sj|qt-1=Si)
其中,t为大于1的任意数值,Sk为任意状态
第二个假设则可以用如下公式表示:
P(qt=Sj|qt-1=Si)= P(qk=Sj|qk-1=Si)
其中,k为任意时刻。即任意时刻两个状态之间的转移概率是一样的,整个转移概率矩阵在所有时间步之间是共享参数的。
Note: For you language folks, this is precisely the same idea as modeling word sequences using a bigram model, where here we have states z instead of having words w.一阶马氏链思想同词序列的bigram模型,只是将词w换成了状态z。
马氏链及其平稳分布
马氏链的数学定义很简单 P(Xt+1=x|Xt,Xt−1,⋯)=P(Xt+1=x|Xt)
也就是状态转移的概率只依赖于前一个状态,Markov Chain 体现的是状态空间的转换关系,下一个状态只决定与当前的状态(可以联想网页爬虫原理,根据当前页面的超链接访问下一个网页)。
马氏链的一个具体的例子
社会学家经常把人按其经济状况分成3类:下层(lower-class)、中层(middle-class)、上层(upper-class),我们用1,2,3 分别代表这三个阶层。社会学家们发现决定一个人的收入阶层的最重要的因素就是其父母的收入阶层。如果一个人的收入属于下层类别,那么他的孩子属于下层收入的概率是 0.65, 属于中层收入的概率是 0.28, 属于上层收入的概率是 0.07。事实上,从父代到子代,收入阶层的变化的转移概率如下
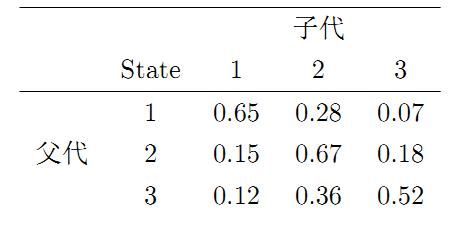
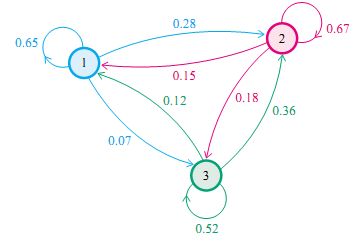
使用矩阵的表示方式,转移概率矩阵记为
P=⎡⎣0.650.150.120.280.670.360.070.180.52⎤⎦
假设当前这一代人处在下层、中层、上层的人的比例是概率分布向量 π0=[π0(1),π0(2),π0(3)],那么他们的子女的分布比例将是π1=π0P, 他们的孙子代的分布比例将是 π2=π1P=π0P2, ……, 第n代子孙的收入分布比例将是πn=πn−1P=π0Pn。
假设初始概率分布为π0=[0.21,0.68,0.11], 则我们可以计算前n代人的分布状况如下。我们发现从第7代人开始,这个分布就稳定不变了,这个是偶然的吗?我们换一个初始概率分布π0=[0.75,0.15,0.1] 试试看,继续计算前n代人的分布状况如下
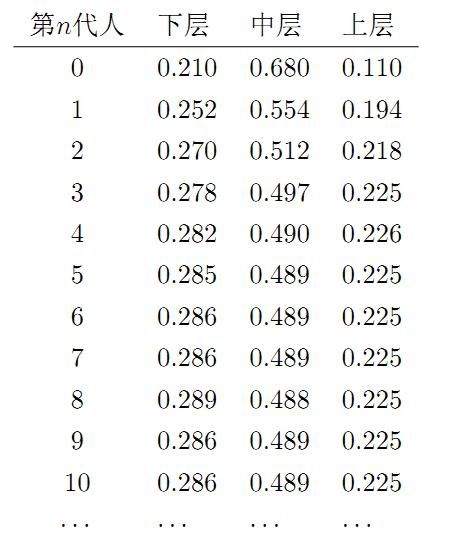
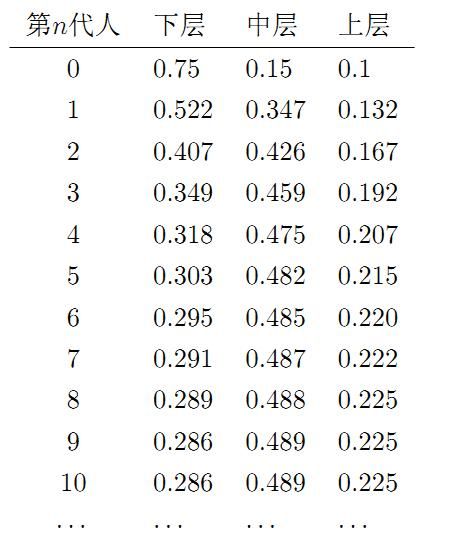
我们发现,到第9代人的时候, 分布又收敛了,事实上,在这个问题中,从任意初始概率分布开始都会收敛到这个上面这个稳定的结果。最为奇特的是,两次给定不同的初始概率分布,最终都收敛到概率分布π=[0.286,0.489,0.225], 也就是说收敛的行为和初始概率分布π0 无关。这说明这个收敛行为主要是由概率转移矩阵P决定的。我们计算一下Pn
P20=P21=⋯=P100=⋯=⎡⎣0.2860.2860.2860.4890.4890.4890.2250.2250.225⎤⎦
我们发现,当 n 足够大的时候,这个Pn矩阵的每一行都是稳定地收敛到π=[0.286,0.489,0.225] 这个概率分布。自然的,这个收敛现象并非是我们这个马氏链独有的,而是绝大多数马氏链的共同行为。
关于马氏链的收敛我们有如下漂亮的定理:
马氏链收敛定理
马氏链定理: 如果一个非周期马氏链具有转移概率矩阵P,且它的任何两个状态是连通的,那么limn→∞Pnij 存在且与i无关,记limn→∞Pnij=π(j), 我们有
- limn→∞Pn=⎡⎣⎢⎢⎢⎢⎢π(1)π(1)⋯π(1)⋯π(2)π(2)⋯π(2)⋯⋯⋯⋯⋯⋯π(j)π(j)⋯π(j)⋯⋯⋯⋯⋯⋯⎤⎦⎥⎥⎥⎥⎥
- π(j)=∑i=0∞π(i)Pij
- π 是方程 πP=π 的唯一非负解
其中,π=[π(1),π(2),⋯,π(j),⋯],∑i=0∞πi=1 π称为马氏链的平稳分布。
所有的 MCMC(Markov Chain Monte Carlo) 方法都是以这个定理作为理论基础的。 定理的证明相对复杂。
定理内容的一些解释说明
- 该定理中马氏链的状态不要求有限,可以是有无穷多个的;
- 定理中的“非周期“这个概念不解释,因为我们遇到的绝大多数马氏链都是非周期的;
- 两个状态i,j是连通并非指i 可以直接一步转移到j(Pij>0),而是指i 可以通过有限的n步转移到达j(Pnij>0)。马氏链的任何两个状态是连通的含义是指存在一个n, 使得矩阵Pn 中的任何一个元素的数值都大于零。
- 我们用 Xi 表示在马氏链上跳转第i步后所处的状态,如果limn→∞Pnij=π(j) 存在,很容易证明以上定理的第二个结论。由于
P(Xn+1=j)=∑i=0∞P(Xn=i)P(Xn+1=j|Xn=i)=∑i=0∞P(Xn=i)Pij
上式两边取极限就得到 π(j)=∑i=0∞π(i)Pij`
某小皮
马尔科夫模型的应用
采样算法中的应用
从初始概率分布 π0 出发,我们在马氏链上做状态转移,记Xi的概率分布为πi, 则有
X0Xi∼π0(x)∼πi(x),
πi(x)=πi−1(x)P=π0(x)Pn``
由马氏链收敛的定理, 概率分布πi(x)将收敛到平稳分布π(x)。假设到第n步的时候马氏链收敛,则有
X0X1XnXn+1Xn+2∼π0(x)∼π1(x)⋯∼πn(x)=π(x)∼π(x)∼π(x)⋯
所以 Xn,Xn+1,Xn+2,⋯∼π(x) 都是同分布的随机变量,当然他们并不独立。如果我们从一个具体的初始状态 x0 开始,沿着马氏链按照概率转移矩阵做跳转,那么我们得到一个转移序列x0,x1,x2,⋯xn,xn+1⋯, 由于马氏链的收敛行为,xn,xn+1,⋯ 都将是平稳分布π(x) 的样本。
顺序数据建模
[顺序数据:状态空间模型 ]
from:http://blog.csdn.net/pipisorry/article/details/46618991
ref: