使用libsvm实现归一化
使用libsvm实现归一化
我在使用svm进行分类的过程中接触了非常好用的库libsvm,但是一开始我是在matlab下使用的,libsvm中有matlab下使用的函数,如下:
libsvmwrite.mexw64
libsvmread.mexw64
svmtrain.mexw64
svmpredict.mexw64问题
但是在使用过程中我遇到一个问题,那就是数据的归一化,在matlab下libsvm中并没有实现数据归一化的函数,在网上查询的过程中,发现大家对于训练集与测试集的数据是否应该放在一起还是分开归一化有非常大的困惑。。。
思考
后来我发现libsvm中有在windows下命令行实现数据归一化、训练及预测的的可执行程序,如下:
svm-scale.exe
svm-train.exe
svm-predict.exe那么这里的svm-scale.exe究竟是怎么实现归一化的呢?针对这个问题我进行了学习。
学习
首先学习svm-scale.exe的使用方法,如下:
功能
缩放输入数据,原始数据范围可能过大或过小,该过程可将数据重新缩放到适当范围使训练与预测速度更快。
使用方法:
svm-scale.exe [-l lower] [-u upper] [-y y_lower y_upper] [-s save_name] [-r store_name] filename
参数说明
-l lower:缩放下限,默认-1;
-u upper:下限,默认1;
[-y y_lower y_upper] 是否对目标值(类标)同时进行缩放及缩放的上下限。
[-s save_name]缩放规则文件存放地址 ;
[-r store_name]读取缩放规则文件;
filename:要进行缩放的数据文件。在这里需要注意-s 与-r参数不能同时使用!
使用举例
F:\ASS\svm\libsvm-3.21\windows>svm-scale -l -1 -u 1 -s F:\ASS\svm\data\range1 F:\ASS\svm\data\svmguide1 >F:\ASS\svm\data\svmguide1.scale
以上程序对训练集进行缩放。规则文件存为range1,缩放后训练文件为svmguide1.scale。
svm-scale.exe的参数
使用svm-scale.exe,参数至少得有一个,即filename,也就是你需要归一化的数据文件,其他的参数都是可选的参数,只有一个参数的时候,默认是将数据归一化到[-1,1]的范围。那么究竟svm-scale是怎么实现数据的归一化的呢?规则很简单,如下:
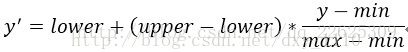
这里y是缩放前的数据,y’是缩放后的数据,lower与upper是缩放后数据的范围,min与max是缩放前数据的范围。
关于参数缩放规则文件的困惑
- 这里的缩放规则文件具体存放了什么内容?
- 训练集与测试集在归一化的时候是不是应该调用同样的缩放规则文件?
- 缩放规则文件是怎么生成的?
我在网上也没有找到一些详细的解释,所以自己设计了以下实验,尝试解决以上的困惑。
实验
收集数据
为了实验的方便,我自己设计了简单的训练集与测试集,里面的数据都是随机的,可能对于SVM分类来说,这些数据是不可分类的,但是现在我们的关注点在归一化上,不涉及到后续的数据分类,能说明归一化的问题即可。我的数据集如下:
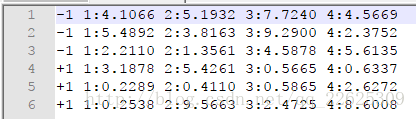
训练集数据:
测试集数据:
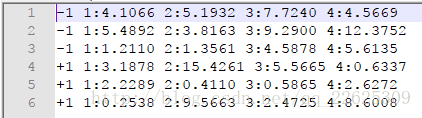
在libsvm中,数据的格式是上面的形式,以训练集为例,训练集中有6个样本,即6行数据,每个样本有自己的标签与特征向量,第一列是每个样本的标签,后续的四列构成了每个样本的四维的特征向量。比如训练中的第一个样本,其标签是0,(1.1 2.1 3.1 4.1)构成其思维的特征。
归一化
取训练集实现归一化,在windows中的cmd中输入如下命令:
![]()
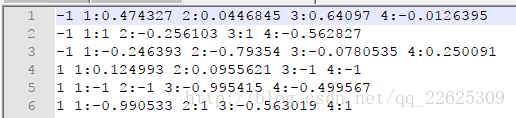
得到的归一化后的文件如下:
得到的缩放规则文件:
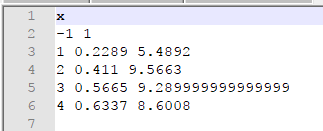
分析缩放规则文件,发现第一行是输入的缩放变量名,第二行的缩放之后数据的范围,从第三行开始是特征向量中每一维原始数据的最小/最大值。可见缩放规则文件的生成是依赖要缩放的原始数据。
一般来说,我们是需要训练集与测试集利用相同的缩放规则来进行缩放的,如下:
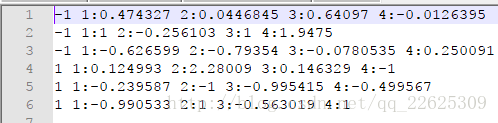
观察测试集归一化的结果,发现样本2的归一化后的数据出现1.9475,超过设定的[-1,1]的范围,这是因为在归一化测试集的时候,我们用的是训练集生成的缩放规则文件range,在range中,各样本特征第四维的最小/最大值默认是0.6377/8.6008,利用这个范围去归一化测试集中样本2的第四维向量的过程是:
y'=-1+(1-(-1))*(y-0.6377)/(8.6008-0.6377)
当y=12.3752的时候,y'=1.9475从上面这个例子中就可以认识到,当将测试集与训练集中的数据分开归一化的时候,就会出现数据出界的问题,但是我觉得即使出界了,也不影响后续的SVM分类,但是为了防止出现这种情况,我认为可以将训练集与测试集放在一起进行归一化,或者不使用训练集的缩放规则去归一化测试集数据,当然-l与-u两个参数还是要一致的。
以上都是我在学习过程中的一点感悟,与个人的理解,如果有不对的地方,请不吝赐教。