2019年秋季数据挖掘与机器学习课程学习笔记
第一节课
第二节课
第三节课
第四节课 density estimation
介绍:
令 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn是来自分布 P P P的密度为 p p p的样本,非参数密度估计目标就是在最少的关于密度 p p p的假设的情况对 p p p进行估计。我们用 p ^ \hat p p^来表示 p p p的估计。这个估计会依赖一个光滑的参数 h h h,小心的选择 h h h是关键的。为了强调这个对 h h h的依赖,我们使用 p ^ h \hat p_h p^h记号。
密度估计可被用于:回归、分类、聚类、无监督预测。举例而言:如果 p ^ ( x , y ) \hat p(x,y) p^(x,y)是 p ( x , y ) p(x,y) p(x,y)的一个估计,那么我们可以得到回归函数的以下估计:
m ^ ( x ) = ∫ y ( ^ y ∣ x ) d y \hat m(x)=\int y\hat (y|x)dy m^(x)=∫y(^y∣x)dy
其中 p ^ ( y ∣ x ) = p ^ ( y , x ) p ^ ( x ) \hat p(y|x)=\hat p(y,x)\hat p(x) p^(y∣x)=p^(y,x)p^(x).对于分类问题而言,我们回忆Bayes rule:
h ( x ) = I ( p 1 ( x ) π 1 > p 0 ( x ) π 0 ) h(x)=I(p_1(x)\pi_1>p_0(x)\pi_0) h(x)=I(p1(x)π1>p0(x)π0)
其中 π 1 = P ( Y = 1 ) , π 0 = P ( Y = 0 ) , p 1 ( x ) = p ( x ∣ y = 1 ) \pi_1=\mathbb{P}(Y=1),\pi_0=\mathbb{P}(Y=0),p_1(x)=p(x|y=1) π1=P(Y=1),π0=P(Y=0),p1(x)=p(x∣y=1), p 0 ( x ) = p ( x ∣ y = 0 ) p_0(x)=p(x|y=0) p0(x)=p(x∣y=0).输入样本对于 π 1 , π 0 \pi_1,\pi_0 π1,π0的估计,对 p 1 , p 0 p_1,p_0 p1,p0的密度估计则会产生一个基于Bayes rule的预测。很多你熟悉的分类器可以被用这种方式重新表述。
损失函数
最常使用的损失函数是 L 2 L_2 L2损失:
∫ ( p ^ − p ( x ) ) 2 d x = ∫ p ^ 2 ( x ) d x − 2 ∫ p ^ ( x ) p ( x ) + ∫ p 2 ( x ) d x \int(\hat p-p(x))^2dx=\int\hat p^2(x)dx-2\int\hat p(x)p(x)+\int p^2(x)dx ∫(p^−p(x))2dx=∫p^2(x)dx−2∫p^(x)p(x)+∫p2(x)dx
风险是 R ( p , p ^ ) = E ( L ( p , p ^ ) ) R(p,\hat p)=\mathbb{E}(L(p,\hat p)) R(p,p^)=E(L(p,p^))。
Devroye and Gyorfi(1985) 强烈推荐使用 L 1 L_1 L1范数
∥ p ^ − p ∥ 1 ≡ ∫ ∣ p ^ ( x ) − p ( x ) ∣ d x \|\hat p-p\|_1\equiv\int|\hat p(x)-p(x)|dx ∥p^−p∥1≡∫∣p^(x)−p(x)∣dx
作为 L 2 L_2 L2范数的代替。 L 1 L_1 L1损失有以下的良好解释:如果 P , Q P,Q P,Q是分布,定义全变差度量:
d T V ( P , Q ) = s u p A ∣ P ( A ) − Q ( A ) ∣ d_{TV}(P,Q)=sup_A|P(A)-Q(A)| dTV(P,Q)=supA∣P(A)−Q(A)∣
上确界取遍所有的可测集。如果 P , Q P,Q P,Q有密度 p , q p,q p,q那么有:
d T V ( P , Q ) = 1 2 ∫ ∣ p − q ∣ = 1 2 ∥ p − q ∥ 1 d_{TV}(P,Q)=\frac{1}{2}\int|p-q|=\frac{1}{2}\|p-q\|_1 dTV(P,Q)=21∫∣p−q∣=21∥p−q∥1
因此,如果 ∫ ∣ p − q ∣ < δ \int|p-q|<\delta ∫∣p−q∣<δ那么我们知道 ∣ P ( A ) − Q ( A ) ∣ < δ 2 |P(A)-Q(A)|<\frac{\delta}{2} ∣P(A)−Q(A)∣<2δ对于所有的 A A A。同样的, L 1 L_1 L1范数是一个变形不变量(transformation invariant)。假设 T T T是一个一对一的光滑映射,令 Y = T ( X ) Y=T(X) Y=T(X)。令 p p p和 q q q是 X X X的密度,令 p ^ , q ^ \hat p,\hat q p^,q^是相应的 Y Y Y的密度,那么:
∫ ∣ p ( x ) − q ( x ) ∣ d x = ∫ ∣ p ^ ( y ) − q ^ ( y ) ∣ d y \int|p(x)-q(x)|dx=\int|\hat p(y)-\hat q(y)|dy ∫∣p(x)−q(x)∣dx=∫∣p^(y)−q^(y)∣dy
因此在此定义下的距离不会因为一一映射而改变,但无论如何我们还是聚焦于 L 2 L_2 L2损失。
Histograms直方图
Perhaps the simplest density estimators are histograms. For convenience, assume that the data X 1 , . . . , X n X_1,...,X_n X1,...,Xn are contained in the unit cube X = [ 0 , 1 ] d X = [0,1]^d X=[0,1]d (although this assumption is not crucial). Divide X \mathcal X X into bins, or sub-cubes, of size h h h. We discuss methods for choosing h h hlater.




Kernel Density Estimation核密度估计
一个一维的光滑核(smoothing kernel)是任意的一个光滑函数(其定义域内无穷阶数连续可导的函数) K K K满足 ∫ K ( x ) d x = 1 , \int K(x)dx=1, ∫K(x)dx=1, ∫ x K ( x ) d x = 0 , σ k 2 ≡ ∫ x 2 K ( x ) d x > 0 \int xK(x)dx=0,\sigma_k^2\equiv\int x^2K(x)dx>0 ∫xK(x)dx=0,σk2≡∫x2K(x)dx>0。一些常用的核函数如下所示:
Boxcar: K ( x ) = 1 2 I ( x ) K(x)=\frac{1}{2}I(x) K(x)=21I(x)
Gaussian: K ( x ) = 1 2 π e − x 2 2 K(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}} K(x)=2π1e−2x2
Epanechnikov : K ( x ) = 3 4 ( 1 − x 2 ) I ( x ) K(x)=\frac{3}{4}(1-x^2)I(x) K(x)=43(1−x2)I(x)
Tricube: K ( x ) = 70 81 ( 1 − ∣ x ∣ 3 ) 3 I ( x ) K(x)=\frac{70}{81}(1-|x|^3)^3I(x) K(x)=8170(1−∣x∣3)3I(x)
其中 I ( x ) = 1 I(x)=1 I(x)=1如果 ∣ x ∣ ≤ 1 |x|\leq 1 ∣x∣≤1。否则 I ( x ) = 0 I(x)=0 I(x)=0.这些核的图像如下,常用的多维的核是 ∏ j = 1 d K ( x j ) , K ( ∥ x ∥ ) \prod_{j=1}^dK(x_j),K(\|x\|) ∏j=1dK(xj),K(∥x∥)。
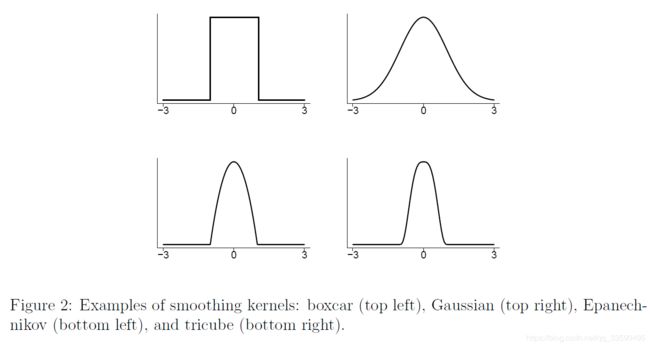

给定一个 X ∈ R d X\in\mathcal{R}^d X∈Rd。给定一个核 K K K和一个正数 h h h,称之为窗宽(bandwidth),核密度的估计定义为:
p ^ ( x ) = 1 n ∑ i = 1 n h d K ( ∥ x − X i ∥ h ) \hat p(x)=\frac{1}{n}\sum_{i=1}^ n{h^dK(\frac{\|x-X_i\|}{h})} p^(x)=n1i=1∑nhdK(h∥x−Xi∥)
由上面示性函数的定义我们知道也就是说与 x x x点的距离(范数)大于 h h h的 X i X_i Xi将不会对 x x x点处的密度有贡献。更一般的我们定义:
p ^ H ( x ) = 1 2 ∑ i = 1 n K H ( x − X i ) \hat p_H(x)=\frac{1}{2}\sum_{i=1}^nK_H(x-X_i) p^H(x)=21i=1∑nKH(x−Xi)
其中 H H H是一个正数定义了窗宽矩阵(bandwidth matrix)以及 K H = ∣ H ∣ − 1 2 K ( H − 1 2 x ) K_H=|H|^{-\frac{1}{2}}K(H^{-\frac{1}{2}}x) KH=∣H∣−21K(H−21x),为了简化表达,我们令 H = h 2 I H=h^2I H=h2I,然后我们得到先前的公式。
有时我们使用记号 p ^ h \hat p_h p^h来表达 p ^ \hat p p^对width h h h的依赖性。在多元的情况下,每个样本的坐标 X i X_i Xi应当被标准化来使每个样本是同方差的,因为范数 ∥ x − X i ∥ \|x-X_i\| ∥x−Xi∥把所有的坐标看做它们是在同一度量下。
核估计对于每个数据点 X i X_i Xi都放置了一个size是 1 n \frac{1}{n} n1的质量块,见图3。核的形式选择没有 h h h的选择关键。一个较小的 h h h会带来一个粗糙的估计,一个较大的 h h h会带来一个更光滑的估计。
4.1Risk Analysis
在这节中我们测试核密度的准确性,首先我们需要一些定义:
假设 X i ∈ X ⊂ R d X_i\in\mathcal{X}\subset\mathbb{R}^d Xi∈X⊂Rd其中 X \mathcal{X} X是紧集。令 β , L \beta,L β,L是正数。给定一个向量 s = ( s 1 , . . . , s d ) s=(s_1,...,s_d) s=(s1,...,sd),定义 ∣ s ∣ = s 1 + . . . + s d |s|=s_1+...+s_d ∣s∣=s1+...+sd, s ! = s 1 ! . . . s d ! s!=s_1!...s_d! s!=s1!...sd!, x s = x 1 s 1 . . . x d s d x^s=x_1^{s_1}...x_d^{s_d} xs=x1s1...xdsd并且
D s = ∂ s 1 + . . . + s d ∂ x 1 s 1 . . . ∂ x d s d D^s=\frac{\partial^{s_1+...+s_d}}{\partial x_1^{s_1}...\partial x_d^{s_d}} Ds=∂x1s1...∂xdsd∂s1+...+sd
令 β \beta β是一个正整数。定义 Holder class:
∑ ( β , L ) = { g : ∣ D s g ( x ) − D s g ( y ) ∣ ≤ L ∥ x − y ∥ , f o r a l l s s u c h t h a t ∣ s ∣ = β − 1 , a n d a l l x , y } \sum(\beta,L)=\{g:|D^sg(x)-D^sg(y)|\leq L\|x-y\|,for\ all\ s\ such\ that |s|=\beta-1,and\ all\ x,y\} ∑(β,L)={g:∣Dsg(x)−Dsg(y)∣≤L∥x−y∥,for all s such that∣s∣=β−1,and all x,y}
举例而言,如果 d = 1 , β = 2 d=1,\beta=2 d=1,β=2也就意味着:
∣ g ′ ( x ) − g ′ ( y ) ∣ ≤ L ∣ x − y ∣ , f o r a l l x , y |g'(x)-g'(y)|\leq L|x-y|,for\ all\ x,y ∣g′(x)−g′(y)∣≤L∣x−y∣,for all x,y
最常见的情况就是 β = 2 \beta=2 β=2,粗略来说这意味着函数被二阶导数限制。
如果 g ∈ ∑ ( β , L ) g\in\sum(\beta,L) g∈∑(β,L)那么 g ( x ) g(x) g(x)和他的泰勒级数展开是接近的:
∣ g ( u ) − g x , β ( u ) ∣ ≤ L ∥ u − x ∥ β |g(u)-g_{x,\beta}(u)|\leq L\|u-x\|^\beta ∣g(u)−gx,β(u)∣≤L∥u−x∥β
现在假设核 K K K有形式 K ( x ) = G ( x 1 ) . . . G ( x d ) K(x)=G(x_1)...G(x_d) K(x)=G(x1)...G(xd)其中 G G G定义在 [ − 1 , 1 ] , ∫ G = 1 , ∫ ∣ G ∣ p < ∞ [-1,1],\int G=1,\int|G|^p<\infty [−1,1],∫G=1,∫∣G∣p<∞对任意的 p > 1 p>1 p>1都成立, ∫ ∣ t ∣ β ∣ K ( t ) ∣ d t < ∞ , ∫ t s K ( t ) = 0 \int|t|^\beta|K(t)|dt<\infty,\int t^sK(t)=0 ∫∣t∣β∣K(t)∣dt<∞,∫tsK(t)=0对于所有的 s ≤ ⌊ β ⌋ s\leq\lfloor\beta\rfloor s≤⌊β⌋。
一个核函数的例子在 β = 2 \beta=2 β=2的情况下满足这些条件的是 G ( x ) = ( 3 / 4 ) ( 1 − x 2 ) G(x)=(3/4)(1-x^2) G(x)=(3/4)(1−x2)对所有的 ∣ x ∣ < 1 |x|<1 ∣x∣<1。构造一个满足 ∫ t s K ( t ) d t = 0 \int t^sK(t)dt=0 ∫tsK(t)dt=0对所有 β > 2 \beta>2 β>2的核函数需要这个核函数可以取负值。
令 p h ( x ) = E [ p ^ h ( x ) ] p_h(x)=\mathbb{E}[\hat p_h(x)] ph(x)=E[p^h(x)]。下一个引理提供了一个偏差 p h ( x ) − p ( x ) p_h(x)-p(x) ph(x)−p(x)的界限。
引理 3
p ^ \hat p p^的偏差满足:
s u p p ∈ ∑ ( β , L ) ∣ p h ( x ) − p ( x ) ∣ ≤ c h β sup_{p\in\sum(\beta,L)}|p_h(x)-p(x)|\leq ch^\beta supp∈∑(β,L)∣ph(x)−p(x)∣≤chβ
对于某个c
证明:我们有:

第一项被 L h β ∫ K ( s ) ∣ s ∣ β Lh^{\beta}\int K(s)|s|^\beta Lhβ∫K(s)∣s∣β限制因为 p ∈ ∑ ( β , L ) p\in\sum(\beta,L) p∈∑(β,L)。第二项是0因为K的性质 p x , β ( x + h v ) − p ( x ) p_{x,\beta}(x+hv)-p(x) px,β(x+hv)−p(x)是一个阶数为 ⌊ β ⌋ \lfloor\beta\rfloor ⌊β⌋的多项式(没有常数项)。
下面,我们来限制方差:
引理 4
p ^ h \hat p_h p^h的方差满足:
s u p p ∈ ∑ ( β , L ) V a r ( p ^ h ( x ) ) ≤ c n h d sup_{p\in\sum(\beta,L)}Var(\hat p_h(x))\leq \frac{c}{nh^d} supp∈∑(β,L)Var(p^h(x))≤nhdc
对于某个c
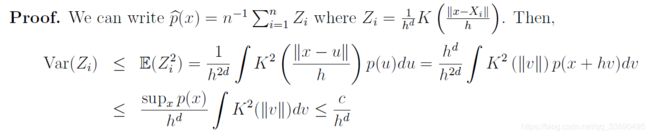
4.3 Boundary Bias
4.4 Confidence Bands and the CLT( central-limit theorem )
考虑一个单点 x x x。令 s n ( x ) = V a r ( p ^ h ( x ) ) s_n(x)=\sqrt{Var(\hat p_h(x))} sn(x)=Var(p^h(x))。CLT(中心极限定理)意味着:
Z n ( x ) ≡ p ^ h ( x ) − p h ( x ) s n ( x ) ⇝ N ( 0 , τ 2 ( x ) ) Z_n(x)\equiv\frac{\hat p_h(x)-p_h(x)}{s_n(x)}\leadsto N(0,\tau^2(x)) Zn(x)≡sn(x)p^h(x)−ph(x)⇝N(0,τ2(x))
对于某个 τ ( x ) \tau(x) τ(x)。即使 h = h n h=h_n h=hn是递减的情况下也成立。特别地,假定 h n → 0 , n h n → 0 h_n\rightarrow 0,nh_n\rightarrow0 hn→0,nhn→0,注意到 Z n ( x ) = ∑ i = 1 n L n i Z_n(x)=\sum_{i=1}^nL_{ni} Zn(x)=∑i=1nLni,跟据Lyaponounov’s CLT, ∑ i = 1 n L n i ⇝ N ( 0 , 1 ) \sum_{i=1}^nL_{ni}\leadsto N(0,1) ∑i=1nLni⇝N(0,1)只要:
lim n → ∞ ∑ i = 1 n E [ L n , i ] 2 + δ = 0 \lim_{n\rightarrow\infty}\sum_{i=1}^n\mathbb{E}[L_{n,i}]^{2+\delta}=0 n→∞limi=1∑nE[Ln,i]2+δ=0
对某个 δ \delta δ成立。但是这个并不会产生一个 p ( x ) p(x) p(x)的置信区间,为了说明这件事:
p ^ h ( x ) − p ( x ) s n ( x ) = p ^ h ( x ) − p h ( x ) s n ( x ) + p h ( x ) − p ( x ) s n ( x ) = Z n ( x ) + b i a s V a r ( x ) \frac{\hat p_h(x)-p(x)}{s_n(x)}=\frac{\hat p_h(x)-p_h(x)}{s_n(x)}+\frac{ p_h(x)-p(x)}{s_n(x)}=Z_n(x)+\frac{bias}{\sqrt{Var}(x)} sn(x)p^h(x)−p(x)=sn(x)p^h(x)−ph(x)+sn(x)ph(x)−p(x)=Zn(x)+Var(x)bias
假定通过平衡偏差(bias)和方差(variance)最优化了risk,那么第二项是某个常数c,因此 p ^ h ( x ) − p ( x ) s n ( x ) ⇝ N ( c , τ 2 ( x ) ) \frac{\hat p_h(x)-p(x)}{s_n(x)}\leadsto N(c,\tau^2(x)) sn(x)p^h(x)−p(x)⇝N(c,τ2(x))
这意味着一个通常的置信区间 p ^ h ( x ) ± z α 2 s ( x ) \hat p_h(x)\pm z_{\frac{\alpha}{2}}s(x) p^h(x)±z2αs(x)将不会以概率 1 − α 1-\alpha 1−α盖住 p ( x ) p(x) p(x)。一个对于这个问题的补救就是使估计不光滑(为什么?)(One fix for this is to undersmooth the estimator. (We sacrfice risk for coverage.))一个更简单的想法就是只把 p ^ h ( x ) ± z α 2 s ( x ) \hat p_h(x)\pm z_{\frac{\alpha}{2}}s(x) p^h(x)±z2αs(x)解释成 p h ( x ) p_h(x) ph(x)的置信区间。
但是这个只在一点处给出了置信区间,为了得到Confidence band我们需要使用bootsrap方法。令 P n P_n Pn是 X 1 , . . . , X n X_1,...,X_n X1,...,Xn的经验分布,想法就是估计分布:
F n ( t ) = P ( n h d ∥ p ^ h ( x ) − p h ( x ) ∥ ∞ < t ) F_n(t)=\mathbb{P}(\sqrt{nh^d}\|\hat p_h(x)-p_h(x)\|_\infty
使用bootsrap estimator(如下)作为上面的估计
F ^ n ( t ) = P ( ( n h d ∥ p ^ h ∗ ( x ) − p ^ h ( x ) ∥ ∞ < t ∣ X 1 , . . . , X n ) \hat F_n(t)=\mathbb{P}((\sqrt{nh^d}\|\hat p_h^*(x)-\hat p_h(x)\|_\infty
其中 p ^ h ∗ \hat p_h^* p^h∗产生于bootstrap 样本 X 1 ∗ , . . . , X n ∗ ∼ P n X_1^*,...,X_n^*\sim P_n X1∗,...,Xn∗∼Pn
下面是算法:
1.令 P n P_n Pn是经验分布满足在每个点 X i X_i Xi放置一个质量 1 n \frac{1}{n} n1的质量块
2.从分布 P n P_n Pn中抽取 X 1 ∗ , . . . , X n ∗ X_1^*,...,X_n^* X1∗,...,Xn∗。这成为一个bootstrap样本
3.根据boostrap样本计算对应的密度估计 p ^ h ∗ \hat p_h^* p^h∗
4.计算 R = sup x n h d ∥ p ^ h ∗ − p ^ h ∥ ∞ R=\sup_x\sqrt{nh^d}\|\hat p^*_h-\hat p_h\|_\infty R=supxnhd∥p^h∗−p^h∥∞
5.重复2-4步骤 B B B次,得到 R 1 , R 2 , . . . , R B R_1,R_2,...,R_B R1,R2,...,RB
6.令 z α z_\alpha zα是 R j R_j Rj的 α \alpha α上分位数,因此 1 B ∑ j = 1 B I ( R j > z α ) ≈ α \frac{1}{B}\sum_{j=1}^BI(R_j>z_\alpha)\approx \alpha B1∑j=1BI(Rj>zα)≈α
7.令 l n ( x ) = p ^ h ( x ) − z α n h d , u n ( x ) = p ^ h ( x ) + z α n h d l_n(x)=\hat p_h(x)-\frac{z_\alpha}{\sqrt{nh^d}},u_n(x)=\hat p_h(x)+\frac{z_\alpha}{nh^d} ln(x)=p^h(x)−nhdzα,un(x)=p^h(x)+nhdzα
定理 7
在适当的条件下(很弱),有:
lim inf n → ∞ P ( l n ( x ) ≤ p h ( x ) ≤ u ( x ) f o r a l l x ) ≥ 1 − α \liminf_{n\rightarrow\infty}\mathbb{P}(l_n(x)\leq p_h(x)\leq u(x) for\ all \ x)\geq1-\alpha n→∞liminfP(ln(x)≤ph(x)≤u(x)for all x)≥1−α
图4说明了这个性质:

如果想要得到一个置信度为p的置信带,我们需要减小偏差bias(undersmooth)。一个简单的方式就是twicing。假设 β = 2 \beta=2 β=2我们使用核估计 p ^ h \hat p_h p^h,注意到对某个 C ( x ) C(x) C(x)有:
E [ p ^ h ( x ) ] = p ( x ) + C ( x ) h 2 + o ( h 2 ) E [ p ^ 2 h ( x ) ] = p ( x ) + C ( x ) 4 h 2 + o ( h 2 ) \mathbb{E}[\hat p_h(x)] =p(x)+C(x)h^2+o(h^2)\\ \mathbb{E}[\hat p_{2h}(x)]=p(x)+C(x)4h^2+o(h^2) E[p^h(x)]=p(x)+C(x)h2+o(h2)E[p^2h(x)]=p(x)+C(x)4h2+o(h2)
第一个式子的偏差是 b ( x ) = C ( x ) h 2 b(x)=C(x)h^2 b(x)=C(x)h2,所以如果我们定义:
b ^ ( x ) = p ^ 2 h − p ^ h ( x ) 3 \hat b(x)=\frac{\hat p_{2h}-\hat p_h(x)}{3} b^(x)=3p^2h−p^h(x)
那么
E [ b ^ ( x ) ] = b ( x ) \mathbb{E}[\hat b(x)]=b(x) E[b^(x)]=b(x)
我们定义减去偏差的估计如下:
p ~ h ( x ) = p ^ h ( x ) − b ^ ( x ) = 4 3 ( p ^ h ( x ) − 1 4 p ^ 2 h ( x ) ) \tilde p_h(x)=\hat p_h(x)-\hat b(x)=\frac{4}{3}(\hat p_h(x)-\frac{1}{4}\hat p_{2h}(x)) p~h(x)=p^h(x)−b^(x)=34(p^h(x)−41p^2h(x))
一个以 p ~ h ( x ) \tilde p_h(x) p~h(x)的置信集合将是近似有效的但是不是最优的估计。这是一个基本的矛盾存在于估计和推断之间。
5.Cross-Validation
在实际操作中我们需要一个基于数据的方法来选择窗宽(bandwidth) h h h。为了达到这个,我们需要估计estimator的风险risk,在 h h h上最小化估计风险estimated risk。现在我们来叙述两种交叉验证的方法。
阅读资料:
Density Estimation 10/36-702
https://blog.csdn.net/weixin_37801695/article/details/84918980
https://blog.csdn.net/liangzuojiayi/article/details/78152180
https://blog.csdn.net/unixtch/article/details/78556499