Gradient Boosted Decision Tree详解
Gradient Boosted Decision Tree详解
第二次写博客,本人数学基础不是太好,如果有幸能得到读者指正,感激不尽,希望能借此机会向大家学习。这一篇的内容主要来自于《机器学习》和《机器学习技法》,以及自己的一些见解。
预备知识:
这一部分主要是谈一谈Adaboost的适用范围,以及Adaboost的更新中涉及到的基础数学公式和定理的推导。
Adaboost的适用范围
若 f ( x ) f\left(x\right) f(x)为样本 x x x的实际标签值, H ( x ) H\left(x\right) H(x)为样本 x x x的预测标签值,则Adaboost的指数损失函数可以表示为,
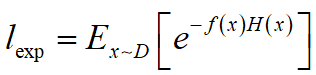
其中, H ( x ) H\left(x\right) H(x)符合加性模型,即

由此可见,Adaboost在未经修改的情况下只适用于二元分类问题。
Adaboost的更新
Adaboost的每轮迭代都会基于当前样本权值产生一个基学习器 h t h_t ht,和这个基学习器的权重 α t \alpha_t αt,并基于这两个条件进行样本分布(权值)的更新,假设第t-1轮迭代产生了学习器 H t − 1 = ∑ i = 1 t − 1 α i h i H_{t-1}=\sum_{i=1}^{t-1}\alpha_ih_i Ht−1=∑i=1t−1αihi,根据Adaboost中给出的指数损失函数,可以推得第t轮的基学习器 h t h_t ht和权重 α t \alpha_t αt的选取要满足下面的式子
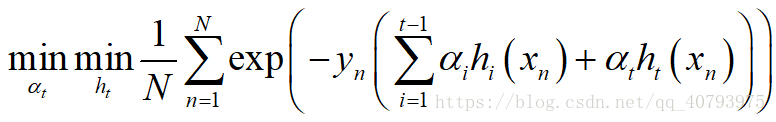
即,他们的选取要以最小化Adaboost的指数损失函数为目标。
推导过程
主要分为五部分:Gradient Boost、训练基学习器、选择基学习器的权值 α t \alpha_t αt、训练集样本的更新和Gradient Boosted Decision Tree。
Gradient Boost
由于未经修改的AdaBoost使用指数损失函数作为目标函数,且使用二元分类器作为其基学习器,导致其适用范围不是很广泛【1】,因此在Gradient Boost中,决定采用任意的学习算法产生基学习器,并将损失函数变为适用于基学习器的“任意”损失函数。
同样,假设第t-1轮迭代产生了学习器 H t − 1 = ∑ i = 1 t − 1 α i h i H_{t-1}=\sum_{i=1}^{t-1}\alpha_ih_i Ht−1=∑i=1t−1αihi,则第t轮的基学习器 h t h_t ht和权重 α t \alpha_t αt的选取要满足下面的式子
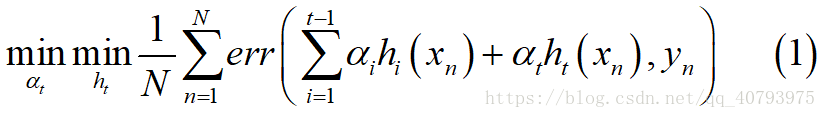
其中, e r r ( ~ ) err\left(\tilde{}\right) err(~)可以为平方损失函数、hinge损失函数等等,由此可见,Gradient Boost可以通过扩展误差的度量方式,来达到接收更多类型的基学习器的目的(e.g. regression/soft classification/etc),下面以回归(Regression)任务为例。
训练基学习器
由式(1)可知,如果先忽略权重 α t \alpha_t αt的影响(先假设 α t \alpha_t αt为一个常数,下面式(3)的推导中用到),基学习器 h t h_t ht要满足
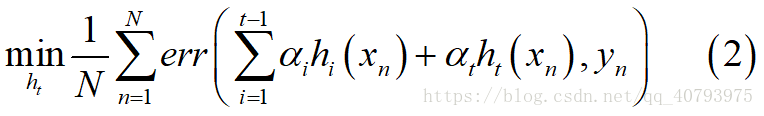
其中, H t − 1 = ∑ i = 1 t − 1 α i h i H_{t-1}=\sum_{i=1}^{t-1}\alpha_ih_i Ht−1=∑i=1t−1αihi,可以得到
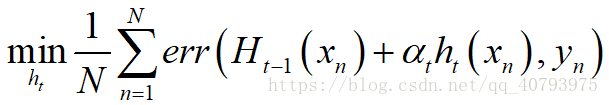
另外,由Taylor公式可知,当 α t h t ( x n ) \alpha_th_t\left(x_n\right) αtht(xn)很小时,其对 e r r ( ~ ) err\left(\tilde{}\right) err(~)的影响可以由下式代替
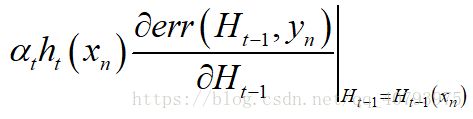
即 α t h t ( x n ) \alpha_th_t\left(x_n\right) αtht(xn)与 e r r ( ~ ) err\left(\tilde{}\right) err(~)梯度的乘积。由于误差损失函数 e r r ( H i ( x n ) , y n ) = ( H i ( x n ) − y n ) 2 err\left(H_i\left(x_n\right),y_n\right)=\left(H_i\left(x_n\right)-y_n\right)^2 err(Hi(xn),yn)=(Hi(xn)−yn)2,式(2)可近似等价于,
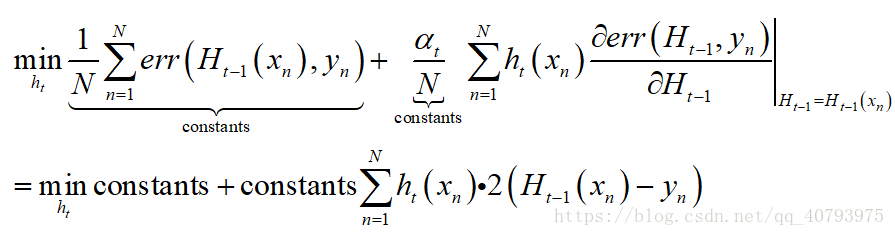
忽略掉常数项(constants)的影响后,上式等价于

若要使式(3)达到最小,最简单的办法是令 h t ( x n ) = − a ∗ ( H t − 1 ( x n ) − y n ) h_t\left(x_n\right)=-a*\left(H_{t-1}\left(x_n\right)-y_n\right) ht(xn)=−a∗(Ht−1(xn)−yn),其中, a > 0 a>0 a>0,在 h t ( x n ) h_t\left(x_n\right) ht(xn)没有任何限制的情况下, a a a可以取到 + ∞ +\infty +∞。
但是,一般情况下,我们不希望 h t ( x n ) h_t\left(x_n\right) ht(xn)的数量级过大,因此在式(3)中加入 L 2 L_2 L2正则项 ( h t ( x n ) ) 2 \left(h_t\left(x_n\right)\right)^2 (ht(xn))2,得到下式
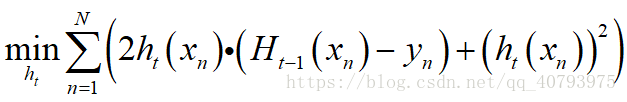
经过配方法后得到,
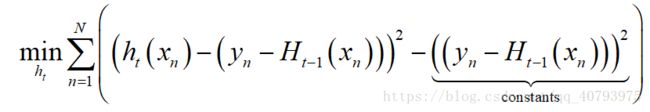
忽略常数项的影响,得到
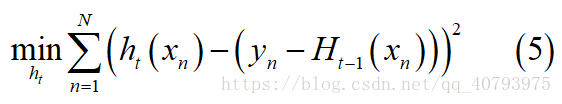
由上式可以看输出,当 x n x_n xn为一个向量,输入为 ( x n , y n ) \left(x_n,y_n\right) (xn,yn),预测输出为 h t ( x n ) h_t\left(x_n\right) ht(xn),实际输出为 ( y n − H i ( x n ) ) \left(y_n-H_i\left(x_n\right)\right) (yn−Hi(xn)),即数据集为 ( x n , ( y n − H i ( x n ) ) ) \left(x_n,\left(y_n-H_i\left(x_n\right)\right)\right) (xn,(yn−Hi(xn)))时,基学习器的选择要使上述平方误差达到最小,这与多变量回归问题十分相近,因此可以使用类似的算法(e.g. C&RT,etc)解决上述问题。需要注意的是,这里的实际输出是上一轮迭代产生的学习器在样本 x n x_n xn上的预测输出 H t − 1 ( x n ) H_{t-1}\left(x_n\right) Ht−1(xn),与样本实际输出值 y n y_n yn的余数(residual)。
选择基学习器的权值 α t \alpha_t αt
当基学习器 h t h_t ht决定下来后,由式(1)可知,权值 α t \alpha_t αt要满足
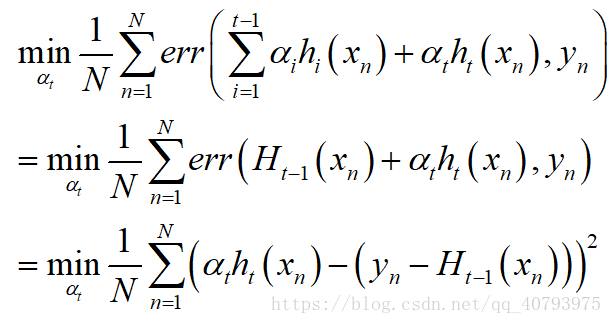
即训练集为 ( h t ( x n ) , ( y n − H t − 1 ( x n ) ) ) n = 1 , 2 , . . . , N \left(h_t\left(x_n\right),\left(y_n-H_{t-1}\left(x_n\right)\right)\right) n=1,2,...,N (ht(xn),(yn−Ht−1(xn))) n=1,2,...,N,其中 h t ( x n ) h_t\left(x_n\right) ht(xn)为一个变量时,权值 α t \alpha_t αt的选取要使上述平方误差最小化,这与单变量回归问题十分相似,因此可采用类似算法(e.g. SVR)解决上述问题。需要注意的是,这里的输入是基学习器 h t h_t ht对样本 x n x_n xn的预测输出值(大小为1X1,即一个变量),这里的实际输出与训练基学习器时一样。
训练集样本的更新
用于训练基学习器 h t h_t ht的训练样本为 ( x n , ( y n − H t − 1 ( x n ) ) ) n = 1 , 2 , . . . , N \left(x_n,\left(y_n-H_{t-1}\left(x_n\right)\right)\right) n=1,2,...,N (xn,(yn−Ht−1(xn))) n=1,2,...,N,这里的 x n x_n xn即原始数据集的输入不需要做任何改动,而实际输出 ( y n − H t − 1 ( x n ) ) \left(y_n-H_{t-1}\left(x_n\right)\right) (yn−Ht−1(xn))会随着迭代次数的改变和集成学习器 H i H_i Hi的更新而更新。
用于选择权值 α t \alpha_t αt的训练样本为 ( h t ( x n ) , ( y n − H t − 1 ( x n ) ) ) n = 1 , 2 , . . . , N \left(h_t\left(x_n\right),\left(y_n-H_{t-1}\left(x_n\right)\right)\right) n=1,2,...,N (ht(xn),(yn−Ht−1(xn))) n=1,2,...,N,这里需要进行两个更新,其中, h t ( x n ) h_t\left(x_n\right) ht(xn)在已经确定好基学习器 h t h_t ht后就成为了一个变量,他随每一轮迭代产生的 h t h_t ht的改变而更新,而实际输出 ( y n − H t − 1 ( x n ) ) \left(y_n-H_{t-1}\left(x_n\right)\right) (yn−Ht−1(xn))会随着迭代次数的改变和集成学习器 H i H_i Hi的更新而更新。
Gradient Boosted Decision Tree
伪代码如下图所示,

注:图中 g t = h t g_t=h_t gt=ht, s n = H t − 1 ( x n ) s_n=H_{t-1}\left(x_n\right) sn=Ht−1(xn).
参考资料
【1】《机器学习》周志华
【2】《机器学习技法》林轩田