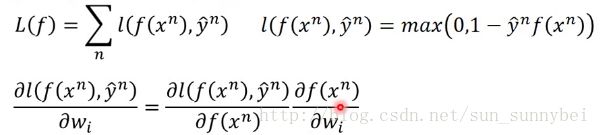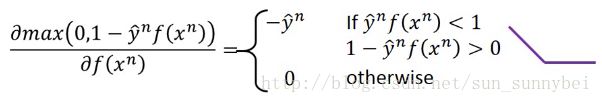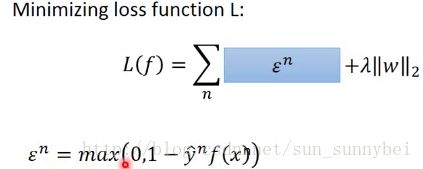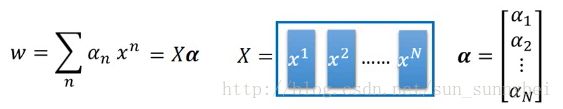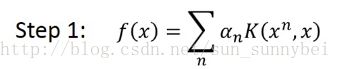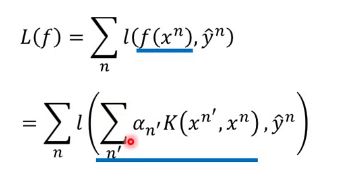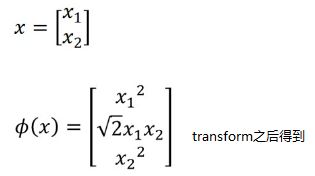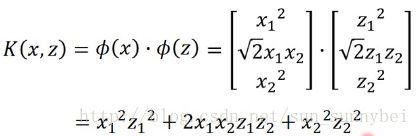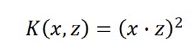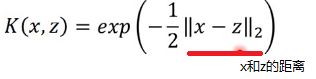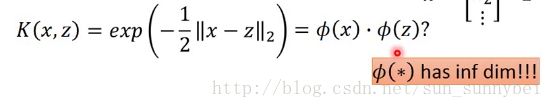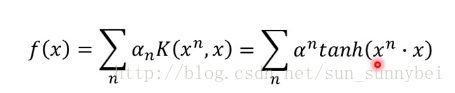Support Vector Machine有两个特色:
Hinge Loss
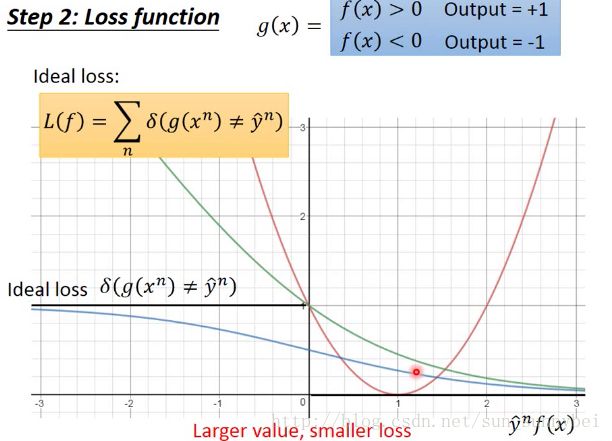
我们常见的Binary Classification如下图所示,其中的Loss Function中的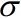 表示g(x)如果与Label y一样则输出0,不一样则输出1,所以损失函数变为:g在training set中总共犯了几次错。
表示g(x)如果与Label y一样则输出0,不一样则输出1,所以损失函数变为:g在training set中总共犯了几次错。

但是Loss function是不可以微分的,所以第三步不能用gradient decent的方法做。所以我们不直接minimize这个loss function,而是改成minimize另一个近似的loss function:
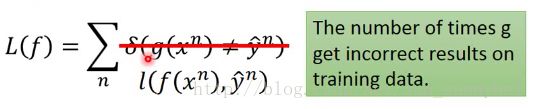
而这个approximation function长什么样子,你可以自己决定,总体的思想是,当y=+1时,f(x)越大越好,y=-1时,f(x)越负越好,所以希望y*f(x)越大越好,二者同向的。如果横轴是y*f(x),纵轴是loss的话,原则上是越往右,y*f(x)越大,loss就要越小。理想状态是假设y和f(x)是反向的,那么loss=1,反之同向的就是0,但是这个是没办法微分的:
现在做近似,把用l来取代,纵轴就是l的值,你可以选各种的function来当做l的function,比如用square loss,当y=1的时候loss越接近1越好,当y=-1的时候loss越接近-1越好:
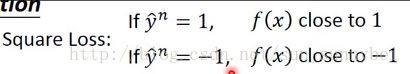
你可以把它化成 ,下图中的红线就是square loss的图:
,下图中的红线就是square loss的图:
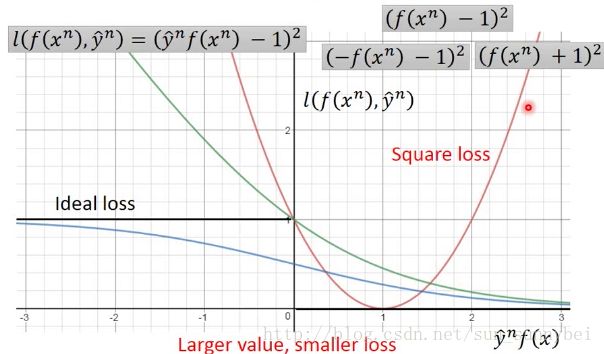
但是这个square loss是不合理的,因为我们并不希望y*f(x)很大的时候有一个很大的loss,这跟我们上述的假设是不一致的。
另外一个是sigmoid+square Loss:
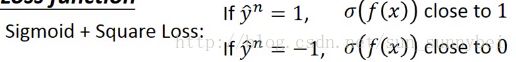
可以改写成这样:
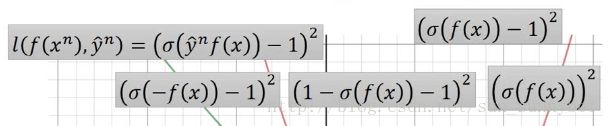
函数图就是下列的蓝色的线:

另一种的function是Sigmoid + cross entropy(logistic regression中用的loss function):
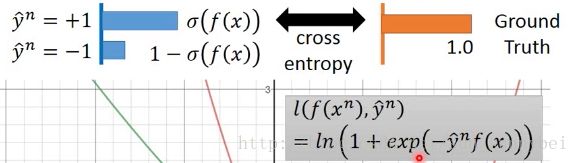
这个function是合理的,当y*f(x)趋近于正无穷大的时候,loss=0,当y*f(x)趋近于负无穷大的时候,loss=无穷大,它的函数图如下面的绿色线(function除以ln2之后的结果图):
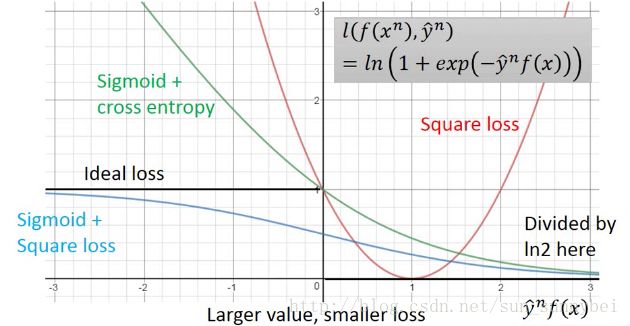
通过比较蓝色的线和绿色的线可以看出在logistic regression时为什么要用cross entropy而不是用square loss。假设y*f(x)从-2移动到-1的时候,sigmoid +square loss变化很少,而sigmoid + cross entropy变化很大,更容易training。
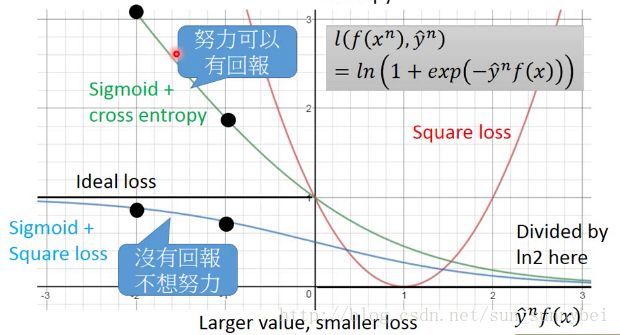
那hinge loss就是把function l写成:
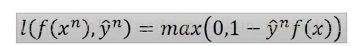
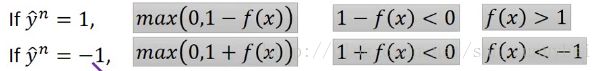
y=1时,f(x)>1的时候完美状态loss=0,y=-1时,f(x)<-1的时候完美状态loss=0,对于positive的例子来说,f(x)>1表示完美的case,对于negative的例子来说,f(x)<-1表示完美的case。f(x)的值不用太大,只要大过1就好,不用太小,只要小过-1就好。
它的图是下面紫色的线,在y*f(x)>1的这段上就已经够好了,loss就是0再大也不会更好了,但是y*f(x)在0-1这段,虽然二者同号,在step1上已经可以得到正确答案,但是hinge loss觉得还不够好,要比正确答案好过一段距离,没有大于1的时候还是有penatly,促使machine使得y*f(x)>1:
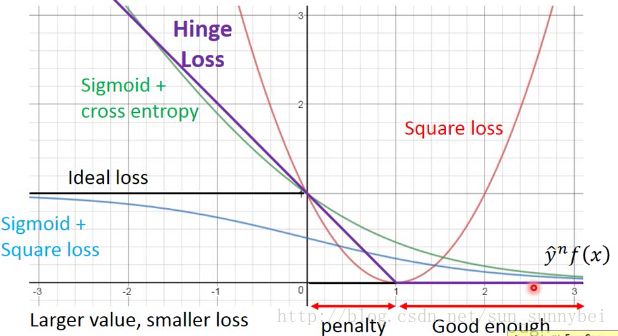
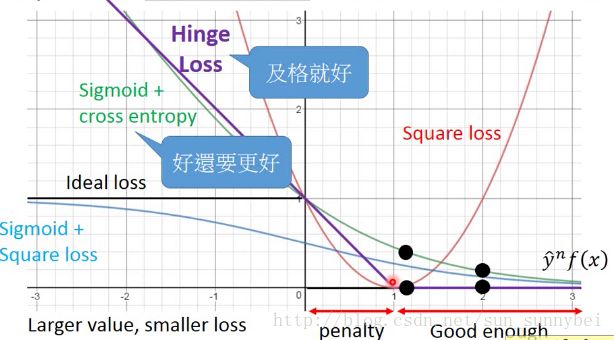
hinge loss和sigmoid+cross entropy都是ideal loss的一个up bound,所以我们可以minimize hinge loss 就可以得到minimize ideal function的效果。
比较hinge-loss和sigmoid+cross entropy,会发现二者的区别就是对待已经做得好的example的态度,将y*f(x)从1改到2,对cross entropy来讲你可以得到loss的下降,所以cross entropy想要好还要更好,它有动机让y*f(x)变得更大。但是对于hinge loss来讲,它是一个及格就好的function,只要你的值大过1就结束了,不会想做的更好。在实际中,二者的效果并没有什么显著的差别,但是hinge loss是比较鲁棒的
Linear SVM
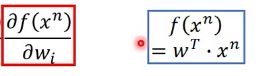
function是linear的,组合得到新的w和x:

它的loss function是hinge loss,通常还会加一个regularization,这个loss function是convex function,作gradient decent就会很简单了,不管你从哪个地方初始化,最后的结果都会是一样的。但是可能在某些点是不可微分的,这并不是什么大问题,都可以用gradient decent来做。
和logistic regression相比,linear SVM只是有不同的loss function,前者用的是cross entropy后者用的是hinge loss。而且step1中的function不一定是要linear的,在做Deep Learning的时候不是用cross entropy作为minimize的对象,而是用hinge loss的话就是一个deep的svm
接下来的问题就是怎么用gradient decent来learn SVM呢?
Linear SVM——gradient descent
已知loss function是hinge loss了,那么对它的微分如下:
其中f(x)是x和w的乘积,所以它的微分如下:
l对f(x)的微分,分为两部分,主要depend on当前的weight是多少:
所以最后可以写成:
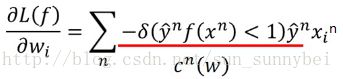
其中的c(w)depend on你现在的参数是什么。
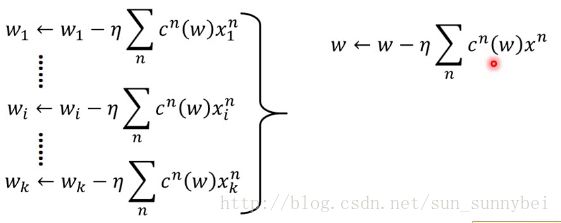
最后在update参数的时候,直接用wi减去微分之后的值就好:
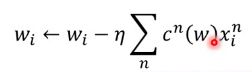 所以SVM是可以用gradient decent来解的。所以你是要写linear的SVM的话,可以用keras很快的写出来。
所以SVM是可以用gradient decent来解的。所以你是要写linear的SVM的话,可以用keras很快的写出来。
可能上述的SVM与你平常看到的SVM是长得不一样的,下面会讲另一种形式
Linear SVM ——another formulation
平常见到的SVM,它的loss function用一个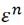 来代替,而且
来代替,而且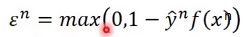 :
:
其中的可以有另一种写法,它取0和1-y*f(x)中较大的那个,那就是说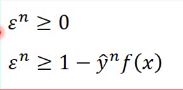 ,单独看
,单独看
的话,这两个式子是不一样的:
但是加上上面的minimize loss function的话,两个式子表达的意义是一摸一样的:
因为要取一个最小的使得L最小,在第二个式子中,因为它同时大于0,大于1-y*f(x),所以它就要等于0和1-y*f(x)中比较打的那个,所以也就是说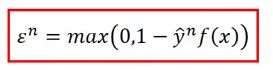 。所以二者的意义是相同的,所以第一个式子可以转化成第二个式子。
。所以二者的意义是相同的,所以第一个式子可以转化成第二个式子。
那这就转化成了我们比较常见的SVM了,也就是y*f(x)要是同号的,相乘之后要大于等于一个margin 1,但是这个margin是soft的,可以把margin稍微放宽变成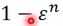 ,而且这个slack variable绝对不能是负的,因为这不符合他的目的,这样会把margin变大了,所以它必须>=0.
,而且这个slack variable绝对不能是负的,因为这不符合他的目的,这样会把margin变大了,所以它必须>=0.
那把这些事情合起来之后,你会有一个要minimize的对象,和一堆constrain(约束),这是一个quadratic programming(二次规划)的问题,你可以带入一个quadratic programming solver去解,但是你也可以用前面所说的gradient decent来解
Kernel Method
Dual Representation
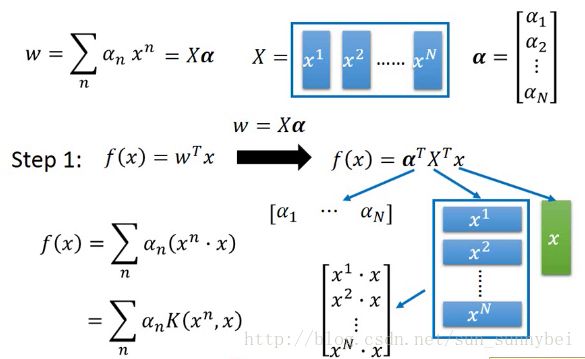
实际上,我们最后找出来的weight w*是training data的Linear combination:
这个的证明可以用拉格朗日来解,这里用另外一个角度来讲。
刚才我们已经知道了用gradient descent来解之后update weight用的式子是这样的:
这就意味着,假设我们把weight初始化成0,那每次在update w的时候,都是加上data point的linear combination。所以最后的结果得到的w就是x的linear combination。
其中c(w)是l对f(x)的偏微分,如果用的hinge loss function,c(w)往往是0 ,也就是并不是所有的xn都会被拿来加到w里去。所以最后解出来的w*它的linear combination的weight a可能是sparse的,可能有很多的data point 对应的a等于0,而那些对应的a不等于0的xn 它就是support vectors:
如果a等于0,那这个的x就对这个model一点作用也没有,没有影响力。如果a不等于0,那这个x会决定最后的parameter w长什么样子,而这些可以决定最后的parameter长什么样子的data point就叫做support vector。只有少数的data point会被选作support vector。所以SVM是比较鲁棒的,如果你选用的loss function是logistic regression中的cross entropy,它就没有sparse的这个特性,它在每个地方的微分都是不等于0的,所以你解出来的a就不是sparse的,如果用hinge loss解出来的就是sparse的,解出来是sparse的就是说,那些不是support vector的data point,你把它从data base中remove掉,对结果是一点影响也没有的。如果今天有一个奇怪的outlier,那你不要把它选作support vector,那它不会影响结果,不像其他的方法如logistic regression每笔data都会有影响:
已知w是data point的linear combination:
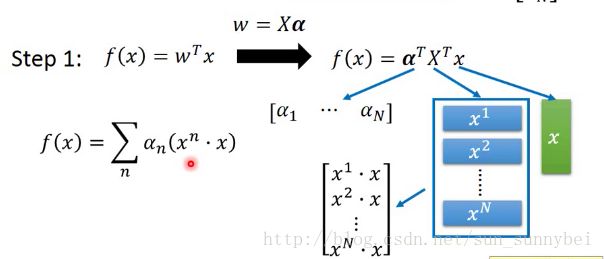
我们可以改一下function的样子:
x是一个vector,x要与每个xi做内积,再分别乘上ai:
并不会所有的xn都做内积,只用考虑a不等于0的vector就好了。我们把x与xn做内积写成function K,叫做kernel function:
所以现在step1可以写成:
那step2,3中未知的参数只剩下a了,所以现在的问题转化成了找一组最好的an,使得loss function最小:
而loss function的输入有两个,一个是f(x)一个是yn,而我们现在知道f(x)是an和K的函数:
从上述的式子可以看出,an是要求的值,yn是已知的Label,那只要知道K的值就可以了。所以我们只需要知道kernel function就可以做所有的optimization(优化)。所以我们并不需要知道x,xn长什么样子,只要知道他们的内积就可以结束了,这个叫做kernel trick,:
Kernel Trick并不仅限于SVM,这种内积的做法同样适用于linear regression和logistic regression,可以有Kernel based的linear regression和Kernel based的logistic regression。
Kernel Trick
对于linear model,它可能会有很多限制,你需要对input的data做一些transform,再用linear model来处理,在神经网络中,经常用几层hidden layer来进行transform。
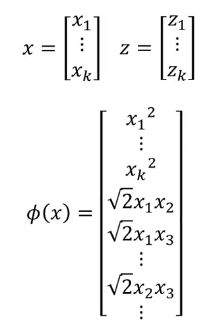
假设我们现在有二维的data x,将它进行feature transform之后再apply linear model:
然后想算K(x,z)的时候,也就是x和z在进行完transform之后的inner product的值,最简单的可以这么算:
但是继续简化之后会发现,先进行transform再进行内积,和先进行内积再平方的结果是一样的:
这样给我们启示是,有时直接计算K(x,z)会比先计算transform再计算内积要快的多。
举例来说,x和z都是k维的,要把它投影到更高维的平面,考虑所有的feature两两之间的关系:
如果你用Kernel Trick的话,你能轻易的把transform之后的x和z的内积求出来,只用求k个element的相乘再求平方就好了:
但是如果你先把它project到高维上再做内积的话,dimension会很大,feature会很长,运算量很大:
将展开式中的x和z分离开就得到了transform之后的x和z。
Radial Basis Function Kernel(RBF Kernel)径向基函数
现在K定义如下,x,z距离乘上-1/2再取exp:
这个函数用来x和z之间的相似度,如果x和z越像Kernel的值就越大,如果二者相同则是1,完全不同则是0。
其实这个式子也可以化成两个high dimension的vector做inner product的结果。而这两个vector是有无穷多维的:
所以本来你要把一个xproject到无穷多维再去做project是做不到的,但是如果你直接算x和z的距离,再乘以-1/2,再去exp,你就等同于在一个无穷多维的空间里做内积。那这个空间长什么样子呢?上面的式子可以展开成下面的式子:
将x和z 的vector串起来,都会有一个无穷长的vector,然后将二者做内积,得到的结果就是Kernel给出的结果。
当你使用RBF Kernel的时候,你就是在无穷多维的平面上去操作,这样是很容易overfitting的。
Sigmoid Kernel
它的Kernel函数如下,它也是将x和z transform到高维上之后做内积的结果:
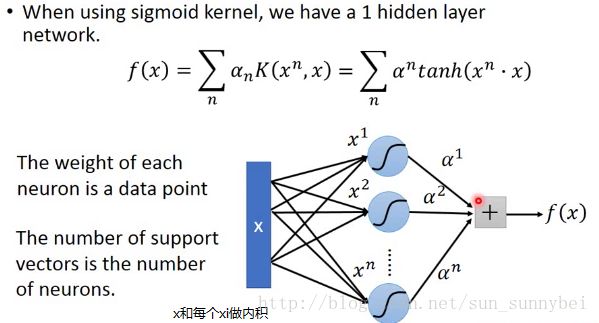
当我们在之前的f(x)中用sigmoid kernel的时候,得到如下的式子:
如果我们用的是sigmoid kernel,那可以把它想做是只有一个hidden layer的neuron network:
既然有了这个Kernel Trick之后,我们可以直接设计Kernel Function,完全不用理会x和z的feature长什么样子,只要有一个Kernel Function把x和z带进去得到一个value,这个value代表了z和x在某个高维平面上的product,你根本就不需要在意x和z的vector长什么样子。
那这招什么时候有用呢?假设你的x是有structure的data,比如说是一个sequence,而且它的长度都不一样,并不容易把一个sequence表示成一个vector。但是可以直接定义它的Kernel Function,已知Kernel Function就是投影到高维上的inner product,往往就是一个类似于similarity的东西,所以你如果能定义一个评估x和zsimilarity的Function,就算x和z是有structure的object也是没有关系的。只要你能算二者之间的similarity,你就可能把这个similarity当做Kernel来使用。
但是如果胡乱定义一个similarity,它背后有feature vector来support它吗?Kernel其实是两个vector做inner product的结果,那你胡乱定义一个Function它可以拆成两个vector的inner product的结果吗?并不是所有的Function都可以,但是有一个叫做Mercer's theory可以去进行检查,得知哪些Function是可以的。
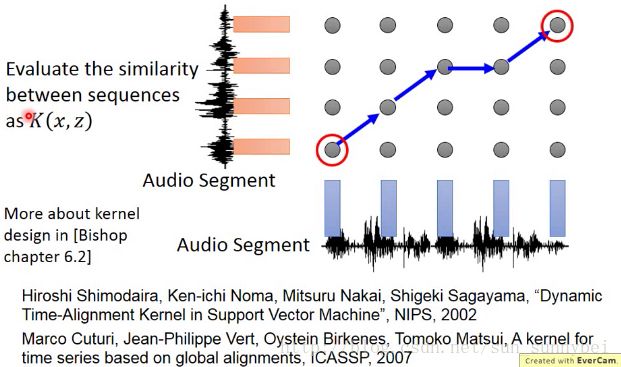
在语音上,假设你要做分类的对象是Audio Segment,一段声音讯号会用一段vector sequence来描述它,每段声音讯号长度是不一样的,所以它的vector sequence也是可能都不一样。现在给你的声音讯号让你区分语者的情绪,可能有高兴,失望等10类。
一段声音讯号你没办法用一个vector来直接描述它,可以直接定它的Kernel,就不管声音变成一个vector之后长什么样子了,直接定义K(x,z),x和z带进去后,这个Function的output应该是什么。定好之后就可以直接用Kernel Trick apply SVM,而不用管vector长什么样子了。
SVM related methods
SVM做regression就是support vector regression。它的思想是:以前的是希望output和target越接近越好,但是在SVR中是说output在target的某一个距离里面loss就是0,。
Ranking SVM常常被用在当你要考虑的对象是一个排序一个list的时候。
one-class SVM,它是希望属于positive的归为一类,属于negative的散布在其他地方
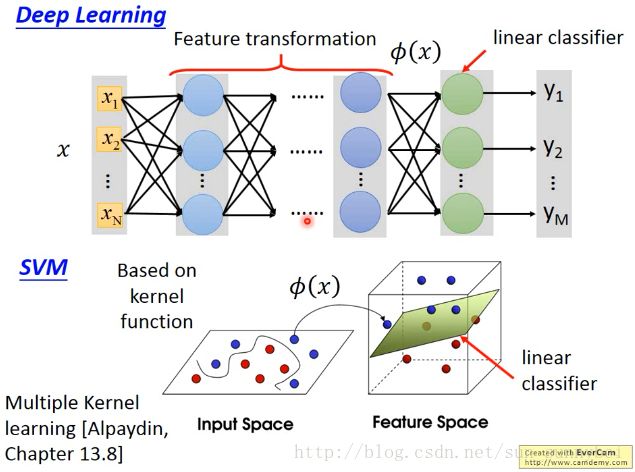
Deep Learning vs SVM
DL的前几个layer可以看做layer transform,最后一个layer可以看做linear classifier。
SVM前面先apply一个Kernel Function把你的feature转到一个高维的空间中,然后在high dimension上面apply linear classifier(一般都用hinge loss)。
SVM的Kernel是learnable的,但是并不像DL那样learn的那么多,你可以做的是好几个不同的Kernel,把它们combine起来,他们之间的weight是可以learn的。