从感知机(Perceptron)到支持向量机(SVM)
duality chapter有错误,待修订
本文会介绍感知机和支持向量机的原理,着重阐述这两个算法中的一些逻辑推导思路。
1.基础知识:函数距离(functional margins)和几何距离(geometrical margins)
假设 x∈Rn ,那么显然 wTx+b=0 是一个超平面。通过推导,空间中的任意一点 x(i) 到这个超平面的距离为
假设我们有样本点 A(x(i),y(i)),y(i)∈{1,−1} ,
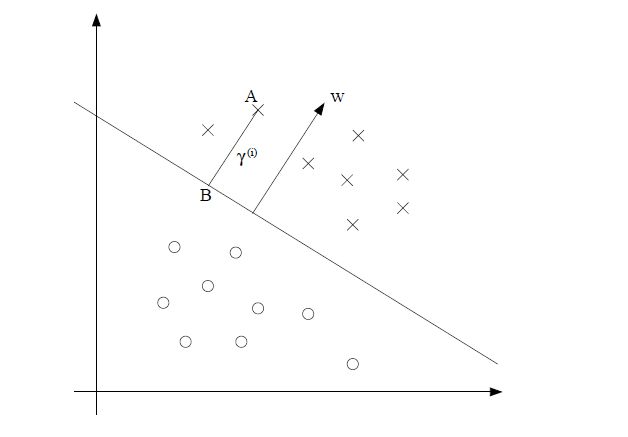
我们定义几何距离(geometrical margins)为
接着我们定义函数距离(functional margins)为
这两个距离有什么特征呢?
① 函数距离可以表示分类的正确性和确信度:当 wTx(i)+b>0 时,说明样本A在超平面的上方,也就属于1类(记上图圆点为-1,叉点为1),如果此时 y(i) =1,那么A样本分类正确, γ^(i)>0 ;否则 γ^(i)<0 。
② 同倍数扩大或缩小w、b,超平面是不变的,函数距离会同等增减;而几何距离不变,因为点到固定平面的距离是不变的。
③ γ^(i)=γ^∗||w||
那这些特性有什么用呢?其实它们在感知计算法中起着重要作用
2.感知机(Perceptron)
利用特性①,我们可以判断样本点是否分类正确,最终画出一个超平面能把线性可分的数据正确分类(注意是线性可分的训练数据);利用特性②,我们可以用误分类样本点的几何距离之和来表示模型的损失函数。
1、具体地,对于误分类点来说, −y(i)(wTx(i)+b)>0 ,所以所有误分类点到超平面的总距离是
M为误分类的集合。这里我们可以直接省略 1||w|| ,就得到感知机学习的损失函数 L(w,b)=−∑x(i)∈My(i)(wTx(i)+b) 。
为什么可以直接省略 1||w|| ?
(1).因为感知机模型是以误分类点为驱动的,最后损失函数的值必然为零,即无误分类点。所以根据特性①,既然函数距离能判断样本点的分类正确性,我们何必用几何距离呢?实际上我们并不关心lost function具体数值的变化,我们只在乎还有没有误分类点。
(2).去掉 1||w|| ,我们得到的lost function是关于w,b的连续可导线性函数,可以用梯度下降法轻松地进行优化。
2、利用随机梯度下降法SGD,损失函数的梯度为
随机选取一误分类点,对w,b进行更新:
3、算法:
给定数据集T,学习率 η
(1)选取初值 w0,b0
(2)根据函数距离选取误分类点
(3)更新 w,b
(4)转至(2),直至没有误分类点
4、可证明对于线性可分数据集,感知机算法是收敛的,具体见《统计学习方法》。
3.支持向量机(SVM)
3.1.从感知机(Perceptron)到支持向量机(SVM)
感知机学习算法会因采用的初值不同而得到不同的超平面。而SVM试图寻找一个最佳的超平面来划分数据,怎么算最佳呢?我们自然会想到用最中间的超平面就是最好的。如下图
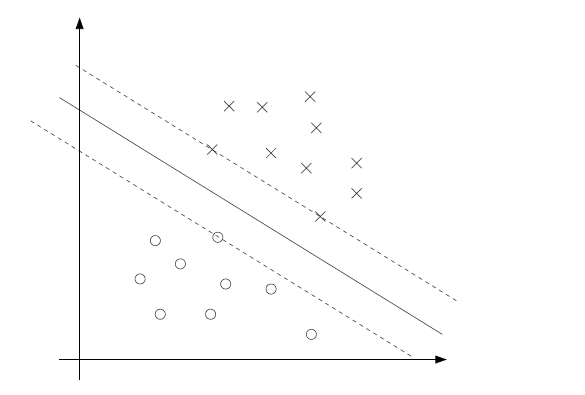
显然在SVM中我们不能在使用函数距离 γ^(i) 来作为损失函数了,当我们试图使上图虚线之间的”gap”,最大自然要用几何距离。
我们定义
通过最大化 γ 就可以找到最大的gap。
根据特性③,我们可以将上面的优化问题转化为
可是这个优化问题并不容易求解,我们期望目标函数是一个凸函数,这样优化起来就比较方便了。
这时注意到函数距离的特性②,我们可以直接让 γ^=1 。Why?假设我们这个优化问题的最优解是 wopt,bopt ,那么我们可以总是可以同倍数地调整 wopt,bopt 使得 γ^=1 ,而此时最优超平面是不变的,所以上面的优化问题可以化成
这样SVM模型就转化为了一个二次规划问题(Quadratic Programming)。此时我们可以用matlab的一些工具来处理这个优化问题了,可是一旦数据量变大,计算就会变得很缓慢。所以我们此时把这个优化问题转化为一个拉格朗日对偶问题,此时不仅能简化计算,更能引入SVM中最重要的kernel概念。啥是拉格朗日对偶问题?为什么能简化计算?什么是kernel?为什么能引入kernel?好吧,我承认问题有很多,不过让我们一一来窥探。
3.2. Lagrange Duality
首先来看看wiki上对Lagrange Multipler和Lagrange Duality的说明
Lagrange Multipler:In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints.
1.对于最简单的只有等式约束的规划问题,例如:
这个优化问题可以粗略地用函数等高线图来表示
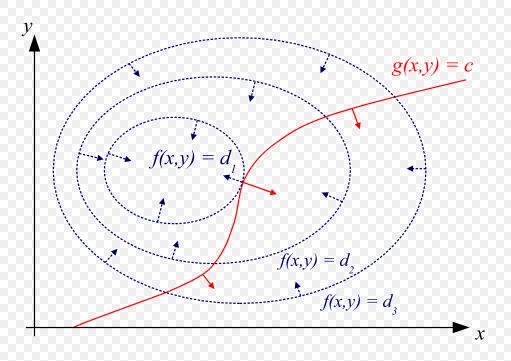
我们的目标就是要找到一点相切点 (x0,y0) ,使得 f(x,y) 达到最小值,因为梯度和等高线图是垂直的,所以 f(x,y)和g(x,y) 在点 (x0,y0) 上的梯度是平行的,此时, ∇x,yf=−λ∇x,yg ,其中 ∇x,yf=(∂f∂x,∂f∂y) , ∇x,yg=(∂g∂x,∂g∂y) , −λ 就是两个向量的平行参数。
我们可以引入一个拉格朗日乘子 λ 得到Lagrange Function
那么令 ∇x,yL=0 就是平行条件, ∇λL=0 就是原始问题的等式约束,这样就把原问题放到一个Lagrange Function中求解。
2.对于更一般的优化问题的原始问题,会有不等式约束例如:
原问题的定义域: D=(∩mi=0domfi)∩(∩pj=1domhj)
可行点(feasible): x∈D ,且满足约束条件。
可行域:所有可行点的集合F。
最优化值: p∗=inf{f0(x)|fi(x)⩽0,hj(x)=0} (求下确界inf和求最小值min在这里是等价的)
注意定义域和可行域的差别:定义域和约束条件无关,一般来说定义域大于可行域。
步骤1:定义一个Lagrange函数为
假设对L函数在 x∈D 上逐点求下确界(参考boyd的《convex optimization》)的函数是
如果我们把原问题的约束条件 (fi(x)⩽0,hj(x)=0) 代入Lagrange function,那么对于原问题中可行域F中的任意可行点 x˜ 有
这个不等式可以推导出两个结果:
① 因为L函数后两项小于等于0,所以, maxλ,νL(x,λ,ν)=f0(x) (注:这里的 f0(x) 是关于x的函数),进而
我们称这个式子为对偶问题中的Primal Problem
② 因为L函数后两项小于等于0,所以
(注:这里的 f0(x˜) 是一个具体的值)
根据下确界的性质:一系列函数逐点下确界必然小于等于这一系列函数,有
因为 x˜ 是可行域F中的任意值,所以
记 dual problem 的最优值为 d∗ 的话,根据上面的推导,我们就得到了如下性质:
步骤2:图形解释
如果上面公式没有理解,我们可以通过画图来理解一下拉格朗日对偶性。
我们还是把原问题的约束条件代入Lagrange function,为了简化图像,我们假设L只有一个不等式约束 f1(x) 且没有等式约束,原问题的函数图像大致如下:
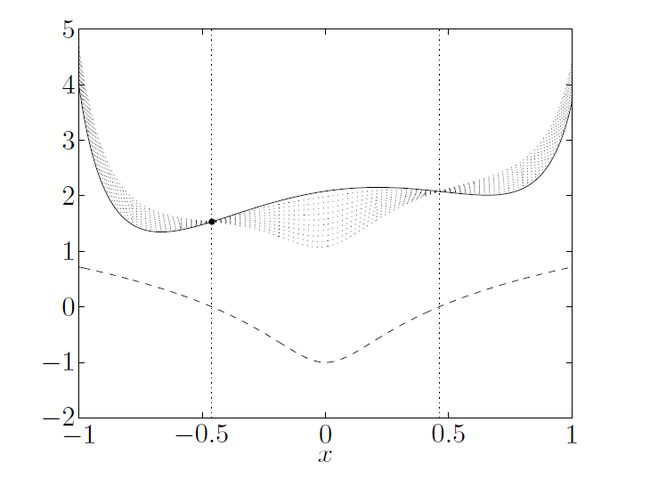
解释:最上面这条是原函数 f0(x) ,最下面的虚线是约束函数 f1(x) ,中间的这10条虚线分别是 λ=0.1,0.2,...,1 时,L函数的图像。在图中我们还可以看到,定义域D至少是[-1,1](图像没画完整),可行点集合F为[-0.46,0.46]
那么根据上图我们可以画出右侧 g(λ) 的图像:
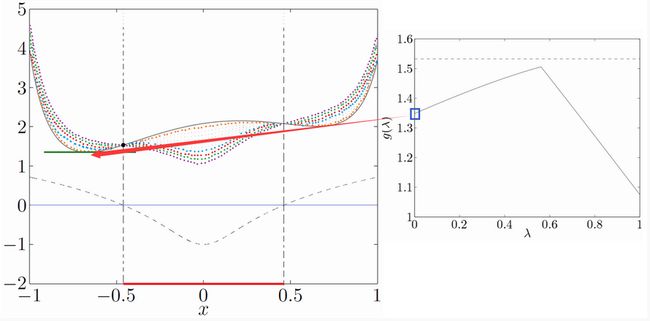
解释:因为 g(λ,ν) 是在 x∈D 上求下确界的,所以我们要考虑定义域D[-1,1]上L的最小值。 g(λ) 的图像上的那条虚线其实是原问题的最优解 p∗=f0(−0.46)=1.54 。
可以看到 maxg(λ) 是小于最优解 p∗ 的,约束条件 f1(x) 在这里的作用是保证 g(λ) 的下降。
步骤3:
通过数学分析和图形解释,我们都可以看到dual problem和primal problem的关系,即
通常我们把 d∗⩽p∗ 的情况叫做weak duality, d∗=p∗ 的情况叫做strong duality, p∗−d∗ 被称作duality gap。需要注意的是,无论 primal problem是什么形式,dual function总是凹的(因为它是关于 λ,ν 的线性函数),dual problem总是一个 convex optimization 的问题——它的极值是唯一的(如果存在的话)。
与原始问题的最优解相比,dual function多了后面
这个就是对偶互补条件 complementary slackness:从形式上看,当 λi>0 时,必须有 fi(x)=0 ;当 fi(x)<0 时,必须有 λi=0 。这就是说,当对偶问题的约束条件不起作用时,原问题的约束条件必须要起作用,反之亦然,或者说,只有原问题的起作用的约束才对应着非零的对偶变量。
然后根据前面的lagrange乘子法,我们要 maxλ,νminxL(x,λ,ν) ,就要
至此,我们得到了著名的Karush–Kuhn–Tucker (KKT) conditions:如果函数 fi(x) 是凸函数且可微, hj(x) 是仿射函数,当满足(1),(2),(3),(4),(5)时, d∗=p∗ 。
其证明比较简单,见pluskid的blog。这里的对偶问题我感觉我讲的很晦涩,pluskid的比较清楚详细,我主要引入一些优化理论中的结论。
步骤4(将lagrange duality应用到svm中):
① svm的最初优化问题:
②lagrange function:
primal problem:
假设 d∗ 是最优解。
③dual problem:
假设 p∗ 是最优解。
只要kkt条件成立,即:
就能使 w∗,b∗ 是原始问题的驻点, α∗ 是对偶问题的驻点,且 d∗=p∗ 。
步骤5:
最后我们来看看wiki上对拉格朗日对偶性的解释
Lagrange Duality:In mathematical optimization theory, duality means that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem (the duality principle). The solution to the dual problem provides a lower bound to the solution of the primal (minimization) problem. However in general the optimal values of the primal and dual problems need not be equal. Their difference is called the duality gap. For convex optimization problems, the duality gap is zero under a constraint qualification condition. Thus, a solution to the dual problem provides a bound on the value of the solution to the primal problem; when the problem is convex and satisfies a constraint qualification, then the value of an optimal solution of the primal problem is given by the dual problem.
这里我加粗了一些名词和句子,这些都是拉格朗日对偶性的重要性质。
3.2. 支持向量机(SVM)基础
根据complementary slackness,当 αi>0 时, y(i)(w∗x(i)+b∗)−1=0 ,即样本i与超平面的函数距离为1,也就是最近点。

虚线上的三个点就称为支持向量(support vectors)。
回顾KKT条件:
在问题中我们已经满足了条件(9)(10),然后我们依次来看剩余的条件。
根据(6)有
那么把w和(7)代回L中有
这时我们通过kkt条件消去了 maxαminw,bL(w,b,α) 中的 w,b 。
最终将primal problem化为了求解
可以看到对偶之后的约束条件比原来的约束条件简单了很多,简化了计算,之后我们用SMO算法求解这个优化问题的时候也可以见其方便性。
当我们求出 α∗i 之后,就可以得到
那么b的取值必然是两个离决策面最近的异类样本(支持向量)的中点,即
这里b需要对任意样本满足对偶互补条件(8)。
于是得到了最终的决策面
至此我们通过了所有KKT条件的要求,得到了最终决策面。其实对偶互补条件会在我们使用SMO算法计算的时候来也要作为一个更新约束的(后文的更新b规则),所以对偶互补条件是作为最后一道关卡的。Cool!
3.3. 核技巧(kernels):处理非线性数据
当数据是线性可分时,我们可以直接采用上面得到的线性SVM模型,可是当数据不可分时,我们要非线性SVM模型。
从Linear regression可以联想到,如果要处理线性不可分的情况,样本特征函数除了原始特征 x1,x2,...,xn ,我们还要引入一些特殊项,比如 x21,x31,x1x2等 ,我们的特征函数为
之前我们通过对偶化把原问题写成了x的内积形式 (x(i)⋅x) ,所以特征函数变化之后,我们可以直接代入 (ϕ(x(i))⋅ϕ(x)) ,这就是我们的Kernel:
通过Kernel就可以处理非线性函数了,不过这里有个问题,如果原始特征是2维,那通过特征组合加上常数项, ϕ(x) 就有6维;原始特征是3维的话, ϕ(x) 就有20维。这个数目是呈爆炸性增长的,而且如果遇到无穷维的情况,就根本无从计算了。
不过如果kernel是这样的话,且x原始特征有3维:
惊奇的发现就这么一个平方式就把 (x⋅z) 算好了,而且此时的 ϕ(x) 就是 ∑ni,j=1xixj,∑ni=12c−−√xi,c 的组合:
(注意:这里只是两个特征之间的组合,如果3个特征组合的话,那 K(x,z)=(xTz+c)3 ,这样可以得到20维的 ϕ )
核函数通过巧妙的计算,把高维 ϕ(x) 的计算转化成了低维原始空间的计算,大大降低计算复杂度,实现了线性不可分数据的分割。
常用的几个核函数:
多项式核 K(x,z)=(xTz+c)d :显然刚才我们举的例子是这里多项式核的一个特例(R = c,d = 2)。这个核所对应的特征空间 ϕ(x) 的维度是 Cdn+d ,n是原始空间的维度。
高斯核 K(x,z)=exp(−||x−z||22σ2) ,将高斯核泰勒展开为
线性核 K(x,z)=(x⋅z) ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
当然不是每个函数都可以作为核函数的,关于kernel的有效性可以参考mercer定理。
3.4. svm的泛化能力:正则化处理
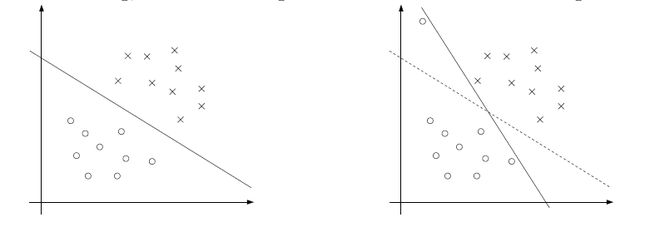
右图只因为一个数据(这种异常数据称作outlier)而大幅度地改变了分割平面,这是我们不想看到的;当使用kernel处理线性不可分数据时,我们没法保证处理之后就一定是线性可分的。
基于以上两点不足之处,我们把SVM模型改为
其中 ξ 称为松弛变量 (slack variable) ,对应数据点允许偏离的 functional margin 的量。当然,如果我们运行 ξ 任意大的话,那任意的超平面都是符合条件的了。所以,我们在原来的目标函数后面加上一项,使得这些的总和也要最小,这样就做到了相互制约。其中 C 是一个参数,用于控制目标函数中两项(“寻找 margin 最大的超平面”和“保证数据点偏差量最小”)之间的权重。注意,其中 ξ 是需要优化的变量(之一),而 C 是一个事先确定好的常量。
优化后模型的拉格朗日函数:
通过 ∇w,b,ξ=0 得到对偶问题就是:
根据KKT的对偶互补条件
和
得
以上给出了不同数值的lagrange乘子 αi 所对应于的样本与决策面之间的位置关系。由于决策面 ∑mi=1αiy(i)k(x(i),x)+b=0 是由非零 αi 的样本确定的,因此我们把 αi>0 的样本称为支持向量。其中 0<αi<C 时,样本与决策面的函数距离为1; αi=C 时,样本就是outliers。
3.4. SMO优化算法(Sequential minimal optimization)
SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。关于SMO最好的资料就是他本人写的《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》了。
SMO算法的核心思想就是分治法,把大问题化成一个个小问题。
SMO的主要步骤如下:

意思是,第一步选取一对 αi 和 αj ,选取方法使用启发式方法(后面讲)。第二步,固定除 αi 和 αj 之外的其他参数,然后就变成了二元优化问题,可以直接用换元法求解。不断重复,直到优化函数收敛。
首先把原问题变成最小化形式是
接下来就来野生推导smo了:
(一) 确定 α1 和 α2 的范围
假设选取变量 α1 和 α2 ,固定其他 αi ,根据 ∑mi=1αiy(i)=0 有
ς 是常数。
①当样本1,2异类,即一个为1,一个为-1,函数 α1y(1)+α2y(2)=ς 的图像如下:
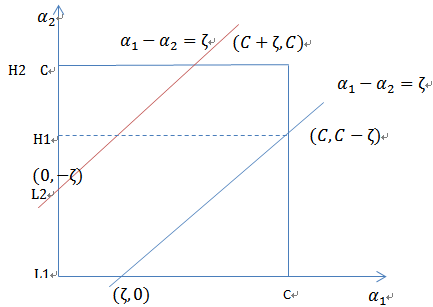
可以看出更新后的