全面理解SVM
支持向量机
看了JULY君的博客和文档后,个人对SVM的理解和总结,欢迎交流和指正。其理论部分可以查看下面文档链接,通俗易懂。
支持向量机通俗导论(理解SVM的三层境界)
第一篇:从四个关键词理解SVM
第二篇:SVM的原理(全面理解SVM)
第三篇:SVM的特点与不足
第四篇:SVM实现
第五篇:从应用上理解SVM
第一篇:从四个关键词理解SVM
理解支持向量机SVM(Support Vector Machine)有四个关键名词:分离超平面、最大边缘超平面、软边缘、核函数。
- 分离超平面(separating hyperplane):处理分类问题的时候需要一个决策边界,类似楚河汉界,在界这边我们判别A,在界那边我们判别B。这种决策边界将两类事物相分离,而线性的决策边界就是分离超平面。
- 最大边缘超平面(Maximal Margin Hyperplane):分离超平面可以有很多个,怎么找最好的那个呢,SVM的作法是找一个“最中间”的。换句话说,就是这个平面要尽量和两边保持距离,以留足余量,减小泛化误差,保证稳健性。或者用中国人的话讲叫做“执中”。以江河为国界的时候,就是以航道中心线为界,这个就是最大边缘超平面的体现。在数学上找到这个最大边缘超平面的方法是一个二次规划问题。
- 软边缘(Soft Margin):但世界上没这么美的事,很多情况下都是“你中有我,我中有你”的混杂状态。不大可能用一个平面完美的分离两个类别。在线性不可分情况下就要考虑软边缘。软边缘可以破例允许个别样本跑到其它类别的地盘上去。但要使用参数来权衡两端,一个是要保持最大边缘的分离,另一个要使这种破例不能太离谱。这种参数就是对错误分类的惩罚程度C。
- 核函数(Kernel Function),为了解决完美分离的问题,SVM还提出一种思路,就是将原始数据映射到高维空间中去,直觉上可以感觉高维空间中的数据变的稀疏,有利于“分清敌我”。那么映射的方法就是使用“核函数”。如果这种“核技术”选择得当,高维空间中的数据就变得容易线性分离了。而且可以证明,总是存在一种核函数能将数据集映射成可分离的高维数据。看到这里各位不要过于兴奋,映射到高维空间中并非是有百利而无一害的,维数过高的弊端就是会出现过度拟合。
所以选择合适的核函数以及软边缘参数C就是训练SVM的重要因素。一般来讲,核函数越复杂,模型越偏向于拟合过度。在参数C方面,它可以看作是LASSO算法中的lambda的倒数,C越大模型越偏向于拟合过度,反之则拟合不足。实际问题中怎么选呢?用人类最古老的办法,试错。常用的核函数有如下种类:
- Linear:使用它的话就成为线性向量机,效果基本等价于Logistic回归。但它可以处理变量极多的情况,例如文本挖掘。
- polynomial:多项式核函数,适用于图像处理问题。
- Radial basis,高斯核函数,最流行易用的选择。参数包括了sigma,其值若设置过小,会有过度拟合出现。
- sigmoid:反曲核函数,多用于神经网络的激活函数。
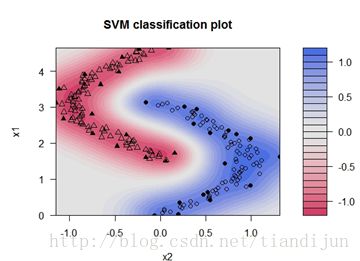
R语言中可以用e1071包中的svm函数建模,而另一个kernlab包中则包括了更多的核方法函数,本例用其中的ksvm函数,来说明参数C的作用和核函数的选择。我们先人为构造一个线性不可分的数据,先用线性核函数来建模,其参数C取值为1。然后我们用图形来观察建模结果,下图是根据线性SVM得到各样本的判别值等高线图(判别值decision value相当于Logistic回归中的X,X取0时为决策边界)。可以清楚的看到决策边界为线性,中间的决策边缘显示为白色区域,有相当多的样本落入此区域。
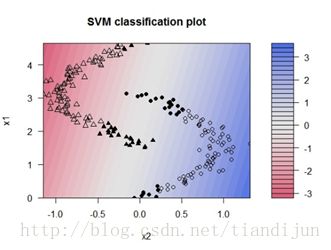
下面为了更好的拟合,我们加大了C的取值,这样如下图所示。可以预料到,当加大惩罚参数后决策边缘缩窄,也使训练误差减少,但仍有个别样本未被正确的分类。
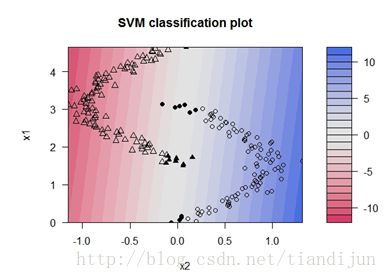
最后我们换用高斯核函数,这样得到的非线性决策边界。所有的样本都得到了正确的分类。
在实际运用中,为了寻找最优参数我们还可以用caret包来配合建模,并且如同前文那样使用多重交叉检验来评价模型。还需要注意一点SVM建模最好先标准化处理。最后来总结一下SVM的优势:1)可用于分类、回归和异常检验2)可以发现全局最优解3)可以用参数来控制过度拟合问题
第二篇:SVM原理
支持向量机基本上是最好的有监督学习算法。其公式推导具体可以参见链接:
http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982639.html
http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982684.html
http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html这份SVM的讲义重点概括了SVM的基本概念和基本推导,中规中矩却又让人醍醐灌顶。起初让我最头疼的是拉格朗日对偶和SMO,后来逐渐明白拉格朗日对偶的重要作用是将w的计算提前并消除w,使得优化函数变为拉格朗日乘子的单一参数优化问题。而SMO里面迭代公式的推导也着实让我花费了不少时间。
对比这么复杂的推导过程,SVM的思想确实那么简单。它不再像logistic回归一样企图去拟合样本点(中间加了一层sigmoid函数变换),而是就在样本中去找分隔线,为了评判哪条分界线更好,引入了几何间隔最大化的目标。
之后所有的推导都是去解决目标函数的最优化上了。在解决最优化的过程中,发现了w可以由特征向量内积来表示,进而发现了核函数,仅需要调整核函数就可以将特征进行低维到高维的变换,在低维上进行计算,实质结果表现在高维上。由于并不是所有的样本都可分,为了保证SVM的通用性,进行了软间隔的处理,导致的结果就是将优化问题变得更加复杂,然而惊奇的是松弛变量没有出现在最后的目标函数中。最后的优化求解问题,也被拉格朗日对偶和SMO算法化解,使SVM趋向于完美。
另外,其他很多议题如SVM背后的学习理论、参数选择问题、二值分类到多值分类等等还没有涉及到,以后有时间再学吧。其实朴素贝叶斯在分类二值分类问题时,如果使用对数比,那么也算作线性分类器。
第三篇:SVM的特点与不足
SVM有如下主要几个特点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。 (4)SVM是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。(5)SVM的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响;②支持向量样本集具有一定的鲁棒性;③有些成功的应用中,SVM方法对核的选取不敏感
两个不足:
(1)SVM算法对大规模训练样本难以实施
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
第四篇:SVM实现
实现的代码很多,实例效果图可以参考:(JAVA版本)
http://blog.csdn.net/dark_scope/article/details/16902033
不同语言的代码可以参考链接:
http://download.csdn.net/detail/tiandijun/8056453
详细的可以参见
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
第五篇 应用方面理解SVM
http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html
一、线性分类器:
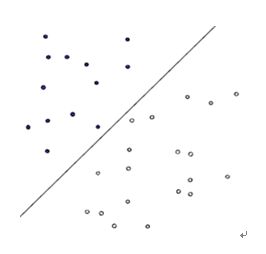
首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线)
假如,令黑色的点= -1, 白色的点=+1,直线f(x)= w.x + b,其中x、w是向量,其实写成这种形式也是等价的f(x)= w1x1 + w2x2 … + wnxn + b, 当向量x的维度=2的时候,f(x)表示二维空间中的一条直线,当x的维度=3的时候,f(x)表示3维空间中的一个平面,当x的维度=n> 3的时候,表示n维空间中的n-1维超平面。这些都是比较基础的内容,如果不太清楚,可能需要复习一下微积分、线性代数的内容。
黑色白色两类的点分别为+1,-1,所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),就可以预测了,sgn表示符号函数,当f(x)> 0的时候,sgn(f(x))= +1, 当f(x)< 0的时候sgn(f(x))= –1。
但是,我们怎样才能取得一个最优的划分直线f(x)呢?下图的直线表示几条可能的f(x)
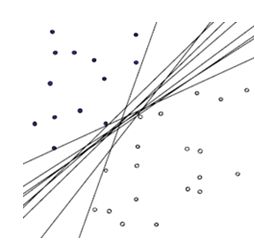
一个很直观的感受是,让这条直线到给定样本中最近的点最远,这句话读起来比较拗口,下面给出几个图,来说明一下:
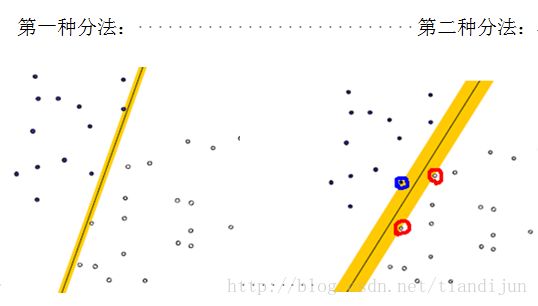
这两种分法哪种更好呢?从直观上来说,就是分割的间隙越大越好,把两个类别的点分得越开越好。在SVM中,称为MaximumMarginal,是SVM的一个理论基础之一。选择使得间隙最大的函数作为分割平面是由很多道理的,比如说从概率的角度上来说,就是使得置信度最小的点置信度最大(听起来很拗口),从实践的角度来说,这样的效果非常好等。
上图被红色和蓝色的线圈出来的点就是所谓的支持向量(supportvector)。
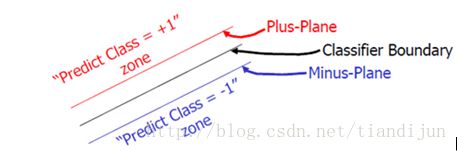
上图就是一个对之前说的类别中的间隙的一个描述。ClassifierBoundary就是f(x),红色和蓝色的线(plusplane与minusplane)就是supportvector所在的面,红色、蓝色线之间的间隙就是我们要最大化的分类间的间隙。

这里直接给出M的式子:(从高中的解析几何就可以很容易的得到了,也可以参考后面Moore的ppt)
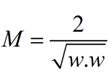
另外支持向量位于wx+ b = 1与wx+ b = -1的直线上,我们在前面乘上一个该点所属的类别y(还记得吗?y不是+1就是-1),就可以得到支持向量的表达式为:y(wx + b) = 1,这样就可以更简单的将支持向量表示出来了。
当支持向量确定下来的时候,分割函数就确定下来了,两个问题是等价的。得到支持向量,还有一个作用是,让支持向量后方那些点就不用参与计算了。这点在后面将会更详细的讲讲。
在这个小节的最后,给出我们要优化求解的表达式:
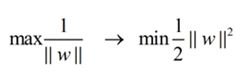
||w||的意思是w的二范数,跟上面的M表达式的分母是一个意思,之前得到,M= 2 / ||w||,最大化这个式子等价于最小化||w||,另外由于||w||是一个单调函数,我们可以对其加入平方,和前面的系数,这个式子是为了方便求导。
这个式子有还有一些限制条件,完整的写下来,应该是这样的:(原问题)
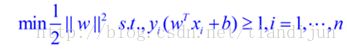
s.t是约束限制条件,这个其实是一个带约束的二次规划(quadratic programming, QP)问题,是一个凸问题,凸问题就是指的不会有局部最优解,可以想象一个漏斗,不管我们开始的时候将一个小球放在漏斗的什么位置,这个小球最终一定可以掉出漏斗,也就是得到全局最优解。s.t.后面的限制条件可以看作是一个凸多面体,我们要做的就是在这个凸多面体中找到最优解。这些问题这里不展开,因为展开的话,一本书也写不完。如果有疑问请看看wikipedia。
二、转化为对偶问题,并优化求解
这个优化问题可以用拉格朗日乘子法去解,使用了KKT条件的理论,这里直接做出这个式子的拉格朗日目标函数:
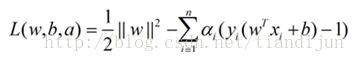
求解这个式子的过程需要拉格朗日对偶性的相关知识(另外pluskid也有一篇文章专门讲这个问题),并且有一定的公式推导,如果不感兴趣,可以直接跳到后面用蓝色公式表示的结论,该部分推导主要参考自plukids的文章。
首先让L关于w,b最小化,分别令L关于w,b的偏导数为0,得到关于原问题的一个表达式
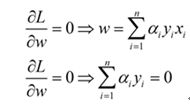
将两式代回L(w,b,a)得到对偶问题的表达式
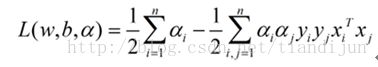
新问题加上其限制条件是(对偶问题):
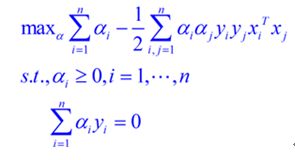
这个就是我们需要最终优化的式子。至此,得到了线性可分问题的优化式子。
求解这个式子,有很多的方法,比如SMO等等,个人认为,求解这样的一个带约束的凸优化问题与得到这个凸优化问题是比较独立的两件事情。
三、线性不可分的情况(软间隔):
下图就是一个典型的线性不可分的分类图,我们没有办法用一条直线去将其分成两个区域,每个区域只包含一种颜色的点。要想在这种情况下的分类器,有两种方式:
1)用曲线去将其完全分开,曲线就是一种非线性的情况(类似于核函数的作用)。

2)用直线(不保证可分性,包容那些分错的情况),得加入惩罚函数,使得点分错的情况尽量合理。
补充:
其实在很多时候,不是在训练的时候分类函数越完美越好,因为训练函数中有些数据本来就是噪声,可能就是在人工加上分类标签的时候加错了,如果我们在训练(学习)的时候把这些错误的点学习到了,那么模型在下次碰到这些错误情况的时候就难免出错了(假如老师给你讲课的时候,某个知识点讲错了,你还信以为真了,那么在考试的时候就难免出错)。这种学习的时候学到了“噪声”的过程就是一个过拟合(over-fitting),这在机器学习中是一个大忌,我们宁愿少学一些内容,也坚决杜绝多学一些错误的知识。
我们可以为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是这个点到其正确位置的距离:
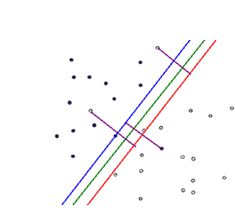
在上图中,蓝色、红色的直线分别为支持向量所在的边界,绿色的线为决策函数,那些紫色的线表示分错的点到其相应的决策面的距离,这样我们可以在原函数上面加上一个惩罚函数,并且带上其限制条件为:
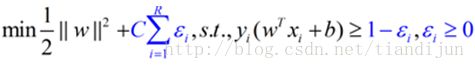
公式中蓝色的部分为在线性可分问题的基础上加上的惩罚函数部分,当xi在正确一边的时候,ε=0,R为全部的点的数目,C是一个由用户去指定的系数,表示对分错的点加入多少的惩罚,当C很大的时候,分错的点就会更少,但是过拟合的情况可能会比较严重,当C很小的时候,分错的点可能会很多,不过可能由此得到的模型也会不太正确,所以如何选择C是有很多学问的,不过在大部分情况下就是通过经验尝试得到的。
接下来就是同样的,求解一个拉格朗日对偶问题,得到一个原问题的对偶问题的表达式:
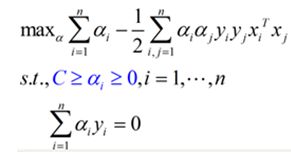
蓝色的部分是与线性可分的对偶问题表达式的不同之处。在线性不可分情况下得到的对偶问题,不同的地方就是α的范围从[0,+∞),变为了[0,C],增加的惩罚ε没有为对偶问题增加什么复杂度。
四、核函数:
上述谈不可分的情况下,如果使用某些非线性的方法,可以得到将两个分类完美划分的曲线,那么这个函数变换就是核函数。
让空间从原本的线性空间变成一个更高维的空间,在这个高维的线性空间下,再用一个超平面进行划分。
补充:
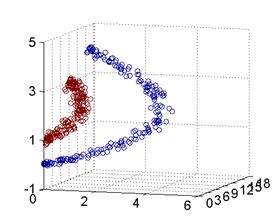
举例理解如何利用增加空间的维度来帮助我们分类的(例子以及图片来自pluskid的kernel函数部分):
下图是一个典型的线性不可分的情况

但是当我们把这两个类似于椭圆形的点映射到一个高维空间后,映射函数为:
用这个函数可以将上图的平面中的点映射到一个三维空间(z1,z2,z3),并且对映射后的坐标加以旋转之后就可以得到一个线性可分的点集了。
用另外一个哲学例子来说:世界上本来没有两个完全一样的物体,对于所有的两个物体,我们可以通过增加维度来让他们最终有所区别,比如说两本书,从(颜色,内容)两个维度来说,可能是一样的,我们可以加上 作者 这个维度,是在不行我们还可以加入 页码,可以加入 拥有者,可以加入 购买地点,可以加入 笔记内容等等。当维度增加到无限维的时候,一定可以让任意的两个物体可分了。
前面得到的对偶问题表达式: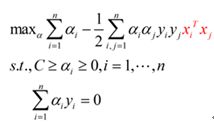
我们可以将红色这个部分进行改造,令:
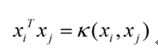
这个式子所做的事情就是将线性的空间映射到高维的空间,k(x,xj)有很多种,下面是比较典型的两种:

高斯核甚至是将原始空间映射为无穷维空间,另外核函数有一些比较好的性质,比如说不会比线性条件下增加多少额外的计算量等。一般对于一个问题,不同的核函数可能会带来不同的结果,一般是需要尝试来得到的。
五、一些其他的问题:
1)如何进行多分类问题:
上面所谈到的分类都是2分类的情况,当N分类的情况下,主要有两种方式,一种是1vs (N – 1)一种是1vs 1,前一种方法我们需要训练N个分类器,第i个分类器是看看是属于分类i还是属于分类i的补集(出去i的N-1个分类)。
后一种方式我们需要训练N* (N – 1) / 2个分类器,分类器(i,j)能够判断某个点是属于i还是属于j。
这种处理方式不仅在SVM中会用到,在很多其他的分类中也是被广泛用到,从林教授(libsvm的作者)的结论来看,1vs 1的方式要优于1vs (N – 1)。
2)SVM会overfitting吗?
SVM避免overfitting,一种是调整之前说的惩罚函数中的C,另一种其实从式子上来看,min||w||^2这个看起来是不是很眼熟?在最小二乘法回归的时候,我们看到过这个式子,这个式子可以让函数更平滑,所以SVM是一种不太容易over-fitting的方法。
参考文档:
主要的参考文档来自4个地方,wikipedia(在文章中已经给出了超链接了),pluskid关于SVM的博文,Andrew moore的ppt(文章中不少图片都是引用或者改自AndrewMoore的ppt,以及prml
参考资料:
1、AnIntroduction to Support Vector Machines and Other Kernel-based Learning Methods(中文译本叫支持向量机导论)
2、thenature of statistical learning theory(中文译本叫统计学习理论的本质)这本书偏重于理论
3、ADual Coordinate Descent Method for Large-scale Linear SVM,线性svm的一个效率很高的算法,针对的是对偶问题,思想是在不同的坐标方向上通过固定其它分量来最小化目标函数
4、Sequentialminimal optimization for SVM,SMO方法
5、PSVM:Parallelizing Support Vector Machines on Distributed Computers,另外一种思路,在Grim矩阵上做文章,利用不完全乔里斯基分解来实现并行的svm
6、这个网址下有较多资料
http://hi.baidu.com/zxdker/blog/item/bbe1571e625b1fcfa686692e.html
参考:
http://hi.baidu.com/izygqdpzndbacnd/item/b3328d82c8c848c499255f7a
http://www.r-bloggers.com/lang/chinese/1067
http://blog.csdn.net/u010555688/article/details/40046947
http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982639.html
http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982684.html
http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html