coursera-斯坦福-机器学习-吴恩达-第7周笔记-支持向量机SVM
coursera-斯坦福-机器学习-吴恩达-第7周笔记-支持向量机SVM
- coursera-斯坦福-机器学习-吴恩达-第7周笔记-支持向量机SVM
- 1大间距分类器 large margin classifier
- 1通过逻辑回归引入SVM
- 1宽边界分类器SVM
- 3SVM数学原理
- 2核函数
- 1核函数1简单例子讲解概念
- 2核函数2SVM计算步骤
- 3实践SVM
- 4复习
- 1quiz
- 2编程
- 1大间距分类器 large margin classifier
1大间距分类器 large margin classifier
1.1通过逻辑回归引入SVM
先回顾一下逻辑回归的相关概念
hθ(x)=11+e−θTx
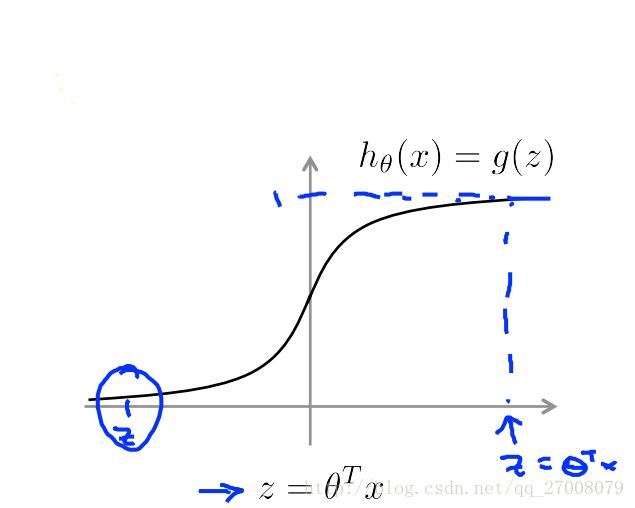
- IF y=1, we want hθ(x)≈1, θTx≫0
- IF y=0, we want hθ(x)≈0, θTx≪0
其CostFunction为:
J(θ)=1m[∑mi=1y(i)(−loghθ(x(i)))+(1−y(i))(−(log(1−hθ(x(i)))))]+λ2m∑mj=1θ2j
在SVM中对costfunction进行改变 :
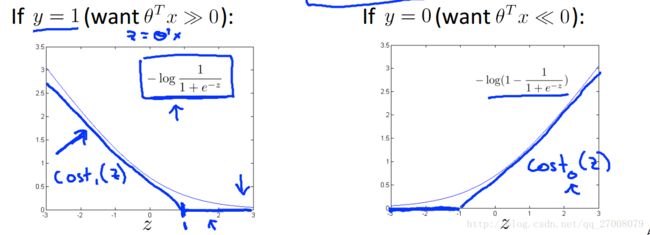
将其中log函数部分换成了蓝色折线所代表的cost函数。(更简洁)
costFunction也相应的改变为:
J(θ)=1m[∑mi=1y(i)Cost1(θTx(i))+(1−y(i))Cost0(θTx(i))]+λ2m∑mj=1θ2j然后在SVM中,我们用C代替λ
J(θ)=C∑mi=1[y(i)Cost1(θTx(i))+(1−y(i))Cost0(θTx(i))]+12∑mj=1θ2j
也就是通过逻辑回归,引出了SVM的代价函数:
J(θ)=C∑mi=1[y(i)Cost1(θTx(i))+(1−y(i))Cost0(θTx(i))]+12∑mj=1θ2j
1.1宽边界分类器SVM
SVM是一种“宽边界”分类器(Large Margin Intuition)。
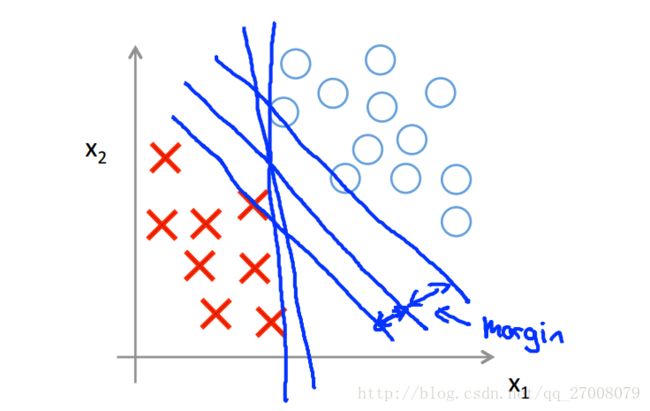
如图,SVM希望找到“最中间”的那条分界线(最宽边界)来分割两类。
我们一步步来看:
首先观察SVM代价函数的图像:
和逻辑回归相比较:
- IF y=1, we want θTx≥1 (not just ≥0)
- IF y=0, we want θTx≤−1 (not just ≤0)
同时,当C非常大时,我们希望蓝色的这部分为0
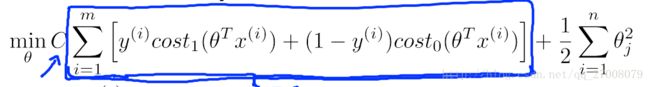
即min 12∑ni=1θ2j
总结一下:此时,我们把SVM的代价函数(目标函数)化简为了:
min 12∑ni=1θ2j
同时,这个函数的约束条件(S.T)为:
- θTx(i)≥+1(if)y(i)=1
- θTx(i)≤+1(if)y(i)=0
这是一个条件极值问题 。
1.3SVM数学原理
通过上一节简化问题,我们知道SVM要求的最小值为||θ||的最小值,即θ的范数最小值。模型如下:
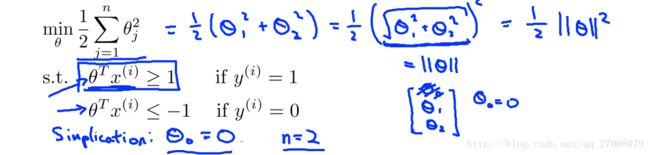
下面看一下限制条件代表的含义,通过高中数学,我们知道两个向量相乘(内积)的几何含义如下 :(向量A在另一条向量B上的映射×向量B的模)

通过上面可知,我们要求||θ||的最小值,因此我们希望 p(i) (x在θ上的映射)尽量大。只有这样才能使上面说的约束条件S.T满足。也就是SVM转变为了找到那个x在θ上的最大映射。
例子如下(θ为分界的法线(垂直)):
- 假如选择了下面图中的绿色线作为边界,我们会发现p(i)比较小,这样不能得出||θ||的最小值
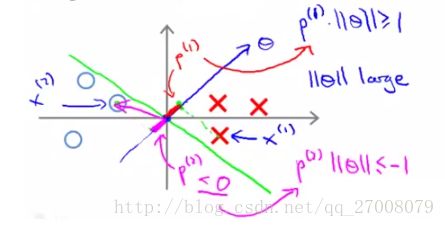
2. 如果选择下面的绿色线作为边界,我们可以得较长的映射p、和较小的||θ||值。

最后再来一张图来直观感受一下:
总结:
1. SVM 要找到最中间的边界。
2. 所以要找到最长的映射p。
3. 进而可以找到所求参数θ的最小值。
2核函数
2.1核函数1:简单例子讲解概念
引入:之前的课程中我们讲解了使用多项式解决非线性拟合问题 ,
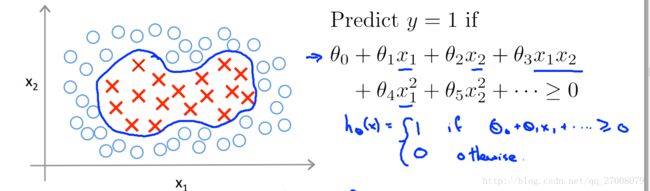
在这里我们通过引入核函数来解决这个问题。
假设函数 hθ(x)=θ0+θ1f1+θ2f2+θ3f3+⋯ (用f代替x的参数)这个函数为新的假设函数。
引入:
如果我们给出几个向量 l(i) 作为landmarks

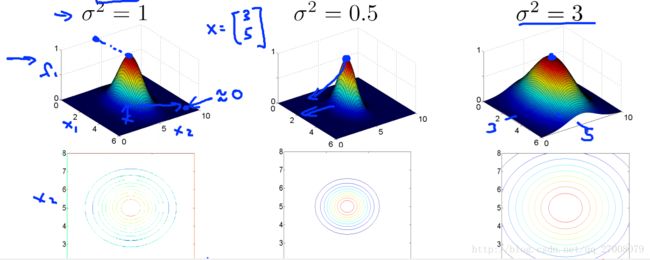
我们设置f函数,衡量标记点和原先样本点的相似性。 为 fi=similarity(x(i),l(i))=exp(−||x(i)−l(i)||22δ2)
exp中的函数为高斯核函数
在这种情况下,f的取值为:
if x(i)≈l(i) 时:
fi≈exp(−022δ2)≈1
if x(i) is far from l(i) 时:
fi≈exp(−(largenumber)22δ2)≈0
这样就表示了样本x的一种高维映射,里标记点越近值越高。
最后,我们需要研究δ对核函数的影响,通过图片看出,δ越大收敛慢,δ越小收敛快。
2.2核函数2:SVM计算步骤
上一节中的标记点,我们是随机选取的,但是这样不科学。
那么,关于landmarks我们应该怎么选取呢?
1. 一种比较好的方法,是将训练集中的正样本选取为标记点,如图:
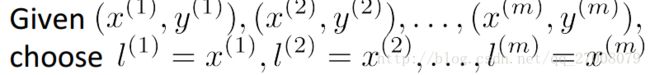
- 这样定义好l后,再定义每一个映射F。
此时,对于每一个训练集中的数据,我们都有一个m+1维向量与之对应。
- 每给定一个样本x,计算他与所有l的映射f:
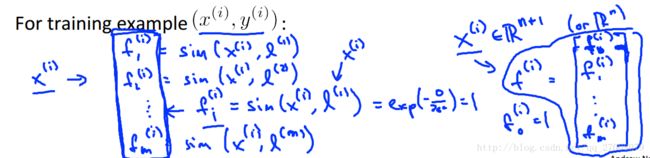
- 预测样本点的归属类:
在预测时,使用以下计算公式:

这个函数等价于: hθ(x)=θ0+θ1f1+θ2f2+θ3f3+⋯
以上就是已知参数θ时 ,怎么做出预测的过程。那么 怎样得到参数θ呢?
方法具体来说就是要求解这个最小化问题, 你需要求出能使这个式子取最小值的参数θ。
J(θ)=C∑mi=1[y(i)Cost1(θTf(i))+(1−y(i))Cost0(θTf(i))]+12∑mj=1θ2j
下面总结一些SVM中的参数对模型的影响,主要是两个方面:C和δ。
1.C
- 大C:低偏差,高方差(对应低λ,overfitting)因为C约等于λ的倒数。
- 小C:高偏差,低方差(对应高λ)
2. δ
- 大δ2:fi分布更平滑,高偏差,低方差
- 小δ2:fi分布更集中,低偏差,高方差 (overfitting)
3实践SVM
在实际工作中,我们往往使用已有的工具包中所包含的SVM。在使用时,我们需要注意其中的参数选定 :
1. 选择一个合适的C:
- 大C:低偏差,高方差(对应低λ,overfitting)因为C约等于λ的倒数。
- 小C:高偏差,低方差(对应高λ)
- 选择一个合适的核函数:
- linear kernel(No kernel)
- 高斯核
表达式如下:
另外一个问题什么时候选择SVM或逻辑回归?

如图:
1. 特征维度n很大:
使用逻辑回归和线性SVM.
2. 特征维度n小,样本数量m中等:
使用高斯核SVM。
3. 特征维度n小,且样本数量m巨大:
- 可以创建新的特征
- 然后使用逻辑回归和无核SVM
4复习
一种形象的解释:
你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。
现在,SVM大侠没有一根直棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
现在,从上面的角度看这些球,这些球看起来像是被一条曲线分开了。
再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
4.1quiz
- Suppose you have trained an SVM classifier with a Gaussian kernel, and it learned the following decision boundary on the training set:

You suspect that the SVM is underfitting your dataset. Should you try increasing or decreasing C? Increasing or decreasing σ2?
答案:A
- It would be reasonable to try increasing C. It would also be reasonable to try decreasing σ2.
- It would be reasonable to try decreasing C. It would also be reasonable to try increasing σ2.
- It would be reasonable to try increasing C. It would also be reasonable to try increasing σ2.
- It would be reasonable to try decreasing C. It would also be reasonable to try decreasing σ2.
- The formula for the Gaussian kernel is given by similarity(x,l(1))=exp(−||x−l(1)||22σ2).
The figure below shows a plot of f1=similarity(x,l(1)) when σ2=1.
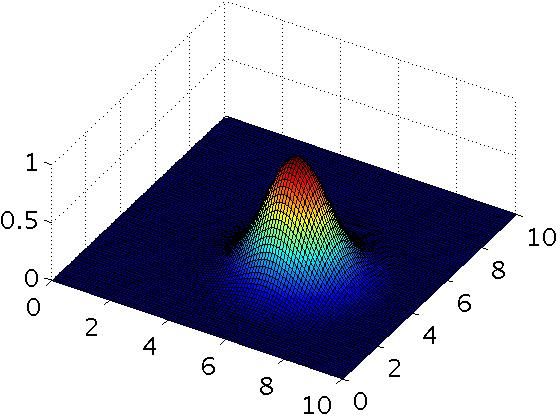
Which of the following is a plot of f1 when σ2=0.25?
答案D,σ减小,变瘦,低误差,容易overfitting
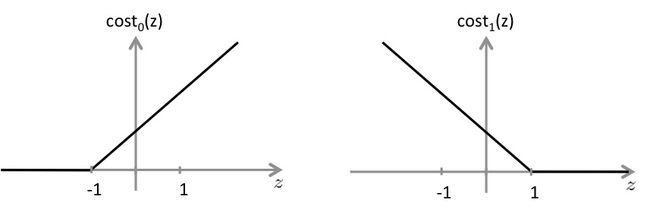
- The SVM solves
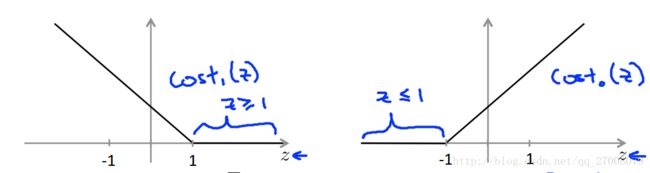
minθ C∑mi=1y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))+∑nj=1θ2j
where the functions cost0(z) and cost1(z) look like this:
The first term in the objective is:
C∑mi=1y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i)).
This first term will be zero if two of the following four conditions hold true. Which are the two conditions that would guarantee that this term equals zero?
答案CD
- For every example with y(i)=0, we have that θTx(i)≤0.
- For every example with y(i)=1, we have that θTx(i)≥0.
- For every example with y(i)=0, we have that θTx(i)≤−1.
- For every example with y(i)=1, we have that θTx(i)≥1.
- Suppose you have a dataset with n = 10 features and m = 5000 examples.
After training your logistic regression classifier with gradient descent, you find that it has underfit the training set and does not achieve the desired performance on the training or cross validation sets.
Which of the following might be promising steps to take? Check all that apply.
答案AC
- Try using a neural network with a large number of hidden units.
- Use a different optimization method since using gradient descent to train logistic regression might result in a local minimum.
- Create / add new polynomial features.
Reduce the number of examples in the training set.
- Which of the following statements are true? Check all that apply.
答案CD
- Which of the following statements are true? Check all that apply.
- Suppose you are using SVMs to do multi-class classification and would like to use the one-vs-all approach. If you have K different classes, you will train K - 1 different SVMs.
- If the data are linearly separable, an SVM using a linear kernel will return the same parameters θ regardless of the chosen value of C (i.e., the resulting value of θ does not depend on C).
- It is important to perform feature normalization before using the Gaussian kernel.
- The maximum value of the Gaussian kernel (i.e., sim(x,l(1))) is 1
4.2编程
在本练习的前半部分,您将使用具有各种示例2D数据集的支持向量机(SVM)。 对这些数据集进行实验将有助于您直观地了解SVM如何工作以及如何在SVM中使用高斯核函数。
作业所提供的脚本ex6.m将帮助您逐步完成练习的前半部分。
打开gaussianKernel.m填入:
sim = exp(-sum((x1 - x2).^2)/2/sigma^2);打开 dataset3Params.m 填入:
cc = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];
ss = cc;
maxx = 0;
for i=1:length(cc)
for j=1:length(cc)
model = svmTrain(X, y, cc(i), @(x1, x2) gaussianKernel(x1, x2, ss(j)));
predict = svmPredict(model, Xval);
cur = mean(double(predict == yval));
if maxx < cur
maxx = cur;
C = cc(i);
sigma = ss(j);
end
end
end在下半年的练习中,您将使用支持向量机来构建垃圾邮件分类器。
今天的许多电子邮件服务都提供了垃圾邮件过滤器,可以将电子邮件以高精度分类为垃圾邮件和非垃圾邮件。 在这部分练习中,您将使用SVM构建您自己的垃圾邮件过滤器。 您将会训练一个分类器来分类给定的电子邮件x是垃圾邮件(y = 1)还是非垃圾邮件(y = 0)。 特别是,您需要将每个电子邮件转换为一个特征向量x∈R n。 练习的以下部分将引导您如何通过电子邮件构建这样的特征向量。
在本练习的其余部分中,您将使用脚本ex6 spam.m. 本练习包含的数据集基于SpamAssassin公共语料库的一个子集。 3为了本练习的目的,您只能使用电子邮件正文(不包括电子邮件标题)。
打开 processEmail.m填入:
for i=1:length(vocabList)
if strcmp(vocabList{i}, str)
word_indices = [word_indices; i];
break;
end
end打开emailFeatures.m
填入:
for i=1:length(word_indices)
x(word_indices(i)) = 1;
end