hive实现txt数据导入,理解hadoop中hdfs、mapreduce
背景:通过hive操作,了解hadoop的hdfs、mapreduce。
场景:hadoop双机集群、hive
版本:hadoop和hive的版本搭配最和谐的是什么,目前没有定论,每种版本的搭配都会有一些bug出现。
本例中版本:hadoop-1.0.3 hive-0.10.0-bin
实现:将本地的网络访问日志文件导入到hive中。
hive demo command list
step1:登录hive创建表
[root@master conf]# hive

hive> create table dq_httplog
(ipdz string,
ll string,
sj string,
khd string,
fwq string,
ym string,
urlmc string
)
row format delimited
fields terminated by '\t' lines terminated by '\n'
stored as textfile;
(ipdz string,
ll string,
sj string,
khd string,
fwq string,
ym string,
urlmc string
)
row format delimited
fields terminated by '\t' lines terminated by '\n'
stored as textfile;
step2:导入本地txt文件数据;
hive> load data local inpath '/httplog.txt' into table dq_httplog;
可以用hive QL语句查看数据和表结构
查看数据的过程就是hive将hive QL语句转换成mapreduce语句在hadoop中执行。
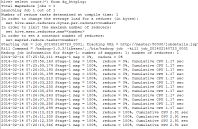
查看表结构:
hive> describe dq_httplog;
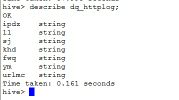
hive中创建的表是以文件的形式存储在hdfs中的
在hadoop中查询
[root@master ~]# hadoop dfs -lsr /user/hive/warehouse

在hive中查询
hive> dfs -lsr /user/hive/warehouse
step3:创建分区表
create table dq_httplog_part
(ll string,
khd string,
fwq string,
ym string,
urlmc string
)
partitioned by (ipdz string,sj string comment 'this is login time')
row format delimited
fields terminated by '\t' lines terminated by '\n'
stored as textfile;
fields terminated by '\t' lines terminated by '\n'
stored as textfile;
注:分区字段必须放在最后面;
导入数据时可以指定分区,也可以动态分区导入数据,动态分区先要设置动态分区的参数;
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
设置完动态分区的参数后,可以动态导入数据,导入过程会按数据情况自动分区;
hive> insert into table dq_httplog_part partition(ipdz,sj) select ll,khd,fwq,ym,urlmc,ipdz,sj from dq_httplog;
同样可以查看到表数据文件和表结构等等;
hive> dfs -lsr /user;
hive>show partitions dq_httplog_part;
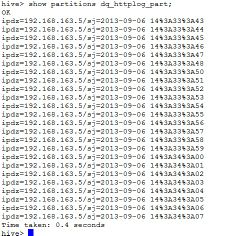
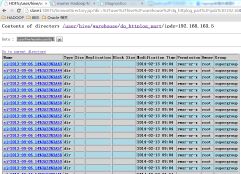
step4:hive web接口
hive web接口可以利用浏览器访问网络接口,完成数据库及表结构的查询,hive查询,系统诊断等;
[root@master bin]# hive --service hwi
登录http://master:9999/hwi 可以使用webui和hive交互
数据库查询:
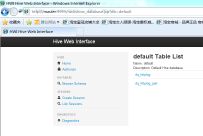
表结构查询:
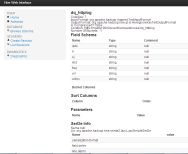
系统诊断:
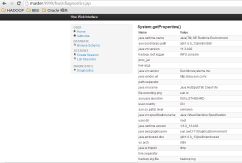
step5:hive中的查询和计算
建表和导入数据完成后就可以在hive中进行复杂查询和计算了,并可以将结果已多种形式保存。

常见错误:
1、Hadoop集群安全模式未关闭,查看创建文件时报错:
mkdir: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/hive/warehouse. Name node is in safe mode.
bin/hadoop dfsadmin -safemode leave 关闭安全模式就可以了;
hadoop的安全模式简介: http://mazd1002.blog.163.com/blog/static/66574965201111304657632/
bin/hadoop dfsadmin -safemode leave 关闭安全模式就可以了;
hadoop的安全模式简介: http://mazd1002.blog.163.com/blog/static/66574965201111304657632/
2、启动hive时:
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
解决方法:将hive/conf的
template文件copy一份,便于个性化配置;
- cp hive-default.xml.template hive-default.xml
- cp hive-default.xml.template hive-site.xml
- cp hive-env.sh.template hive-env.sh
- cp hive-log4j.properties.template hive-log4j.properties
将hive-log4j.properties中将log4j.appender.EventCounter的值修改为
org.apache.hadoop.log.metrics.EventCounter,
这样就不会报WARNING了。
# log4j.appender.EventCounter=org.apache.hadoop.metrics.jvm.EventCounter
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
3、copy完hive配置文件后,重新启动hadoop或者运行hive时:
- hive-site.xml:180:3: The element type "description" must be terminated by the matching end-tag "".
- Exception in thread "main" java.lang.RuntimeException: org.xml.sax.SAXParseException: The element type "description" must be terminated by the matching end-tag "".
解决方法:根据提示的行数,修改hive_site.xml文件。上面的报错就是hive_site.xml的180行没有
结尾。
4、启动hive的web接口服务hwi时:
hive-site.xml not found on CLASSPATH
解决方法:需要配置
haddoop的hadoop_env.sh,
如下添加$HADOOP_CLASSPATH,hive/conf,hive/bin,hive/lib
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/hive-0.10.0-bin/conf/:
/hive-0.10.0-bin/bin:/hive-0.10.0-bin/lib