Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单、易用的APIs,支持跨多种语言(比如:Scala、Java、Python和R)来操作大数据。
本文主要讲解Apache Spark 2.0中RDD,DataFrame和Dataset三种API;它们各自适合的使用场景;它们的性能和优化;列举使用DataFrame和DataSet代替RDD的场景。文章大部分聚焦DataFrame和Dataset,因为这是Apache Spark 2.0的API统一的重点。
Apache Spark 2.0统一API的主要动机是:追求简化Spark。通过减少用户学习的概念和提供结构化的数据进行处理。除了结构化,Spark也提供higher-level抽象和API作为特定领域语言(DSL)。
弹性数据集(RDD)
RDD是Spark建立之初的核心API。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和action。
那什么时候用RDD呢?
使用RDD的一般场景:
- 你需要使用low-level的transformation和action来控制你的数据集;
- 你的数据集非结构化,比如:流媒体或者文本流;
- 你想使用函数式编程来操作你的数据,而不是用特定领域语言(DSL)表达;
- 你不在乎schema,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
- 你放弃使用DataFrame和Dataset来优化结构化和半结构化数据集。
RDD在Apache Spark 2.0中惨遭抛弃?
DataFrame
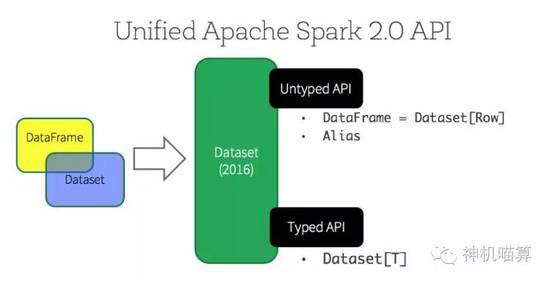
Dataset
| Language | Main Abstraction |
|---|---|
| Scala | Dataset[T] & DataFrame (alias for Dataset[Row]) |
| Java | Dataset |
| Python* | DataFrame |
| R* | DataFrame |
Dataset API的优势
2. High-level抽象以及结构化和半结构化数据集的自定义视图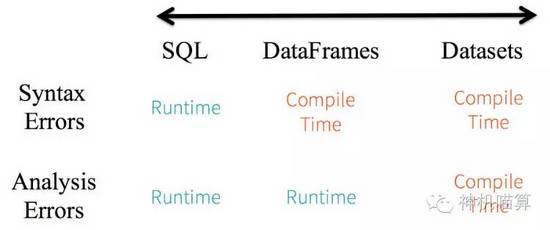
{
"device_id": 198164,
"device_name": "sensor-pad-198164owomcJZ",
"ip": "80.55.20.25",
"cca2": "PL",
"cca3": "POL",
"cn": "Poland",
"latitude": 53.08,
"longitude": 18.62,
"scale": "Celsius",
"temp": 21,
"humidity": 65,
"battery_level": 8,
"c02_level": 1408,
"lcd": "red",
"timestamp": 1458081226051
}case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String,
cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long,
ip: String, latitude: Double, lcd: String, longitude: Double,
scale:String, temp: Long, timestamp: Long)// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read.json("/databricks-public-datasets/data/iot/iot_devices.json").as[DeviceIoTData]这个时候有三个事情会发生:
- Spark读取JSON文件,推断出其schema,创建一个DataFrame;
- Spark把数据集转换DataFrame -> Dataset[Row],泛型Row object,因为这时还不知道其确切类型;
- Spark进行转换:Dataset[Row] -> Dataset[DeviceIoTData],DeviceIoTData类的Scala JVM object。
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)4. 性能和优化
使用DataFrame和Dataset API获得空间效率和性能优化的两个原因:
✈ 首先,DataFrame和Dataset API是建立在Spark SQL引擎之上,它会使用Catalyst优化器来生成优化过的逻辑计划和物理查询计划。R,Java,Scala或者Python的DataFrame/Dataset API使得查询都进行相同的代码优化以及空间和速度的效率提升。

✈ 其次,Spark作为编译器可以理解Dataset类型的JVM object,它能映射特定类型的JVM object到Tungsten内存管理,使用Encoder。Tungsten的Encoder可以有效的序列化/反序列化JVM object,生成字节码来提高执行速度。
什么时候使用DataFrame或者Dataset?
- 你想使用丰富的语义,high-level抽象,和特定领域语言API,那你可以使用DataFrame或者Dataset;
- 你处理的半结构化数据集需要high-level表达,filter,map,aggregation,average,sum,SQL查询,列式访问和使用lambda函数,那你可以使用DataFrame或者Dataset;
- 你想利用编译时高度的type-safety,Catalyst优化和Tungsten的code生成,那你可以使用DataFrame或者Dataset;
- 你想统一和简化API使用跨Spark的Library,那你可以使用DataFrame或者Dataset;
- 如果你是一个R使用者,那你可以使用DataFrame或者Dataset;
- 如果你是一个Python使用者,那你可以使用DataFrame或者Dataset。
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)总结
通过上面的分析,什么情况选择RDD,DataFrame还是Dataset已经很明显了。RDD适合需要low-level函数式编程和操作数据集的情况;DataFrame和Dataset适合结构化数据集,使用high-level和特定领域语言(DSL)编程,空间效率高和速度快。