计算机网络——从直连网络到以太网
1. Ch1-1 计算机网络体系结构
搞清楚网络的基本概念 :要会计算几个重要的性能参数。
1.1. 什么是计算机网络?
计算机网络是互联的通用计算机的集合。
1.2. 构成
网络 = {节点,链路} = {V,L}
节点(Node):
端节点:自身拥有计算机资源的源宿用户设备
转接节点:支持网络连通并在网络中对数据起交换和转接的节点,如 交换机/路由器/集线器
链路(Link):
物理链路:在物理层连接两个节点的物理介质,如电话线、同轴电缆、光纤、无线电波
逻辑链路:
在两点间通过通信协议的作用建立起来的数据联结通路
通路(Path):
从源点到宿点所经过的一串节点和链路的有序集。或端到端的通路
协议(Protocol)
多个进程为完成一个任务而共同遵守的动作序列规范
三要素:语法、语义、规则(同步时序)
网络云:
区分通信子网交换交换结点(云内)和资源主机结点(云外)的分界线,可表示任何网络(单、多、交换等)
1.3. 网络性能测量与评价
性能测量的两个参数:带宽和延迟
1.3.1. 带宽(Bandwidth): Hz,KHz,MHz,GHz,bps
信号带宽:构成一信号的各种不同频率成分所占据的频率范围。如人类声音带宽为:3300Hz-300=声音带宽3000Hz
媒体带宽:通信媒体允许通过的信号频带范围
比特率:某时段内网络上可能传输的比特数,或传输每比特数据所需的时间宽度。习惯把“带宽”作为数字信道的数据率或比特率
比特率越高,高频分量越多,频率范围越大,信号带宽越高。
吞吐率(Throughput):bps
数字信号的发送速率,因此发送带宽也成为吞吐率,由于各种影响 10M 带宽实际完成 2Mbps
吞吐率:链路上实际每秒传输的比特数
1.3.2. 延迟
定义:延迟 = 处理+排队+传输+传播,主要考虑后两个
处理时延:检查包首部、决定导向何处;比特差错检测,高速Router一般在微秒或更低数量级,接收完整的一个分组的时间=包容量/链路速率
排队时延:等待输出链路空闲,与当时流量和排队规则有关
传输时延:数据量/带宽;微秒到毫秒级
传播时延:距离/光速(光缆中1000km传播延迟约5ms) 广域网在毫秒级
Delay : 把一个报文从网络一端传输到另一端所需的时间one way,光传播
速度:
3.0x10^8m/s ;光在真空内传播的速率
2.8x10^8m/s ;电在Cable内传播的速率
2.0x10^8m/s ;光在Fiber内传播的速率
Round Trip Time (RTT):发收来回时间(2次时延)
传输/传播的比较
传输时延是路由器把分组发送出去所需时间,由数据量和链路实际带宽
决定,与两个路由器间距离无关,
传播时延是一个比特从发送路由器到接收路由器传播所需的时间,是距
离的函数,ms级
1.3.3. 延迟带宽积(以太网相关参数)
一对进程通道间的延迟(总体延迟)带宽积:信道管道的体积=链路上所容纳的比特数
一个信道延迟=50ms ,带宽45Mbps, 则能容纳=50ms* 45Mbps=5010^-3 sec45Mbits/sec =2.25Mbits
等价于信道上同时可以存在281K个Byte信号(2.25M/8)
1.4. 评价参数
加性参数
时延、抖动、路径长度、路由代价…
满足可加性:通道特性由沿途各段链路相加决定
乘性参数
可靠性、丢包率
满足可乘性:度量为各链路或设备的乘积…
极性参数(最短木板原理)
带宽、剩余能量、生存时间、吞吐量…
满足极值要求(凹性或凸性),由通道或设备的瓶颈属性(极
值)决定
1.5. 传输可靠性
什么是传输可靠性
数据最小颗粒能正确到达
数据不同分片能有序到达(当采用分组交换时)
计算机网络并不是一个完备的世界
机器坏/光纤断/电接口受干扰/交换缓存溢出
网络设计者要考虑三种类型的故障
1)链路上的单比特错,突发连续比特错。
铜缆:10^6—— 10^7
光缆:10^12— 10^14
2)包错:一个包在网络上丢失
包中包含有不可纠正的比特错
中继接点因故(缓冲满,TTL)丢掉
输出链路故障等
3)结点和链路级故障
物理链路断
相连计算机崩溃
电源断电
操作失误
1.6. Internet管理
IETF是各种工作组提出RFC,是互联网工程师主要活动组织
ISOC是非盈利组织,为IETF、IAB、IESG、IRTF提供经济和法律支持,但不负责具体事务,董事会选举IAB和IESG
IAB负责长期规划和对IESG投诉处理
IESG负责管理IETF,分为各个领域总监
1.6.1. 参数计算常见习题
端到端吞吐率 = 实际传输大小/传输时间
实际传输时间 = RTT+ 传输大小/信道带宽
RTT:请求与回答时间
问题1 :信道带宽1Gbps,一端到另一端传播时延τ= 10ms,TCP发送窗口65535字节。问可能达到的最大吞吐率T ?信道利用率ρ?
解析:
T= size/(2τ+size/BW)
= size*BW/(2τ*BW+size) bps
= 65535*8*10^9/(20*10^9*10^-3s+65535*8)bps
= 524280*10^3/(20 *10^6 +524280)Mbps
= 25.5 Mbps,
ρ=25.5M/1000M=2.55%
问题2:一局域网最大距离为2KM,对于100Byte的数据包,在带宽为多少时,传播时延等于传输时延?512Byte的数据包呢?(光速为3*10^8 M/S)
解:τ =d/v = 2000m/3*10^8m/s
t=size/BW
BW = v*size/d
2. 直连网络-最简单的网络
- 调制、编码、成帧 :几种编码方案以及它们的优缺点,成帧需要的技术
- 信道共享技术
- 差错控制技术
2.1. 直连网络-Links
香农定理决定了一个链路传输能力上限
这个传输能力C用bps为单位,跟链路上信号的信噪比相关(S/N,decibels or dB)
C = B*log2 (1+S/N)
标准音频电话线支持的典型频率范围为300~3300Hz,信道带宽是3kHz。
其中C是可达的信道容量,单位为bps,B是用Hz表示的信道带宽(3300Hz-300Hz=3000Hz),S是信号的平均功率,N是噪声的平均功率。信噪比(S/N,或SNR)通常用dB表示,计算公式如下:
SNR = 10 * log10 (S/N)
假设我们有一个典型的信噪比为30dB,这表示S/N=1000。因此我们有
C = 3000 * log2 (1001)
2.2. 编码技术
信号调制:修改信号的幅度、频率和相位及其组合形式来标示和携带数据信息的过程
调制的一个原因:
我们知道链路上信噪比的重要性,影响信号的噪声在不同频率上的强度并非完全一样。
如果能把原始信号移动到噪声频率谱上噪声强度最低的频率上去,就可以避开本底噪声很高的区域,和其他没有被彻底屏蔽掉的干扰信号。
信号调制时,需要选择一个「载波」——这个载波就可以选择系统噪声强度最低区域的频率。
信号的物理层处理
模拟→模拟;(调制)
模拟→数字;(编码)
数字→数字;(编码)
数字→模拟。(调制)
2.3. 编码方案(NRZ、NRZI、曼彻斯特、4B/5B)
NRZ:这是一种不归零的编码方案,将数值1映射为高电平,数值0映射为低电平。这种方案存在的问题1是连续的1或0易导致基线漂移,即接收方保持它所接收的信号平均值用来区分高低电平受到干扰。问题2是编解码需要双方的时钟同步,这依赖于信号内有许多跳变,只有信号跳变才能进行时钟同步。
NRZI:不归零反转,跳变表示1,将不变表示0。这样就解决了连续1的问题,但是显然未解决连续0的问题。
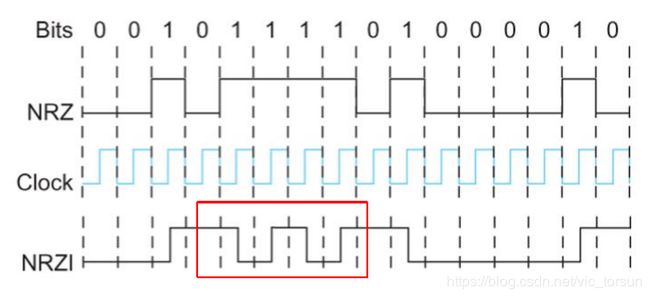
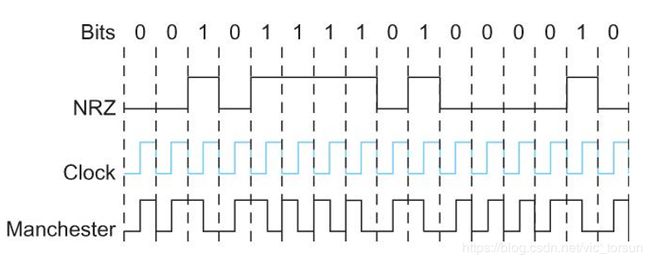
曼彻斯特编码:传输NRZ编码与时钟的异或值。(把本地时钟看作一个从低到高变化的内部信号,一对低/高变化的电平看作一个时钟周期)可理解为一个比特使用了两个本地时钟周期。
上面这张图可以简单理解为由于是和0/1做异或,则前半个曼彻斯特编码周期一定与NRZ相同,后半个周期一定相反。
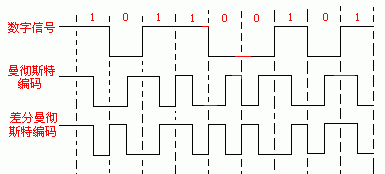
差分曼彻斯特编码:若信号的前一半与前一比特信号的后一半信号相等则编码为1,反之编码为0。
可记为差分曼彻斯特每位中间的跳变仅提供时钟定时,而用每位开始时有无跳变表示"0"或"1",有跳变为"0",无跳变为"1"。
4B/4B:由于曼彻斯特编码中比特率是波特率的一半,为解决低效的问题。4B/5B编码力图 通过在比特流中插入额外的比特以打破一连串的0或1。准确的讲就是用5个比特来编码4个比特的数据,5比特的代码是通过以下方式选定的:每个代码最多有一个前导0,并且末端最多有两个0。因此,当连续传送是,最多有三个连续的0,因为NRZI已经解决了连续1的问题。注意4B/5B的编码效率为80%。
由于5个比特足以编码32个不同代码,因此我们只用了16个,剩下十六个可用于其他目的。
2.4. 组帧
Frame是一个在具体网络(与类型和厂家有关)第二层上实现的、与硬件有关的特殊分组。是网上传输的最小数据单元。
Frame=数据部分+发送和接收站点的物理地址+处理控制部分。
2.4.1. 面向字节的协议
编帧最老的方法是面向字符终端协议
BISYNC:Binary Synchronous Communication Message Protocol,面向 字节的协议由IBM开发,以字节(8bit)为单位,开始是SYN,SOH( Start Of Header)
DDCMP:Digital Data Communication Message Protocol, 用于DECNET 都支持ASCII
PPP/SLIP
BISYNC使用称为起止字符(sentinel character)的特定字符表示帧的开始与结束。一帧的开始由发送一个特定的SYN(同步)字符表示。其后帧的数据部分包含在两个特殊的起止字符之间:STX(正文开始符)和ETX(正文结束符)。SOH(首部开始符)字段与STX字段的目的是一样的。自然,起止标记法存在的问题是ETX字符可能会出现在帧的数据部分。
BISYNC通过对ETX字符“转义”的方法解决这个问题,无论ETX出现在帧体中什么位置,都在其前加上一个DLE(数据链路转义)字符,帧体中的DLE字符也采用同样的方法(在其前多加一个DLE)处理。(C程序员可能注意到,这类似于当引号出现在一个字符串中时用反斜线转义的处理方法。)因为要在帧的数据部分插入额外的字符,所以这种方法常称为字符填充法(character stuffing)。
2.4.2. 面向比特协议
不关心字节的边界 把帧看做比特的集合 可能是ASCII码、图像的象素值、指令、操作数或IP电话的声音值
SDLC:Synchronous Data Link Control Protocol
Developed By IBM ,was later Standardized by OSI as HDLC
面向Byte和面向Bit的协议,会发现有些特殊字符或者Bit序列作为帧开始、结束、控制标志,那么如果 Body/Payload中有这些标志怎么办?
Character stuffing: 在特殊字符前加上data-link-escape (DLE) Body中有DLE,那么变成两个DLE
Bit stuffing
头尾标志是01111110
零比特插入技术,5个连续‘1’插‘0’
发送时插入 01111111 = 011111011
接收时删除 011111011 = 01111111
2.4.3. 基于时钟的帧(SONET)
基本SONET帧每125us产生810字节,有无数据都同步发送,故每秒8000帧
9x90=810 Bytes/s x 8000=51.84Mbps,构成基本SONET信道
每帧前3列留作系统管理信息。当段开销的头两个字节A1,A2出现时,接收方就认为这是同步状 态,并能正确解释帧
2.5. 信道共享技术
信道:Channel是通信中传递信息的通道,它由发送与接收信息的设备及传 输介质组成。信道有独占或共享两种使用方式
复用:把共享信道划分成多个子信道,每个子信道传输一路数据
复用方法
- 时分复用TDM (Time Division Multiplexing)-统计时分复用STDM
按时间划分不同的信道,目前应用最广泛 - 频分复用FDM (Frequency Division Multiplexing) 按频率划分不同的信道,如CATV系统
- 波分复用WDM (Wave Division Multiplexing:DWDM/CWDM) 按波长划分不同的信道,用于光纤传输
- 码分复用CDM (Code Division Multiplexing) 按地址码划分不同的信道,如手机
2.6. 差错控制技术
什么是差错控制?
在通信过程中,发现、检测差错并进行纠正
为何要进行差错控制?
不存在理想的信道→传输总会出错 与语音、图像传输不同,计算机通信要求极低的差错率。
基本思想:发方编码、收方检错,能纠则纠,不能则重传
基本方法:收方进行差错检测,并向发送方应答,告知是否 正确接收。
差错控制技术:自动请求重传ARQ(Automatic Repeat Request)
停等ARQ :每发送一帧就需要一个应答帧
只重传刚才出错的帧
Go-back-N ARQ :每发送N帧需要一个应答帧
需重传前面(N-i+1)帧(0≤i≤N)
选择重传ARQ :每发送N帧需要一个应答帧
只重传出错的帧
2.7. 检验纠错
任何检验纠错技术的基本思想: 纠错码主要有编码方法: 网卡功能 MAC地址 对10Mbps 802.3 LAN的改进 100Base-TX 100Base-FX 100Base-T4(4根线收发) 和 100Base-TX(2根线收发)统称 100Base-T 两种类型的HUB 随着网络速度的提高,共享信道方式越来越不适应发展 工作方式 PAUSE协议 2002.6月正式发布802.3ae 10GE标准 长距离(40-50KM)网络 两种物理层技术: 以太网封装比SONET/SDH更简单且成本更低 40 Gbps已成为过渡产品 2010年6月22日,IEEE802.3ba和100Gb/s以太网技术标准已经正式获审通过。 国内华为、中兴;国外Juniper Network、CISCO;上海贝尔已经开发出了自有标准100Gbps以太网接口路由器 集线器(HUB):物理层互连设备 交换机(Switch):链路层互连设备 广播域:广播报文可以达到的范围 不依赖三层交换,通过虚拟局域网VLAN,可以将同一交换机或者多个交换机的广播域划分多个广播域(每个虚拟局域网一个广播域) 交换机可以通过学习自动得到转发表。但是一旦交换机连接存在环路,会造成严重后果。 当交换机之间存在多条活动链路时,容易形成环路,导致转发表的不正确与不稳定,并且还会导致重复的数据包在网络中传递,引起广播风暴,使网络不稳定。 为了防止交换机之间由于多条活动链路而导致的网络故障,必须将多余的链路置于非活动状态,即不转发用户数据包,而只留下单条链路作为网络通信。 要实现此功能,需要依靠生成树协议(Spanning Tree Protocol)来完成,STP将交换网络中任何两个点之间的多余链路置于Blocking(关闭)状态,而只留一条活动链路,当使用中的活动链路失效时,立即启用被Block的链路,以此来提供网络的冗余效果。 从理论上一个LAN可以看作一个图graph,这个图可能循环 (cycles) spanning tree实际是这个图的一个子图sub-graph,但是可以到达所有节点 Spanning Tree协议 STP为IEEE标准协议,并且有多个协议版本,版本与协议号的对应关系如下: 去掉环路的方法:所有交换机按照树的方式进行连通 STP的核心思想是网络中选出一台交换机做为核心交换机,STP称其为Root,也就是根,功能相当于hub-spoke网络中的Hub。 其它不是Root的交换机则需要留出一条活动链路去往根交换机,因为只要普通交换机到根是通的,到其它交换机也就是通的。 只有在一个广播能够到达的范围内,才需要进行相同的STP计算与选举,也就是一个广播域内独立选举STP 下图中网络被路由器分割成两个广播域,所以在两个网段中,需要进行独立的STP计算与选举。 交换机之间选举根交换机(Root) 交换机端口之间选举根端口(Root Port) 非根交换机选择指定端口(Designated Port) 剩余端口状态为Blocking BPDU(Bridge Protocol Data Unit) Path cost计算 端口ID总共占16bit,其中8位是端口优先级,8位是端口编号,所以端口优先级部分的取值范围是0-255,缺省值为128. 根端口(Root port) 指定端口(Designated port) 第二种类型的BPDU包:Topology Change Notification(TCN) BPDU。 用户识别地址:公司/机关/团体/个人注册的因特网可访问的ID:域名 ICMP 报文分类 ICMP报文封装在IP数据包中进行传输 ICMP最典型的应用 自治域AS 内部网关协议IGP:在一个AS内运行 外部网关协议EGP:在AS间运行 LSP(link-state packet) 为什么使用随机初始序号? 一方先关闭: ESTABLISHED → FIN_WAIT_1 →FIN_WAIT_2→TIME_WAIT → CLOSED. IGMP实现的功能是双向的:一方面,主机通过IGMP协议通知本地路由器希望加入并接收某个特定组播组的信息;另一方面,路由器通过IGMP协议周期性地查询局域网内某个已知组的成员是否处于活动状态(即该网段是否仍有属于某个组播组的成员),实现对所连网络组成员关系的收集与维护。 如果要让路由器也能像转发单播数据一样,将组播根据路由表来精确地转发到目的地,那就需要让路由器拥有像单播路由表一样的组播路由表。 组播源会向所有PIM邻居发出查询,查询数据包中包含组的地址,下一跳PIM邻居路由器还会继续向它的邻居发出查询数据包,这些查询数据包会在所有PIM邻居之间传递。 如果查询数据包到一个连接了组成员的网络,这时路由器收到组成员的报告之后,就会向自己上一跳邻居(RPF接口方向的邻居)发送加入组的消息,以宣布自己要接收组播,从而将组播转发到组成员。 PIM-SM模式路由器不仅需要记录(*,G)信息,也和PIM-DM模式一样需要记录在该组中,哪些接口是出口,从此接口将数据发给接收者。 QoS能力 A.地址的三种文本表示,以方便怎样阅读、输入和操作 CIDR形式 共分3级,6个部分
加入冗余信息到帧中去(极端:两份拷贝)
一般为n位信息加入k<
3. 报文交换
3.1. 以太网
3.1.1. 以太网卡与MAC地址模式
数据的封装与解封
链路管理:CSMA/CD
bit的编码与解码
Unicast:单播帧地址,仅对某个网卡
Broadcast:广播帧地址,仅对某个子网
Multicast:多播帧地址,组地址
杂收模式:Promiscuous mode:接收总线上所有的可能接收的帧3.1.2. 高速局域网:快速以太网100Mbps
局域网发展史上重要里程碑
Fast Ethernet标准
1995年,IEEE通过802.3u标准,实际上是802.3的一个补充。原有的帧格式、接口、规程不变,只是将每比特时间从100ns缩短为10ns。3.1.3. 高速局域网:100Base-TX/F
使用2对5类平衡双绞线或150Ω屏蔽平衡电缆,1对 to the hub,1对from the hub,支持全双工;
5类双绞线使用125 MHz的信号;
4B/5B编码,5个时钟周期发送4个比特,物理层与FDDI兼容使用NRZ-I编码,比特率为125 * 4/5 = 100 Mbps;
使用2根多模光纤,支持全双工,物理层和FDDI兼容
共享式HUB,一个冲突域,工作方式与802.3相同,CSMA/CD,二进制指数后退算法,半双工 …
交换式HUB,输入帧被缓存,一个端口构成一个冲突域。
共享信道跟全双工是矛盾的
100Base-FX在半双工模式下,为了兼容以太网报文,为了确保检测到碰撞,最大长度为412米。但是在全双工模式下,则可达到2000m,如果用Repeater,可以到10公里
共享信道意味着所有主机在一个冲突域,主机数量一多冲突的概率大大
增加。3.1.4. 高速局域网: 1000Mbps以太网
IEEE 802.3定义的10M/100M以太网一致的CSMA/CD帧格式
以太网交换机(全双工模式)中的千兆端口不能采用共享信道方式访问介质,不使用 CSMA/CD 协议,而只能采用全双工方式.
在使用双绞线的情况下,可以通过自动协商机制,切换到半双工方式下仍使用 CSMA/CD 协议
编码采用8b/10b encoding和NRZ
双绞线很少用,因为同时5对线收发产生串扰
规范发展完善了PAUSE协议,不采用CSMA/CD协议完成全双工操作。
该协议采用不均匀流量控制方法,最先应用于100M以太网中。
流控
利用802.3定义的Pause控制帧进行流量控制,要求发送数据节点暂停数据发送,避免缓冲区溢出造成的丢包。
只有在全双工时,才支持Pause流控,半双工时不支持流控。3.1.5. 万兆(10Gbps)以太网
只全双工,不支持单工和半双工,也不采用CSMA/CD
不持自协商;提供广域网物理层接口。
扩展了网络的覆盖区域,且标准简化。
支持现存的大量SONET网络兼容
局域网物理层LAN PHY;10.000Gbps精确10G;
广域网物理层WAN PHY;OC-192,异步SONET/SDH
与10M/100M/1000Mbps帧格式完全相同;3.1.6. 100Gbps以太网
3.1.7. 以太网的连接设备
1进多出,相同速率,无帧缓冲/线障隔离,使用方便
带宽受限 ,广播风暴 ,单工传输,通信效率低
依帧头信息转发以太帧;
实现方法
直接交换方式
存储转发方式
改进直接交换方式。3.2. 广播域和冲突域
冲突域:可以发生报文冲突的范围(交换以太网每个端口处于独立冲突域)3.3. 虚拟局域网
3.4. 交换机生成树协议
3.4.1. Span Tree

需要所有交换机支持
IEEE 802.1 标准规定了LAN 交换机必须支持
每个交换机实际上需要disable掉自己的某些端口,不转发frame
极端情况下,可能一个交换机完全不参与任何frame的转发
Common Spanning Tree (CST) = IEEE 802.1D
Rapid Spanning Tree Protocol (RSTP)=IEEE 802.1w
Per-VLAN Spanning-Tree plus (PVST+)=Per-VLAN IEEE 802.1D
Rapid PVST+=Per-VLAN IEEE 802.1w
Multiple Spanning Tree Protocol (MSTP)=IEEE 802.1s3.5. 生成协议

一个广播域内只能选举一台根交换机。Birdge-ID中优先级最高(即数字最小)的为根交换机,优先级范围为0-65535,如果优先级相同,则MAC地址小的为根交换机。
所有非根交换机都要选举根端口,选举规则为到根交换机的Path Cost值最小的链路。
简单地理解为每条连接交换机的link有两个端口(属于不同交换机)中,有一个要被选举为指定端口。
选举规则和选举根端口一样,即:到根交换机的Path Cost值最小的端口,如果多条链路到达根交换机的Path Cost值相同,则选举上一跳交换机Bridge-ID最小的链路。
在STP选出根交换机,根端口以及指定端口后,其它所有端口全部为Blocking状态,为了防止环路,所有Blocking端口只有在根端口或指定端口失效、拓扑改变的时候才会被启用。
一个端口,在STP中只能处于一种角色,不可能是两种角色3.6. 选举
交换机间用BPDU报文来选举,目的地址为layer2 multicast address 01:80:C2:00:00:00 :
Protocol ID 固定为0。
Version:0为802.1d,1为802.1w,2为802.1s。
Message type:0为普通BPDU,80为TCN(Topology Change Notification)。
Flags字段:802.1d时只用到0位和7位,都和TCN相关,TCN的ACK报文里0位置1,TC报文里7位置1。
Root ID,Cost of path,Bridge ID,Port ID:用于选举。
每个交换机会把自己链路的代价加上接收到的邻居交换机的Path Cost,得到总的PathCost。3.7. 选举过程
3.7.1. 例子

根交换机(Root)
因为4台交换机的优先级分别为SW1(4096) ,SW2(24576),SW3(32768),SW4(32768),选举优先级最高的(数字最低的)为根交换机,所以SW1被选为根交换机,如果优先级相同,则比较MAC地址。
所有链路为100 Mb/s,即PathCost值为19;128为port ID
反映速率低于1Gbit/s的宽带链路的STP开销:
带宽
STP开销
4 Mbit/s
250
100 Mbit/s
19
1 Gbit/s
2
根端口需要在除SW1外的非根交换机上选举。
SW2从端口F0/23到达根的Path Cost值为19,从F0/19和F0/20到达根的Path Cost值都为19×3=57。因此,F0/23被选为根端口。
SW3上F0/19被选为根端口。
SW4上从所有端口到达根的Path Cost值都为19×2=38,接下来比较上一跳交换机Bridge-ID,选择SW2,再比较对端端口优先级,选择F0/20
根交换机上所有的端口都应该是指定端口。
在SW3连接SW4的两个link中,同样也是SW3上的两个端口离根交换机最近,所以在这两个link中,选举SW3上的端口为指定端口。
在SW2连接SW4的两个link中,同样也是SW2上的两个端口离根交换机最近,所以在这两个link中,选举SW2上的端口为指定端口。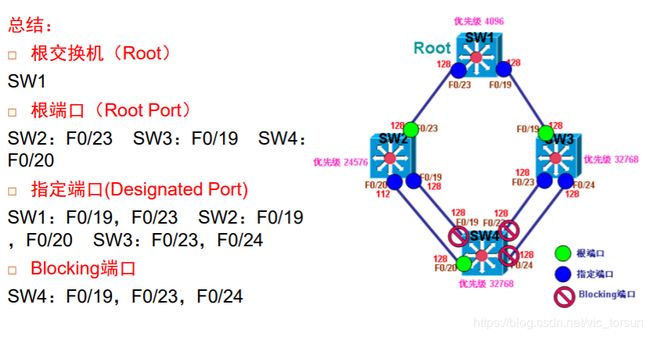
3.8. TCN
4. TCP/IP
4.1. 因特网的三地址
网络地址:同一体系结构中的可访问的计算机ID: IP地址
物理地址:物理媒体可访问的计算机某端口的唯一ID: MAC地址4.2. 错误报告协议(ICMP)
差错和控制报文协议:
报告IP传输中发生的(差错报文+控制报文+测试报文)
ICMP报文=头部+数据部分
IP头中的包类型=1;
ICMP并不是IP的上一层协议,仅用IP的转发功能
ping:
通过发送回送请求报文(echo request)和回送回答报文(echoreply)来检测源主机到目的主机的链路是否有问题,同时可以检测目的地是否可达,以及通信的延迟情况
traceroute:通过发送探测报文来获取路由信息。
第一个探测报文TTL为1,到达第一个路由器时,TTL减1为0所以丢掉这个探测包,同时向源主机发回ICMP时间超过报文,这时源主机就获得了第一个路由器的IP地址;
接着源主机发送第二个探测报文,TTL增1为2,到达第一个路由器TTL减1为1并转发探测包到第二个路由器,这时TTL减1为0,丢掉这个探测包并向源主机发回ICMP时间超过报文,源主机就获得了第二个路由器的IP地址;
以此类推,直到探测报文到达traceroute的目的地,这时源主机就获得了到目的地的每一跳路由的IP地址。4.3. 路由算法(RIP,OSPF)
ICANN分配唯一编号。全球所有AS组成因特网。
RIP(Routing Information Protocol)适应小规模网络:定时只向邻居说(如30s),说知道的所有(自路由表);
OSPF(Open Shortest Path First Protocol)适应较大规模网络:(链路)变化时向所有人说(区内路由器组播),只说邻居的事(链路状态)
原因:因特网规模大,AS间直接OSPF收敛时间很长;AS间最佳路由不现实(cost意义不统一);各AS管理策略不同。
BGP4:只寻求一条能到达目网的较好路由(不循环),并不最佳;
BGP采用路径向量(Path Vector)路由选择协议;
变动触发BGP发言人(对接路由器)间交换彼此的路由信息4.3.1. 距离向量算法(RIP)

4.3.2. 链路状态算法
OSPF一个Domain中的路由器会交换链路状态,LSP采用洪泛的方法传给所有Domain中的路由器4.3.3. OSPF
4.4. TCP
4.4.1. 三次握手建立连接
防止前面的连接实例的数据段干扰。4.4.2. 四次握手结束连接
另一方:ESTABLISHED → CLOSE_WAIT → LAST_ACK→CLOSED.4.5. 组播:IGMP,PIM-SM,PIM-DM:IGMP的作用
4.5.1. IGMP
通过上述IGMP机制,在组播路由器里建立起一张表,其中包含路由器的各个接口以及在接口所对应的子网上都有哪些组的成员。当路由器接收到某个组的数据报文后,只向那些有该组成员的接口上转发数据报文。
至于数据报文在路由器之间如何转发则由组播路由协议决定,IGMP协议并不负责。4.5.2. PIM协议
要让路由器生成一张功能完全的组播路由表,就需要在路由器之间运行一种协议,这种协议可以让组播源和目的之间的路由表生成单播表一样地生成组播表,最后路由器根据这张组播路由表来完成组播的转发。
这个协议就是PIM(Protocol Independent Multicast)。
PIM要为路由器学习组播路由表从而建立组播树,有两种不同的方式,这两种不同方式在PIM中分两种模式来运行,为PIM-DM(密集模式)和PIM-SM(稀疏模式)4.5.3. PIM-DM模式
4.5.4. PIM基本概念:PIM-SM(稀疏模式)
但是与PIM-DM模式不同的是,PIM-SM模式只记录连接着接收者的接口,其它没有接收者,不需要接收组播的接口是不会被记录的。
比如路由器上有5个接口有PIM邻居,其中只有一个是forwarding出口,再去掉1个RPF接口,还剩3个PIM接口是不需要接收组播的,在 PIM-DM模式中,会记录下一个RPF口和一个forwarding状态的出口,以及三个不需要接收组播的pruning状态的接口5. IPV6
5.1. IPv4和IPv6差异?
32bits→128 bits
全局unicast地址等价于IPv4公开地址
直接使用CIDR,网络前缀取代掩码,前缀表示子网号
基本报头固定40bytes
简化路由器的操作
引入结构化扩展报头,取消可选项长度限制
建立一系列自动发现和自动配置功能
最大单元发现(MTU discovery)
邻接节点发现(neighbor discovery )
路由器通告(router advertisement )
路由器请求(router solicitation)
节点自动配置(auto-configuration)
IP security ,提供IP层的安全IPSec
实现认证头(Authentication Header)
安全载荷封装(Encapsulated Security Payload)
流标号(flow label),20比特,发送者可以要求路由器对此流进行特殊处理,路由器可以鉴别特殊流的所有报文
多播寻址
在multicast地址中增加了 范围“scope”字段,允许将多播路由限定在正确的范围内
设置flog允许区分永久性多播地址和临时性多播地址
可移动性
信宿选项报头、路由选项报头、自动配置、安全机制、以及anycast技术,将QoS同移动节点结合,从而强化对移动的支持5.2. IPv6的地址结构
点分十进制
104.230.140.100.255.255.255.255.0.0.17.128.150.10.255.255
冒分16进制,共8个,相同字间距。上面地址为
68E6:8C64:FFFF:FFFF:0:1180:96A:FFFF
0压缩::表示,对连续长串0用::代替,一个地址中仅出现一次,如:
2080:0:0:0:8:800:200C:417A→2080::8: … ;unicast address
FF01:0:0:0:0:0:0:101→ FF01::101 ; multicast address
0:0:0:0:0:0:0:1 → ::1 ; loopback address
0:0:0:0:0:0:0:0 →:: ; undefined address
混合表示,x: x: x: x: x: x: d.d.d.d, x :表示16进制(16 Bits), d.表示10进制(8 Bits )
0:0:0:0:0:0:13.1.168.3 或 ::13.1.168.3
0:0:0:0:0:FFFF:129.144.52.38或 :: FFFF:129.144.52.38
IPv6地址/前缀长度,长度是10进制,表明地址最左端连续比特个数
正确表示12AB00000000CD3的60bits前缀是:
12AB:0000:0000:CD30:0000:0000:0000:0000/60
12AB::CD30:0:0:0:0/60
12AB:0:0:CD30::/60
不正确的表示为(没有准确体现前缀=60个bit后面为0):
12AB:0:0:CD3/60 ;可理解为0CD3
12AB::CD30/60 ;可理解为12AB:0:0:0:0:0:0:CD30
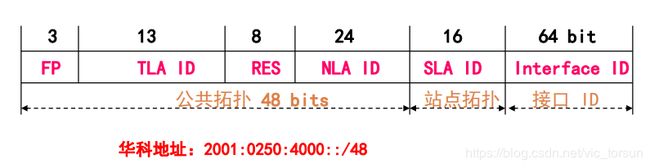
HUST的IPV6地址=2^81 = 2^80 ×2
2001:0250:4000::/48
2001:0DA8:3000::/485.3. 可聚类全局Unicast地址
001:全球可聚合Unicast地址
TLA ID(Top Level Aggregator):顶级聚合标识符,分配给大型ISP,从IANA直接获得。
RES:留做将来使用-Reserved for future use
NLA ID(Next Level Aggregator):次级聚合标识符,中型ISP从TLA获取。
SLA ID(Site Level Aggregator):站点级聚合标识符,小型ISP从NLA获得
接口ID:接口标识符Interface Identifier