在上一篇文章《从架构特点到功能缺陷,重新认识分析型分布式数据库》中,我们完成了对不同“分布式数据库”的横向分析,本文Ivan将讲述拆解的第二部分,会结合NoSQL与NewSQL的差异,从纵向来谈谈OLTP场景“分布式数 据库”实现方案的关键技术要点。本文既是前文的延伸,同时也算是分布式数据库专题文章的一个总纲,其中的要点Ivan之后也会单独撰文阐述。
特别说明:本文是原创文章,首发在DBAplus社群,转载须获得作者同意。
一、NewSQL & NoSQL
NewSQL是本专题关注的重点,也是前文中特指的“分布式数据库”,其适用于OLTP场景,具有高并发低延迟的特点,特性接近Oracle/DB2等传统数据库,依赖通用X86服务器实现性能上的水平拓展,能够扛住海量交易的性能压力。
目前具有较高知名度的NewSQL有Google的Spanner / F1、阿里的OceanBase、CockroachDB、TiDB。其中后两者是正在成长中的开源项目,2018年相继发布了2.0版本。
NewSQL与NoSQL有很深的渊源,所以下文在对NewSQL的介绍中会穿插一些NoSQL对应的实现技术方式。
1.存储引擎
B+ Tree
B+树是关系型数据库常用的索引存储模型,能够支持高效的范围扫描,叶节点相关链接并且按主键有序,扫描时避免了耗时的遍历树操作。B+树的局限在于不适合大量随机写场景,会出现“写放大”和“存储碎片”。
以下借用姜承尧老师书中的例子[1]来说明B+树的操作过程↓
存在高度为2的B+树,存储在5个页表中,每页可存放4条记录,扇出为5。下图展示了该B+ Tree的构造,其中略去了叶子节点指向数据的指针以及叶子节点之间的顺序指针:
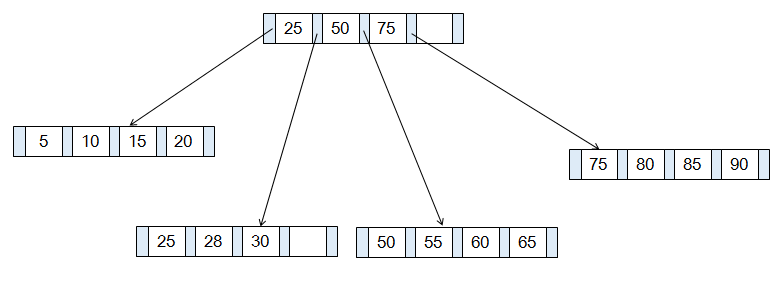
B+树由内节点(InterNode)和叶节点(LeafNode)两类节点构成,后者携带指向数据的指针,而前者仅包含索引信息。
当插入一个索引值为70的记录,由于对应页表的记录已满,需要对B+树重新排列,变更其父节点所在页表的记录,并调整相邻页表的记录。完成重新分布后的效果如下:
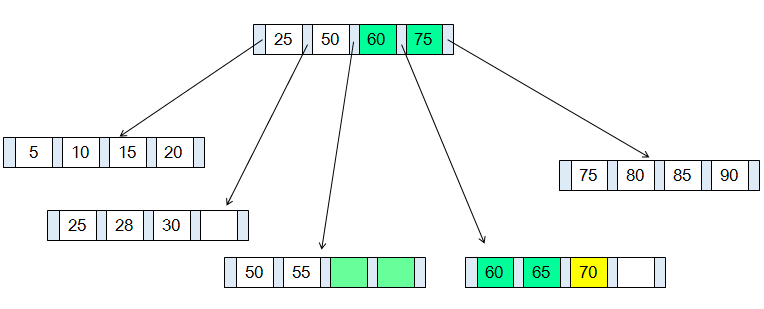
变更过程中存在两个问题:
写放大
本例中,逻辑上仅需要一条写入记录(黄色标注),实际变动了3个页表中的7条索引记录,额外的6条记录(绿色标注)是为了维护B+树结构产生的写放大。
注: 写放大(Write Amplification):Write amplification is the amount of data written to storage compared to the amount of data that the application wrote,也就是说实际写入磁盘的数据大小和应用程序要求写入数据大小之比
存储不连续
新 增叶节点会加入到原有叶节点构成的有序链表中,整体在逻辑上是连续的;但磁盘存储上,新增页表申请的存储空间与原有页表很可能是不相邻的。这样,在后续包 含新增叶节点的查询中,将会出现多段连续读取,磁盘寻址的时间将会增加。进一步来说,在B+Tree上进行大量随机写会造成存储的碎片化。
在 实际应用B+Tree的数据库产品(如MySQL)中,通常提供了填充因子(Factor Fill)进行针对性的优化。填充因子设置过小会造成页表数量膨胀,增大对磁盘的扫描范围,降低查询性能;设置过大则会在数据插入时出现写扩大,产生大量 的分页,降低插入性能,同时由于数据存储不连续,也降低了查询性能。
LSM-Tree
LSM-Tree(Log Structured-Merge Tree)由Patrick O'Neil首先提出,其在论文[2]中系统阐述了与B+树的差异。而后Google在Bigtable中引入了该模型,如下图所示:

LSM-Tree的主要思想是借助内存将随机写转换为顺序写,提升了写入性能;同时由于大幅度降低了写操作对磁盘的占用,使读操作获得更多的磁盘控制权,读操作性能也并未受到过多的影响。
写操作简化过程如下:
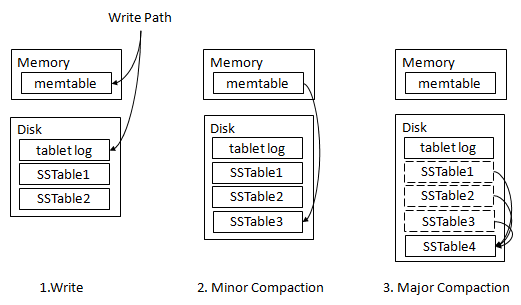
- 当写入请求到达时,首先写入内存中Memtable,处理增量数据变化,同时记录WAL预写日志;
- 内 存增量数据达到一定阈值后,当前Memtable会被冻结,并创建一个新的Memtable,已冻结的Memtable中的数据会被顺序写入磁盘,形成有 序文件SSTable(Sorted String Table),这个操作被称为Minor Compaction(在HBase中该操作称为Flush操作,而Minor Compaction有其他含义);
- 这些SSTable满足一定的规则后进行合并,即Major Compaction。每个Column Family下的所有SSTable被合并为一个大的SSTable。
该模型规避了随机写的IO效率问题,有效缓解了B树索引的写放大问题,极大的提升了写入效率。
NoSQL广泛使用了LSM-Tree模型,包括HBase、Cassandra、LevelDB、RocksDB等K/V存储。
当然LSM-Tree也存在自身的缺陷:
- 首先,其Major Compaction的操作非常重影响联机读写,同时也会产生写放大。因为这个原因,HBase的使用中通常会禁止系统自动执行Major Compaction。
注释:
Major Compaction操作的意义是降低读操作的时间复杂度。设系统包含多个SSTable文件,共有N数据,SSTable平均包含m数据。
执行读操作时,对单一SSTable文件采用折半查找方法的时间复杂度为O(log2m),则整体时间复杂度为O(N/m* log2m);合并为一个SSTable后,时间复杂度可降低到O(log2N)
其次是对读效率的影响,因为SSTable文件均处于同一层次,根据批量写的执行时序形成若干文件,所以不同文件中的Key(记录主键)会出现交叉重叠,这样在执行读操作时每个文件都要查找,产生非必要的I/O开销。
最后是空间上的放大(Space Amplification),最坏情况下LSM Tree需要与数据大小等同的自由空间以完成Compact动作,即空间放大了100%,而B+树的空间放大约为1/3。
Leveled LSM Tree
Leveled LSM Tree 的变化在于将SSTable做了进一步的分层,降低写放大的情况,缩小了读取的文件范围,在LevelDB 中率先使用,随后Cassandra 1.0也引入了该策略[3]。
SSTable的层次化设计策略是:
- 单个SSTable文件大小是固定的,在Cassandra中默认设置为5M;
- 层 级从Level 0开始递增,存储数据量随着层级的提升而增长,层级之间有一致的增长系数(Growth Factor)。Cassandra中Growth Factor设置为10,Level 1文件为1-10M则Level 2 文件为10-100M,这样10TB数据量会达到Level 7;
- Level 0的SSTable比较特殊,固定为4个文件,且文件之间存在Key交叉重叠的情况,从Level 1开始,SSTable不再出现Key交叉情况;
- Level 0层的SSTable超过容量大小时,向Level 1 Compaction,因为存在Key交叉,所以要读取Level 0的所有SSTable;当Level 1 的文件大小超过阈值时,将创建Level 2的SSTable并删除掉Level 1原有的SSTable;当Level 1的Key范围对应Level 2的多个SSTable时,要重写多个SSTable,但由于SSTable的大小固定,所以通常只会涉及少数的SSTable。

多个有序的SSTable,避免了Major Compaction这样的重量级文件重写,每次仅更新部分内容,降低了写放大率。
对于读取元数据来锁定相关的SSTable,效率显然超过了对所有SSTable的折半查找和Bloom Filter。因此,读取效率得到了显著提升,按照某种评估方式[3],在每行数据大小基本相同的情况下,90%的读操作仅会访问一个SSTable。
该策略下,Compaction的操作更加频繁,带来了更多I/O开销,对写密集型操作而言,最终结果是否能够得到足够的效率提升存在不确定性,需要在应用中权衡。
NewSQL的策略
NewSQL 数据库的存储层普遍都采用K/V存储,所以基本沿用了LSM Tree模型。其中CockroachDB和TiDB都在KV层使用RocksDB。OceanBase采用了不同的方法规避Major Compaction的影响,大体是利用闲置的副本(Follower)进行Compaction操作,避免了对读操作的阻塞,在Compaction完 成后,进行副本的角色的替换。
同时,K/V存储引擎仍然在继续发展中,一些其他的改进如分形树(Fractal Tree)等,限于篇幅我们就不在此展开了。
2.分片
分片(Sharding)概念与RDBMS的分区相近,是分布式数据库或分布式存储系统的最关键特性,是实现水平扩展的基础,也在NoSQL类系统中得到了大量运用。
分片的目标是将数据尽量均匀地分布在多个节点上,利用多节点的数据存储及处理能力提升数据库整体性能。
Range&Hash
虽然不同的系统中对分片策略有很多细分,但大致可以归纳为两种方式,Range和Hash。
Range分片有利于范围查询,而Hash分片更容易做到数据均衡分布。在实际应用中,Range分片似乎使用得更多,但也有很多应用会混合了两种分片方式。
HBase采用了Range方式,根据Rowkey的字典序排列,当超过单个Region的上限后分裂为两个新的Region。Range的优点是数据位置接近,在访问数据时,范围查找的成本低;缺点也比较明显,在容易出现热点集中的问题。
例 如,在HBase通常不建议使用业务流水号作为RowKey,因为连续递增的顺序号在多数时间内都会被分配到同一个RegionServer,造成并发访 问同时竞争这个RegionServer资源的情况。为了避免该问题,会建议将RowKey进行编码,序号反转或加盐等方式。这种方式实质上是使用应用层 的设计策略,将Range分片转换成类似Hash分片的方式。
Spanner的底层存储沿用了BigTable的很多设计思路,但在分片上有所调整,在Tablet内增加了Directory的动态调配来规避Range分片与操作热点不匹配的问题,后续在事务管理部分再详细描述。
静态分片&动态分片
按照分片的产生策略可以分为静态分片和动态分片两类。
静态分片在系统建设之初已经决定分片的数量,后期再改动代价很大;动态分片是指根据数据的情况指定的分片策略,其变更成本较低,可以按需调整。
传 统的DB + Proxy方案,进行水平分库分表就是一种常见的静态分片。我们熟知的几个互联网大厂在大规模交易系统中都进行过类似的设计,默认将数据做成某个固定数量 的分片,比如100、255、1024,或者其它你喜欢的数字。分片的数量可以根据系统预期目标的整体服务能力、数据量和单节点容量进行评估,当然具体到 100片合适还是1024片合适,多少还是有拍脑袋的成分。
在NoSQL中,Redis集群也采用同样的静态分片方式,默认为16384个哈希槽位(等同于分片)。
静 态分片的缺点是分片数量已经被确定,基于单点处理能力形成一个容量的上限;灵活性较差,后续再做分片数量调整时,数据迁移困难,实现复杂。优点也很明显, 静态分片的策略几乎是固化的,因此对分区键、分区策略等元数据管理的依赖度很低,而这些元数据往往会形成分布式数据库中的单点,成为提升可靠性、可用性的 障碍。
相比之下,动态分片的灵活性更好,适用于更丰富的应用场景,所以NewSQL也主要采用动态分片方式,代价则是对元数据管理的复杂度增加。
在分片处理上,NoSQL与NewSQL面临的问题非常接近。
3.副本
首先是由于通用设备单机可靠性低,必须要通过多机副本的方式。本文中关注两个问题:一是副本一致性;二是副本可靠性与副本可用性的差异。
数据副本一致性
多 副本必然引入了副本的数据一致性问题。之前已经有大名鼎鼎的CAP理论,相信大家都是耳熟能详了,但这里要再啰嗦一句,CAP里的一致性和事务管理中的一 致性不是一回事。Ivan遇到过很多同学有误解,用CAP为依据来证明分布式架构不可能做到事务的强一致性,而只能是最终一致性。
事务的一致性是指不同数据实体在同一事务中一起变更,要么全部成功,要么全部失败;而CAP中的一致性是指原子粒度的数据副本如何保证一致性,多副本在逻辑上是同一数据实体。
副本同步大致归纳为以下三种模式:
强同步:即 在多个副本都必须完成更新,数据更新才能成功。这种模式的问题是高延时、低可用性,一次操作要等待所有副本的更新,加入了很多网络通讯开销,增加了延时。 多个副本节点必须都正常运行的情况下,整个系统才是可用的,任何单点的不可用都会造成整个系统的不可用。假设单点的可用性是95%,则三个节点的构成的多 副本,其可靠性为95% * 95% * 95% = 85.7%。因此虽然Oracle/MySQL等主流数据库都提供了强同步方式,但在企业实际生产环境中很少有应用。
半同步:MySQL提供了半同步方式,多个从节点从主节点同步数据,当任意从节点同步成功,则主节点视为成功。这个逻辑模型有效规避了强同步的问题,多节点可用性的影响从“与”变为“或”,保障了整体的可用性。但遗憾的是在技术实现上存在瑕疵,会有退化为异步的问题。
Paxos/Raft:该 方式将参与节点划分为Leader/Follower等角色,主节点向多个备节点写入数据,当存在一半以上节点写入成功,即返回客户端写入成功。该方式可 以规避网络抖动和备节点服务异常对整体集群造成的影响。其他像Zookeeper的ZAB协议,Kafka的ISR机制,虽然与Paxos/Raft有所 区别,但大致是一个方向。
副本可靠性与副本可用性
数据副本仅保证了数据的持久性,即数据不丢失。我们还面临着副本的可用性问题,即数据是否持续提供服务。以HBASE-10070为例来说明这个问题:
HBase通过分布式文件系统HDFS实现了数据多副本的存储,但是在提供服务时,客户端是连接到RegionServer进而访问HDFS上的数据。因为一个Region会被唯一的RegionServer管理,所以RegionServer仍然是个单点。
在 RegionServer宕机时,需要在一定的间隔后才被HMaster感知,后者再调度起一个新的RegionServer并加载相应的Region, 整个过程可能达到几十秒。在大规模集群中,单点故障是频繁出现的,每个单点带来几十秒的局部服务中断,大大降低了HBase的可用性。
为了解决这问题,HBase引入从RegionServer节点的概念,在主节点宕机时,从节点持续提供服务。而RegionServer并不是无状态服务,在内存中存储数据,又出现了主从RegionServer间的数据同步问题。
HBase实现了数据的可靠性,但仍不能充分实现数据的可用性。CockroachDB和TiDB的思路是实现一个支持Raft的分布式KV存储,这样完全忽略单节点上内存数据和磁盘数据的差异,确保数据的可用性。
4.事务管理
分布式事务处理由于其复杂性,是NoSQL发展中最先被舍弃的特性。但由于大规模互联网应用广泛出现,其现实意义逐渐突出,又重新成为NewSQL无法规避的问题。随着NewSQL对事务处理的完善,也让过去十余年数据库技术的演进终于实现了一个接近完整的上升螺旋。
鉴于分布式事务管理的复杂性,Ivan在本文中仅作简要说明,后续文章中会进一步展开。
NewSQL 事务管理从控制手段上分为锁(Lock-Base)和无锁(Lock-Free)两种,其中,无锁模式通常是基于时间戳协调事务的冲突。从资源占用方式 上,分为乐观协议和悲观协议,两者区别在于对资源冲突的预期不同:悲观协议认为冲突是频繁的,所以会尽早抢占资源,保证事务的顺利完成;乐观协议认为冲突 是偶发的,只在可以容忍的最晚时间才会抢占资源。

以下通过最经典的“两阶段提交协议”和具体的两种应用实践,来具体阐述实现方式:
两阶段提交协议(2PC)
两阶段提交协议(Tow phase commit protocol,2PC)是经典的分布式事务处理模型,处理过程分为两个阶段:
请求阶段:
- 事务询问。协调者向所有参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的相应;
- 执行事务。各参与者节点执行事务操作,并将Undo和Redo信息记入事务日志中;
- 各参与者向协调者反馈事务询问的响应。如果参与者成功执行了事务操作,那么就反馈给协调者Yes,表示事务可以执行;如果参与者没有成功执行事务,那么就反馈给No,表示事务不可以执行。
提交阶段:
- 提交事务。发送提交请求。协调者向所有参与者节点发出Commit请求;
- 事务提交。参与者接到Commit后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占有的事务资源;
- 反馈事务提交结果。参与者在完成事务提交后,向协调者发送Ack消息;
- 完成事务。协调者收到所有参与者反馈的Ack消息后,完成事务;
- 中断事务。发送回滚请求。协调者向所有参与者发出Rollback请求;
- 事务回滚。参与者接收到Rollback请求后,会利用其阶段一记录的Undo信息来执行事务回滚操作,并在完成回滚之后释放在整个事务执行期间占有的事务资源;
- 反馈事务回滚结果。参与者在完成事务回滚后,向协调者发送Ack消息;
- 中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
该模型的主要优点是原理简单,实现方便。
缺点也很明显,首先是同步阻塞,整个事务过程中所有参与者都被锁定,必然大幅度影响并发性能;其次是单点问题,协调者是一个单点,如果在第二阶段宕机,参与者将一直锁定。
Spanner
根据Spanner论文[4]的介绍,其分布式事务管理仍采用了2PC的方式,但创新性的设计是改变了Tablet的数据分布策略,Tablet不再是单一的连续Key数据结构,新增了Directory作为最小可调度的数据组织单元。

通过动态的调配,降低事务内数据跨节点分布的概率。

Ivan将这种事务处理的设计思想理解为:“最好的分布式事务处理方式,就是不做分布式事务处理,将其变为本地事务”。在OceanBase的早期版本中也采用了一个独立的服务器UpdateServer来集中处理事务操作,理念有相近之处。
Percolator
Percolator[5] 是Google开发的增量处理网页索引系统,在其诞生前,Google采用MapReduce进行全量的网页索引处理。这样一次处理的时间取决于存量网页 的数量,耗时很长;而且即使某天只有少量的网页变更,同样要执行全量的索引处理,浪费了大量的资源与时间。采用Percolator的增量处理方式后,大 幅度减少了处理时间。
在这篇论文中给出了一个分布式事务模型,是“两阶段提交协议”的变形,其将第二阶段的工作简化到极致,大幅提升了处理效率。
具体实现上,Percolator是基于BigTable实现分布式事务管理,通过MVCC和锁的两种机制结合,事务内所有要操作的记录均为新增版本而不更新现有版本。这样做的好处是在整个事务中不会阻塞读操作。
- 事务中的锁分为主(Primary)和从锁(Secondary),对事务内首先操作的记录对加主锁,而后对事务内的其他记录随着操作过程逐步加从锁并指向主锁记录,一旦遇到锁冲突,优先级低的事务释放锁,事务回滚;
- 事务内的记录全部更新完毕后,事务进入第二阶段,此时只需要更新主锁的状态,事务即可结束;
- 从锁的状态则依赖异步进程和相关的读操作来协助完成,由于从锁记录上保留了指向主锁记录的指针,异步进程和读操作都很容易判断从锁的正确状态,并进行更新。
分布式事务管理的其他内容,包括无锁事务控制、全局时钟的必要性等等,待后续文章中再讨论。
二、结语
本文最初的立意是面向几类典型技术背景的同学,对“分布式数据库”展开不同方向的解读,并就其中部分技术要点进行阐述,使不同技术领域的同学能够对相关技术有些许了解,为有兴趣深入研究的同学做一个铺垫。
随着分析的深入愈发觉得文章框架过于庞大难于驾驭,因而对关键技术的解读也存在深浅不一的情况。对于本文中未及展开的部分,Ivan会尽力在后续系列文章中予以补充,水平所限文中必有错漏之处,欢迎大家讨论和指正。
文献参考:
[1] 姜承尧, MySQL技术内幕:InnoDB存储引擎机, 械工业出版社, 2011
[2] Patrick O'Neil The Log-Structured Merge-Tree
[3] Leveled Compaction in Apache Cassandra
https://www.datastax.com/dev/blog/leveled-compaction-in-apache-cassandra
[4] James C. Corbett, Jeffrey Dean, Michael Epstein, et al. Spanner: Google's Globally-Distributed Database
[5] Daniel Peng and Frank Dabek, Large-scale Incremental Processing Using Distributed Transactions and Notifications