风格迁移1-05:Liquid Warping GAN(Impersonator)-白话给你讲论文-翻译无死角(2)
以下链接是个人关于Liquid Warping GAN(Impersonator)-姿态迁移,所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
风格迁移1-00:Liquid Warping GAN(Impersonator)-目录-史上最新无死角讲解
3.4. Training Details and Loss Functions
在这个部分,主要是介绍 loss 的定义,以及整个训练系统。对于人体mesh重构,我们使用的是HMR的loss,并且使用了他的预训练模型。
对于Liquid Warping GAN,在训练阶段,我们从任意视频从随机抽取一对图片,一帧当做 source I s I_s Is,一帧当做 reference I r I_r Ir, 注意我们提出方法,是集中于动作模仿,外貌转化,以及新视角合成为一个框架。因此他们三个模型的任意一个模型训练完成,都可适用于另外两个任务。如,在我们的实验中,我们训练的是动作模仿的模型,但是同样适用于另外两个任务。
整体的 l o s s loss loss由四部分组成,分别是perceptual loss, face identity loss,attention regularization loss,adversarial loss。
Perceptual Loss. 是对重构的source image I ^ s \hat I_s I^s 以及 I ^ s \hat I_s I^s 进行调整,让他们接近对应的ground truth I s I_s Is于 I r I_r Ir(在VGG提取出来的特征空间),可以使用如下表达式表示:
L p = ∣ ∣ f ( I ^ s ) − f ( I S ) ∣ ∣ 1 + ∣ f ( I ^ t ) − f ( I r ) ∣ ∣ 1 L_p=||f(\hat I_s)-f(I_S)||_1 + |f(\hat I_t)-f(I_r)||_1 Lp=∣∣f(I^s)−f(IS)∣∣1+∣f(I^t)−f(Ir)∣∣1这里的f表示的是VGG-19。
Face Identity Loss. 其主要是保证合成的图像 I ^ t \hat I_t I^t与ground truth I r I_r Ir身份ID的相似,这样能够保留面部的细节, l o s s loss loss定义如下:
L f = ∣ ∣ g ( I ^ t ) − g ( I r ) ∣ ∣ 1 L_f = ||g(\hat I_t)-g(I_r)||_1 Lf=∣∣g(I^t)−g(Ir)∣∣1
这里的g表示使用预训练模型的SphereFaceNet
Adversarial Loss. 的作用主要是让生成数据的分布接近真实数据的分布,我们是的LSGAN l o s s loss loss,对于生成目标类似于PatchGAN,这个鉴别器去对 I ^ t \hat I_t I^t进行调整,让他看起来逼真,我们使用的是条件鉴别器,输入是生成的图像以及对应的 G t G_t Gt(6通道),如下:
L a d v G = ∑ D ( I ^ t , C t ) 2 L_{adv}^G = \sum D(\hat I_t,C_t)^2 LadvG=∑D(I^t,Ct)2
Attention Regularization Loss. 的作用是让attention map A变得平滑,不容易饱和。如果attention map A是没有对应的ground truth,这让他直接从训练的过程中学习到,但是这种情况,其训练的结果是很容易饱和为1的,为为了缓解这种情况,我们调整了mask,使其更接近3D身体网格渲染的轮廓,因为轮廓是一个粗略的地图,它包含了没有衣服和头发的身体的map,并且我们还对他执行了正则化。为了补偿这个轮廓的不足之处,当预测的背景 I ^ b g \hat I_{bg} I^bg和color map P P P组合时,进一步强化平滑了颜色空间,定义如下:
L a = ∣ ∣ A s − S s ∣ ∣ 2 2 + ∣ ∣ A t − S t ∣ ∣ 2 2 + T V ( a s ) + T V ( A t ) L_a = ||A_s-S_s||^2_2 + ||A_t-S_t||_2^2 +TV(a_s) + TV(A_t) La=∣∣As−Ss∣∣22+∣∣At−St∣∣22+TV(as)+TV(At) T V ( A ) = ∑ i , j [ A ( i , j ) − A ( i − 1 , j ) ] 2 + [ A ( i , j ) − A ( i , j − 1 ) ] 2 TV(A) = \sum_{i,j}[A(i,j) - A(i-1,j)]^2 + [A(i,j) - A(i,j-1)]^2 TV(A)=i,j∑[A(i,j)−A(i−1,j)]2+[A(i,j)−A(i,j−1)]2
对于生成器,完整的损失函数定义如下
L G = λ p L p + λ f L f + λ a L a + L a d v G L^G = \lambda_pL_p + \lambda_fL_f + \lambda_aL_a + L_{adv}^G LG=λpLp+λfLf+λaLa+LadvG
对于鉴别器的定义如下:
L D = ∑ [ D ( I ^ t , G t ) + 1 ] 2 + ∑ [ D ( I r , G t ) − 1 ] 2 L^D = \sum [D(\hat I_t,G_t) + 1]^2 + \sum [D(I_r,G_t) - 1]^2 LD=∑[D(I^t,Gt)+1]2+∑[D(Ir,Gt)−1]2
3.5. Inference
训练一个动作模仿的模型,该模型可以应用其他的任务,他们的不同点在于变换矩阵T的操作不同,其余的操作,如Body Mesh Recovery and Liquid Warping GAN 模型都是一样的,下面我们详细介绍每个任务在测试阶段的操作。
Motion Imitation. 我们首先复制 reference θ r θ_r θr 姿态参数的值到 source,得到 SMPL 的综合参数,以及 3D mesh M t = M ( θ r , β s ) Mt=M(\theta_r,\beta_s) Mt=M(θr,βs)。下一步,在 K s K_s Ks的视角下,渲染source mesh M s M_s Ms 以及 合成的 mesh M t M_t Mt , 渲染之后分别得到 C s C_s Cs 以及 C t C_t Ct。然后利用project结合弱视角摄像机参数将2D image 投影到二维图像空间中, v s = P r o j ( V s , K s ) v_s = Proj(V_s,K_s) vs=Proj(Vs,Ks),下一步我们计算每个mesh 表面的重心坐标,得到 f s ∈ R N f × 2 f_s \in \mathbb{R}^{N_f\times2} fs∈RNf×2,最后根据source对应的 map,以及其网格面坐标 f s f_s fs之间的对应关系,与合成对应的 map进行匹配,计算出变换矩阵 T ∈ R H × W × 2 T \in \mathbb{R}^{H \times W \times2} T∈RH×W×2,其为 Fig. 5 (a),Fig. 5如下所示:

图示翻译:在测试阶段,根据任务的不同,其计算转换流的方式也不同,这个最左边的部分,是Body Recovery 模型,右边是不同任务转换流的实现。
Novel View Synthesis. 给出一个新的摄像头视角,即旋转参数 R R R 与平移参数 t t t, 我们首先计算新视角下的3D mesh, M t = M s R + t M_t = M_sR + t Mt=MsR+t, 接下来的操作类似于动作模仿,在K_s的参数下对 M s , M t Ms,M_t Ms,Mt 进行渲染,得到 G s , G t G_s,G_t Gs,Gt,并且计算他们之间的转换矩阵 T ∈ R H × W × 2 T \in \mathbb{R}^{H \times W \times2} T∈RH×W×2,整个过程如上图的 b 所示。
Appearance Transfer. 这个操作,是要保持source 的头部不变,从reference image 拷贝衣服过来。我们把转换矩阵 T T T 分割成了两个子矩阵source T 1 T_1 T1, 与 reference T 2 T_2 T2, 注意,头部的Mesh M h = ( V h , F h ) M^h = (V^h,F^h) Mh=(Vh,Fh)以及身体Mesh M b = ( V b , F b ) M^b = (V^b,F^b) Mb=(Vb,Fb),同时 M = M h ∪ M b M=M^h \cup M^b M=Mh∪Mb。对于 T 1 T_1 T1 ,我们首先构建头部 source 的mesh M s h M_s^h Msh进入图像空间,获得其轮廓 S s h S_s^h Ssh,然后创建 mesh 格子 G ∈ R H × W × 2 G \in \mathbb{R}^{H \times W \times2} G∈RH×W×2 ,然后通过 S s h S_s^h Ssh 对 G G G 进行 mask 操作,即 T 1 = G ∗ S h T1 = G * S^h T1=G∗Sh,这里的 * 表示的是像素级别的相乘,对于 T 2 T_2 T2类似于动作模仿,渲染source body M s b M_s^b Msb以及 M t b M_t^b Mtb对应的map,得到 G s b G_s^b Gsb, G t b G_t^b Gtb。最后计算他们之间的转换流 T 2 T_2 T2,如上图的 © 所示。
4. Experiments
Dataset. 为了对我们提出的方法进行评估,我们创建了一个叫iPER的数据集,其中一共包含了30个身高胖瘦不同的人,并且每个人执行一个固定的动作,以及几个随机动作,其中有的人,录制多个视频,并且每个视频穿的衣服都不一样。总计103种服装,206个视频,共241564帧图像,我们按照8:1的比例,把他们分成了训练集和测试集。
Implementation Details. 对于该网络的训练,我们把所有图像正则化到[-1,1]之间,并且改变大小为256x256。每次送入网络的,是从同一视频随机抽取两帧。在实验中mini-batch为 4, λ p , λ f , λ a , \lambda_p,\lambda_f,\lambda_a, λp,λf,λa,分别为10.0, 5.0,1.0。对于 生成器以及鉴别器,我们使用的优化方式都是Adam。
4.1. Evaluation of Human Motion Imitation.
Evaluation Metrics. 我们提出了一种iPER数据集测试集的评估协议,该协议能够从不同方面反映不同模型的性能,详细的细节如下:
1.对于每个视频,我们选择3张图像(正面,侧面,遮挡)带有不同程度的遮挡,正面图像包含了最多的信息,侧面图像丢失了一些信息,遮挡图像将引入模糊的信息。
2.对于每个source image,让他执行了自我模仿,使用SSIM 与 Learned Perceptual Similarity (LPIPS) 的方式进行评估。
3. 我们还进行了交叉模仿,我们使用一个预训练好的Score(IS) 与 Frechet Distance的模型(名字叫FReID),去评估生成图像的质量。
Comparison with Other Methods. 在实验中,和一些先进的模型进行了对比,其中包括了PG2 , SHUP,DSC ,所有的模型都是在 iPER 上进行训练,使用上面提到的评估方法,结果展示如下:
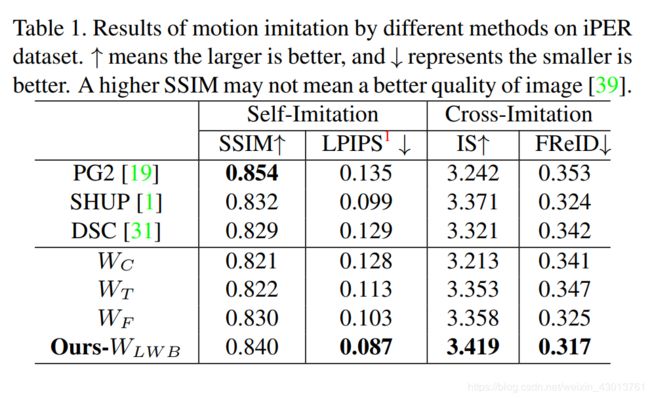
可以看到,我们的模型超过了其他的模型,另外我们还生成了一些图片进行对比,如下:

我们可以发现:
1.如果一个高的人,去模仿一个矮的人,其他的方法效果都不是很好,但是我们的模型表现很突出。
2.从上图的第一行可以看出,对于遮挡的一些情况,我们提出的模型鲁棒性也比较好,生成的遮挡或者不可见部分更加的逼真。
3.从第二行,可以看出我们的方法,能够保留更多的细节信息,如衣服上的标记。
4.从下图,Figure 7可以看出,我们的模型能生成质量较高的图像。

Ablation Study. 为了证明我们提出的Liquid Warping Block (LWB) 对整个网络起到了作用,使用前面提到的方法设计了三个基线来传原图像的信息,包含了最早出现的concatenation, texture warping 以及 feature warping,出了原图信息的传递不同之外,其他的结构完全相同,concatenation, texture warping, feature warping 以及我们的 LWB 分别表示为 W C , W T , W F , W L W B W_C,W_T,W_F,W_{LWB} WC,WT,WF,WLWB,同样都是在iPER 数据集上进行训练,然后分别评估动作模仿的性能,从前面给出的表格,可以看出我们的方法超过了其他的方法。
4.2. Results of Human Appearance Transfer.
这里再次强调一下,单一个模型被训练出来之后,是可以适用于另外两个任务的。我们随机生成了一些样本显示如下:
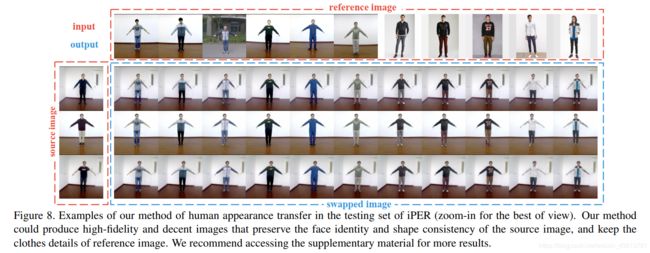
对于任务的面部ID,以及衣服等细节,我们的网络都保护得很好。并且我们的网络,使用网上找来的图片(不在iPER数据集),效果也很好,如上面的第六列之后。
4.3. Results of Human Novel View Synthesis.
我们随机从 iPER 的测试集挑取了一些样本,改变他的视角从30到60度,展示如下:

从上面可以看到,我们的网络,有能力去捕获一些看不见的信息,甚至在一些自遮挡的情况下,如上图的中间两行。
5. Conclusion
叽里呱啦一堆吹逼的,就不翻译了。
结语
到这里,终于翻译完成,如果大家看得懂,就给赞呗,下面为大家讲解整个网络模型。