图的基本算法(最小生成树)
假设以下情景,有一块木板,板上钉上了一些钉子,这些钉子可以由一些细绳连接起来。假设每个钉子可以通过一根或者多根细绳连接起来,那么一定存在这样的情况,即用最少的细绳把所有钉子连接起来。
更为实际的情景是这样的情况,在某地分布着N个村庄,现在需要在N个村庄之间修路,每个村庄之前的距离不同,问怎么修最短的路,将各个村庄连接起来。
以上这些问题都可以归纳为最小生成树问题,用正式的表述方法描述为:给定一个无方向的带权图G=(V, E),最小生成树为集合T, T是以最小代价连接V中所有顶点所用边E的最小集合。 集合T中的边能够形成一颗树,这是因为每个节点(除了根节点)都能向上找到它的一个父节点。
解决最小生成树问题已经有前人开道,Prime算法和Kruskal算法,分别从点和边下手解决了该问题。
Prim算法
Prim算法是一种产生最小生成树的算法。该算法于1930年由捷克数学家沃伊捷赫·亚尔尼克(英语:Vojtěch Jarník)发现;并在1957年由美国计算机科学家罗伯特·普里姆(英语:Robert C. Prim)独立发现;1959年,艾兹格·迪科斯彻再次发现了该算法。
Prim算法从任意一个顶点开始,每次选择一个与当前顶点集最近的一个顶点,并将两顶点之间的边加入到树中。Prim算法在找当前最近顶点时使用到了贪婪算法。
算法描述:
1. 在一个加权连通图中,顶点集合V,边集合为E
2. 任意选出一个点作为初始顶点,标记为visit,计算所有与之相连接的点的距离,选择距离最短的,标记visit.
3. 重复以下操作,直到所有点都被标记为visit:
在剩下的点钟,计算与已标记visit点距离最小的点,标记visit,证明加入了最小生成树。
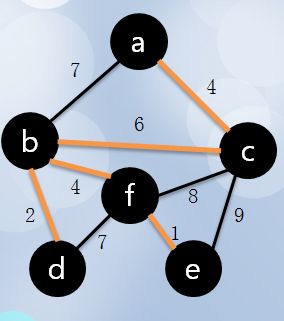
下面我们来看一个最小生成树生成的过程:
1 起初,从顶点a开始生成最小生成树

2 选择顶点a后,顶点啊置成visit(涂黑),计算周围与它连接的点的距离:
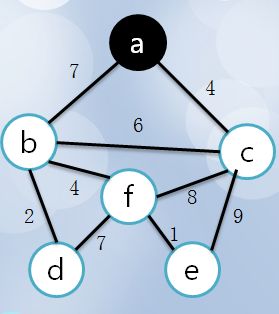
3 与之相连的点距离分别为7,6,4,选择C点距离最短,涂黑C,同时将这条边高亮加入最小生成树:
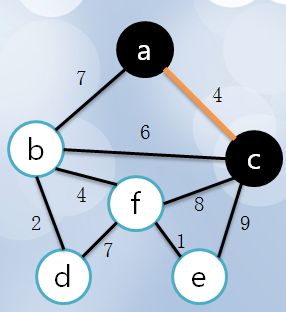
4 计算与a,c相连的点的距离(已经涂黑的点不计算),因为与a相连的已经计算过了,只需要计算与c相连的点,如果一个点与a,c都相连,那么它与a的距离之前已经计算过了,如果它与c的距离更近,则更新距离值,这里计算的是未涂黑的点距离涂黑的点的最近距离,很明显,b和a为7,b和c的距离为6,更新b和已访问的点集距离为6,而f,e和c的距离分别是8,9,所以还是涂黑b,高亮边bc:
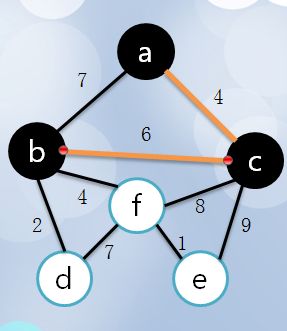
5 接下来很明显,d距离b最短,将d涂黑,bd高亮:

6 f距离d为7,距离b为4,更新它的最短距离值是4,所以涂黑f,高亮bf:
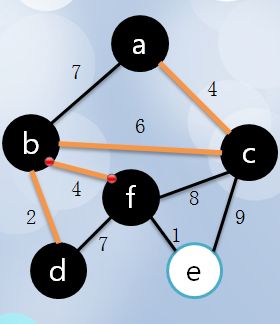
7 最后只有e了:
针对如上的图,代码实例如下:
#includeKruskal算法
Kruskal是另一个计算最小生成树的算法,其算法原理如下。首先,将每个顶点放入其自身的数据集合中。然后,按照权值的升序来选择边。当选择每条边时,判断定义边的顶点是否在不同的数据集中。如果是,将此边插入最小生成树的集合中,同时,将集合中包含每个顶点的联合体取出,如果不是,就移动到下一条边。重复这个过程直到所有的边都探查过。
下面还是用一组图示来表现算法的过程:
1 初始情况,一个联通图,定义针对边的数据结构,包括起点,终点,边长度:
typedef struct _node{
int val; //长度
int start; //边的起点
int end; //边的终点
}Node;
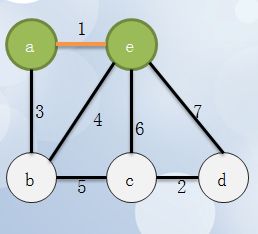
2 在算法中首先取出所有的边,将边按照长短排序,然后首先取出最短的边,将a,e放入同一个集合里,在实现中我们使用到了并查集的概念:
3 继续找到第二短的边,将c, d再放入同一个集合里:

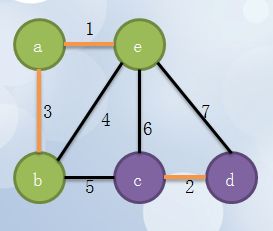
4 继续找,找到第三短的边ab,因为a,e已经在一个集合里,再将b加入:
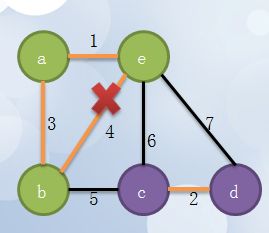
5 继续找,找到b,e,因为b,e已经同属于一个集合,连起来的话就形成环了,所以边be不加入最小生成树:
6 再找,找到bc,因为c,d是一个集合的,a,b,e是一个集合,所以再合并这两个集合:

这样所有的点都归到一个集合里,生成了最小生成树。
根据上图实现的代码如下:
#includereturn 0;
}