编写KNN算法预测泰坦尼克号存活率
1.读取文件:titanic3.csv
2.数据预处理
3.分析相关性,定义合适的特征变量
4.训练模型,得出存活率
首先引用库(没用的和有用的都在里面,需要你们自己去选择):
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score, precision_score,recall_score, f1_score, roc_curve
from pydotplus import graph_from_dot_data
import graphviz
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, KFold, GridSearchCV
from sklearn.preprocessing import Imputer, LabelEncoder, OneHotEncoder,LabelBinarizer
from sklearn.feature_selection import SelectKBest, SelectPercentile,SelectFromModel, chi2
from sklearn.neighbors import KernelDensity
from sklearn.neighbors import KNeighborsClassifier
from sklearn import model_selection
from sklearn.metrics import confusion_matrix #混淆矩阵
import operator`
读文件,并查看文件数据情况:
an=pd.read_csv('titanic3.csv')
an.info()
看到如下结果: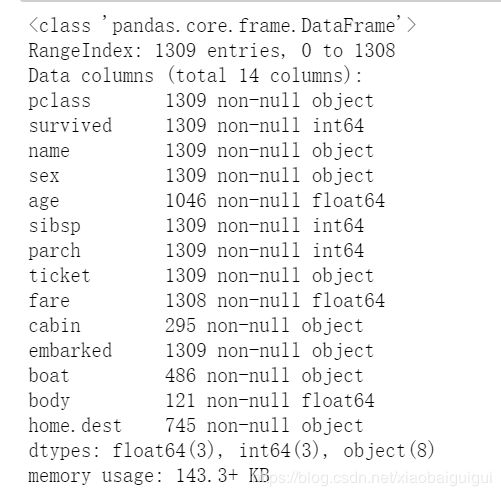
发现 age,cabin,fare都有缺失值(其他变量与存活率关系不大,可不考虑),接下来就是数据预处理了,先填充,然后再选特征变量。
填充如下图:
an['age']=an['age'].fillna(an['age'].median())
对于embarked我们用1,2,3来替代地点:
mapDict={'Southampton':1,'Cherbourg':2,'Queenstown':3}
an['embarked']=an['embarked'].map(mapDict)
an['embarked']=an['embarked'].fillna('1')
对于cabin,pclass也是替代,并用0填充:
an['cabin']=an['cabin'].fillna('0')
an[ 'cabin' ] = an[ 'cabin' ].map( lambda c : 1 )
an['pclass']=an['pclass'].map(lambda c:int(c[0]))
其他数据也类似:
sex_Dict={'male':1,'female':0}
an['sex']=an['sex'].map(sex_Dict)
an['fare']=an['fare'].fillna(an['fare'].mean())
an[ 'familysize' ] = an[ 'parch' ] + an[ 'sibsp' ] + 1
an['fare']=an['fare']/100
对name也进行预处理:
def getTitle(name):
str1=name.split( ',' )[1]
str2=str1.split( '.' )[0]
str3=str2.strip()
return str3
titleDf = pd.DataFrame()
titleDf['title'] = an['name'].map(getTitle)
titleDf.head()
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
titleDf['title'] = titleDf['title'].map(title_mapDict)
titleDf = pd.get_dummies(titleDf['title'])
titleDf.head()
an=pd.concat([an,titleDf],axis=1)
an.drop('name',axis=1,inplace=True)
然后就可以查看相关度,选择特征变量:
corrDf = an.corr()
corrDf['survived'].sort_values(ascending =False)
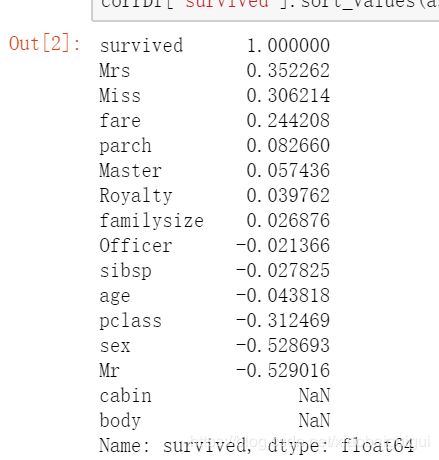
然后我是选择了[‘pclass’,‘sex’,‘fare’, ‘familysize’,‘Mrs’,‘Miss’,‘Master’]作为特征变量,划分训练集和测试集:
X = np.array(an[['pclass','sex','fare', 'familysize','Mrs','Miss','Master']])
Y=np.array(an['survived'])
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.5, random_state = 0)
接下来就是定义KNN算法(也可以直接调用库),KNN算法原理就是计算距离,将测试集标签定义为离训练集距离最小的k个点中最多的标签类中,我们可以直接用numpy进行矩阵的距离运算,然后根据距离大小排序(升序),从前k个点中找出其中标签最多的那个标签,这个就是我们对测试集预测的标签,再与测试集本身的标签对比可以计算出预测准确率。KNN如下:
#测试集应该一行一行输入
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0] #训练集行数
dif=np.tile(testdata,(traindatasize,1))-traindata #矩阵相减
sqdif=dif**2 #每个数都平方
sumsqdif=sqdif.sum(axis=1) #将一个矩阵的每一行向量相加,二维变一维
distance=sumsqdif**0.5 #距离
sortdistance=distance.argsort() #将distance中的元素从小到大排列,提取其对应的index(索引),然后输出到sortdistance
count={}
for i in range(0,k):
vote=labels[sortdistance[i]] #sortdistance[i]为原来元素的位置
count[vote]=count.get(vote,0)+1 #累计次数
sortcount=sorted(count.items(),key=operator.itemgetter(1),reverse=True)
return sortcount[0][0] #返回距离最近的那个标签
这样之后我们就可以用自己编写的KNN了,并画出混淆矩阵:
le=len(X_test)
a=b=c=d=0
for i in range(le):
q=knn(50,X_test[i],X_train,Y_train)
if Y_test[i]==1 and q==1:
d+=1
elif Y_test[i]==1 and q==0:
c+=1
elif Y_test[i]==0 and q==1:
b+=1
elif Y_test[i]==0 and q==0:
a+=1
得出准确率和混淆矩阵:
accury=(a+d)/len(X_test)
array=np.zeros([2,2])
array[0][0]=a
array[0][1]=b
array[1][0]=c
array[1][1]=d
print(array) #混淆矩阵
print("finish!")
print("准确率为:{}%".format(accury*100))
输出为:

准确率很低,算法还需要改善,小白作者会加油的!完整代码给你们:
#KNN算法编写
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score, precision_score,recall_score, f1_score, roc_curve
from pydotplus import graph_from_dot_data
import graphviz
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, KFold, GridSearchCV
from sklearn.preprocessing import Imputer, LabelEncoder, OneHotEncoder,LabelBinarizer
from sklearn.feature_selection import SelectKBest, SelectPercentile,SelectFromModel, chi2
from sklearn.neighbors import KernelDensity
from sklearn.neighbors import KNeighborsClassifier
from sklearn import model_selection
from sklearn.metrics import confusion_matrix #混淆矩阵
import operator
an=pd.read_csv('titanic3.csv')
an.info()
an['age']=an['age'].fillna(an['age'].median())
mapDict={'Southampton':1,'Cherbourg':2,'Queenstown':3}
an['embarked']=an['embarked'].map(mapDict)
an['embarked']=an['embarked'].fillna('1')
an['cabin']=an['cabin'].fillna('0')
an[ 'cabin' ] = an[ 'cabin' ].map( lambda c : 1 )
an['pclass']=an['pclass'].map(lambda c:int(c[0]))
sex_Dict={'male':1,'female':0}
an['sex']=an['sex'].map(sex_Dict)
an['fare']=an['fare'].fillna(an['fare'].mean())
an[ 'familysize' ] = an[ 'parch' ] + an[ 'sibsp' ] + 1
an['fare']=an['fare']/100
def getTitle(name):
str1=name.split( ',' )[1]
str2=str1.split( '.' )[0]
str3=str2.strip()
return str3
titleDf = pd.DataFrame()
titleDf['title'] = an['name'].map(getTitle)
titleDf.head()
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
titleDf['title'] = titleDf['title'].map(title_mapDict)
titleDf = pd.get_dummies(titleDf['title'])
titleDf.head()
an=pd.concat([an,titleDf],axis=1)
an.drop('name',axis=1,inplace=True)
an.head()
corrDf = an.corr()
corrDf['survived'].sort_values(ascending =False)
X = np.array(an[['pclass','sex','fare', 'familysize','Mrs','Miss','Master']])
Y=np.array(an['survived'])
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.5, random_state = 0)
print(len(X_test))
print(len(X_train))
#测试集应该一行一行输入
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0] #训练集行数
dif=np.tile(testdata,(traindatasize,1))-traindata #矩阵相减
sqdif=dif**2 #每个数都平方
sumsqdif=sqdif.sum(axis=1) #将一个矩阵的每一行向量相加,二维变一维
distance=sumsqdif**0.5 #距离
sortdistance=distance.argsort() #将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y
count={}
for i in range(0,k):
vote=labels[sortdistance[i]] #sortdistance[i]为原来元素的位置
count[vote]=count.get(vote,0)+1 #累计次数
sortcount=sorted(count.items(),key=operator.itemgetter(1),reverse=True)
return sortcount[0][0] #返回距离最近的那个标签
le=len(X_test)
a=b=c=d=0
for i in range(le):
q=knn(50,X_test[i],X_train,Y_train)
if Y_test[i]==1 and q==1:
d+=1
elif Y_test[i]==1 and q==0:
c+=1
elif Y_test[i]==0 and q==1:
b+=1
elif Y_test[i]==0 and q==0:
a+=1
accury=(a+d)/len(X_test)
array=np.zeros([2,2])
array[0][0]=a
array[0][1]=b
array[1][0]=c
array[1][1]=d
print(array)
print("finish!")
print("准确率为:{}%".format(accury*100))