1.3万字的支持向量机-含详尽的数学推导和细致全面的逻辑解释-第一部分
- 一、前言
- (1)现有SVM相关材料的贡献与不足
- 周志华《机器学习》
- 李航《统计学习方法》
- 支持向量机通俗导论(理解 SVM 的三层境界)
- 从零推导支持向量机
- (2)本文的贡献和不足
- 本文的贡献
- 本文的不足
- (3)阅读本文所需的数学知识
- (4)主动思考,亲自动手,化整为零
- (5)我的疑问
- (1)现有SVM相关材料的贡献与不足
- 二、相关定义和主要任务:
- (1)相关定义
- (2)任务
- 三、不存在噪音的训练数据集
- (1) 训练数据集线性可分
-
- 1)最优超平面的特征
- 2) 最大化硬间隔得目标函数和约束条件
- 21)支持向量与硬间隔
- 22)目标函数与约束条件
- 23) 简化约束条件
- 24)整理目标函数和约束条件
- 3) 构造拉格朗日函数得到对偶问题
- 4) 用SMO算法求解
-
- (2) 训练数据集线性不可分-核函数
-
- 1) 低维映射到高维的启发
- 2) 如何求解低维映射到高维后的线性超平面
- 21)直接在高维空间计算会比较复杂
- 22)使用核技巧和核函数
- 23)找到合适的核函数后,更改目标函数和约束条件
-
- (1) 训练数据集线性可分
后续见到https://blog.csdn.net/yeziand01/article/details/80871168 1.3万字的支持向量机-含详尽的数学推导和细致全面的逻辑解释-第二部分
一、前言
简要的总结,物以类聚,同类之间距离是相对较近,不同类之间距离相对较远。而支持向量机SVM就是要在空间上找出不同类之间的分界面,还要进一步找出其中最接近真相的那个分界面。在数学上,就表现为求解点到平面的最短距离,也就是求解在约束条件下的n元二次函数的最值【n为样本点的个数】。求解的手段上,先构造拉格朗日函数,再转为等价的对偶问题,再用SMO算法化整为零,将n元二次函数的最值问题转为二元二次函数,再转化为求一元一次函数的最值问题,并通过不等式解出变量的约束范围。
(1)现有SVM相关材料的贡献与不足
学习完SVM后,最大的感悟是对于初学者来说,不能只看一本教材,一篇文章,要“眼观六路,耳听八方”。每本教材,每篇文章都有它的闪光点,也有它不足之处。如果光看某一本教材或某一篇文章,你会发现自己被其中某个云里雾里的阐述卡住了,以至于无法往下看。下面是对一些材料的评价。
周志华《机器学习》
周志华的《机器学习》叙述相对流畅,有种娓娓道来感。比较闪光的部分是核函数、损失函数、核方法的介绍。但它含糊的地方也很多,比如:
1)未解释清楚为什么“划分间隔最大”的超平面学习能力最强。——周志华认为这样的超平面对样本扰动容忍能力最小,因而泛化能力最强。如果不深入思考,就会止步在这里,感觉好像懂了。但这只是一个结论,如何证明或量化样本扰动呢?如何证明或量化容忍能力呢?
2)未解释清楚为什么要假设支持向量落在超平面 wTx+b=1 w T x + b = 1 上。——这个假设是很重要的,将一个复杂的问题变成简单的问题。但周志华直接“令”支持向量落在该超平面上,仿佛这是个黑匣子,不需要知道过程,只要认同假设(笑哭脸)。但偏偏很多面试就会抓住这点来提问,因为教材没解释,谁明白了谁牛逼。
3)未解释清楚为什么要使用拉格朗日函数,为什么拉格朗日乘子要大于等于0,为什么要满足KKT条件?——没有为什么,只有是什么(再次笑哭)。
4)没有对SMO算法的详细推导过程,只有SMO的结论
5)为什么要引入松弛变量?松弛变量如何能表征样本点不满足约束的程度?——不解释。
6)对于非线性的训练数据集,为什么要映射到高维空间?这怎么想到的?——不解释。
总的来说,周志华对SVM的阐述里面,还是“是什么”成分居多,“为什么”成分相对较少,娓娓道来的风格本来是对初学者很友好的,但是却被惯性的”不解释“破坏了,可能大神自己知道为什么,就默认初学者也知道了。
李航《统计学习方法》
李航的《统计学习方法》就没有《机器学习》的柔性了。它里面一段话20个字,15个字是专业术语,显得非常“专业”。但“专业”跟对初学者的“友好”似乎是负相关的,像我这样的初学者看起来就非常头大。不过李航至少解释了周志华不解释的几个问题:
1)用点到平面距离度量超平面预测的确信度,因而“划分间隔”越大,超平面预测可信度越高,其泛化能力越强。
2)指出假设支持向量落在超平面 wTx+b=1 w T x + b = 1 对最优解没有影响,但没很好解释为什么没影响
3)解释清楚加入松弛变量后,参数C的意义
4)解释清楚对于非线性的训练数据集,如何想到映射到高维度空间去解决。
5)解释清楚核函数和映射规则(低维到高维)的区别
6)解释清楚SMO算法中变量的选择规则
7)解释清楚SMO算法中,常数项b的选择规则
但它的问题也很明显:
1)“一言不合就来数学证明”,把简单的问题弄到复杂化,证明的过程也并不详尽,只有重要的几步,其他还要读者自己推导。
2)核矩阵的定义、性质、种类说的非常复杂,没有周志华讲得清晰易懂
3)SMO算法中对变量的约束分析很突兀,直接上结论。
总的来说,虽然李航对SVM的阐述很多难懂的证明,对初学者可读性查,但在关键问题上还是解释“为什么”,这点比周志华要好很多。
支持向量机通俗导论(理解 SVM 的三层境界)
该文的作者是Jack Cui,网上阅读量非常高。我认为他解释得比较精彩的点是:
1)清晰解释了支持向量概念的来源。
2)解释怎么想到在高维空间去解决低维空间的非线性数据集划分问题
3)详细解释各种核函数
4)松弛变量的意义
下面是我并不认同的地方:
1)July从逻辑斯蒂回归解释标签 y={−1,+1} y = { − 1 , + 1 } ,但我认为 y y 之所以取 +1 + 1 , −1 − 1 ,是为了保证能通过 yf(x) y f ( x ) 的正负值判断样本点是否被正确分类。
从零推导支持向量机
该文的作者是南京大学的张皓。我认为他解释得比较精彩的点是:
1)经过缩放的最优解仍然是最优解。
2)从计算复杂度解释使用核技巧的原因
3)解释清楚软间隔支持向量机中,权重C的大小的意义
(2)本文的贡献和不足
本文的贡献
总的来说,本文是站在巨人的肩膀上,将各材料中的闪光之处无违和感地整合到一起,并做出非常细致的解释,对新手非常友好。特别是在数学推导上,尽可能详尽不略过任何一步,尽量减少读者的额外推导。具体来说,本文的贡献如下:
1)糅合了周志华没解释但李航解释,李航没解释但周志华解释的精华部分
2)解释清楚以下两位都没解释的问题
为什么要使用拉格朗日函数?
为什么拉格朗日乘子要大于等于0?
KKT条件是怎么得来的?
为什么将支持向量固定在超平面 wTx+b=1 w T x + b = 1 上,对求解最优超平面没有影响?
为什么非线性训练集要从低维映射到高维度去计算?这样会有什么缺陷?
为什么要引入核函数和核技巧?
引入松弛变量后的目标函数中权重C的意义?
巧用符号,简化SMO算法的数学推导。
3)以训练数据集是否线性可分,是否存在噪音,该如何解决的思路行文,更加有的放矢,中心明确。
4)用markdown语法写出数学推导,排版优美,方便阅读。
本文的不足
1)没有解释清楚对偶问题中的变量的原始值指什么?意义是什么?
2)对松弛变量的理解不够深入
3)对每种核方法的使用场景没有介绍
4)对实践中,完整计算一个SVM分类问题还没做出总结
5)没有涉及到SVM的变体
6)没有涉及到损失函数
(3)阅读本文所需的数学知识
1)空间几何:点到平面的距离公式
2)通过一阶导数求函数的最值
3)拉格朗日函数
4)线性代数中的矩阵简单运算知识
(4)主动思考,亲自动手,化整为零
除了要多看各种材料,主动思考,亲自动手,化整为零对SVM中的数学推导很重要。
现存各个材料在数学推导上面存在很多问题,比如貌似默认了读者懂了某个数学知识点,然后直接多步略过。或者嫌弃写过程太费力了,直接跳到最后一步。又或者符号体系出问题,上面的推导是符号a,下面突然冒出个符号b。这对我这种不能容忍一点点模糊的人来说就尴尬了。因为很多关键的假设都反应在推导的细节上面,而不是最后的结果上面。不了解推导过程,就无法在数学层面论证假设,那假设就像“光棍司令”,没有任何科学的支撑(此处科学指的是数学)。
这样,就需要自己硬着头皮,主动思考,不理会暂时看不懂的材料的某步推导,从自己能看懂的地方开始一步一步顺着自己的思路推导,这就是化整为零。若材料中也有某步的推导,就时不时检验下自己的推导是否与之吻合。通过不断缩小推导的起点与推导的终点之间的间隔,最后推出结果后,再回去看材料的推导,会发现自己居然看明白了之前视之为天书的各种材料中的推导。
化整为零在写作的时候也很重要,一开始可能完全没有思路该怎么组织要阐述的内容,可能只有豆芽一点大小的想法。不灰心,不嫌弃,把它给整理出来,你会发现,咦,虽然下下一步不知道说什么,但下一步好像知道怎么组织了。
(5)我的疑问
1)引入噪音后的模型中KKT条件中 α=C α = C 时,就分类错误,为什么还能是最优解要满足的情况之一?
二、相关定义和主要任务:
(1)相关定义
1)假设训练数据集 D D 有 n n 个样本点,即 D={(x1,y1),(x2,y2),...,(xn,yn)} D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } , xi x i 代表第 i i 个样本点,每个样本点 x x 有 d d 个特征,即 x=(x1,x2,...,xd) x = ( x 1 , x 2 , . . . , x d ) , xi x i 是第 i i 个特征。 y y 代表真实值, yi y i 代表第 i i 个样本点所对应的真实值。现在我们要处理的任务是二分类问题,即 y={−1,+1} y = { − 1 , + 1 } 。
2)将所有样本点描绘在一个 d d 维的空间中(如果d=2,则为平面;如果d=3,则为立体空间,如果d>3,则为高维空间)。假设 d d 维的空间中,存在一个超平面,即 wTx+b=0 w T x + b = 0 。其中, w=(w1,w2,...,wd) w = ( w 1 , w 2 , . . . , w d ) ,是超平面 p p 的法向量, b b 是位移项,决定了超平面 p p 和原点的距离。位于超平面上方的点 xi x i ,有 f(xi)=wTxi+b>0 f ( x i ) = w T x i + b > 0 ;位于超平面下方的点有 f(xi)=wTxi+b<0 f ( x i ) = w T x i + b < 0 ;
我们规定,正确分类的定义是,所有正类( y=1 y = 1 )都在超平面 p p 的上方;所有的负类( y=−1 y = − 1 )都在超平面 p p 的下方。明显,若某超平面对某点分类正确的话,应有 yf(x)=y(wTx+b)>0 y f ( x ) = y ( w T x + b ) > 0 。而且在分类正确的点中,若点 xa x a 比点 xb x b 离超平面更远,则有 yaf(xa)>ybf(xb)>0 y a f ( x a ) > y b f ( x b ) > 0 。若分类错误的话,比如正类( y=1 y = 1 )分在超平面 p p 的下方,或者负类( y=−1 y = − 1 )在超平面 p p 的上方,此时应有 yf(x)=y(wTx+b)<0 y f ( x ) = y ( w T x + b ) < 0 。
3) 空间中任意一点 x x 到一个超平面 p p 的距离为 r=|wTx+b|||w|| r = | w T x + b | | | w | | 。其中 ||w||=w21+w22+...+w2d−−−−−−−−−−−−−−√,|wTx+b|=|w1x1+w2x2+...+wdxd+b| | | w | | = w 1 2 + w 2 2 + . . . + w d 2 , | w T x + b | = | w 1 x 1 + w 2 x 2 + . . . + w d x d + b |
(2)任务
1)首先,现在我们希望找到一个超平面 p p ,能将正类负类完全分开。
通过最小化“误分类点到超平面的距离”,我们可以得到多个符合条件的超平面,即 wTx+b=0 w T x + b = 0 存在多组解,见本博客另一篇博文。https://blog.csdn.net/yeziand01/article/details/80581912
2)能够将正类、负类的点分开的超平面有很多个,我们应该选择哪一个?
我们希望进一步找到一个超平面,不仅能将训练集中正、负类的点分开,而且对于训练集外的点也能够恰当地分类。这样的一个平面,我们称之为最优超平面。
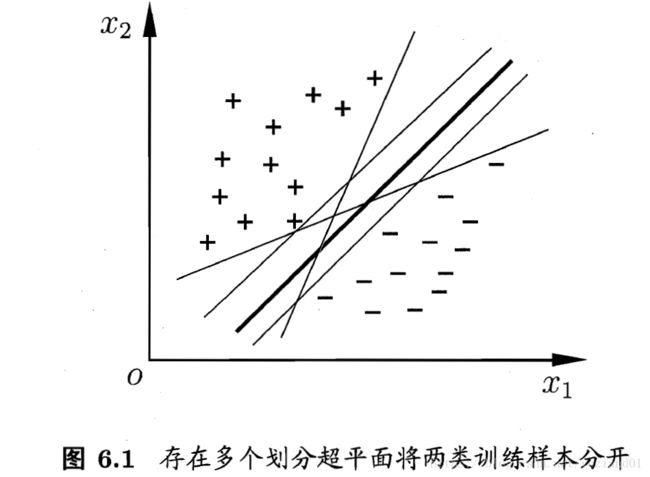
备注:该图引自《机器学习》-周志华
三、不存在噪音的训练数据集
现在我们假设,我们的训练数据集是不存在噪音的,我们将训练数据集分为线性可分,和线性不可分两种情况来讨论,如何找到最优超平面。
(1) 训练数据集线性可分
1)最优超平面的特征
首先,我们来研究超平面对未知的点分类的准确度。如下图所示:
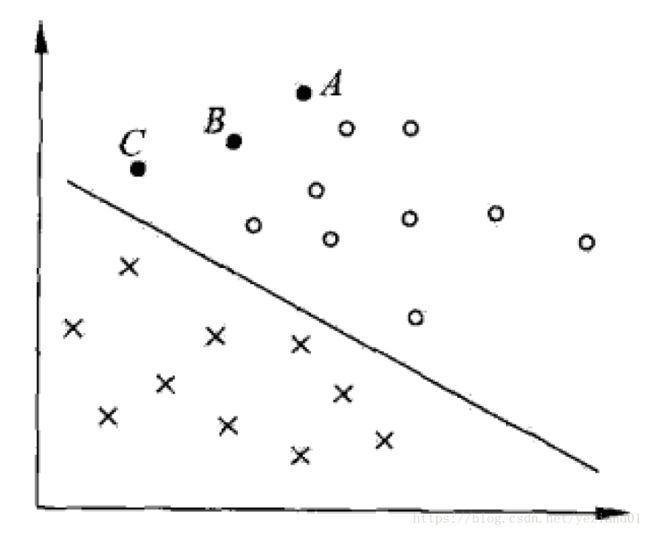
备注:该图源于李航《统计学习方法》
假设我们已经根据训练集得到一个能将正类(圆圈)、负类(交叉)分开的超平面(图中的直线),现在有三个训练集之外的点A、B、C,均位于超平面上方,因而均被预测为正类。
其中A离超平面最远,若预测A为正类,则就比较确信预测是正确的。为什么?如果A实际上是负类,那么要将我们训练出的超平面转过很大的角度才能得到A分类正确,但这样会导致其他很多点分类出现错误。因此我们认为A不大可能是负类,而很可能是正类。
另一方面,C离超平面最近,若预测C为正类,我们不那么确信预测是正确的。为什么?因为就算C实际是负类,我们只需将训练出来的超平面稍微转一下,就可以将C分类正确,而其他点可能仍然保持分类正确。所以,C有可能是负类。
也就是说,一般而言,一个点距离超平面的远近可以表示分类预测的确信程度。一个点离超平面越远,我们越确信得到正确的预测。一个点离超平面越近,我们越不确信能得到正确的预测。这个对训练集的点也同样成立。
我们希望对于那些最难分的点(离超平面最近的点),也有足够大的确信度将它们分开,我们认为这样的超平面应该对于未知的点也有很好的预测能力。因此最理想的超平面应该是离这些最难分的点最远的。如下图所示,最优的超平面应该是正中间的那条直线(最粗那条)代表的超平面。因为它离正负类最近的点的距离最远。
备注:该图引自《机器学习》-周志华
现在总结下我们所寻找的最优超平面的特质
1)能将正负类点完全分开
2)离超平面最近的点到超平面的距离取得最大值
3) 位于离超平面最近的点的正中间
2) 最大化硬间隔得目标函数和约束条件
21)支持向量与硬间隔
知道了最优超平面的特质后,我们可以进行最优超平面的数学分析。如下图所示。
备注:该图片来源于https://blog.csdn.net/macyang/article/details/38782399/
假设最优超平面为 wTx+b=0 w T x + b = 0 ,它是位于正中间的红色线,而离超平面最近的点位于粉色线和蓝色线上。它们起到“支撑”该结构的作用,这些点就叫做支持向量(support vector)。
最优超平面到正类最近的点的距离等于它到负类最近的点的距离。也就是红色线到粉色线的距离,以及红色线到蓝色线的距离,两者是相等的。假设蓝线上的支持向量点 xa x a 到最优超平面的距离为 |wTxa+b|||w|| | w T x a + b | | | w | | ,粉线上的点到最优超平面的距离与之相同,因此蓝线和粉线之间的距离可定义为 γ(w,b)=2|wTxa+b|||w|| γ ( w , b ) = 2 | w T x a + b | | | w | | , γ γ 就是硬间隔(hard margin)【和软间隔区别在于,硬间隔是超平面对所有点均分类正确下的间隔】。
22)目标函数与约束条件
而我们的目标就是让间隔 γ γ 取得最大值,即
另外一方面,因为其他所有被正确分类的点都比蓝线上的支持向量点 xa x a 离超平面的距离相等或更远,因而根据 上面的分析可得到 yi(wTxi+b)≥yaf(xa)>0,i=1,2,...,n y i ( w T x i + b ) ≥ y a f ( x a ) > 0 , i = 1 , 2 , . . . , n 。而 yaf(xa)=|wTxa+b| y a f ( x a ) = | w T x a + b | ,因此我们有
归纳下,我们的目标是求在2)式约束下,1)式的最优解,可写成以下形式:
这里,我们要注意到, r r 的取值对目标函数和约束都没有影响,即就算我们将 r r 扩大 c(c>0) c ( c > 0 ) 倍,即将 (w,b) ( w , b ) 变为 (cw,cb) ( c w , c b ) 【见推导】,不会改变求得的最优超平面。因为如果 (w∗,b∗) ( w ∗ , b ∗ ) 是最优解, (w∗)Tx+b∗=0 ( w ∗ ) T x + b ∗ = 0 是最优超平面 p p ,那么对于任意 c>0 c > 0 , (cw∗,cb∗) ( c w ∗ , c b ∗ ) 也是最优解, ((cw)∗)Tx+(cb)∗=0 ( ( c w ) ∗ ) T x + ( c b ) ∗ = 0 仍然是该最优超平面 p p 【见推导】。
推导: cr=c|wTxi+b|=|cwTxi+cb|=|(cw)Txi+(cb)| c r = c | w T x i + b | = | c w T x i + c b | = | ( c w ) T x i + ( c b ) |
((cw)∗)Tx+(cb)∗=c((w∗)Tx+b∗)=0→(w∗)Tx+b∗=0 ( ( c w ) ∗ ) T x + ( c b ) ∗ = c ( ( w ∗ ) T x + b ∗ ) = 0 → ( w ∗ ) T x + b ∗ = 0
23) 简化约束条件
因此,为了简化问题,我们可以设 r=|wTxa+b|=1(xa是支持向量) r = | w T x a + b | = 1 ( x a 是 支 持 向 量 ) ,则目标函数和约束变为:
而当我们设 r=|wTxa+b|=1(xa是支持向量) r = | w T x a + b | = 1 ( x a 是 支 持 向 量 ) 时,就意味着我们将支持向量 xa x a 固定在超平面 wTx+b=±1 w T x + b = ± 1 上,如下图所示,被圆圈圈着的是支持向量。
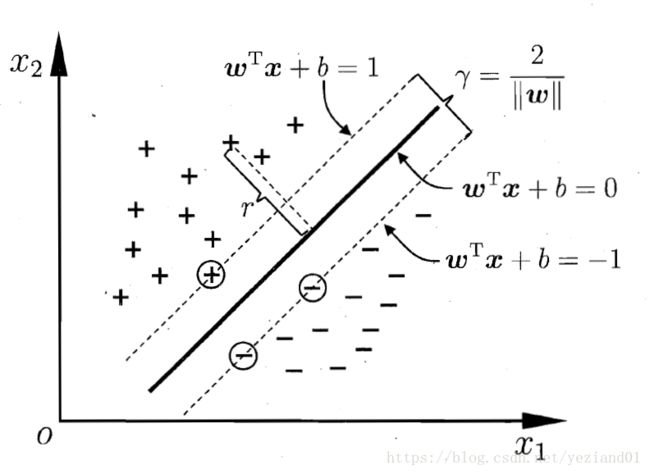
决定超平面时,只有支持向量起作用,其他点并不起作用。移动支持向量,将会改变所求的最优超平面。但支持向量外的点,在间隔边界一侧移动它们,甚至去掉它们,不影响最优超平面。可见,支持向量在确定最优超平面中起到决定性的作用。而支持向量是很少的,可见支持向量机是由训练集中很少但重要的样本点(支持向量)所决定。
24)整理目标函数和约束条件
最大化 2||w|| 2 | | w | | ,等价于最小化 12||w||2 1 2 | | w | | 2 ,因此上述公式等价于:
变形得
这个就是支持向量机(Support Vector Machine,SVM)的基本型。
3) 构造拉格朗日函数得到对偶问题
由上已经得出了最优超平面的数学公式-SVM的基本型,现在我们来探讨如何求解最优超平面。
注意到SVM的基本型是在给定不等式约束条件下,求目标函数的最小值。因此,我们可以用拉格朗日乘子法求解。【关于拉格朗日乘子法求最优化问题,可见本博客另一篇博文https://blog.csdn.net/yeziand01/article/details/80765415】
首先,我们想构造拉格朗日函数 L≤f L ≤ f ,当 L L 取得最大值时, f f 可取得最小值。
其中, 拉格朗日乘子 αi≥0,(i=1,2,...,n) α i ≥ 0 , ( i = 1 , 2 , . . . , n ) 【KKT条件之1】。因为要保证 L≤f L ≤ f , L L 的第二项中 1−yi(wTxi+b)≤0 1 − y i ( w T x i + b ) ≤ 0 ,若 αi≤0 α i ≤ 0 ,则第二项的最大值是正无穷大 ∞ ∞ , L≤f L ≤ f 不能恒成立。 只有当 αi≥0 α i ≥ 0 ,才能保证第二项最大值是0,从而 L≤f L ≤ f 恒成立。
也就是,当L取得最大值时,必然要求
对于任意样本点 xi x i ,总有 αi=0 α i = 0 或 αi>0,yi(wTxi+b)=1 α i > 0 , y i ( w T x i + b ) = 1 。当 αi=0 α i = 0 时,证明该点对最优解没有任何约束,也就是不会影响最优解。当 αi>0,yi(wTxi+b)=1 α i > 0 , y i ( w T x i + b ) = 1 时,即 αi>0,|wTxi+b|=1 α i > 0 , | w T x i + b | = 1 ,该点影响最优解,且该点为支持向量。这从数学的角度,再一次论证了 支持向量机是由训练集中很少但重要的样本点(支持向量)所决定
现在我们令 L L 对 w w , b b 求导:
L=12wTw+∑ni=1αi−wT∑ni=1αiyixi−b∑ni=1αiyi L = 1 2 w T w + ∑ i = 1 n α i − w T ∑ i = 1 n α i y i x i − b ∑ i = 1 n α i y i
∂L∂w=12∂wTw∂w−∂wT∂w∑ni=1αiyixi=12∗2w−∑ni=1αiyixi=w−∑ni=1αiyixi=0→w=∑ni=1αiyixi ∂ L ∂ w = 1 2 ∂ w T w ∂ w − ∂ w T ∂ w ∑ i = 1 n α i y i x i = 1 2 ∗ 2 w − ∑ i = 1 n α i y i x i = w − ∑ i = 1 n α i y i x i = 0 → w = ∑ i = 1 n α i y i x i
∂L∂b=−∑ni=1αiyib=0→0=∑ni=1αiyi ∂ L ∂ b = − ∑ i = 1 n α i y i b = 0 → 0 = ∑ i = 1 n α i y i
解得:
这时,我们的目标函数最优解可以写成 f(x)=wTx+b=∑ni=1αiyixix+b f ( x ) = w T x + b = ∑ i = 1 n α i y i x i x + b
再将此结果代入 L L 中,消掉 w w , b b :
L=12wTw+∑ni=1αi−wTw=∑ni=1αi−12wTw L = 1 2 w T w + ∑ i = 1 n α i − w T w = ∑ i = 1 n α i − 1 2 w T w
=∑ni=1αi−12(∑ni=1αiyixTi)(∑nj=1αjyjxj) = ∑ i = 1 n α i − 1 2 ( ∑ i = 1 n α i y i x i T ) ( ∑ j = 1 n α j y j x j )
=∑ni=1αi−12∑ni=1∑nj=1αiyiαjyjxTixj = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i y i α j y j x i T x j
由此,我们可以得到 L L 的等价问题 g g ,也称为对偶问题,记做:
变形得
4) 用SMO算法求解
详见下面的非线性训练数据集中的SMO算法求解。
(2) 训练数据集线性不可分-核函数
1) 低维映射到高维的启发
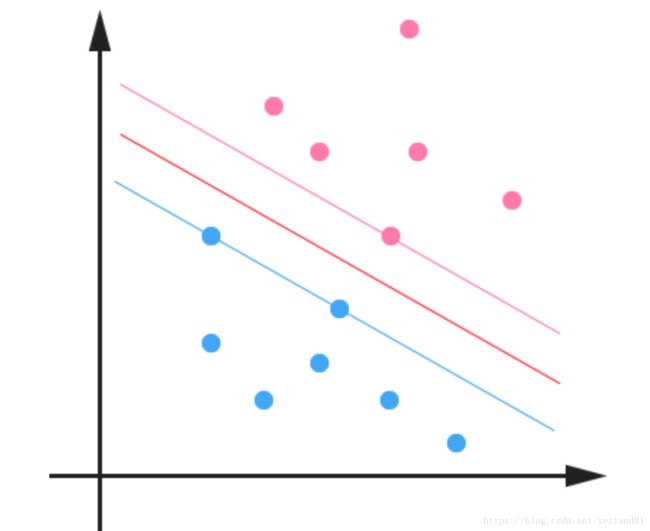
之前我们假设训练数据集是线性可分的,才可能找到一个线性超平面。但当训练数据集并非线性可分时(如下例所示),该如何处理?
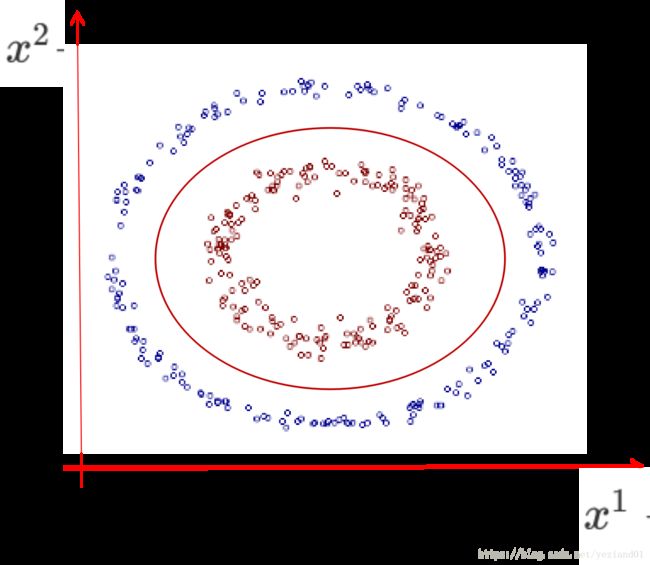
上图中的训练集数据的样本有两个特征, x1 x 1 和 x2 x 2 ,其理想的划分边界应该是椭圆,而不是直线。椭圆的一般方程为:
若我们记 z1=(x1)2,z2=(x2)2,z3=x1x2,z4=x1,z5=x2 z 1 = ( x 1 ) 2 , z 2 = ( x 2 ) 2 , z 3 = x 1 x 2 , z 4 = x 1 , z 5 = x 2 ,则有 α1z1+α2z2+α3z3+α4z4+α5z5+b=0 α 1 z 1 + α 2 z 2 + α 3 z 3 + α 4 z 4 + α 5 z 5 + b = 0
再记 w=(α1,α2,α3,α4,α5)T,z=(z1,z2,z3,z4,z5)T w = ( α 1 , α 2 , α 3 , α 4 , α 5 ) T , z = ( z 1 , z 2 , z 3 , z 4 , z 5 ) T ,则有 wTz+b=0 w T z + b = 0 。这和我们的线性超平面方程是一样的。
因此,这给我们一个启发,我们可以将低维空间中的样本点映射到高维的空间去,本例中即将2维的样本点映射成5维的样本点。这样,我们在高纬度的空间,也许能够找到一个划分正、负类样本点的线性超平面。
本例的映射规则为
事实上,我们有个定理,当维数有限时,一定存在一个更高的维度,让样本空间映射到高维度后能够线性可分。
2) 如何求解低维映射到高维后的线性超平面
21)直接在高维空间计算会比较复杂
假设我们已经根据一定的规则,将每个样本点从低维度 d d 的空间映射到高维度 d~ d ~ 的空间,并且在高维度的空间中,存在一个线性超平面将正负类样本点分开,那该如何求解高维度中的线性超平面?
确定了映射规则后,我们的目标函数和约束条件变为:
当样本点从2维映射到5维时,内积 ϕ(xTi)ϕ(xj) ϕ ( x i T ) ϕ ( x j ) 的计算,需要我们先分别计算 ϕ(xTi) ϕ ( x i T ) [5步]、 ϕ(xTj) ϕ ( x j T ) [5步],再计算 ϕ(xTi)ϕ(xj) ϕ ( x i T ) ϕ ( x j ) [5步],总的来说,我们要计算3*5=15步。算法的复杂度是 O(d~) O ( d ~ ) ,跟映射后的高纬度维数 d~ d ~ 相关。
当我们映射到的维度很高,甚至无穷维时,存储所需要的空间以及计算所需要的时间都是巨大的或不可承受的,因此我们希望找到一个新的方法,能降低计算的时间复杂度和空间复杂度。
22)使用核技巧和核函数
注意到内积 ϕ(xTi)ϕ(xj) ϕ ( x i T ) ϕ ( x j ) 是 xi x i 和 xj x j 的函数,我们希望找到一个新函数 κ(xi,xj)=ϕ(xTi)ϕ(xj) κ ( x i , x j ) = ϕ ( x i T ) ϕ ( x j ) ,并且计算 κ(xi,xj) κ ( x i , x j ) 的复杂度是 O(d) O ( d ) ,这就是核技巧,而这个新函数称之为核函数。
由上可见,核技巧就是找到一个核函数 κ(xi,xj) κ ( x i , x j ) ,让特征映射 ϕ(xTi) ϕ ( x i T ) 、 ϕ(xTj) ϕ ( x j T ) 和内积计算 ϕ(xTi)ϕ(xj) ϕ ( x i T ) ϕ ( x j ) 压缩为核函数 κ(xi,xj) κ ( x i , x j ) 的计算,让计算的复杂度由高维度的 O(d~) O ( d ~ ) 下降到低维度的 O(d) O ( d ) 。
明显,如果我们知道映射规则 ϕ ϕ 的具体形式,那就可以写出核函数。但在现实中,我们通常不知道映射规则是什么,那合适的核函数是否一定 存在呢?什么样的函数才能作为核函数呢?
核函数的定义
首先,核函数必然是个对称函数。
其次,对于任意数据集D,只有当以下的矩阵(核矩阵)为半正定时,函数 κ(xi,xj) κ ( x i , x j ) 才是核函数。反过来,若函数 κ(xi,xj) κ ( x i , x j ) 是核函数,核矩阵必然为半正定矩阵。
>K=⎡⎣⎢>κ(x1,x1)...κ(x1,xn)>...>κ(xn,x1)...κ(xn,xn)>⎤⎦⎥> > K = [ > κ ( x 1 , x 1 ) . . . κ ( x 1 , x n ) > . . . > κ ( x n , x 1 ) . . . κ ( x n , x n ) > ] >
核函数的性质如果 κ1 κ 1 和 κ2 κ 2 是核函数,那么其任意的线性组合 r1κ1+r2κ2,r1>0,r