muduo源码分析之Buffer设计
好久没有看muduo了,最近看Nginx看的有点醉,换换口味。
(一)阻塞与非阻塞I/O总结
1、对于read 调用,如果接收缓冲区中有 20字节,请求读 100个字节,就会返回 20;对于 write调用,如果请求写 100个字节,而发送缓冲区中只有 20个字节的空闲位置,那么 write会阻塞,直到把 100个字节全部交给发送缓冲区才返回。
对于非阻塞I/O来说,以write为例,假设要保证将应用程序的100个字节全部发送,这个时候write了20个字节的数据之后,由于发送缓冲区满,write返回一个EAGAIN的错误,为了保证能够将数据全部发送,需要写一个循环:
int n = strlen(buffer);//n : 100 bytes
while (n > 0) {
nwrite = write(fd, buf + data_size - n, n);
if (nwrite < n) {//未全部发送
if (nwrite == -1 && errno != EAGAIN) {
perror("write error");
}
break;
}
n -= nwrite;//剩余待发送
}2、read 没有一点数据可读或 write 没有一点空间可以写入,如果disable O_NONBLOCK 则会阻塞。如果enable O_NONBLOCK 则会返回-1,errno = EAGAIN | EWOULDBLOCK 错误。(这是阻塞与非阻塞I/O最直观的说明)
3、阻塞模式下可以用setsockopt设置SO_RCVTIMEO(超时时间),即如果在超时时间内接收缓冲区都没有一点数据到来,那么返回-1,errno = EAGAIN | EWOULDBLOCK 错误。
同理,还有SO_SNDTIMEO 选项,在超时时间内发送缓冲区都没有足够内存存放数据,也是返回-1,errno = EAGAIN | EWOULDBLOCK 错误。
4、recv的第四个参数若为MSG_WAITALL,则在阻塞模式下不等到指定数目的数据不会返回,除非超时时间到。当然如果对方关闭了,即使超时时间未到,recv 也返回0。/usr/include/i386-linux-gnu/bits/socket.h MSG_WAITALL = 0x100
5、在多线程环境中,某个线程的阻塞不会引起进程的阻塞,除非进程中的所有线程都被阻塞。(pthread)
(二)muduo::Buffer简介
在上述I/O中,进程直接跟套接字打交道,muduo对I/O做了一层封装,让网络库与真正的套接字打交道,在应用层只需要利用封装的Buffer完成数据的收发,下面简要介绍其实现。
对于一个TcpConnection来说,在应有层对Buffer的封装有两个方面。
1.TcpConnection必须要有
output buffer
2.TcpConnection必须要有input buffer
2.1Output Buffer简介
假设现在套接字可写(发送缓冲未满),poll/epoll/select的POLLOUT事件激活,应用程序想要通过TCP连接发送100KB数据,但是现在发送缓冲区只有80KB空闲,那么当写满80KB后,write阻塞,这不是所期望的,因为我们希望尽快返回event loop去等待其他可能发生的事件,这20KB数据怎么办?
此时,网络库就需要维护一个发送缓冲,应用程序无需关心数据怎么发送。对于上述多于的20KB数据,完全可以由网络库的Output Buffer接管,然后注册POLLOUT事件。另外,比如当Output Buffer里面还有20KB数据的时候,应用程序又要发送50KB程序,则将这50KB数据append到20KB数据之后;再比如当Output Buffer里面还有数据时关闭连接,网络库并不是立即关闭连接,而是半关闭,shutdown(),先关闭读端(等待在路上的数据,也就是Output Buffer里面的数据),然后等待对方关闭连接后再关闭。
2.2Input Buffer简介
对于event loop来说,当socket可读时,网络库需要一次将接收缓冲的内容拷贝到应用层buffer,否则将一直触发POLLIN,当对端的消息可能分多次收到时,由于TCP是一个无边界的字节流协议,网络库将要保证当接收到的内容构成一条完成的消息再通知应用程序进行业务逻辑,这就是Input Buffer的主要任务。
2.3总结
所谓的Input和Output来说,是针对应用程序来说,应用程序从Input读数据,往Output写数据;而TcpConnection则相反,它把从套接字读取的数据放到Input Buffer里面;从Output Buffer里面读出数据写入到套接字发送缓冲区中。
(三)muduo::Buffer设计
muduo::Buffer的要点如下:
使用vector保存数据,因此size()是可变的,使用时像一个queue,在尾部写入数据,往头部写入数据,通过两个int索引(readIndex可类比队列的front 和 writeIndex可类比队列的rear)来维护。
为什么要使用2个int的索引而不是用迭代器或者指针?
这跟std::vector的设计有关,size表示vector中实际对象的大小,capability则表示vector的容量,它的扩充是指数级的。当vector需要需要扩充时,会申请一段更大内存将之前的数据copy进来,再销毁原来的内容。
也就是说,一旦vector发生扩容,迭代器将会失效。
另外,muduo的设计者将Buffer前添加了一段8字节的预留空间(称之为prependable)。这样做的好处,比如Input Buffer收到来自网络的消息,并计算它的长度后,可以将这个长度值写入到prependable区域,简化使用。
muduo::Buffer设计如图:
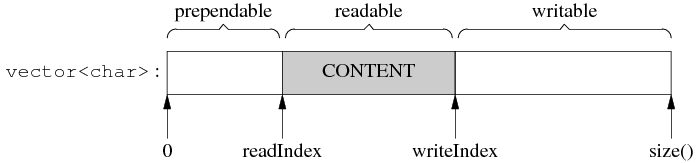
因此得到如下计算公式:
prependable = readIndex
readable = writeIndex - readIndex
writable = size() - writeIndex
当writeIndex==readIndex,Buffer为空。
Buffer的操作
1.基本读写操作
写入操作将writeIndex向后移动。
读出操作将readIndex向后移动。
2.自动增长
当要写入的数据大于Buffer的可写入大小后需要对Buffer进行扩容。
由底层的vector特性帮助实现。
3.内部腾挪
跟队列类似,设想当读写操作频繁时,readIndex和writeIndex都会往后移动,留下了巨大的prependable空间,此时如果再写入数据,将会不会重新分配内存,而是将已有的数据往前挪动(同时挪动readIndex和writeIndex)。
4.前方添加
也就是作者为什么要预留8个字节的prependable空间,可以写入数据的头部信息,方便使用。
(四)muduo::Buffer源码分析
源码出处:https://github.com/chenshuo/muduo
此处为部分个人注释版本(略去一些内容):muduo/net/Buffer.h和muduo/net/Buffer.cc
//Buffer.h
class Buffer : public muduo::copyable
{
public:
//初始化prepend为8个字节大小
static const size_t kCheapPrepend = 8;
//初始化Buffer大小为1024字节 默认
static const size_t kInitialSize = 1024;
//计算可读
size_t readableBytes() const
{ return writerIndex_ - readerIndex_; }
//计算可写
size_t writableBytes() const
{ return buffer_.size() - writerIndex_; }
//计算prependable大小
size_t prependableBytes() const
{ return readerIndex_; }
//用来返回数据内容的起始位置
const char* peek() const
{ return begin() + readerIndex_; }
//该函数用来回收Buffer空间,在读取Buffer的内容后
//调用此函数来挪动索引
void retrieve(size_t len)
{
assert(len <= readableBytes());
if (len < readableBytes())
{
readerIndex_ += len;
}
else
{
//当要回收的大小超过可读的个数,直接回收所有空间
retrieveAll();
}
}
//回收所有Buffer,将两个索引回归到初始位置
void retrieveAll()
{
readerIndex_ = kCheapPrepend;
writerIndex_ = kCheapPrepend;
}
//写入数据
void append(const char* /*restrict*/ data, size_t len)
{
//ensure保证Buffer有足够空间可写,其中关键函数makeSpace见后
ensureWritableBytes(len);
//copy(iterator first,iterator last,iterator result)
std::copy(data, data+len, beginWrite());
hasWritten(len);//挪动writeIndex
}
void ensureWritableBytes(size_t len)
{
if (writableBytes() < len)
{
makeSpace(len);
}
assert(writableBytes() >= len);
}
private:
void makeSpace(size_t len)
{
if (writableBytes() + prependableBytes() < len + kCheapPrepend)
{
//resize,这个时候是真的不够了
buffer_.resize(writerIndex_+len);
}
else
{
//将数据挪动到Buffer的前面,因为前面prependable还有富余空间
assert(kCheapPrepend < readerIndex_);
size_t readable = readableBytes();
std::copy(begin()+readerIndex_,
begin()+writerIndex_,
begin()+kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}
private:
std::vector<char> buffer_;//底层存储
//读写索引
size_t readerIndex_;
size_t writerIndex_;
};Buffer如何从读取数据,当缓冲区足够大的时候,可以减少我们的系统调用,但是如果每个连接都有一个50KB的读写缓冲,那么当并发连接达到10000的时候,将占用1GB的内存空间,这个开销不小,并且很多情况下缓冲区的使用率不高。
muduo::Buffer的做法比较巧妙,由上代码可知,底层默认会有一个1KB大小的vector,除此之外,muduo在栈上申请一个65536字节大小的临时空间,这是当网络套接字数据太大时,可以将超出1K的数据先放入这个临时空间,然后在append到Buffer里面(这个时候Buffer就会resize一个适应的大小)。利用readv()系统调用可以实现,“The readv() system call works just like read(2) except that multiple buffers are filled.” 通过参数iovec控制。
//Buffer.cc
// 结合栈上的空间,避免内存使用过大,提高内存使用率
ssize_t Buffer::readFd(int fd, int *savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read
// 节省一次ioctl系统调用(获取有多少可读数据)
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
// 第一块缓冲区
vec[0].iov_base = begin() + writerIndex_;
vec[0].iov_len = writable;
// 第二块缓冲区
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
const ssize_t n = sockets::readv(fd, vec, 2);
if (n < 0)
{
*savedErrno = errno;
}
else if (implicit_cast(n) <= writable) //第一块缓冲区足够容纳
{
writerIndex_ += n;
}
else // 当前缓冲区,不够容纳,因而数据被接收到了第二块缓冲区extrabuf,将其append至buffer
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
// if (n == writable + sizeof extrabuf)
// {
// goto line_30;
// }
return n;
} (五)参考
1.《linux 多线程服务器编程:使用muduo c++网络库》
2.http://blog.csdn.net/jnu_simba/article/details/14453603