数据分析师必知必会:AB测试项目复盘(附PPT、python源码)
↑ 点击上方 “凹凸数据” 关注 + 星标 ~
每天更新,大概率是晚9点 

近期和团队完成了一次AB测试,期间发现有些小伙伴对AB测试的理解还不够透彻,刚好项目结束,结合实际情况,对AB测试做一次完整梳理,一方面算是复盘实际项目,另一方面也算是个总结,以帮助更多的初级数据分析师快速掌握一些高阶方法,促进晋升。
在做AB测试时,如果你没有想过需要做一些假设检验,或者是统计分布,那更应该好好看看这篇文章,这里不仅是理论框架,以及实操中的注意事项,还有一个完整实例数据案例,建议收藏,在实操时可以跟着一步步操作,更能加强理解(文末附数据来源)。
本篇文章共分为四个部分:走进AB测试、拓展AB测试、实战AB测试以及代码实操
 目录
目录
首先进入第一部分:
1、走进AB测试
 第 1 部分:走进AB测试
第 1 部分:走进AB测试
 AB测试来源
AB测试来源
AB测试最早来源于医学中的“双盲测试”,即让随机产生的两组病人,在不知情的情况下分别服用安慰剂和测试用药,经过一段时间观察,比较两组病人是否具有显著差异,以决定测试用药是否有效。
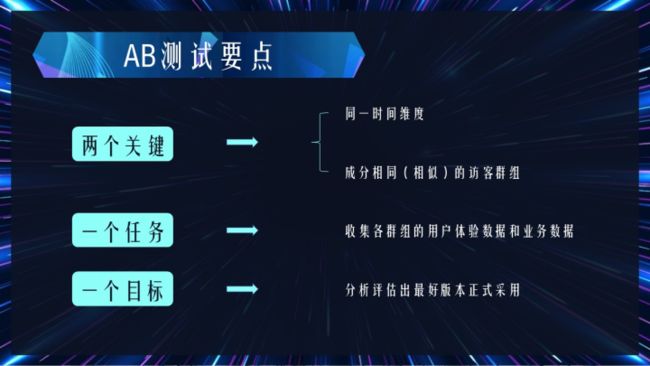 AB测试要点
AB测试要点
针对定义分析可以看出,AB测试的关键要求为“同一时间维度”和“成分相同(相似)的访客群组”,通过“收集用户体验数据和业务数据”,以“分析评估最好版本正式采用”。
 AB测试应用场景
AB测试应用场景
AB测试的主要应用场景一共有两个:界面设计、算法优化。
界面设计:调整界面颜色、按钮颜色、界面外观等因素,通过视觉效果达到吸引用户的作用。
例如:在界面设计方面,早期重点推荐的是写实风格,即页面中的元素更逼真化,而近几年的界面设计更偏向于扁平风格,虽然不是逼真如实物,也能让用户快速判断图标的作用;早期比较推崇的是单一颜色的界面风格,而近几年,渐变色风格逐渐开始占据一定地位。
算法优化:重点针对页面中显示的元素进行优化,如根据推荐算法向用户推荐一些高频搜索或者关注的内容,或者调整不同小版块的出现顺序或者所在位置,帮助用户在最短时间内到达自己需要的功能。
例如:在算法上,在微信上使用任何主要功能时,操作基本上都控制在3个操作步骤以内。
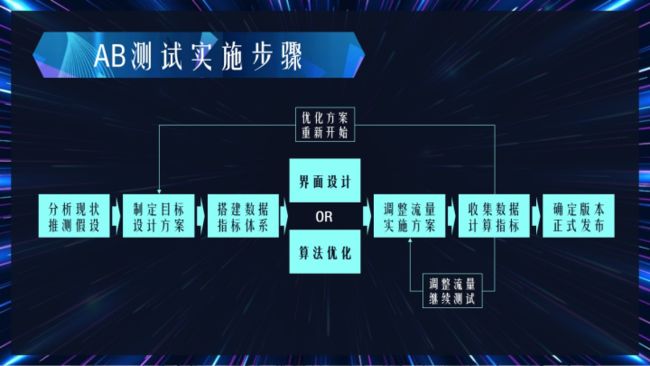 AB测试实施步骤
AB测试实施步骤
AB测试从计划开始到最终结束,主要分为7个步骤。
 测试流程
测试流程
想要推进AB测试,切不能一次性给全部用户推进,如果最初设定的优化方向后期需要调整,那带给公司的损失是不可估量的。
 AB测试推进节奏
AB测试推进节奏
推进AB测试时,不仅要考虑推进节奏,还有注意以下三个问题:
 AB测试注意事项(一)
AB测试注意事项(一)
 AB测试注意事项(二)
AB测试注意事项(二)
 AB测试注意事项(三)
AB测试注意事项(三)
经过以上的学习,只是掌握了AB测试中最为基本的部分,要想深入理解AB测试,还需要对其进行深层次理解,接下来就开始第二部分:
2、拓展AB测试
 第 2 部分:拓展AB测试
第 2 部分:拓展AB测试
在计划推进AB测试时,如果在同一个上有多个优化方案,如在设计登录界面的按钮颜色时,可以一次性测试多个颜色对用户的影响,此时需要推行的就是AB测试的升级版本——ABN测试了。
 ABN测试
ABN测试
在进行AB测试时,可能会有各种情况会对最终的结果产生影响,因此,可以使用AA测试,以及其升级版本——ANB测试方式进行推进,避免偶然因素对目标产生误差。
 ANB测试
ANB测试
既然AB测试能为产品的优化带来极大的益处,那么快速迭代就能帮助企业更快发展,对此,可以针对多个维度同时进行AB测试,这也就是为什么有些公司一年内能对同一款产品完成上千次AB测试。
什么,你没有感受到AB测试对你的影响,怎么可能这么多?那就对了,有些测验版本也不能保证有效,故此只有一小部分用户体验到了,绝大部分用户是不会知道的,作为用户的你就不会感受到了。
具体如何实施呢,看看下面的介绍:
 多维测试
多维测试
但是这样的测试有一个弊端,那就是每个测试群中的用户数量较少,不一定能反映真实用户情况,故此,需要进行改进:
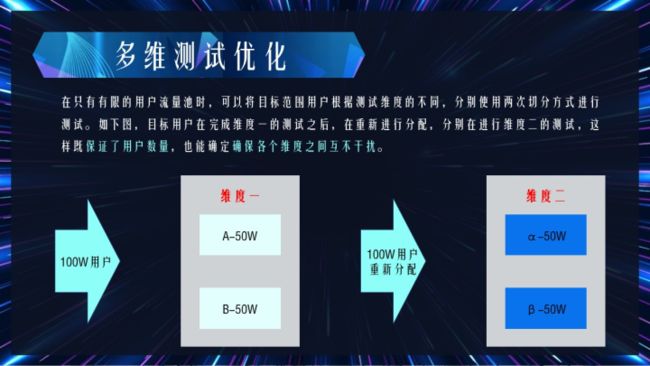 多维测试优化
多维测试优化
那么作为数据分析师,在AB测试中需要担任什么样的角色,以及在每一个环节中,需要完成哪些任务,注意哪些问题呢?
 任务与职责(数据分析师)
任务与职责(数据分析师)
 任务与职责 - 专题分析
任务与职责 - 专题分析
 任务与职责 - 优化方向
任务与职责 - 优化方向
 任务与职责 - 分析体系
任务与职责 - 分析体系
 任务与职责 - 流量分配
任务与职责 - 流量分配
 任务与职责 - 测试优化
任务与职责 - 测试优化
 任务与职责 - 分析总结
任务与职责 - 分析总结
 任务与职责 - 文件归档
任务与职责 - 文件归档
以上,我们对数据分析的内容已经了解的比较深入了,也明确了作为数据分析师在进行AB测试时需要完成哪些任务与要求,在本篇的最后,将会使用一个实际案例的数据带你认识具体需要如何操作。
一起走进第三部分:实战AB测试。
3、实战AB测试
本部分先是对整个实操过程进行了一次框架讲解,最后附所有代码脚本、讲解以及数据。
 第 3 部分:实战AB测试
第 3 部分:实战AB测试
开始实操之初,先对数据的商业背景做一个完整的认识:
 商业理解
商业理解
作为数据分析师,一定要认真理解数据情况:
 数据理解
数据理解
面对本次数据,经过查验,需要作出以下优化:
 数据整理
数据整理
结合上述对数据的理解,以及对业务环境的熟悉,制定了以下数据分析步骤:
 数据分析
数据分析
在完成数据分析之后,最终得到了以下结论:
 形成结论
形成结论
最终经过分析,建议延长本次AB测试的时间,继续观察再确定结论。
4、代码实操
接下来是代码实操部分:
1)导入相关Python库
import numpy as np
import pandas as pd
2)导入数据并查看前5行
# 导入数据
df = pd.read_csv('ab_data.csv')
# 查看数据前5行
df.head()
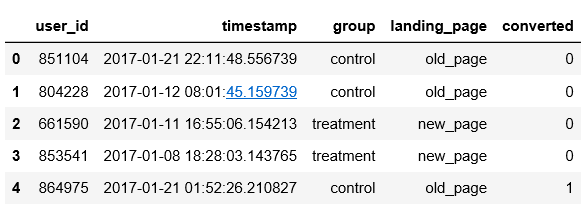 前5行数据情况
前5行数据情况
3)查看数据形状
# 查看数据大小
df.shape
(294478, 5)
4)查看数据信息
# 查看数据信息
df.info()
 数据信息
数据信息
5)查看缺失值
# 查看缺失值
df.isnull().sum() # 没有缺失值
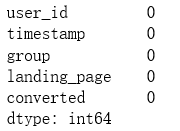 缺失值信息
缺失值信息
6)基于业务理解校验数据
# 查看对于treatment和 new_page,或者control和old_page会出现不一致的行
df.loc[(df['group'] == 'treatment') != (df['landing_page'] == 'new_page')].count()
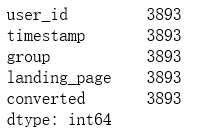 无效数据
无效数据
7)剔除无效数据
# 去除无效数据,并将其赋值到df2中
df2 = df.loc[~((df['group'] == 'treatment') != (df['landing_page'] == 'new_page'))]
df2.count()
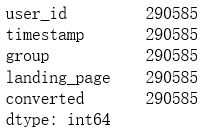 保留有效数据
保留有效数据
8)校验重复值
# 查看是否有重复数据
df2.user_id.nunique() # 从用户ID确定有重复数据
# 查看重复的用户ID,以及相关信息
df2[df2['user_id'].duplicated(keep=False)] # 重复的用户ID为773192
 重复用户数据
重复用户数据
9)删除重复值,并查看数据情况
# 删除重复值
df2 = df2.drop_duplicates(subset=['user_id'], keep='first') # 保留重复项中的第一项
# 查看df2的形状
print(df2.shape)
# 查看df2中是否还有重复值
print(df2.user_id.nunique())
(290584, 5)
290584
10)计算用户转化率
# 整体转化率
df2['converted'].mean() #整体转化率为11.96%
0.11959708724499628
# 新页面转化率
df2[df2['landing_page'] == 'new_page']['converted'].mean() # 新页面的转化率为11.88%
0.11880806551510564
# 旧页面转化率
df2[df2['landing_page'] == 'old_page']['converted'].mean() # 旧页面的转化率为12.04%
0.1203863045004612
# 用户收到新页面的概率
df2[df2['landing_page'] == 'new_page'].shape[0] / df2.shape[0] # 用户收到新页面的概率为50%
0.5000619442226688
通过以上数据可以看出:整体页面转化率为11.96%,新页面转化率为11.88%,旧页面的转化率为12.04%,用户收到新旧页面的概率参半。
看似使用旧页面效果更好,是本身就是如此,还是由于一些随机因素导致的呢?对此需要进行显著性检验:
11)设计AB测试
由于目标是新页面转化率高于旧页面转化率,设计原假设和备择假设如下:
H0: P_new - P_old <= 0
H1: P_new - P_old > 0
# 新页面转化率
p_new = df2[df2['landing_page'] == 'new_page']['converted'].mean()
p_new
0.11880806551510564
# 旧页面转化率
p_old = df2[df2['landing_page'] == 'old_page']['converted'].mean()
p_old
0.1203863045004612
# 新页面数量
n_new = df2[df2['landing_page'] == 'new_page'].shape[0]
n_new
145310
# 旧页面数量
n_old = df2[df2['landing_page'] == 'old_page'].shape[0]
n_old
145274
# 引入SciPy库
from scipy.stats import norm
# 计算显著性检验Z值
z_score = (p_old - p_new) / np.sqrt(p_old * (1 - p_old) / n_old + p_new * (1 - p_new) / n_new)
z_score
1.3109271488301917
# 计算置信区间
norm.ppf(1-0.05)
1.6448536269514722
结论:由于z_score=1.31小于norm.ppf(1-0.05)=1.64,落在95%的置信区间中,所以无法拒绝原假设,建议延长测试时间,继续观测情况。
以上,是对AB测试做完了一次完整的梳理,欢迎大家继续关注。
如果对本文源数据、源码感兴趣,网页打开链接直接下载
https://alltodata.cowtransfer.com/s/b6eddb13746642





后台回复「进群」,加入读者交流群~
点击红字「积分」,可了解积分规则~
