Prometheus - 时间序列数据库
1.Prometheus 简介
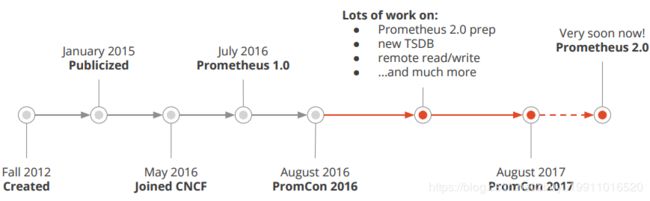
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,能更好地与容器平台、云平台配合。
官网地址:https://prometheus.io/
作为新一代的监控框架,Prometheus 具有以下特点:
- 开源监控工具
- 所有的 metrics 都可以设置任意的多维标签,使用 pull 模式采集数据
- 社区生态丰富,多语言,各种 exporters
- 高效:单机性能强,数以百万的监控指标,每秒处理数十万的数据点
- 可以通过服务发现或者静态配置去获取监控的 targets。
- 强大的查询语言PromQL,有多种可视化图形界面。
需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。
指标(metric):metric name和描述当前样本特征的labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value): 一个folat64的浮点型数据表示当前样本的值。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
http_request_total{status="200", method="POST"}@1434417560938 => 4748
http_request_total{status="200", method="POST"}@1434417561287 => 4785
2.Prometheus 组成及架构
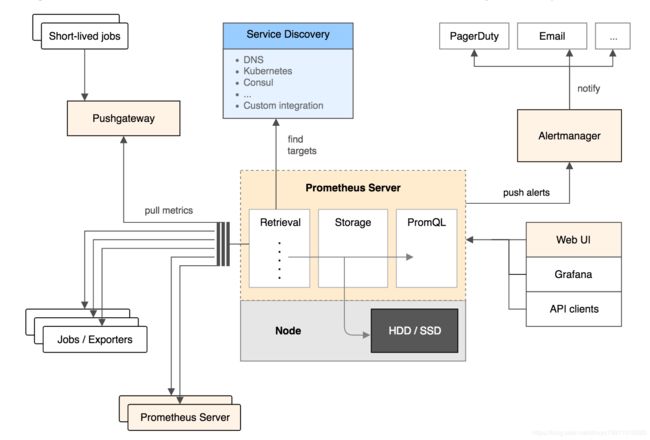
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
一些其他的工具。
3.四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
- Counter:一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
- Gauge:一种常规的 metric,仪表盘,典型的应用如:温度、内存使用率,运行的 goroutines 的个数,可以任意加减。
- Histogram:可以理解为柱状图,典型的应用如:请求持续时间,响应大小,可以对观察结果采样,分组及统计。
- Summary:类似于 Histogram, 典型的应用如:请求持续时间,响应大小,提供观测值的 count 和 sum 功能,提供百分位的功能,即可以按百分比划分跟踪结果。
prometheus主要用于监控 web 应用—需要暴露 metrics 端点,也可以监控服务器—需要安装node_exporter,node_exporter 暴露 metrics 给 prometheus,其中 metrics 包括:cpu 的负载,内存的使用情况,网络等。
4.监控的4个黄金指标
Four Golden Signals是Google针对大量分布式监控的经验总结,4个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。主要关注与以下四种类型的指标:延迟,通讯量,错误以及饱和度:
-
延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。 例如在数据库或者其他关键祸端服务异常触发HTTP 500的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提倡“快速失败”,开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。 -
通讯量:监控当前系统的流量,用于衡量服务的容量需求。
流量对于不同类型的系统而言可能代表不同的含义。例如,在HTTP REST API中, 流量通常是每秒HTTP请求数; -
错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
对于失败而言有些是显式的(比如, HTTP 500错误),而有些是隐式(比如,HTTP响应200,单实际业务流程依然是失败的)。对于一些显式的错误如HTTP 500可以通过在负载均衡器(如Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。 -
饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。 例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘I/O,那就主要观测磁盘I/O的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在4个小时候就满了”。 -
RED方法
RED方法是Weave Cloud在基于Google的“4个黄金指标”的原则下结合Prometheus以及Kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。主要关注以下三种关键指标:
(请求)速率:服务每秒接收的请求数。
(请求)错误:每秒失败的请求数。
(请求)耗时:每个请求的耗时。
在“4大黄金信号”的原则下,RED方法可以有效的帮助用户衡量云原生以及微服务应用下的用户体验问题
5.安装-入门实践
下载地址:https://prometheus.io/download/
- node_exporter: node_exporter-0.17.0.linux-amd64.tar.gz
- prometheus:prometheus-2.7.2.windows-amd64.tar.gz
安装前需要了解 prometheus 架构图中的内容,prometheus server 通过主动拉取 应用或服务器暴露的 metrics 端点的数据存放到 storage 中,多种可视化图形界面(webui、grafana),同时提供告警组件alertmanager,通过告警组件与email、微信等集成,把告警信息发送给运维人员
安装 node_exporter ,我有台 centos 云服务器,先来个监控服务器的,需要在服务器上安装 node_exporter,请下载下载对应的 node_exporter
1.把 node_exporter-0.17.0.linux-amd64.tar.gz 文件上传到服务器
2.解压,tar -xvzf node_exporter-0.17.0.linux-amd64.tar.gz , cd node_exporter-0.17.0.linux-amd64
并把node_exporter复制到 /usr/local/bin/ 中
3.输入 nohup ./node_exporter & 启动
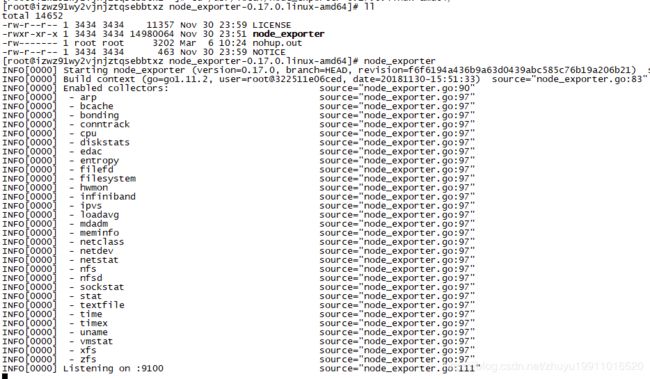
看到上面的界面说明 node_exporter 启动成功,可以在浏览器上访问 http://xxx:9100 端口,点击界面上的 metrics 链接查看数据
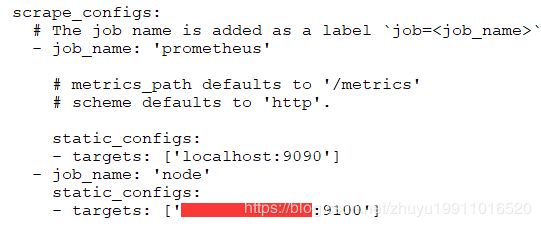
安装 prometheus,本地电脑是windows版本的, 解压后进入prometheus目录,在里面创建data文件夹,然后打开 prometheus.yml文件,添加job静态配置,地址指向上面云服务器上安装的 node_exporter 暴露的 metrics 端口
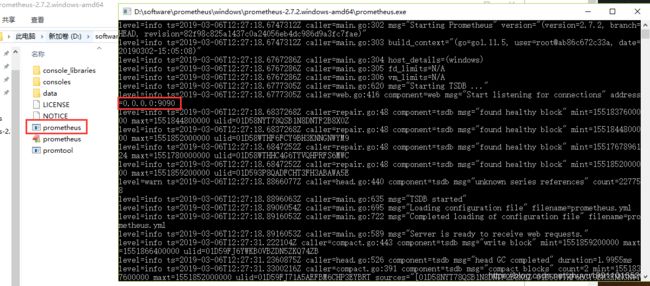
双击 prometheus.exe ,看到下面的界面说明 prometheus server 启动成功
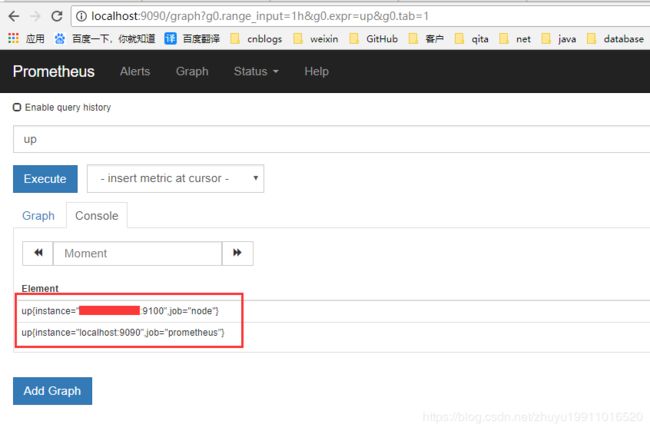
访问 localhost:9090 ,在文本框中输入 up,查询 prometheus 监控的服务那些状态是正常的,下面出现了两个 instance,一个是 prometheus自己,还一个是我的云服务器
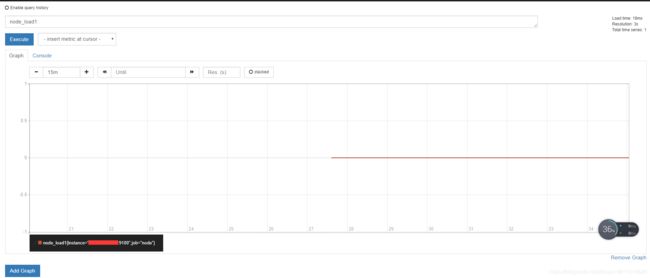
使用关键字 node_load1 可以查询出Prometheus采集到的主机负载的样本数据
基础的监控已经搭建好了,只是缺少可视化图形界面,下图是与grafana集成后,显示我的云服务器的各项CPU、内存、磁盘等各项指标情况,下面讲解怎么与grafana集成
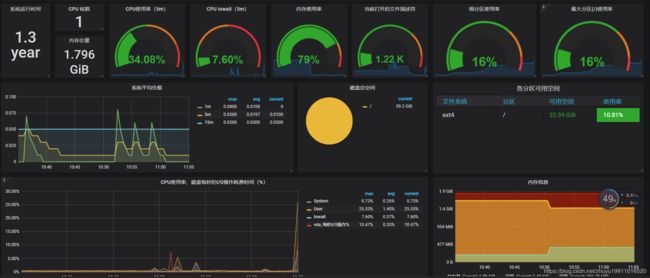
通过 grafana ,可以让 prometheus 采集到的数据近乎实时的显示出来,像天猫、京东双十一电子大屏显示当天每分钟的成交量与成交额