网站/APP 流量分析、用户访问分析
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
- 数据仓库设计
- 网站/APP 流量分析、用户访问分析
- 网站/APP 流量分析、点击流分析、用户访问分析
- 网站埋点+网站日志自定义采集系统+nginx的相关安装
2.本项目中数据仓库的设计(注:采用星型模型)
1.事实表设计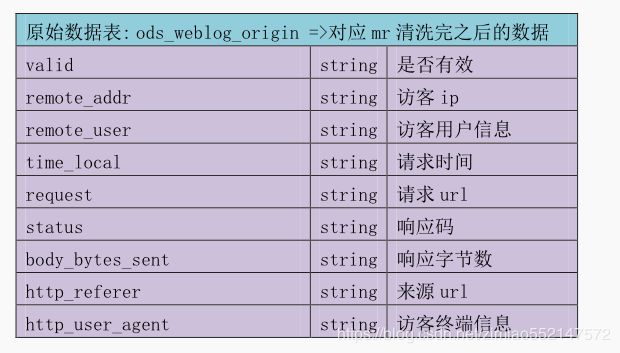

2.维度表设计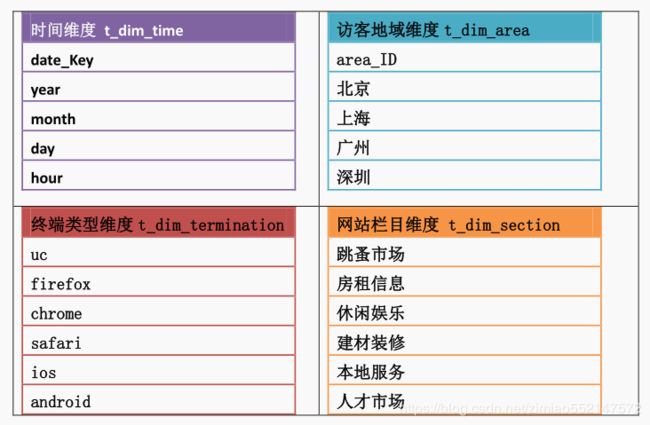
注意:
维度表的数据一般要结合业务情况自己写脚本按照规则生成,也可以使用工具生成,方便后续的关联分析。
比如一般会事前生成时间维度表中的数据,跨度从业务需要的日期到当前日期即可,具体根据你的分析粒度,
可以生成年、季、月、周、天、时等相关信息,用于分析。
3.模块开发----ETL
ETL 工作的实质就是从各个数据源提取数据,对数据进行转换,并最终加载填充数据到数据仓库维度建模后的表中。
只有当这些维度/事实表被填充好,ETL工作才算完成。
本项目的数据分析过程在 hadoop 集群上实现,主要应用 hive 数据仓库工具,因此,采集并经过预处理后的数据,需要加载到 hive 数据仓库中,以进行后续的分析过程。
1.创建 ODS 层数据表
1.原始日志数据表
1.drop table if exists ods_weblog_origin;
2.create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited fields terminated by '\001';
2.点击流模型 pageviews 模型表
1.drop table if exists ods_click_pageviews;
2.create table ods_click_pageviews(
session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited fields terminated by '\001';
3.点击流模型 visit 模型表
1.drop table if exist ods_click_stream_visit;
2.create table ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string)
row format delimited fields terminated by '\001';
2.导入 ODS 层数据
1.数据导入:load data inpath '/weblog/preprocessed/' overwrite into table ods_weblog_origin partition(datestr='20130918');
2.查看分区:show partitions ods_weblog_origin;
3.统计导入的数据总数:select count(*) from ods_weblog_origin;
4.点击流模型的两张表(pageviews、visit 模型表)数据导入操作同上。
5.注:生产环境中应该将数据 load 命令,写在脚本中,然后配置在 azkaban 中定时运行,注意运行的时间点,应该在预处理数据完成之后。
3.生成 ODS 层明细宽表
1.需求实现
整个数据分析的过程是按照数据仓库的层次分层进行的,总体来说,是从 ODS 原始数据中整理出一些中间表
(比如,为后续分析方便,将原始数据中的时间、url 等非结构化数据作结构化抽取,将各种字段信息进行细化,形成明细表),
然后再在中间表的基础之上统计出各种指标数据。
2.ETL 实现:建明细表 ods_weblog_detail
1.drop table ods_weblog_detail;
2.create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, # 来源 IP
remote_user string, # 用户标识
time_local string, # 访问完整时间
daystr string, # 访问日期
timestr string, # 访问时间
month string, # 访问月
day string, # 访问日
hour string, # 访问时
request string, # 请求的 url
status string, # 响应码
body_bytes_sent string, # 传输字节数
http_referer string, # 来源 url
ref_host string, # 来源的 host
ref_path string, # 来源的路径
ref_query string, # 来源参数 query
ref_query_id string, # 来源参数 query 的值
http_user_agent string) # 客户终端标识
partitioned by(datestr string);
3.通过查询插入数据到明细宽表 ods_weblog_detail 中
1.抽取 refer_url 到中间表 t_ods_tmp_referurl,也就是将来访 url 分离出 host、path、query、query id。
2.drop table if exists t_ods_tmp_referurl;
3.create table t_ods_tmp_referurl as
SELECT a.*,b.*
FROM ods_weblog_origin a
LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b
as host, path, query, query_id;
4.LATERAL VIEW 用于和 split, Explode 等 UDTF 一起使用,它能够将一列数据拆成 多行数据。
5.UDTF(User-Defined Table-Generating Functions) :
用来解决 输入一行 输出多行(On-to-many maping) 的需求。
Explode 也是拆列函数,比如 Explode (ARRAY) ,array 中的每个元素生成一行。
4.抽取转换 time_local 字段到中间表明细表 t_ods_tmp_detail
1.drop table if exists t_ods_tmp_detail;
2.create table t_ods_tmp_detail as
select b.*,substring(time_local,0,10) as daystr,
substring(time_local,12) as tmstr,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,11,3) as hour
from t_ods_tmp_referurl b;
5.以上语句可以合成一个总的语句
insert into table shizhan.ods_weblog_detail partition(datestr='2013-09-18')
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from (SELECT a.valid,a.remote_addr,a.remote_user,a.time_local, a.request,a.status,a.body_bytes_sent,a.http_referer,
a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM shizhan.ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST',
'PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c;
4.模块开发----统计分析
数据仓库建设好以后,用户就可以编写 Hive SQL 语句对其进行访问并对其中数据进行分析。
在实际生产中,究竟需要哪些统计指标通常由数据需求相关部门人员提出,而且会不断有新的统计需求产生,以下为网站流量分析中的一些典型指标示例。
注:每一种统计指标都可以跟各维度表进行钻取。
1.流量分析
1.多维度统计 PV 总量
1.按时间维度
1.计算每小时 pvs,注意 gruop by 语法
select count(*) as pvs,month,day,hour from ods_weblog_detail group by month,day,hour;
2.方式一:直接在 ods_weblog_detail 单表上进行查询
1.计算该处理批次(一天)中的各小时 pvs
1.drop table dw_pvs_everyhour_oneday;
2.create table dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint)
partitioned by(datestr string);
3.insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')
select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a
where a.datestr='20130918' group by a.month,a.day,a.hour;
2.计算每天的 pvs
1.drop table dw_pvs_everyday;
2.create table dw_pvs_everyday(pvs bigint,month string,day string);
3.insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a
group by a.month,a.day;
3.方式二:与时间维表关联查询
1.维度:日
1.drop table dw_pvs_everyday;
2.create table dw_pvs_everyday(pvs bigint,month string,day string);
3.insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a
join ods_weblog_detail b
on a.month=b.month and a.day=b.day
group by a.month,a.day;
2.维度:月
1.drop table dw_pvs_everymonth;
2.create table dw_pvs_everymonth (pvs bigint,month string);
3.insert into table dw_pvs_everymonth
4.select count(*) as pvs,a.month from (select distinct month from t_dim_time) a
join ods_weblog_detail b on a.month=b.month group by a.month;
3.另外,也可以直接利用之前的计算结果。比如从之前算好的小时结果中统计每一天的
insert into table dw_pvs_everyday
select sum(pvs) as pvs,month,day from dw_pvs_everyhour_oneday group by month,day having day='18';
2.按终端维度
1.数据中能够反映出用户终端信息的字段是 http_user_agent。
2.User Agent 也简称 UA。
1.它是一个特殊字符串头,是一种向访问网站提供所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
2.例如:User-Agent,Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/58.0.3029.276 Safari/537.36
3.上述 UA 信息就可以提取出以下的信息:
chrome 58.0、浏览器 chrome、浏览器版本 58.0、系统平台 windows、浏览器内核 webkit
3.可以用下面的语句进行试探性统计,当然这样的准确度不是很高。
select distinct(http_user_agent) from ods_weblog_detail where http_user_agent like '%Chrome%' limit 200;
3.按栏目维度
网站栏目可以理解为网站中内容相关的主题集中。
体现在域名上来看就是不同的栏目会有不同的二级目录。
比如某网站网址为 www.xxxx.cn,旗下栏目可以通过如下方式访问:
栏目维度:../job
栏目维度:../news
栏目维度:../sports
栏目维度:../technology
那么根据用户请求 url 就可以解析出访问栏目,然后按照栏目进行统计分析。
4.按 referer 维度
1.统计每小时各来访 url 产生的 pv 量
1.drop table dw_pvs_referer_everyhour;
2.create table dw_pvs_referer_everyhour(
referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint)
partitioned by(datestr string);
3.insert into table dw_pvs_referer_everyhour partition(datestr='20130918')
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
2.统计每小时各来访 host 的产生的 pv 数并排序
1.drop table dw_pvs_refererhost_everyhour;
2.create table dw_pvs_refererhost_everyhour(
ref_host string,month string,day string,hour string,ref_host_cnts bigint)
partitioned by(datestr string);
3.insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918')
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;
3.注:还可以按来源地域维度、访客终端维度等计算
2.人均浏览量
1.需求描述:统计今日所有来访者平均请求的页面数。
2.人均浏览量也称作人均浏览页数,该指标可以说明网站对用户的粘性。
人均页面浏览量表示用户某一时段平均浏览页面的次数。
计算方式:总页面请求数/去重总人数
remote_addr表示不同的用户。
可以先统计出不同 remote_addr 的 pv量, 然后累加(sum)所有 pv 作为总的页面请求数,再 count 所有 remote_addr 作为总的去重总人数。
3.总页面请求数/去重总人数
1.drop table dw_avgpv_user_everyday;
2.create table dw_avgpv_user_everyday(day string, avgpv string);
3.insert into table dw_avgpv_user_everyday
select '20130918',sum(b.pvs)/count(b.remote_addr) from
(select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20130918' group by remote_addr) b;
3.统计 pv 总量最大的来源 TOPN (分组 TOP)
1.需求描述:统计每小时各来访 host 的产生的 pvs 数最多的前 N 个(topN) 。
2.row_number()函数
1.语法:row_number() over (partition by xxx order by xxx) rank。
2.rank 为分组的别名,相当于新增一个字段为 rank。
3.partition by 用于分组,比方说依照 sex 字段分组
4.order by 用于分组内排序,比方说依照 sex 分组,组内按照 age 排序
5.排好序之后,为每个分组内每一条分组记录从 1 开始返回一个数字
6.取组内某个数据,可以使用 “where 表名.rank > x” 之类的语法去取
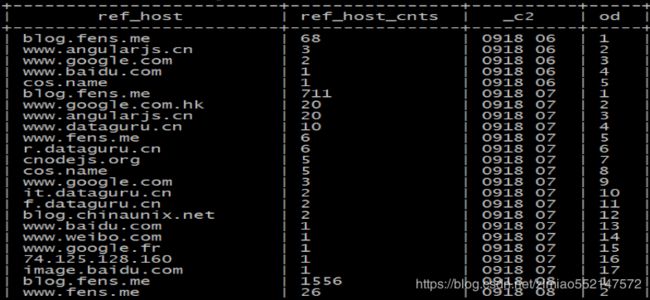
3.以下语句对每个小时内的来访 host 次数倒序排序(从大到小)标号:
select ref_host,ref_host_cnts,concat(month,day,hour),
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour;
4.效果如下:
2.受访分析(从页面的角度分析)
1.各页面访问统计
主要是针对数据中的 request 进行统计分析,比如各页面 PV ,各页面 UV 等。
以上指标无非就是根据页面的字段 group by。
例如:统计各页面 pv
select request as request,count(request) as request_counts from ods_weblog_detail
group by request having request is not null order by request_counts desc limit 20;
2.热门页面统计
统计每日最热门的页面 top10
1.drop table dw_hotpages_everyday;
2.create table dw_hotpages_everyday(day string,url string,pvs string);
3.insert into table dw_hotpages_everyday
select '20130918',a.request,a.request_counts from
(
select request as request,count(request) as request_counts from ods_weblog_detail where datestr='20130918'
group by request having request is not null
) a order by a.request_counts desc limit 10;
3.访客分析
1.独立访客
1.需求描述:按照时间维度,比如:小时来统计独立访客及其产生的 pv。
2.对于独立访客的识别,如果在原始日志中有用户标识,则根据用户标识即很好实现;
此处,由于原始日志中并没有用户标识,以访客 IP 来模拟,技术上是一样的,只是精确度相对较低。
3.时间维度:时
1.drop table dw_user_dstc_ip_h;
2.create table dw_user_dstc_ip_h(remote_addr string, pvs bigint, hour string);
3.insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day,hour),remote_addr;
4.在此结果表之上,可以进一步统计,如每小时独立访客总数:
select count(1) as dstc_ip_cnts,hour from dw_user_dstc_ip_h group by hour;
4.时间维度:日
select remote_addr,count(1) as counts,concat(month,day) as day
from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day),remote_addr;
5.时间维度:月
select remote_addr,count(1) as counts,month
from ods_weblog_detail
group by month,remote_addr;
4.每日新访客
1.需求:将每天的新访客统计出来。
2.实现思路:创建一个去重访客累积表,然后将每日访客对比累积表。
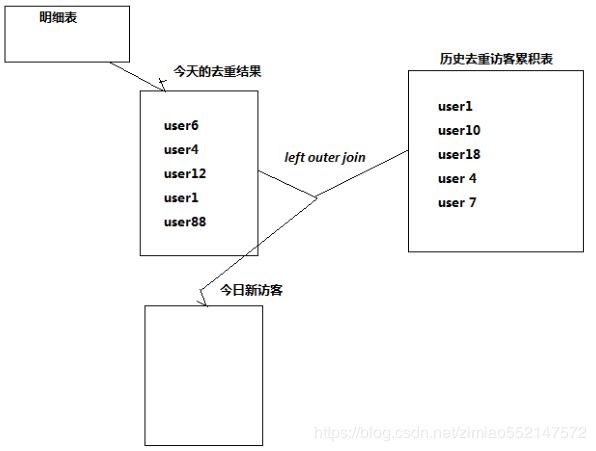
3.历日去重访客累积表
1.drop table dw_user_dsct_history;
2.create table dw_user_dsct_history(day string, ip string)
partitioned by(datestr string);
4.每日新访客表
1.drop table dw_user_new_d;
2.create table dw_user_new_d (day string, ip string)
partitioned by(datestr string);
5.每日新用户插入新访客表
1.insert into table dw_user_new_d partition(datestr='20130918')
select tmp.day as day,tmp.today_addr as new_ip
from(
select today.day as day,today.remote_addr as today_addr,old.ip as old_addr
from (
select distinct remote_addr as remote_addr,"20130918" as day
from ods_weblog_detail where datestr="20130918"
) today left outer join dw_user_dsct_history old on today.remote_addr=old.ip
) tmp
where tmp.old_addr is null;
6.每日新用户追加到累计表
insert into table dw_user_dsct_history partition(datestr='20130918')
select day,ip from dw_user_new_d where datestr='20130918';
7.验证查看:
select count(distinct remote_addr) from ods_weblog_detail;
select count(1) from dw_user_dsct_history where datestr='20130918';
select count(1) from dw_user_new_d where datestr='20130918';
8.注:还可以按来源地域维度、访客终端维度等计算
5.访客 Visit 分析(点击流模型)
1.回头/单次访客统计
1.需求:查询今日所有回头访客及其访问次数。
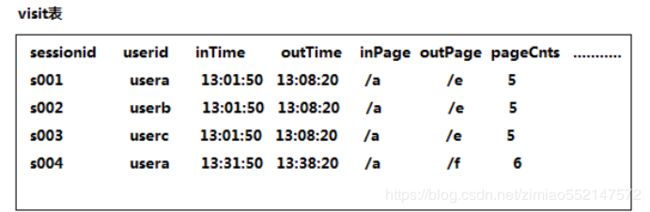
2.实现思路:上表中 “出现次数 > 1” 的访客,即回头访客;反之,则为单次访客。
1.drop table dw_user_returning;
2.create table dw_user_returning(day string, remote_addr string, acc_cnt string)
partitioned by (datestr string);
3.insert overwrite table dw_user_returning partition(datestr='20130918')
select tmp.day,tmp.remote_addr,tmp.acc_cnt
from (select '20130918' as day,remote_addr,count(session) as acc_cnt from ods_click_stream_visit group by remote_addr) tmp
where tmp.acc_cnt > 1;
2.人均访问频次
1.需求:统计出每天所有用户访问网站的平均次数(visit)
2.总 visit 数/去重总用户数
select sum(pagevisits)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918';
6.关键路径转化率分析(漏斗模型)
1.需求分析
转化:在一条指定的业务流程中,各个步骤的完成人数及相对上一个步骤的百分比。
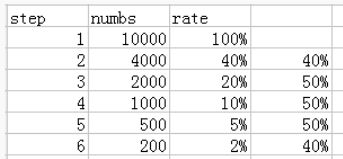
2.模型设计
定义好业务流程中的页面标识,下例中的步骤为:
Step1、 /item
Step2、 /category
Step3、 /index
Step4、 /order
3.开发实现
1.查询每一个步骤的总访问人数:查询每一步人数存入 dw_oute_numbs
1.create table dw_oute_numbs as
select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920' and request like '/item%'
union
select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920' and request like '/category%'
union
select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920' and request like '/order%'
union
select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920' and request like '/index%';
注:UNION 将多个 SELECT 语句的结果集合并为一个独立的结果集。
2.查询每一步骤相对于路径起点人数的比例
思路:级联查询,利用自 join
1.dw_oute_numbs 跟自己 join
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr;
2.每一步的人数/第一步的人数==每一步相对起点人数比例
select tmp.rnstep,tmp.rnnumbs/tmp.rrnumbs as ratio
from (
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr
) tmp where tmp.rrstep='step1';
3.查询每一步骤相对于上一步骤的漏出率:自 join 表过滤出每一步跟上一步的记录
1.select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr
where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1;
2.select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
from (
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr
) tmp where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
4.汇总以上两种指标
select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate
from (
select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate
from (
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr
) tmp where tmp.rrstep='step1'
)
abs left outer join
(
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate
from (
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn inner join dw_oute_numbs rr
) tmp where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1
) rel on abs.step=rel.step;
网站流量日志分析--模块开发--ETL--创建ODS层表
1.时间同步命令:ntpdate ntp6.aliyun.com
2.启动 mysql 版的 Hive,本地路径下启动hive
1.本地连接方式:
cd /root/hive/bin
./hive
2.外部Linux连接访问当前Linux下的hive:(注意使用外部连接方式时必须先启动hiveserver2服务器)
1.后台模式启动hiveserver2服务器:
cd /root/hive/bin
nohup ./hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
然后会返回hiveserver2服务器的进程号
2.外部Linux连接访问当前Linux下的hive
cd /root/hive/bin
./beeline -u jdbc:hive2://NODE1:10000 -n root
然后输入NODE1所在linux的用户名和密码
3.本地模式:
# 设置本地模式(仅需当前机器)执行查询语句,不设置的话则需要使用yarn集群(多台集群的机器)执行查询语句
# 本地模式只推荐在开发环境开启,以便提高查询效率,但在生产上线环境下应重新设置为使用yarm集群模式
set hive.exec.mode.local.auto=true;
4.创建数据库:
create database itheima;
use itheima;
5.创建表:
1.原始数据表:对应mr清洗完之后的数据,而不是原始日志数据
1.drop table if exists ods_weblog_origin;
2.create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited fields terminated by '\001';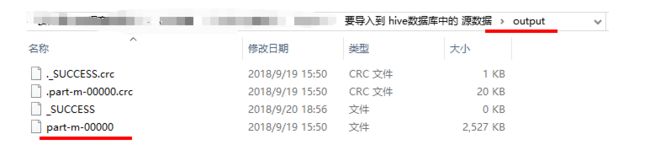

2.点击流pageview表
1.drop table if exists ods_click_pageviews;
2.create table ods_click_pageviews(
session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited fields terminated by '\001';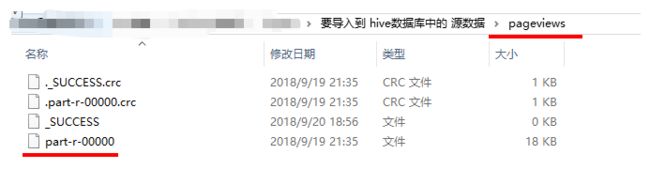
![]()
3.点击流visit表
1.drop table if exists ods_click_stream_visit;
2.create table ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string)
row format delimited fields terminated by '\001';
![]()
4.维度表示例:
1.drop table if exists t_dim_time;
2.create table t_dim_time(date_key int,year string,month string,day string,hour string) row format delimited fields terminated by ',';
5.show tables;
网站流量日志分析--模块开发--ETL--导入ODS层数据
1.hdfs中创建指定目录,准备用于存储数据文件
hdfs dfs -mkdir -p /weblog/preprocessed
hdfs dfs -mkdir -p /weblog/clickstream/pageviews
hdfs dfs -mkdir -p /weblog/clickstream/visits
hdfs dfs -mkdir -p /weblog/dim_time
2.浏览器查看hdfs文件系统:192.168.25.100:50070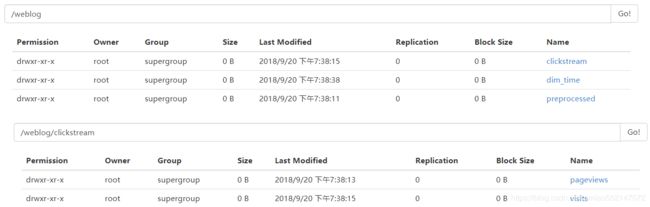
3.把要导入的数据文件先上传到指定位置
hdfs dfs -put /root/hivedata/weblog/output/part-m-00000 /weblog/preprocessed
hdfs dfs -put /root/hivedata/weblog/pageviews/part-r-00000 /weblog/clickstream/pageviews
hdfs dfs -put /root/hivedata/weblog/visitout/part-r-00000 /weblog/clickstream/visits
hdfs dfs -put /root/hivedata/weblog/dim_time_dat.txt /weblog/dim_time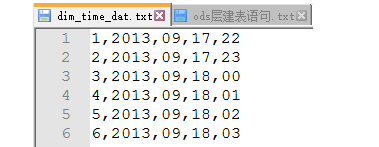
4.把hdfs文件系统路径下的数据文件导入到hive数据库表中:
1.把 清洗结果数据 导入到 源数据表ods_weblog_origin
load data inpath '/weblog/preprocessed/' overwrite into table ods_weblog_origin partition(datestr='20130918');
show partitions ods_weblog_origin; # 显示结果 datestr=20130918
select count(*) from ods_weblog_origin; # 显示结果 13770
2.把 点击流模型pageviews数据 导入到 ods_click_pageviews表
load data inpath '/weblog/clickstream/pageviews' overwrite into table ods_click_pageviews partition(datestr='20130918');
select count(*) from ods_click_pageviews; # 显示结果 76
3.把 点击流模型visit数据 导入到 ods_click_stream_visit表
load data inpath '/weblog/clickstream/visits' overwrite into table ods_click_stream_visit partition(datestr='20130918');
select count(*) from ods_click_stream_visit; # 显示结果 57
4.把 dim_time_dat.txt 导入到 时间维度表
load data inpath '/weblog/dim_time' overwrite into table t_dim_time;
select count(*) from t_dim_time; # 显示结果 29
网站流量日志分析--模块开发--ETL--ODS明细宽表
1.创建表明细宽表 ods_weblog_detail
1.drop table ods_weblog_detail;
2.create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源url
ref_host string, --来源的host
ref_path string, --来源的路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标识
)partitioned by(datestr string);
2.抽取refer_url到中间表 t_ods_tmp_referurl
1.drop table if exists t_ods_tmp_referurl;
2.create table t_ods_tmp_referurl as
SELECT a.*,b.*
FROM ods_weblog_origin a
LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id;
3.解析:
regexp_replace(字段名, "\"", ""):把双引号 替换为 空字符串
parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id'):将来访url值分离出四列值:host、path、query、query_id
3.创建中间表明细表 t_ods_tmp_detail,并且抽取转换time_local字段到中间表明细表 t_ods_tmp_detail
1.drop table if exists t_ods_tmp_detail;
2.create table t_ods_tmp_detail as
select b.*,substring(time_local,0,10) as daystr,
substring(time_local,12) as tmstr,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,11,3) as hour
From t_ods_tmp_referurl b;
4.把查询数据 插入到明细宽表ods_weblog_detail中
insert into table ods_weblog_detail partition(datestr='20130918')
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from
(SELECT a.valid,a.remote_addr,a.remote_user,a.time_local,
a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b
as ref_host, ref_path, ref_query, ref_query_id) c;
网站流量日志分析--模块开发--统计分析--时间&来访维度统计pvs
1.流量分析
1.计算每小时pvs,注意gruop by语句的语法
select count(*) as pvs,month,day,hour from ods_weblog_detail group by month,day,hour;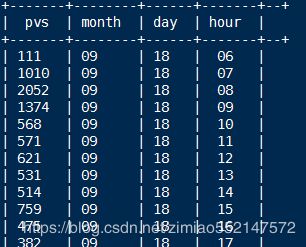
2.多维度统计PV总量
1.第一种方式:直接在ods_weblog_detail单表上进行查询
1.计算该处理批次(一天)中的各小时pvs
1.drop table dw_pvs_everyhour_oneday;
2.create table dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
3.insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')
select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a
2.计算每天的pvs
1.drop table dw_pvs_everyday;
2.create table dw_pvs_everyday(pvs bigint,month string,day string);
3.insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a
group by a.month,a.day;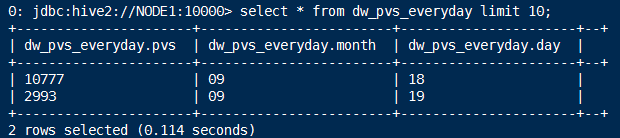
2.第二种方式:与时间维表关联查询
1.维度:日
1.drop table dw_pvs_everyday;
2.create table dw_pvs_everyday(pvs bigint,month string,day string);
3.insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a
join ods_weblog_detail b
on a.month=b.month and a.day=b.day
group by a.month,a.day;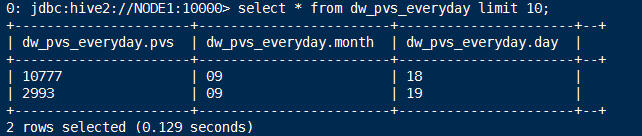
2.维度:月
1.drop table dw_pvs_everymonth;
2.create table dw_pvs_everymonth (pvs bigint,month string);
3.insert into table dw_pvs_everymonth
select count(*) as pvs,a.month from (select distinct month from t_dim_time) a
join ods_weblog_detail b on a.month=b.month group by a.month;
3.另外,也可以直接利用之前的计算结果。比如从之前算好的小时结果中统计每一天的
insert into table dw_pvs_everyday
select sum(pvs) as pvs,month,day from dw_pvs_everyhour_oneday group by month,day having day='18';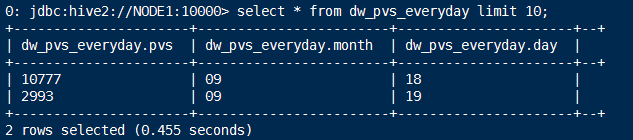
网站流量日志分析--模块开发--统计分析--了解其他维度&人均浏览量
1.按照来访维度统计pv
1.统计每小时各来访url产生的pv量,查询结果存入:( "dw_pvs_referer_everyhour" )
1.drop table dw_pvs_referer_everyhour;
2.create table dw_pvs_referer_everyhour(referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint) partitioned by(datestr string);
3.insert into table dw_pvs_referer_everyhour partition(datestr='20130918')
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
+-------------------------------------------------------------+----------------------------------------+---------------------------------+-------------------------------+--------------------------------+------------------------------------------+-----------------------------------+--+
| dw_pvs_referer_everyhour.referer_url | dw_pvs_referer_everyhour.referer_host | dw_pvs_referer_everyhour.month | dw_pvs_referer_everyhour.day | dw_pvs_referer_everyhour.hour | dw_pvs_referer_everyhour.pv_referer_cnt | dw_pvs_referer_everyhour.datestr |
+-------------------------------------------------------------+----------------------------------------+---------------------------------+-------------------------------+--------------------------------+------------------------------------------+-----------------------------------+--+
| "http://blog.fens.me/r-density/" | blog.fens.me | 09 | 19 | 00 | 26 | 20130918 |
| "http://blog.fens.me/r-json-rjson/" | blog.fens.me | 09 | 19 | 00 | 21 | 20130918 |
| "http://blog.fens.me/-pptp-client-ubuntu/" | blog.fens.me | 09 | 19 | 00 | 20 | 20130918 |
| "http://blog.fens.me/hadoop-mahout-roadmap/" | blog.fens.me | 09 | 19 | 00 | 20 | 20130918 |
| "http://blog.fens.me/hadoop-zookeeper-intro/" | blog.fens.me | 09 | 19 | 00 | 20 | 20130918 |
| "http://www.fens.me/" | www.fens.me | 09 | 19 | 00 | 12 | 20130918 |
| "http://h2w.iask.cn/jump.php?url=http%3A%2F%2Fwww.fens.me" | h2w.iask.cn | 09 | 19 | 00 | 5 | 20130918 |
| "https://www.google.com.hk/" | www.google.com.hk | 09 | 19 | 00 | 3 | 20130918 |
| "http://angularjs.cn/A0eQ" | angularjs.cn | 09 | 19 | 00 | 2 | 20130918 |
| "http://blog.fens.me/about/" | blog.fens.me | 09 | 19 | 00 | 2 | 20130918 |
+-------------------------------------------------------------+----------------------------------------+---------------------------------+-------------------------------+--------------------------------+------------------------------------------+-----------------------------------+--+
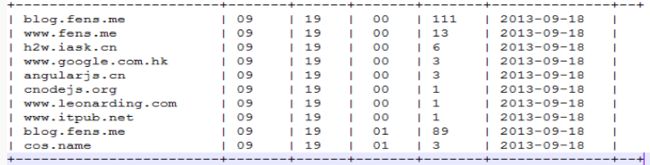
2.统计每小时各来访host的产生的pv数并排序
1.drop table dw_pvs_refererhost_everyhour;
2.create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
3.insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918')
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;
+----------------------------------------+-------------------------------------+-----------------------------------+------------------------------------+---------------------------------------------+---------------------------------------+--+
| dw_pvs_refererhost_everyhour.ref_host | dw_pvs_refererhost_everyhour.month | dw_pvs_refererhost_everyhour.day | dw_pvs_refererhost_everyhour.hour | dw_pvs_refererhost_everyhour.ref_host_cnts | dw_pvs_refererhost_everyhour.datestr |
+----------------------------------------+-------------------------------------+-----------------------------------+------------------------------------+---------------------------------------------+---------------------------------------+--+
| blog.fens.me | 09 | 19 | 00 | 111 | 20130918 |
| www.fens.me | 09 | 19 | 00 | 13 | 20130918 |
| h2w.iask.cn | 09 | 19 | 00 | 6 | 20130918 |
| www.google.com.hk | 09 | 19 | 00 | 3 | 20130918 |
| angularjs.cn | 09 | 19 | 00 | 3 | 20130918 |
| cnodejs.org | 09 | 19 | 00 | 1 | 20130918 |
| www.leonarding.com | 09 | 19 | 00 | 1 | 20130918 |
| www.itpub.net | 09 | 19 | 00 | 1 | 20130918 |
| blog.fens.me | 09 | 19 | 01 | 89 | 20130918 |
| cos.name | 09 | 19 | 01 | 3 | 20130918 |
+----------------------------------------+-------------------------------------+-----------------------------------+------------------------------------+---------------------------------------------+---------------------------------------+--+
网站流量日志分析--模块开发--统计分析--分组TopN(rowNumber)
1.统计pv总量最大的来源TOPN
1.需求:按照时间维度,统计一天内各小时产生最多pvs的来源topN
2.row_number函数
select ref_host,ref_host_cnts,concat(month,day,hour),
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour;
+-------------------------+----------------+----------+-----+--+
| ref_host | ref_host_cnts | _c2 | od |
+-------------------------+----------------+----------+-----+--+
| blog.fens.me | 68 | 0918 06 | 1 |
| www.angularjs.cn | 3 | 0918 06 | 2 |
| www.google.com | 2 | 0918 06 | 3 |
| www.baidu.com | 1 | 0918 06 | 4 |
| cos.name | 1 | 0918 06 | 5 |
| blog.fens.me | 711 | 0918 07 | 1 |
| www.google.com.hk | 20 | 0918 07 | 2 |
| www.angularjs.cn | 20 | 0918 07 | 3 |
| www.dataguru.cn | 10 | 0918 07 | 4 |
3.综上可以得出
1.drop table dw_pvs_refhost_topn_everyhour;
2.create table dw_pvs_refhost_topn_everyhour(
hour string,
toporder string,
ref_host string,
ref_host_cnts string
)partitioned by(datestr string);
3.insert into table dw_pvs_refhost_topn_everyhour partition(datestr='20130918')
select t.hour,t.od,t.ref_host,t.ref_host_cnts from
(select ref_host,ref_host_cnts,concat(month,day,hour) as hour,
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour) t where od<=3;
+-------------------------------------+-----------------------------------------+-----------------------------------------+----------------------------------------------+----------------------------------------+--+
| dw_pvs_refhost_topn_everyhour.hour | dw_pvs_refhost_topn_everyhour.toporder | dw_pvs_refhost_topn_everyhour.ref_host | dw_pvs_refhost_topn_everyhour.ref_host_cnts | dw_pvs_refhost_topn_everyhour.datestr |
+-------------------------------------+-----------------------------------------+-----------------------------------------+----------------------------------------------+----------------------------------------+--+
| 0918 06 | 1 | blog.fens.me | 68 | 20130918 |
| 0918 06 | 2 | www.angularjs.cn | 3 | 20130918 |
| 0918 06 | 3 | www.google.com | 2 | 20130918 |
| 0918 07 | 1 | blog.fens.me | 711 | 20130918 |
| 0918 07 | 2 | www.google.com.hk | 20 | 20130918 |
| 0918 07 | 3 | www.angularjs.cn | 20 | 20130918 |
| 0918 08 | 1 | blog.fens.me | 1556 | 20130918 |
| 0918 08 | 2 | www.fens.me | 26 | 20130918 |
| 0918 08 | 3 | www.baidu.com | 15 | 20130918 |
| 0918 09 | 1 | blog.fens.me | 1047 | 20130918 |
+-------------------------------------+-----------------------------------------+-----------------------------------------+----------------------------------------------+----------------------------------------+--+
2.人均浏览页数
1.需求描述:统计今日所有来访者平均请求的页面数。
2.总页面请求数/去重总人数
1.drop table dw_avgpv_user_everyday;
2.create table dw_avgpv_user_everyday(
day string,
avgpv string);
3.insert into table dw_avgpv_user_everyday
select '20130918',sum(b.pvs)/count(b.remote_addr) from
(select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20130918' group by remote_addr) b;

各页面访问统计
各页面PV
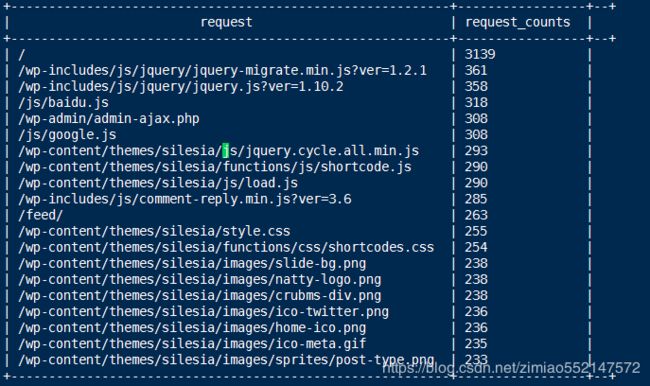
select request as request,count(request) as request_counts from
ods_weblog_detail group by request having request is not null order by request_counts desc limit 20;
网站流量日志分析--模块开发--受访分析--热门页面
热门页面统计
统计每日最热门的页面top10
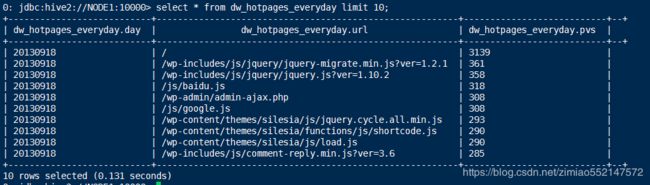
1.drop table dw_hotpages_everyday;
2.create table dw_hotpages_everyday(day string,url string,pvs string);
3.insert into table dw_hotpages_everyday
select '20130918',a.request,a.request_counts from
(select request as request,count(request) as request_counts from ods_weblog_detail where datestr='20130918' group by request having request is not null) a
order by a.request_counts desc limit 10;
网站流量日志分析--模块开发--访客开发--独立访客&新访客
1.独立访客
1.需求:按照时间维度来统计独立访客及其产生的pv量
2.时间维度:时
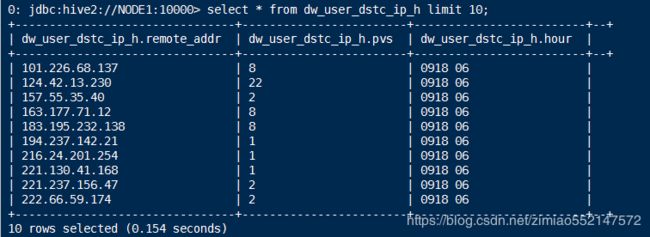
1.drop table dw_user_dstc_ip_h;
2.create table dw_user_dstc_ip_h(
remote_addr string,
pvs bigint,
hour string);
3.insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour
from ods_weblog_detail
where datestr='20130918'
group by concat(month,day,hour),remote_addr;
3.在上述基础之上,可以继续分析,比如每小时独立访客总数
select count(1) as dstc_ip_cnts,hour from dw_user_dstc_ip_h group by hour;
+---------------+----------+--+
| dstc_ip_cnts | hour |
+---------------+----------+--+
| 19 | 0918 06 |
| 98 | 0918 07 |
| 129 | 0918 08 |
| 149 | 0918 09 |
| 107 | 0918 10 |
| 54 | 0918 11 |
| 52 | 0918 12 |
| 71 | 0918 13 |
| 62 | 0918 14 |
| 72 | 0918 15 |
| 93 | 0918 16 |
| 55 | 0918 17 |
4.时间维度:日
select remote_addr,count(1) as counts,concat(month,day) as day
from ods_weblog_detail
where datestr='20130918'
group by concat(month,day),remote_addr;
+------------------+---------+-------+--+
| remote_addr | counts | day |
+------------------+---------+-------+--+
| 1.162.203.134 | 1 | 0918 |
| 1.202.186.37 | 28 | 0918 |
| 1.202.222.147 | 1 | 0918 |
| 1.202.70.78 | 1 | 0918 |
| 1.206.126.5 | 1 | 0918 |
| 1.34.23.44 | 1 | 0918 |
| 1.80.249.223 | 5 | 0918 |
| 1.82.139.173 | 24 | 0918 |
| 101.226.102.97 | 1 | 0918 |
| 101.226.166.214 | 1 | 0918 |
| 101.226.166.216 | 1 | 0918 |
| 101.226.166.222 | 1 | 0918 |
| 101.226.166.235 | 2 | 0918 |
| 101.226.166.236 | 1 | 0918 |
| 101.226.166.237 | 2 | 0918 |
5.时间维度: 月
select remote_addr,count(1) as counts,month
from ods_weblog_detail
group by month,remote_addr;
+------------------+---------+--------+--+
| remote_addr | counts | month |
+------------------+---------+--------+--+
| 1.162.203.134 | 1 | 09 |
| 1.202.186.37 | 35 | 09 |
| 1.202.222.147 | 1 | 09 |
| 1.202.70.78 | 1 | 09 |
| 1.206.126.5 | 34 | 09 |
| 1.34.23.44 | 1 | 09 |
| 1.80.245.79 | 1 | 09 |
| 1.80.249.223 | 5 | 09 |
| 1.82.139.173 | 24 | 09 |
| 101.226.102.97 | 1 | 09 |
| 101.226.166.214 | 1 | 09 |
2.每日新访客
1.需求:将每天的新访客统计出来。
2.历日去重访客累积表
1.drop table dw_user_dsct_history;
2.create table dw_user_dsct_history(
day string,
ip string
) partitioned by(datestr string);
3.每日新访客表
1.drop table dw_user_new_d;
2.create table dw_user_new_d (
day string,
ip string
) partitioned by(datestr string);
4.每日新用户插入新访客表
insert into table dw_user_new_d partition(datestr='20130918')
select tmp.day as day,tmp.today_addr as new_ip from
(
select today.day as day,today.remote_addr as today_addr,old.ip as old_addr
from
(select distinct remote_addr as remote_addr,"20130918" as day from ods_weblog_detail where datestr="20130918") today
left outer join
dw_user_dsct_history old
on today.remote_addr=old.ip
) tmp where tmp.old_addr is null;
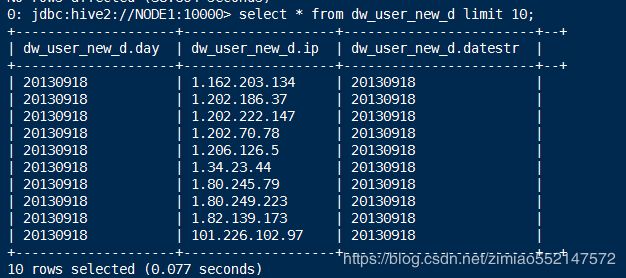
5.每日新用户追加到累计表
insert into table dw_user_dsct_history partition(datestr='20130918')
select day,ip from dw_user_new_d where datestr='20130918';
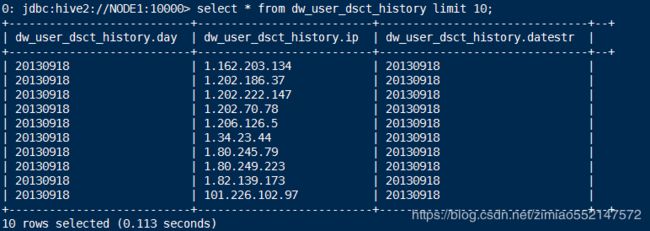
6.验证:
select count(distinct remote_addr) from ods_weblog_detail; # 结果值显示为 1027
select count(1) from dw_user_dsct_history where datestr='20130918'; # 结果值显示为 1027
select count(1) from dw_user_new_d where datestr='20130918'; # 结果值显示为 1027
网站流量日志分析--模块开发--访客开发--回头客&人均频次(点击流模型)
1.回头/单次访客统计
1.drop table dw_user_returning;
2.create table dw_user_returning(
day string,
remote_addr string,
acc_cnt string)
partitioned by (datestr string);
3.insert overwrite table dw_user_returning partition(datestr='20130918')
select tmp.day,tmp.remote_addr,tmp.acc_cnt
from (select '20130918' as day,remote_addr,count(session) as acc_cnt from ods_click_stream_visit group by remote_addr) tmp where tmp.acc_cnt>1;
2.人均访问频次
select sum(pagevisits)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918'; # 结果值显示为 1.4339622641509433
网站流量日志分析--模块开发--转化分析--漏斗模型转化率分步实现
1.漏斗模型原始数据click-part-r-00000
1.hdfs dfs -put /root/hivedata/weblog/click-part-r-00000 /weblog/clickstream/pageviews
2.load data inpath '/weblog/clickstream/pageviews/click-part-r-00000' overwrite into table ods_click_pageviews partition(datestr='20130920');
3.select * from ods_click_pageviews where datestr='20130920' limit 10;
+---------------------------------------+----------------------------------+----------------------------------+---------------------------------+------------------------------+---------------------------------+------------------------------------+-----------------------------------+---------------------------------------------------------+--------------------------------------+-----------------------------+------------------------------+--+
| ods_click_pageviews.session | ods_click_pageviews.remote_addr | ods_click_pageviews.remote_user | ods_click_pageviews.time_local | ods_click_pageviews.request | ods_click_pageviews.visit_step | ods_click_pageviews.page_staylong | ods_click_pageviews.http_referer | ods_click_pageviews.http_user_agent | ods_click_pageviews.body_bytes_sent | ods_click_pageviews.status | ods_click_pageviews.datestr |
+---------------------------------------+----------------------------------+----------------------------------+---------------------------------+------------------------------+---------------------------------+------------------------------------+-----------------------------------+---------------------------------------------------------+--------------------------------------+-----------------------------+------------------------------+--+
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:15:42 | /item/HZxEY8vF | 1 | 340 | /item/qaLW7pa5 | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:21:22 | /item/IyA5hVop | 2 | 1 | /item/MQtiwwhj | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:21:23 | /item/RDqibwBo | 3 | 44 | /item/RCbNqxIy | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:22:07 | /item/IzrJixZc | 4 | 101 | /item/RCbNqxIy | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:23:48 | /item/yrZqXxfN | 5 | 19 | /item/1Wvc1NeH | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:24:07 | /item/hWBn8VCg | 6 | 442 | /item/LwOziljH | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:31:29 | /item/1nQESbrT | 7 | 348 | /item/GFDdR8SR | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:37:17 | /item/c | 8 | 2 | /category/d | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:37:19 | /item/a | 9 | 11 | /category/c | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
| 47826dd6-be71-42df-96b2-14ff65425975 | | - | 2013-09-20 00:37:30 | /item/X2b5exuV | 10 | 348 | /item/N2Pos96N | Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 | 1800 | 200 | 20130920 |
+---------------------------------------+----------------------------------+----------------------------------+---------------------------------+------------------------------+---------------------------------+------------------------------------+-----------------------------------+---------------------------------------------------------+--------------------------------------+-----------------------------+------------------------------+--+
2.查询每一个步骤的总访问人数
create table dw_oute_numbs as
select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/item%'
union
select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/category%'
union
select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/order%'
union
select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/index%';
3.查询每一步骤相对于路径起点人数的比例
1.级联查询,自己跟自己join
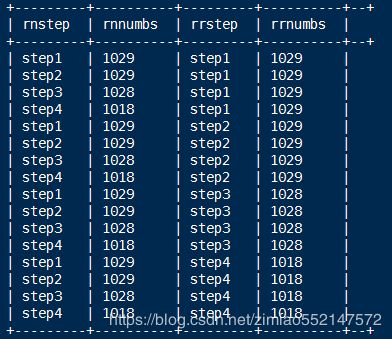
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr;
自join后结果如下图所示:
+---------+----------+---------+----------+--+
| rnstep | rnnumbs | rrstep | rrnumbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step1 | 1029 |
| step2 | 1029 | step1 | 1029 |
| step3 | 1028 | step1 | 1029 |
| step4 | 1018 | step1 | 1029 |
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step2 | 1029 |
| step3 | 1028 | step2 | 1029 |
| step4 | 1018 | step2 | 1029 |
| step1 | 1029 | step3 | 1028 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step3 | 1028 |
| step4 | 1018 | step3 | 1028 |
| step1 | 1029 | step4 | 1018 |
| step2 | 1029 | step4 | 1018 |
| step3 | 1028 | step4 | 1018 |
| step4 | 1018 | step4 | 1018 |
+---------+----------+---------+----------+--+
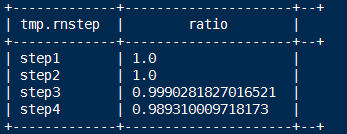
2.每一步的人数/第一步的人数==每一步相对起点人数比例
select tmp.rnstep,tmp.rnnumbs/tmp.rrnumbs as ratio
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
) tmp where tmp.rrstep='step1';
4.查询每一步骤相对于上一步骤的漏出率
1.首先通过自join表过滤出每一步跟上一步的记录
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1;
+---------+----------+---------+----------+--+
| rnstep | rnnumbs | rrstep | rrnumbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step4 | 1018 |
+---------+----------+---------+----------+--+
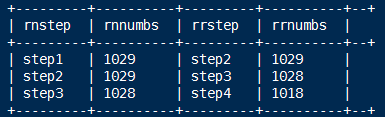
2.然后就可以非常简单的计算出每一步相对上一步的漏出率
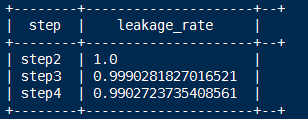
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
) tmp where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
5.汇总以上两种指标
select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate
from
(
select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
) tmp where tmp.rrstep='step1'
) abs
left outer join
(
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
) tmp where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1
) rel on abs.step=rel.step;

网站流量日志分析--模块开发--转化分析--级联求和(累加)
1.创建表
create table t_access_times(username string,month string,salary int)
row format delimited fields terminated by ',';
2.导入数据
1.hdfs dfs -put /root/hivedata/weblog/t_access_times.dat /weblog
2.load data inpath '/weblog/t_access_times.dat' overwrite into table t_access_times;
3.select * from t_access_times limit 10;

3.第一步:先求个用户的月总金额
select username,month,sum(salary) as salary from t_access_times group by username,month;
+-----------+----------+---------+--+
| username | month | salary |
+-----------+----------+---------+--+
| A | 2015-01 | 33 |
| A | 2015-02 | 10 |
| B | 2015-01 | 30 |
| B | 2015-02 | 15 |
+-----------+----------+---------+--+
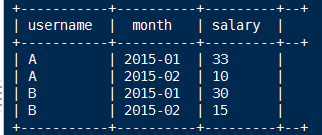
4.第二步:将月总金额表 自己连接 自己连接
select A.*,B.* FROM
(select username,month,sum(salary) as salary from t_access_times group by username,month) A
inner join
(select username,month,sum(salary) as salary from t_access_times group by username,month) B
on A.username=B.username
where B.month <= A.month;
+-------------+----------+-----------+-------------+----------+-----------+--+
| a.username | a.month | a.salary | b.username | b.month | b.salary |
+-------------+----------+-----------+-------------+----------+-----------+--+
| A | 2015-01 | 33 | A | 2015-01 | 33 |
| A | 2015-01 | 33 | A | 2015-02 | 10 |
| A | 2015-02 | 10 | A | 2015-01 | 33 |
| A | 2015-02 | 10 | A | 2015-02 | 10 |
| B | 2015-01 | 30 | B | 2015-01 | 30 |
| B | 2015-01 | 30 | B | 2015-02 | 15 |
| B | 2015-02 | 15 | B | 2015-01 | 30 |
| B | 2015-02 | 15 | B | 2015-02 | 15 |
+-------------+----------+-----------+-------------+----------+-----------+--+
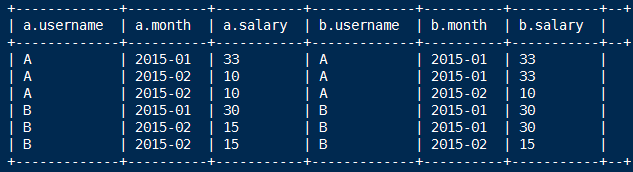
5.第三步:从上一步的结果中
进行分组查询,分组的字段是a.username a.month
求月累计值:将b.month <= a.month的所有b.salary求和即可
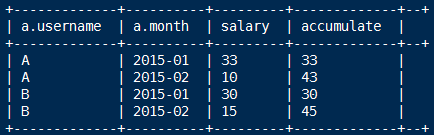
select A.username,A.month,max(A.salary) as salary,sum(B.salary) as accumulate
from
(select username,month,sum(salary) as salary from t_access_times group by username,month) A
inner join
(select username,month,sum(salary) as salary from t_access_times group by username,month) B
on A.username=B.username
where B.month <= A.month
group by A.username,A.month
order by A.username,A.month;