使用docker-compose搭建hadoop伪分布式,并用springboot进行读写访问
前言
- 本人初学Hadoop,在不懂得什么是完全分布式,什么是伪分布式,以及hdfs的具体架构得情况下,就盲目的跟着网上的教程搭建hadoop集群.最后结果是,环境搭起来了,springboot客户端却无法访问,然后反反复复重装hadoop环境,却不懂得问题所在.最后重新学习hadoop原理,才发现了突破口.
- 这篇文章的内容经过实践,是可以成功运行并访问的.
- docker的宿主机是阿里云的linux centos系统
- 遇到的问题是,springboot可以访问namenode,但是无法真正的上传文件,只能在namenode创建目录(后面会有解决办法)
- 如果你不适用springboot进行访问也没事,解决办法一样的
文章目录:
预备知识
docker-compose编写
springboot访问
遇到的问题
解决办法
总结经验
预备知识
在开始搭环境之前,我们先看看什么是伪分布式,什么是完全分布式
1.单机(非分布式)模式
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试
2.伪分布式运行模式
-
这种模式也是在一台单机上运行,但用不同端口模仿分布式运行中的各类结点: (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode)
-
从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
开启多个进程模拟完全分布式 -
如果用docker进行部署hadoop伪分布式集群环境,docker上有一个专门的伪分布式镜像,如下:(可根据几个镜像写一个docker-compose,进行伪分布式部署)
![]()
3.完全分布式模式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
如果要用docker进行部署,基本思路:(只是一个基本思路)
- 在docker中创建centos容器
- 在该容器中创建hadoop
- 配置hadoop
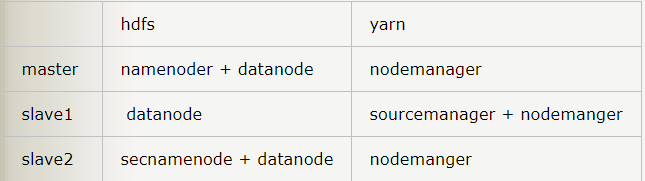
- 将该centos容器制作成镜像,由此创造出三个centos容器,一主二辅
- 规划好哪个容器上有namenode,datanode,resource Manager…如下:
知道了伪分布式和完全分布式的区别,接下来我们看看hdfs的读写流程
详情请学习这篇中的hdfs模块
看完之后,你应该清楚了,namenode只是一个目录,客户端和namenode创建连接的时候,namenode返回给客户端的是datanode的地址,准确的来说,是datanode的内网ip, 这也是后面用springboot无法访问hdfs文件系统的原因.不急,我们先把环境搭起来,再说怎么解决
docker-compose编写
在Linux虚拟机上新建一个文件夹hadoop
创建docker-compose 和hadoop.env文件,
创建data文件夹
在data文件夹中创建三个文件夹
docker-compose :
version: "2"
services:
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
hostname: namenode
container_name: namenode
volumes:
- ./data/namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- "50070:50070"
- "8020:8020"
- "50470:50470"
resourcemanager:
image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
hostname: resourcemanager
container_name: resourcemanager
depends_on:
- "namenode"
links:
- "namenode"
ports:
- "58088:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
hostname: historyserver
container_name: historyserver
volumes:
- ./data/historyserver:/hadoop/yarn/timeline
depends_on:
- "namenode"
links:
- "namenode"
ports:
- "58188:8188"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
hostname: nodemanager1
container_name: nodemanager1
depends_on:
- "namenode"
- "resourcemanager"
links:
- "namenode"
- "resourcemanager"
ports:
- "58042:8042"
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
hostname: datanode
container_name: datanode
depends_on:
- "namenode"
links:
- "namenode"
volumes:
- ./data/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
ports:
- "50010:50010"
- "50075:50075"
- "50475:50475"
- "50020:50020"
hadoop.env:
这里解释一下,这个文件相当于hadoop的配置文件,只是放在一个文件中进行配置
如果你还不懂hadoop的配置文件有哪些,请先看这篇文章中的Hadoop配置文件模块
我在这个配置文件中,进行了这样的设置:
HDFS_CONF_dfs_client_use_datanode_hostname=true
HDFS_CONF_dfs_datanode_use_datanode_hostname=true
意思是修改了默认的ip内网访问,改为主机名访问.为什么这样改呢?请继续往下看
下面是配置的对应关系:
- /etc/hadoop/core-site.xml ----- CORE_CONF
- /etc/hadoop/hdfs-site.xml HDFS_CONF
- /etc/hadoop/yarn-site.xml YARN_CONF
- /etc/hadoop/httpfs-site.xml HTTPFS_CONF
- /etc/hadoop/kms-site.xml KMS_CONF
- /etc/hadoop/mapred-site.xml MAPRED_CONF
CORE_CONF_fs_defaultFS=hdfs://namenode:8020
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_client_use_datanode_hostname=true
HDFS_CONF_dfs_datanode_use_datanode_hostname=true
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource___tracker_address=resourcemanager:8031
在hadoop目录下运行,
docker-compose up -id
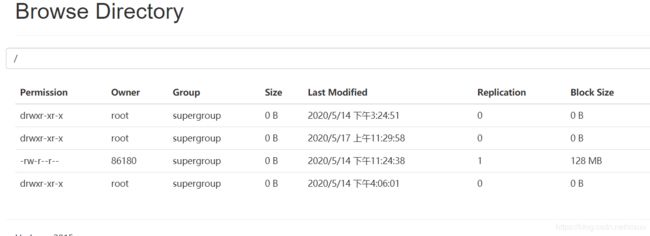
不出意外的话,访问你的主机ip+50070就能访问:
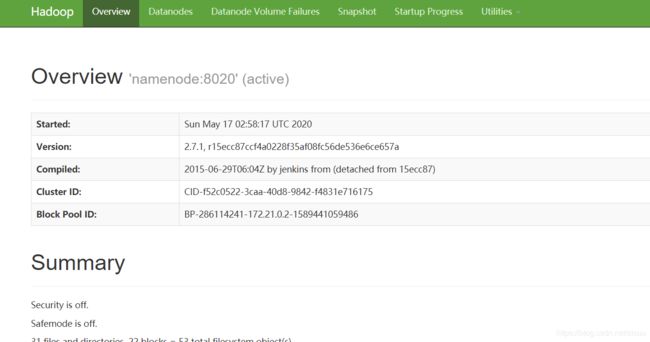
点击Utilities->brose the file system,可以浏览文件目录
springboot访问hadoop
pom.xml:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn</artifactId>
<version>2.7.1</version>
</dependency>
目录:
HadoopConfig:
@Configuration
public class HadoopConfig {
@Bean("fileSystem")
public FileSystem createFs(){
//读取配置文件
org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();
conf.set("dfs.replication", "1");
conf.set("dfs.client.use.datanode.hostname", "true");
System.setProperty("HADOOP_USER_NAME","root");
FileSystem fs = null;
try {
URI uri = new URI("hdfs://121.199.16.65:8020/");
fs = FileSystem.get(uri,conf);
} catch (Exception e) {
e.printStackTrace();
}
return fs;
}
}
HadoopTemplate
这里PostConstruct会先创建一个名为test的目录
@Service
@ConditionalOnBean(FileSystem.class)
public class HadoopTemplate {
@Autowired
private FileSystem fileSystem;
private String nameSpace="/test";
@PostConstruct
public void init(){
existDir(nameSpace,true);
}
public void uploadFile(String srcFile){
copyFileToHDFS(false,true,srcFile,nameSpace);
}
public void uploadFile(String srcFile,String destPath){
copyFileToHDFS(false,true,srcFile,destPath);
}
public void delFile(String fileName){
rmdir(nameSpace,fileName) ;
}
public void delDir(String path){
nameSpace = nameSpace + "/" +path;
rmdir(path,null) ;
}
public void download(String fileName,String savePath){
getFile(nameSpace+"/"+fileName,savePath);
}
/**
* 创建目录
* @param filePath
* @param create
* @return
*/
public boolean existDir(String filePath, boolean create){
boolean flag = false;
if(StringUtils.isEmpty(filePath)){
throw new IllegalArgumentException("filePath不能为空");
}
try{
Path path = new Path(filePath);
if (create){
if (!fileSystem.exists(path)){
fileSystem.mkdirs(path);
}
}
if (fileSystem.isDirectory(path)){
flag = true;
}
}catch (Exception e){
e.printStackTrace();
}
return flag;
}
/**
* 文件上传至 HDFS
* @param delSrc 指是否删除源文件,true为删除,默认为false
* @param overwrite
* @param srcFile 源文件,上传文件路径
* @param destPath hdfs的目的路径
*/
public void copyFileToHDFS(boolean delSrc, boolean overwrite,String srcFile,String destPath) {
// 源文件路径是Linux下的路径,如果在 windows 下测试,需要改写为Windows下的路径,比如D://hadoop/djt/weibo.txt
Path srcPath = new Path(srcFile);
// 目的路径
Path dstPath = new Path(destPath);
// 实现文件上传
try {
// 获取FileSystem对象
fileSystem.copyFromLocalFile(srcPath, dstPath);
//fileSystem.copyFromLocalFile(delSrc,overwrite,srcPath, dstPath);
//释放资源
// fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除文件或者文件目录
*
* @param path
*/
public void rmdir(String path,String fileName) {
try {
// 返回FileSystem对象
if(org.junit.platform.commons.util.StringUtils.isNotBlank(fileName)){
path = path + "/" +fileName;
}
// 删除文件或者文件目录 delete(Path f) 此方法已经弃用
fileSystem.delete(new Path(path),true);
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
}
/**
* 从 HDFS 下载文件
*
* @param hdfsFile
* @param destPath 文件下载后,存放地址
*/
public void getFile(String hdfsFile,String destPath) {
// 源文件路径
Path hdfsPath = new Path(hdfsFile);
Path dstPath = new Path(destPath);
try {
// 下载hdfs上的文件
fileSystem.copyToLocalFile(hdfsPath, dstPath);
// 释放资源
// fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
test:
@RestController
public class test {
@Autowired
HadoopTemplate template;
@GetMapping(value = "/test")
public String test(){
template.copyFileToHDFS(true,false,"D:\\Amaven\\test.txt","/test");
return "success";
}
}
遇到的问题
- 这个时候你可能会高高兴兴的用postMan进行测试,发现报了下面这个错误:
File /test/test.txt could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
但是你到回到前面访问过的那个50070web页面,发现目录里是有text.txt的,但是大小却为0

- 亦或者,你尝试着在50070web界面下载文件,却告诉你无法连接
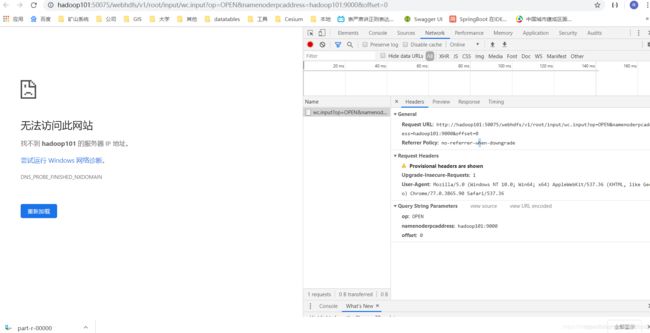
原因分析:
我们知道,客户端对Hdfs文件系统访问的大概流程是:
- 客户端通过公网ip+端口与namenode进行通信
- namenode返回datanode的地址,注意是hdfs文件系统的内网地址!!!
- 客户端根据地址去和datanode进行连接
但是,我们是在自己的电脑去访问虚拟机,用的是公网的地址,这样当然是无法访问hdfs的内网地址,也无法和datanode建立正常的输送连接,这也是为什么namenode上有目录,但是大小却为0的原因,也是为什么web界面无法下载文件的原因
所以,我们要去想办法让namenode不要返回datanode的内网地址,而是公网的地址,这样我们才能访问和连接
解决办法:
回顾上面的hadoop.env配置文件,有以下配置,将默认的内网ip访问,改为主机名访问
HDFS_CONF_dfs_datanode_use_datanode_hostname=true
再看dockerFile文件,datanode模块下的配置,指定了datanode的主机名为datanode,映射了宿主机的端口
datanode:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
hostname: datanode
container_name: datanode
depends_on:
- "namenode"
links:
- "namenode"
volumes:
- ./data/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
ports:
- "50010:50010"
- "50075:50075"
- "50475:50475"
- "50020:50020"
再看看springboot的HadoopConfig中的一行代码,设置了namenode返回的是datanode的主机名,而不是内网ip
conf.set(“dfs.client.use.datanode.hostname”, “true”);
ok,我们来撸一撸思路,现在已经配置了hdfs以主机名的方式进行互相访问,设置了datanode的主机名叫datanode,并且namenode返回的是datanode的主机名,现在该做什么?
没错,就是在我们自己的电脑上的/etc/hosts文件中,加一个linux公网ip和datanode的主机名(datanode)的映射:

你的虚拟机公网ip datanode
121.199.16.xx datanode
这样,当我们根据namenode返回的datanode的主机名,并通过映射关系,以公网ip+端口去访问datanode时,也就成功了

总结经验
- 在学习之前,一定要先理解原理再去跟着教程做,如果不懂得hdfs的读写流程,就不懂到底是和datanode连接错误,还是和namenode连接错误,不懂为什么可以创建目录,但是size=0.
- 本人也正是因为太心急,没有理解清楚原理,导致吃了大亏,卡在这个地方好几天,但是实际上,理解清楚原理,可能只需要两个小时