(2)Hadoop核心-java代码对MapReduce的操作
上一篇文件介绍了java代码怎么操作hdfs文件的,hdfs理念“就是一切皆文件”,我们现在搞定了怎么使用java上传下载等操作了接下来就要处理文件了,hadoop的mapreduce模块。
一、Hadoop Map/Reduce框架
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(job configuration)。然后,Hadoop的 job client提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给job-client。
注:以上Hadoop Map/Reduce摘自hadoop官方介绍,地址:http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html
二、环境准备
1.已经搭建好的linux虚拟机,地址为192.168.2.2
2.IDEA 开发编辑器,springboot项目
3.下载一个部小说(本文使用著名小说:三国演义 sgyy.txt,文件网上随便下载的可能不是全集)
4.上一篇中的项目基础,代码地址:代码地址
三、开发编码
1.启动hdfs服务
使用xshell连接之前搭建的虚拟机,并启动hdfs服务
cd /usr/local/hadoop/hadoop-3.1.1
sbin/start-all.sh

2.上传文件到hdfs
在上一篇文章的基础上上传三国演义(sgyy.txt)文件到java目录,用作读取的文件,上传成功后我们打开hdfs文件管理系统查看。

3.编写WordCount程序,计算出指定数据集中指定单词出现的次数
我们后面会使用到分词器,所以需要先添加一个jar包
cn.bestwu
ik-analyzers
5.1.0
mapReduce的工作原理简单说就是map负责将文件安装用户指定规则拆分成key,value格式的数据,reduce负责将拆成的数据进行统计并输出到另外一个文件中。
现在写新建一个 WordCountMap 类用来接收文件,这里使用到了分词器,因为默认map读取文件是按照行读取的,也就是key是一行的内容,value为数字1,使用分词器后会将行内容拆分成我们常用的词语,比如中国会拆分成 <中,1><国,1><中国,1>
这种才是符合我们的要求的。我们拆分的是三国演义,会把sgyy.txt 中出现的文字统计一遍,下图是统计后的结果,统计前单词都是一个一个的,reduce负责将key相同的单词累加起来并输出到文件。

import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.*;
import java.util.StringTokenizer;
/**
* 类或方法的功能描述 :统计单个字符出现的次数
*
* @date: 2018-12-05 15:37
*/
public class WordCountMap extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// // 防止中文乱码
String line = new String(value.getBytes(), 0, value.getLength(), "GBK");
// // 未使用分词器,分隔文件行默认为空格,也就是一行的内容作为key,value就是数量1即<行内容,1>
// StringTokenizer itr = new StringTokenizer(line);
// while (itr.hasMoreTokens()) {
// word.set(itr.nextToken());
// context.write(word, one);
// }
// 使用分词器,分隔文件行内容根据常用的短语分隔,比如我们,被分隔成 <我,1>,<们,1><我们,1>
byte[] btValue = line.getBytes();
InputStream inputStream = new ByteArrayInputStream(btValue);
Reader reader = new InputStreamReader(inputStream);
IKSegmenter ikSegmenter = new IKSegmenter(reader, true);
Lexeme lexeme;
while ((lexeme = ikSegmenter.next()) != null) {
word.set(lexeme.getLexemeText());
context.write(word, one);
}
}
} 接下来再新建一个 WordCountReduce 类用来统计map中切分的单词,这里我们统计三国演义中曹操和孙权出现的次数并输出到控制台。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 类或方法的功能描述 : 统计单个字符出现的次数
*
* @date: 2018-12-05 18:29
*/
public class WordCountReduce extends Reducer {
private IntWritable result = new IntWritable();
private String text = "孙权";
private int textSum = 0;
private List textList = null;
public WordCountReduce() {
textList = new ArrayList<>();
textList.add("曹操");
textList.add("孙权");
}
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
String keyStr = key.toString();
// 未使用分词器,需要根据map传过来的行内容检索并累加
// boolean isHas = keyStr.contains(text);
// if (isHas) {
// textSum++;
// System.out.println("============ " + text + " 统计分词为: " + textSum + " ============");
// }
// 使用分词器,内容已经被统计好了,直接输出即可
if (textList.contains(keyStr)) {
System.out.println("============ " + keyStr + " 统计分词为: " + sum + " ============");
}
}
} 新建一个 ReduceJobsUtils 类用来配置hadoop的运行环境,跟上一篇的 HdfsUtils 类似,这里用到的是 getWordCountJobsConf 方法。
import com.sunvalley.hadoop.reduce.mapper.WeatherMap;
import com.sunvalley.hadoop.reduce.mapper.WordCount;
import com.sunvalley.hadoop.reduce.mapper.WordCountMap;
import com.sunvalley.hadoop.reduce.reducer.WeatherReduce;
import com.sunvalley.hadoop.reduce.reducer.WordCountReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.IOException;
/**
* 类或方法的功能描述 : Map/Reduce工具类
*
* @date: 2018-12-04 14:16
*/
@Component
public class ReduceJobsUtils {
@Value("${hdfs.path}")
private String path;
private static String hdfsPath;
/**
* 获取HDFS配置信息
* @return
*/
public static Configuration getConfiguration() {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", hdfsPath);
configuration.set("mapred.job.tracker", hdfsPath);
return configuration;
}
/**
* 获取单词统计的配置信息
* @param jobName
* @return
*/
public static void getWordCountJobsConf(String jobName, String inputPath, String outputPath) throws IOException , ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration(getConfiguration());
Job job = Job.getInstance(conf, jobName);
job.setMapperClass(WordCountMap.class);
job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.waitForCompletion(true);
}
/**
* 单词统计
* @param jobName
* @return
* @throws IOException
* @throws ClassNotFoundException
* @throws InterruptedException
*/
public static void wordCount(String jobName, String inputPath, String outputPath) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration(getConfiguration());
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.waitForCompletion(true);
// System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* 获取单词一年最高气温计算配置
* @param jobName
* @return
*/
public static JobConf getWeatherJobsConf(String jobName) {
JobConf jobConf = new JobConf(getConfiguration());
jobConf.setJobName(jobName);
jobConf.setOutputKeyClass(Text.class);
jobConf.setOutputValueClass(LongWritable.class);
jobConf.setMapperClass(WeatherMap.class);
jobConf.setCombinerClass(WeatherReduce.class);
jobConf.setReducerClass(WeatherReduce.class);
jobConf.setInputFormat(TextInputFormat.class);
jobConf.setOutputFormat(TextOutputFormat.class);
return jobConf;
}
@PostConstruct
public void getPath() {
hdfsPath = this.path;
}
public static String getHdfsPath() {
return hdfsPath;
}
} 因为我使用的是RPC的方式调用mapReduce方法,使用postman发送请求,所以我们再新建一个 MapReduceService 和 MapReduceController 类。MapReduceService 中的wordCount方法中我们默认了输出目录为/output + jobName
import com.sunvalley.hadoop.util.HdfsUtil;
import com.sunvalley.hadoop.util.ReduceJobsUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.springframework.stereotype.Service;
/**
* 类或方法的功能描述 : 单词统计
*
* @date: 2018-12-05 19:02
*/
@Service
public class MapReduceService {
// 默认reduce输出目录
private static final String OUTPUT_PATH = "/output";
/**
* 单词统计,统计某个单词出现的次数
* @param jobName
* @param inputPath
* @throws Exception
*/
public void wordCount(String jobName, String inputPath) throws Exception {
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return;
}
// 输出目录 = output/当前Job,如果输出路径存在则删除,保证每次都是最新的
String outputPath = OUTPUT_PATH + "/" + jobName;
if (HdfsUtil.existFile(outputPath)) {
HdfsUtil.deleteFile(outputPath);
}
ReduceJobsUtils.getWordCountJobsConf(jobName, inputPath, outputPath);
}
/**
* 单词统计,统计所有分词出现的次数
* @param jobName
* @param inputPath
* @throws Exception
*/
public void newWordCount(String jobName, String inputPath) throws Exception {
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return;
}
// 输出目录 = output/当前Job,如果输出路径存在则删除,保证每次都是最新的
String outputPath = OUTPUT_PATH + "/" + jobName;
if (HdfsUtil.existFile(outputPath)) {
HdfsUtil.deleteFile(outputPath);
}
ReduceJobsUtils.wordCount(jobName, inputPath, outputPath);
}
/**
* 一年最高气温统计
* @param jobName
* @param inputPath
* @throws Exception
*/
public void weather(String jobName, String inputPath) throws Exception {
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return;
}
// 输出目录 = output/当前Job
String outputPath = OUTPUT_PATH + "/" + jobName;
if (HdfsUtil.existFile(outputPath)) {
HdfsUtil.deleteFile(outputPath);
}
JobConf jobConf = ReduceJobsUtils.getWeatherJobsConf(jobName);
FileInputFormat.setInputPaths(jobConf, new Path(inputPath));
FileOutputFormat.setOutputPath(jobConf, new Path(outputPath));
JobClient.runJob(jobConf);
}
} import com.sunvalley.hadoop.VO.BaseReturnVO;
import com.sunvalley.hadoop.reduce.service.MapReduceService;
import com.sunvalley.hadoop.util.HdfsUtil;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* 类或方法的功能描述 :TODO
* @date: 2018-12-05 19:10
*/
@RestController
@RequestMapping("/hadoop/reduce")
public class MapReduceController {
@Autowired
MapReduceService mapReduceService;
/**
* 单词统计
* @param jobName
* @param inputPath
* @return
*/
@PostMapping("/wordCount")
public BaseReturnVO wordCount(@RequestParam("jobName") String jobName, @RequestParam("inputPath") String inputPath) throws Exception{
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return new BaseReturnVO("请求参数为空");
}
mapReduceService.wordCount(jobName, inputPath);
return new BaseReturnVO("单词统计成功");
}
/**
* 单词统计
* @param jobName
* @param inputPath
* @return
* @throws Exception
*/
@PostMapping("/newWordCount")
public BaseReturnVO newWordCount(@RequestParam("jobName") String jobName, @RequestParam("inputPath") String inputPath) throws Exception{
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return new BaseReturnVO("请求参数为空");
}
mapReduceService.newWordCount(jobName, inputPath);
return new BaseReturnVO("单词统计成功");
}
/**
* 一年最高气温统计
* @param jobName
* @param inputPath
* @return
*/
@PostMapping("/weather")
public BaseReturnVO weather(@RequestParam("jobName") String jobName, @RequestParam("inputPath") String inputPath) throws Exception{
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return new BaseReturnVO("请求参数为空");
}
mapReduceService.weather(jobName, inputPath);
return new BaseReturnVO("温度统计成功");
}
} 好了,到此代码就已经全部写完了,接下来我们启动项目,使用postman调用一下
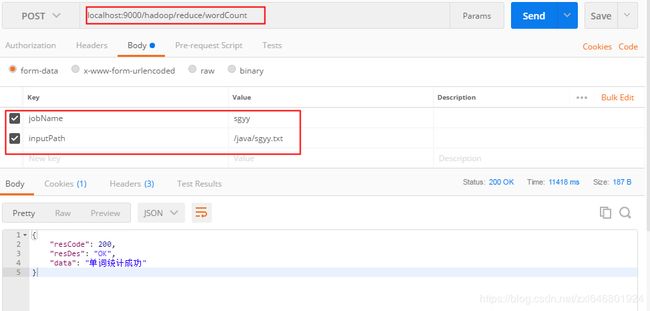
统计成功后我们查看控制台输出,我们可以看到sgyy.txt文件中曹操出现 913次,孙权出现 316次

reduce结果输出到文件,我统一将输出的目录设置为了 /output/xxx,xxx为reduce的jobName
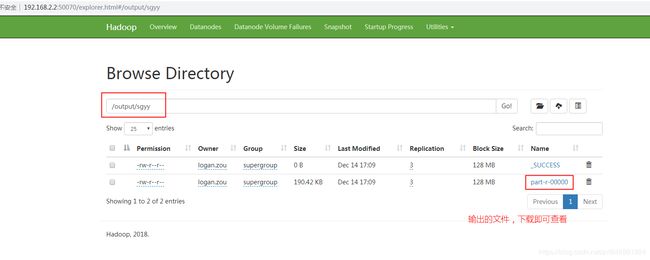
使用postman下载输出文件

我们把输出文件下载到了D盘,现在打开文件内容,我们可以清楚的看到三国演义中每个单词出现的次数分别是多少
