国税总局发票查验平台验证码识别方案,识别率达98%
全国增值税发票查验平台验证码
7.17 更新 (必读)
被迫日更营业,不好意思了,质疑我另有所图可以,可是不能质疑我的技术啊,
专票查询要输入金额(带小数点),校验码是6位,这不是常识吗? 居然还有人跑来问我为什么核验结果不一致。100元和100.80元能一样吗,0.8元就不是钱了吗?
之前验证码也是,居然有不少人截屏传了一张 [230x75] 的图过来,测完气乎乎的说我骗人,识别率根本就是0,我也是服气,都不看文章的吗???

以至于最终被迫妥协限制了输入 [90x35] 尺寸,除了人工打码平台没人会去识别截图的。
拜托了各位老铁们,好好看看文章吧,我没有写废话的习惯。我本着钓鱼的目的写的接口,接口各项指标都是和描述一致的,任何测评数据都是丝毫不掺水分的。
7.16 更新(关于发票查验服务本身)
验证码识别率是不需要更高了,我看有人找我了解发票查验这块,也顺带给个测试好了,目前支持全发票种类,你们看到的没错,是全发票种类,市面上的API接口也不一定能支持,其中包括(凑字数):增值税专用发票、增值税专用发票带清单、货物运输业增值税专用发票、增值税普通发票、增值税电子专用发票、增值税电子普通发票、增值税普通发票(卷票)、通行费xxx增值税电子普通发票、二手车销售统一发票。
恕我直言,就算是专门做查验服务的企业也不一定有我们业余开发的专业,不信的尽管来对比测试hhhh。
查验服务测试接口:
| 请求地址 | Content-Type | 参数形式 | 请求方法 |
|---|---|---|---|
| http://106.53.31.110:8080/check?fpdm=3100171320&fphm=79262007&date=20170620&code=184553&channel=yd | url | JSON | GET |
具体参数:
| 参数名 | 必选 | 类型 | 说明 |
|---|---|---|---|
| fpdm | Yes | String | 发票代码 |
| fphm | Yes | String | 发票号码 |
| date | Yes | String | 发票时间 |
| code | Yes | String | 开具金额或者校验六位。不知道就不填,服务器会返回提示之后再根据填写。 |
| channel | Yes | String | 你猜,不填就拉闸 |
返回结果:
| 参数名 | 类型 | 说明 |
|---|---|---|
| message | String | 结果提示 |
| code | String | 0为成功处理 |
| time | String | 请求所花费的时间(毫秒) |
| data | String | 解析的数据 |
| info | String | 原始数据 |
7.14 更新(验证码识别率截至15号有97.5%了其实)
后来想想94不好看,就跑到96%了,测试次数为一万个官网请求,这样又是全网最高识别率。


7.13 更新(识别率回归,初步到94%)
由于没有更高的需求,中文字符集训练过于耗时,GPU资源也不能一直用来跑这个,决定停止训练,目前版本官网实测5千次请求,94.3%准确率。
7.12 更新(生成器调参思路)
最新的思路:样本生成器自动调参的方法,当然了写生成器需要有一定的技术含量,需要弄清楚哪些是变量,CSDN有位大佬写过python版本的生成器,我下载来生成了一波,发现相似度比我简书放出的钓鱼版本还低hhhh,通过预留参数接口基于给出的一张样图,生成各种参数的生成样本,自动对比生成样本和给定对照样本的相似度,取最佳参数即可获得官网算法的最佳参数,调参成本也就生成w级别的样本即可找出最佳参数,对于计算机而言1分钟不到。这样只要掌握的通用生成器,只要在一定范围内更新都不是问题。此方法过于偏门,其实就算公开了思路,但是能写出来的人估计也没几个。有钱的大公司每次更新无脑去人工打码采集样本就好了,小公司还是不要做什么发票查验了,实力劝退。
7.6 更新(官网更新,识别率翻车到90%)
由于官网会测试本接口,对生成参数进行算法微调,不论是字体样式,颜色配比,字符集等等都针对这CSDN的两篇文章的生成器做了对抗,由于之前训练的时候尽可能考虑到模型的泛化能力,测试接口识别率降比不大,目前仍有90%的识别率,为了保证模型的持续抗更新能力,目前在线接口已不再进行更新。
之前技术不精,思路略显笨拙,新的模型辅助了全新的生成器算法,能更好的对抗和适应各种参数的更新,后续或会开放最新的防更新思路,如何提高模型的泛化能力,最新接口请直接联系我,白嫖勿扰。
6.19 更新(训练和部署源码+JS逆向思路)
有人说我文章没有干货只有思路,这里我分享一下源码,训练及部署的教程:
https://blog.csdn.net/kerlomz/article/details/86706542
至于国税总局的发票查验平台JS这块的逆向可以参考:
https://blog.csdn.net/qq_35228149/article/details/106818057
验证码分析
如图所示:图像验证码,识别指定颜色的文字。
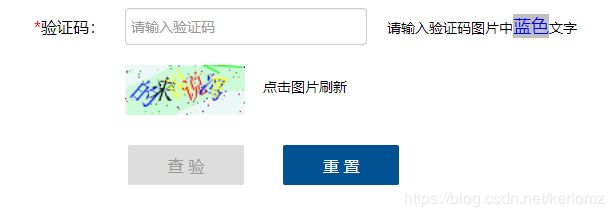
识别思路
首先有几条道路可以通向罗马,这里不分先后优劣一一讲述。
- 颜色提取的思路,可以采用HSV/K-means聚类进行颜色的分离提取:效果如下:

弊端显而易见,会有较大的特征丢失,识别率有较大的提升瓶颈,经过测试,中英文+汉字的识别率在90%左右。 - 不分离颜色的思路,该方案有两种处理方法:
(1)同时预测颜色和字符内容,这种方法看起来比较正统,但是成本较高,需要标注每张图的颜色和字符内容,这个要求有多高呢,一般的打码平台是无法提供这样的结果的,打码平台只返回对应颜色的内容,只能人工标注,那么需要多少样本呢?笔者训练的识别率98的模型用了100w左右的样本。一张这样的样本标注假设需要0.1元,那么100w样本需要10w标注费用,假设0.01元,也要1w的标注费用。但是验证码高质量的人工标注几乎是不存在的,因为很多样本,人眼的识别率是不如机器的,其次,标注团队不一定都是高学历,官网使用的字符集并不一定寻常人都认识,大多不会去深究,再者,相似的汉字也是容易混淆的,一个汉字旋转之后像另一个汉字是很常见的现象,所以总而言之,总体标注的准确率大概率不会超过85%。 所以即使有钱,也不一定能获得最好的资源,这方法看起来并不可取,有一种节约成本的办法,可以通过算法生成样本,但是呢,生成的识别率英文数字还可以,中文的识别率就低的可怜了。附上生成方法:https://www.jianshu.com/p/da1b972e24f2 ,当然这个生成算法是需要修改加工的,原始算法识别率不会超过40%。综合多个维度的算法微调去和官网的算法进行碰撞匹配,才能达到最终的效果,所以在此先劝退伸手党。CSDN也有另一篇Python版的生成算法,可以自行测试,生成的图片比我这个还不像hhhh,也是需要自行修改的。
(2)每个颜色分别训练一个模型, 这种方法看起来有点蠢,但是确实比较合适有效的办法了,可以轻松借助打码平台的返回结果标注样本。需要的颜色可以通过官网提供的字段取到,返回结果通过打码平台识别得到,这样一组合,样本就有了。这种方法的成本相对较低,样本数不变的前提下,打码价格低于人工标注的成本。不过人工打码响应平均在10-20秒之间,采集如此大量的样本数据可能要把业务都熬没了,其次还是一个认知水平问题,打码平台的打手普遍学历不高,尚有不少汉字是人不齐全的,很有可能导致样本极度不均衡,字符集不全等等,归根到底高质量的样本还是得从生成算法入手,慢慢提升模型对汉字的辨识度,笔者训练的样本用了100w。每个颜色分别训练这样成本还是下不来。四种颜色就是500w样本。官网的每次获取图片的时候颜色随机出现的概率也不一定是1/4。

(3)把所有颜色都通过颜色变换为一种颜色,整体思路同(2)。如下图,笔者将黑色转换为红色。我们只需要训练红色的图片:蓝转红、黄转红、黑转红,样本成本只有采集一种颜色的成本。看起来是目前位置最佳的方案了,事实也是如此的。但是呢,100w的总样本量对于普通人来说也是一笔不小的花销,即便有了样本能做出来也需要花费不少的时间和精力。
有些算法工作者可能会低估样本的实际需求量,3.6k分类,中文字体小,容易混淆相似的字多,不同的角度重叠干扰都会大大增加,过于复杂的网络对性能的要求也高,为了平衡性能和准确率,足够数量的样本支撑是必须的,100w样本量其实不大,一点都不要惊讶,7月之后的版本笔者用了6k字符集做的抗更新模型,训练足足花了1周。
不过采集样本不是单纯的接打码平台就完事了,需要经过官网判断,只有通过验证,正确的样本才保存下来。这样有效的样本对提高识别率才有帮助。

实验成果


笔者实时对接官网对实验模型进行检验,结果如上图,测试了200+次,识别率达到98%以上,识别速度的话,CPU大概5-8毫秒左右,部署腾讯云1核1G服务器实测10ms-12ms,模型大概3mb。
附上接口仅供测试,为了防止滥用,接口每天只支持请求500次:
| 请求地址 | Content-Type | 参数形式 | 请求方法 |
|---|---|---|---|
| http://152.136.207.29:19812/captcha/v1 | application/json | JSON | POST |
具体参数:
| 参数名 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | Yes | String | Base64 编码 |
| param_key | No | String | 颜色,red\blue\black\yellow |
请求为JSON格式,形如:
{"image": "iVBORw0KGgoAAAANSUhEUgAAAFoAAAAjCAIAAA...base64编码后的图像二进制流", "param_key ": "blue"}
注意:图片只能是 90x35 尺寸的原图,请勿截图
也请勿使用 模拟浏览器 的截图获取,如果不知道如何使用协议获取验证码,可以参考这个文章的方法:
https://blog.csdn.net/kerlomz/article/details/106793781
若对最新的JS逆向感兴趣可以关注作者。
若以上方法都不清楚,可以【另存为图片】,本模型针对【原图】训练。
截图无法识别,不理解的可以先了解下深度学习 图像识别原理 ,或咨询 作者 。
返回结果:
| 参数名 | 类型 | 说明 |
|---|---|---|
| message | String | 识别结果或错误消息 |
| code | String | 状态码 |
| success | String | 是否请求成功 |
该返回为JSON格式,形如:
{'uid': "9b5a6a34-9693-11ea-b6f9-525400a21e62", "message": "xxxx", "code": 0, "success": true}
请勿恶意使用,若超出当日限制将返回:
{'uid': "9b5a6a34-9693-11ea-b6f9-525400a21e62", 'message': '超出当日请求限制,请联系作者QQ:27009583', 'success': False, 'code': -555}
若返回 400 则表示数据包格式有误,请检查是否符合JSON标准。
若返回 405 则请检查确保使用POST方式请求。
Python示例:
import requests
import base64
with open(r"C:\1.png", "rb") as f:
b = f.read()
# param_key: black-全黑色,red-红色,blue-蓝色,yellow-黄色
r = requests.post("http://152.136.207.29:19812/captcha/v1", json={
"image": base64.b64encode(b).decode(), "param_key": "yellow"
})
print(r.json())