Linux下查找日志命令大全
Linux下查找日志命令大全
grep
grep这个命令肯定是大家使用最多的了,但是这个命令到底怎么用呢,你都掌握了么?
grep:查找文件中包含指定文本的命令
语法:grep "测试" test.log
解释:查找test.log所有包含"测试"字符串的行
基本用法
这个是最基础的语法,但是仅仅是这远远不够,我们来看下它有哪些参数(只介绍最常用的一些参数):
-a或者-text: 不忽略二进制数据-A:显示匹配的行以及该行后n行-B:显示匹配的行以及该行前n行-C:显示匹配的行以及该行前后n行-c:显示匹配的行数总和(注意是行数,如果一行匹配到两个也算一行)-H:显示匹配的行说属文件名-i:不区分大小写-n:显示匹配的行并行显示当前行数是多少-r:查询文件夹下所有内容-v:显示除匹配以外的内容(就是不包含的意思)-w:匹配整个单词而不是字符串的一部分
举例:查找test.log中有多少行包含"KingMouse"字符串
grep -c "KingMouse" test.log
高级用法
一次查找多个文件
示例:grep “KingMouse” test1.log test2.log
但是更多 的还有一种情况,比如线上我们的服务产生的日志都是按照大小来分割的,比如:
- test-error.log
- test-error.log.1
- test-info.log
- test-info.log.1
- test-info.log.2
- test-info.log.3
那这个时候我们用-r就不行,因为我们不想查error文件中日志,那这个时候就可以用:grep "KingMouse" test-info.log.* 来查找(生产上慎用,会大大增加cpu压力,最好确定范围再查找)
正则表达式
注意:使用正则表达式的时候不要用双引号,而是要用单引号
场景:搜索日志中记录当前线程池空位信息
grep "线程池空位"

结果出来很多结果,如果我们此时急需要查记录线程池空位490-495之前怎么办呢?此时就需要用到正则表达式了:
‘grep ‘线程池空位49[0-5]’ test.log’
此时搜索出来的:
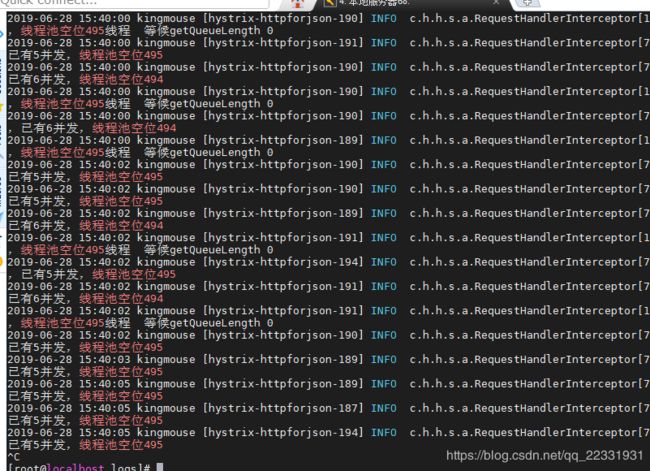
我们发现这样是不是简单很多,当然,关于正则表达式的还有很多,这里我就不说那么多,不会的小伙伴可以自己去搜下正则表达式!下面给一个分官网上的关于这个命令正则表达式规则说明:
^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ # 锚定行的结束 如:'grep$' 匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。
[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) # 标记匹配字符,如'\(love\)',love被标记为1。
\< # 锚定单词的开始,如:'\ # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} # 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} # 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} # 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W # \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b # 单词锁定符,如: '\bgrep\b'只匹配grep。
多条件查找
1、或操作
grep '123|abc' test.log 查找test.log中包含123或者abc的行
2、与操作
grep '123' test.log | grep 'abc' 查找test.log中包含123同时也包含abc的行
head
其实整个命令我本人用的不是很多,不过偶尔也用,head其实很好理解,就是头的意思嘛,所以他可以用来查看当前日志文件开头内容比如查看文件前10行 head -10 test.log
tail
这个命令生产上用的也不是很多吧,大概就是调试的时候用的比较多,比如我们想要实时查看当前服务日志:tail -f test.log,效果类似本地控制台吧
再或者我们需要最新的100行内容(文件末尾100行):tail -100 test.log
sed
这个命令很重要,应为生产上日志文件一般都是非常大的,我们要在一个很大的日志中搜索或者下载某部分内容相当不容易,此时可以用sed命令
查看某一段时间内的日志(日志输出需要有时间才可)
- 查看2020年3月27号上午9点到夜晚9点中间的日志
sed -n '/2020-03-27 09:00/,/2020-03-27 21:59/p' test.log
搜索某段时间内的日志
- 搜索2020年3月27号上午9点到夜晚9点中包含"kingmouse" 字符串的行数
sed -n '/2020-03-27 09:00/,/2020-03-27 21:59/p' test.log | grep -c "kingmouse"
将某段时间内的日志保存到一个新的文件中
- 将2020年3月27号上午9点到夜晚9点时间段内所有日志保存到当前目录下
sed -n '/2020-03-27 09:00/,/2020-03-27 21:59/p' test.log > newfile.log
关于sed命令用法还有很多,这里我给大家介绍最长用的,其他的可以去自行了解下
终极奥义 awk
awk是在过于强大,本人也是在学习探索中,今天我就来给大家说其中一种用法:拆分,类似java中的split()方法
最常用的,比如rest接口会默认打印接受的参数信息:
2020-03-27 10:16:05.615 cs_ccc_smartivr 10.172.54.145 kingmouse [http-nio-8080-exec-5] INFO c.h.h.system.log.ControllerAspect[48] [CallId : , ContactId : ] [TxId : -2006951347.113.15852753656100767 , SpanId : ]- Controller CLASS.METHOD : com.csc.kingmosue.controller.IvrFlowEngineController.query Args : [1585275342-66529420200327101605608, 1585275342-665294, 13180090312, 0, null, null, 100100311, 1800130, 2, 0, 0, 1, null, 255, null, null, 13180090312, null, org.springframework.security.web.firewall.FirewalledResponse@11bd369a]
如果我们想看一下某个参数,比如第二个参数是啥,我只想看第二个参数
那么我们可以这样:
1、查找出当前和这个接口记录的内容
grep "com.csc.kingmosue.controller.IvrFlowEngineController.query Args" test.log > test2.log
2、将每行按照逗号拆分并输出第二个参数
awk -F ',' '{print $4}' test2.log
有人说为什么不是2而是4,为什么说和java的split()方法类似呢,他是以都逗号分隔,钱数前面还存在逗号,所以就不是第二个了,这个自己大家数一下就好
你以为到这里就结束了?no!
我们刚刚输出了第二个参数,如果我需要判断当第二个参数不等于null的时候输出,等于null就不输出
awk -F ',' '$4 ~/null/{print $4}' test2.log
再增加点难度,比如我想判断第二个参数不等于null并且去重然后再统计行数
awk -F ',' '$4 ~/null/{print $4}' test2.log|sort|uniq|wc -l
解释:
uniq:去重,一般配合sort使用
wc -l:统计行数
好了,今天的知识分享到这里了,我这里介绍的知识众多命令中的冰山一角,而我也是把我平时使用最多的拿出来和大家分享下!