Java并发编程实战总结
https://time.geekbang.org/column/intro/159 的总结
并发bug原因
由于CUP,内存与I/O设备三者存在速度差异,为了平衡三者速度差异,采用了以下三种方式
- cpu增加缓存平衡与内存速度差异,但是会导致可见性问题(线程a对共享变量的操作,线程b可能看不到);
- 操作系统增加进程与线程,以分时复用cpu来平衡cup与I/O设备的速度差异,但是会导致原子性问题(我们潜意识的整体操作,如变量的自加在CPU执行过程中可能会由于线程的切换而导致操作被中断);
- 为了合理利用缓存, 编译程序优化指令执行顺序,但是会导致有序性问题(优化后的程序可能不会按设想那样去执行,会引发类似空指针异常的问题)
Java内存模型(可见性和有序性问题)
Java内存模型规范了JVM如何按需禁用缓存和编译优化的方法***。具体是volatile、synchronized、final三个关键字,以及六项Happens-Before规则*(前一操作结果对后续操作是可见的)
- volatile告诉编译器对这个变量的读写不用cpu缓存,必须从内存中读写(这个可以解决可见性问题)
- happen-before规则
a. 程序的顺序性规则 程序前面对变量修改对后续操作可见
b. volatile变量规则 一个volatile变量的写操作对后续这个volatile变量的读操作可见
c. 传递性 A Happens-Before B,且B Happens-Before C,那A Happens-Before C
d. 管程中锁规则 一个锁的解锁 Happens-Before 于后续对这个锁(管程是同步意思)
e. 线程start()规则 主线程A调用了子线程B,子线程B能够看到主线程A调用它之前的操作
f. 线程join()规则 主线程A调用了子线程B的join()方法后,主线程A能看到子线程B对共享变量的操作 - final final修饰的变量就是告诉编译器该变量不改变,可以优化到极致(解决有序性问题)
互斥锁(原子性问题)
线程切换是导致原子性问题的原因,而解决该问题有个方法就是同一时刻只有一个线程执行,就是互斥
而实现互斥的方法就是锁,synchronized,要注意的是对应的锁去保护对应的资源像门票指定座位
有一条隐式规则:
当修饰静态方法时候,锁定是当前类的Class对象;当修饰非静态方法时候锁的是当前实例对象this
class SafeCalc {
long value = 0L;
synchronized long get() { //java编译器会在synchronized修饰方法或代码块前后自动加锁和解锁
return value;
}
synchronized void addOne() {//这里相当于synchronized(this) void addOne(){}
value += 1;
}
}

锁和受保护资源关系
受保护资源和锁之间的关联关系是N:1的关系,多对一,有点类似包场,注意不能多把锁保护一个资源
保护没有关联关系的多个资源
有两种方法:
- 不同资源用不同的锁,各管各的
- 用一把互斥锁保护多个资源,如:帐户类里帐户余额和密码都可以用一把锁来保护,只需要在类里所有方法加上synchronized,但是由于所有操作都是串行,会有性能问题。
综上所述,可以对不同受保护资源进行仔细分类,用不同锁对对这些资源保护,提高性能,这就是细粒度锁
保护有关联关系的多个资源
像转账业务,A帐户赚钱给帐户B,就需要锁是覆盖帐户A和帐户B的
而实现的方式有:
- 用具体类对象作为共享锁,这里可以使用Account.class,但是所有操作成串行,实际不可行
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
synchronized(Account.class) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}

2. 像古代那样同时到出账本(锁)和入账本(锁),也可以实现转账,但是可能会造成死锁,如:帐户A与帐户B同时相互转账,线程A拿到帐户A的锁,线程B拿到帐户B的锁,两个线程都拿不到两个锁,就互相等待
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this) {
// 锁定转入账户
synchronized(target) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
}

解决死锁问题
死锁:一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象。
思路:并发程序一旦死锁很多时候只能重启应用,所以最好的方法还是避免死锁,分析死锁发生条件,通过破坏其中一个条件来避免死锁发生
死锁条件:
- 互斥,共享资源X和Y只能被一个线程占用;(这个条件没办法破坏)
- 占有且等待,线程T1已经取得共享资源X,在等待共享资源Y时不释放共享资源X;(一次申请所有资源)
- 不可抢占,其他线程不能抢线程T1占用的资源;(其它资源申请不到线程T1占用资源时,主动释放自己占用资源)
- 循环等待,线程T1与线程T2互相等待彼此占有的资源;(给资源排序,按顺序申请资源就不会循环)
具体实现
破坏占有且等待条件 :多个管理员,当线程A来申请共享资源X和共享资源Y时候,只有X和Y都在时候才允许申请,具体可看代码实现
class Allocator {
//这个list用来装载被申请的资源,list中的对象表示该对象已经被线程占用
private List<Object> als =
new ArrayList<>();
// 一次性申请所有资源
synchronized boolean apply(
Object from, Object to){
if(als.contains(from) ||
als.contains(to)){
return false;
} else {
als.add(from);
als.add(to);
}
return true;
}
// 归还资源
synchronized void free(
Object from, Object to){
als.remove(from);
als.remove(to);
}
}
class Account {
// actr 应该为单例
private Allocator actr;
private int balance;
// 转账
void transfer(Account target, int amt){
// 一次性申请转出账户和转入账户,直到成功
while(!actr.apply(this, target));//apply()方法代表资源可以申请 这里用了while死循环后面可以再优化以提高性能
try{
// 锁定转出账户
synchronized(this){
// 锁定转入账户
synchronized(target){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
} finally {
actr.free(this, target)
}
}
}
破坏不可抢占条件:核心是主动释放占用的资源,但是用synchronized是做不到的,可以用java.util.concurrent下的Lock解决
破坏循环等待条件:对资源进行排序,且按顺序申请资源,这里可以用id作为序号,从小到大顺序来申请((避免申请同一共享资源),可以看代码
class Account {
private int id;
private int balance;
// 转账
void transfer(Account target, int amt){
Account left = this ①
Account right = target; ②
if (this.id > target.id) { ③
left = target; ④
right = this; ⑤
} ⑥
// 锁定序号小的账户
synchronized(left){
// 锁定序号大的账户
synchronized(right){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
等待-通知机制
业务需求:上面为了避免死锁而去破坏占有且等待的条件(一次申请所有资源),方法是通过一个资源管理员来管理资源,只有申请共享资源都没被占用时才可以。其中用到了while的是死循环来判断共享资源有没有被占用,这里如果并发量大时候有优化需求,最好的办法是当线程想申请的所有资源没有或不全时,让线程阻塞自己进入等待状态;而当线程申请资源齐全时候则通知线程,通知线程重新执行
完整的等待-通知机制:线程获取互斥锁,线程要求条件不满足时候释放互斥锁并进入等待状态;等要求满足的时,通知等待的线程重新获取互斥锁
实现方法: 可以参考排队看医生流程
- 患者先去挂号,然后等待叫号==线程排队
- 叫到患者号时,患者去找大夫就诊==线程获取互斥锁
- 就诊过程中,大夫可能叫患者去做检查,同时叫下位患者==线程要求没有满足,且该线程释放持有的锁,让其他线程来获取锁
- 患者做好检查拿到报告后重新分诊,等待叫号==线程重新进入排队的队列里等待获取互斥锁
- 大夫再叫到号的时,患者再去找大夫就诊==线程再次获取互斥锁
实现方式
方式有很多种,其中一种用synchronized配合wait(),notify(),notifyAll()就能实现,下面是原理图,调用了wait()方法之后线程被阻塞进入互斥锁的等待队列,并同时释放互斥锁;当条件满足时调用notify()会通知互斥锁的等待队列,告诉它条件曾经满足过。
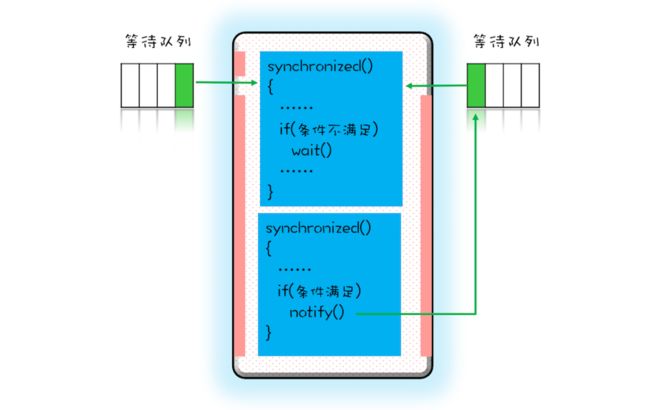
class Allocator {
private List<Object> als;
// 一次性申请所有资源
synchronized void apply(//Allocator是单列的,所以这里用this作为互斥锁
Object from, Object to){
// 经典写法
while(als.contains(from) ||
als.contains(to)){
try{
wait();//条件不满足就等待
}catch(Exception e){
}
}
als.add(from);
als.add(to);
}
// 归还资源
synchronized void free(
Object from, Object to){
als.remove(from);
als.remove(to);
notifyAll();//当锁被释放的时候就通知
}
}
尽量使用notifyAll()
使用notify()是随机通知等待队列中一个线程,这样某些线程可能永远不会被通知到,notifyAll()是通知所有线程
wait与sleep区别
- wait()会释放持有锁,sleep不会
- wait()只能在同步方法或代码块中使用,sleep可在任意地方使用
- wait()无需捕捉异常,sleep需要
- wait()是Object类方法,sleep是Thread方法
- wiat()调用时不用指定时间,sleep方法必须指定时间
安全性问题
首先要一开始就分析了并发bug三个主要源头:原子性,可见性和有序性,处理问题就要从这三个源头来避免。当存在共享数据且该数据会发生变化,意思就是多个线程同时读写同一数据。
线程安全:程序按照我们期望去运行
数据竞争:多个线程同时访问同一数据,并且至少有一个线程写数据时候,如果没采取防护措施就会导致并发bug
竞争条件:指程序执行结果依赖线程执行顺序,如果代码出现if语句也有可能存在竞争条件问题看下面代码
public class Test {
private long count = 0;
synchronized long get(){
return count;
}
synchronized void set(long v){
count = v;
}
void add10K() {
int idx = 0;
while(idx++ < 10000) {
set(get()+1)
}
}
}
该代码通过用synchronized修饰set和get方法,解决了数据竞争的问题,但是线程A和线程B同时执行get和set方法的话,最终count就不会得到预想结果,就是存在线程安全问题。如果两线程分开先后执行就不会存在这问题,就是结果依赖线程执行顺序,这就是竞争条件
活跃性问题
指的是某个操作无法执行下去,三种典型情况:死锁,活锁和饥饿
死锁 线程阻塞,解决方法上面又说
活锁 线程没有发生阻塞,但依仍然执行不下去,情况为线程互相谦让,联想两个迎面的人互相让道场景。解决方法是设置一个随机等待时间既可以同时互相避免谦让的情况
饥饿 线程因无法访问所需资源而无法执行下去的情况 ,就是线程优先级“不均”或持有锁线程执行时间过长,那线程优先级低或其它线程执行机会就小。解决方法三种:
- 保证资源充足
- 公平分配资源 这个可行性比较高
- 避免持有锁的线程执行时间过长
性能问题
锁本质就是是并行程序串行化,而锁的过度使用有可能使串行范围过大,这样不能发挥多线程的优势了。
Amdahl定律是用来表述多核多线程比单核单线程能提速多少呢

n为cpu核数,p为并行百分比,1-p为串行百分比。假设串行百分比为5%,CPU核数无穷大,那S极限是20,意味着无论采用什么技术,最高提高20倍性能。
如何避免锁带来性能问题
- 使用无锁算法和数据结构,技术有:线程本地存储,写入时复刻,乐观锁等;Java并发包里面的原之类也是一种无所的数据结构;Disruptor则是个无锁的内存队列
- 减少锁持有时间,具体实现方案:使用细粒度的锁如java并发包里的ConcurrentHashMap,它使用了分段锁技术;还有读写锁,读无锁,写才有锁
性能度量
3. 吞吐量:单位时间内能处理请求数量,越高约好
4. 延迟:从发出请求到响应时间,越小越好
5. 并发量: 同时处理的请求数量,并发量增加,延迟也增加
管程(monitor,解决互斥和同步)
定义: 指管理共享变量以及对共享变量操作的过程,使他们支持并发
MESA模型:
管程如何实现互斥: 实现统一时刻只有一个线程访问共享资源,思路是把共享变量和对共享变量的操作统一封装起来

管程X封装了共享变量queue和,对其X操作的方法enq()和deq(),线程想访问共享变量queue只能通过enq()和deq()方法;enq()和deq()保证互斥性,只允许一个线程进入管程
管程如何实现同步:
跟就医流程差不多,门口患者等待,只有一个患者就诊 注意每个条件变量都有自己等待队列,当线程T1在条件变量A的等待队列里等待时候,如果被通知当时满足条件变量A,线程T1就到入口等待队列重新排队等待进入管程

hasen模型与hoare模型与mesa模型的区别
核心区别是wait()之后的唤醒机制:
- hasen是执行完后再去唤醒另外一个线程,并且保证线程的执行;
- hoare是中断当前线程,唤醒另外一个线程,执行完再去唤醒,且保证执行;
- measa是进入等待队列,不保证一定执行
JAVA线程的生命周期
通用的线程生命周期

- 初始状态:编程语言上线程被创建,但在操作系统里真正线程没有创建,还不允许分批cpu执行
- 可运行状态:操作系统创建了线程,线程可以分配给cpu运行
- 运行状态:当cpu空闲时候,操作系统将可运行状态的线程分配给cpu,该线程状态也就变成了运行状态
- 休眠状态:运行状态的线程如果调用一个阻塞api或等待某个事件(如条件变量),该线程就会变成休眠状态且释放cpu使用权。等待事件出现后,休眠状态的线程又会变成运行状态
- 终止状态:线程执行完或者出现异常进入终止状态,该线程生命周期也结束了
java语言把可运行状态和运行状态合并了,然后把休眠状态细化
java中线程生命周期
NEW(初始化状态)、 RUNNABLE(可运行/运行状态)、BLOCK(阻塞状态)、WAITING(无时限等待)、TIMED_WAITING(有时限等待)、TERMINATED(终止状态),其中BLOCK、WAITING、TIMED_WAITING这三种都是睡眠状态,简化一下可得下图

而我们平时所谓的 Java 在调用阻塞式 API 时,线程会阻塞,指定是操作系统线程的状态,并不是java线程的状态
RUNNABLE与BLOCK转换
线程等待synchronized的隐式锁。synchronized修饰的方法、代码块同一时刻只能运行一个线程执行,其他线程等待就把状态从RUNNABLE转成BLOCK状态
RUNNABLE与WAITING转换
a. 获得synchronized隐式锁的线程,调用无参数的Object.wait()方法。
b. 调用无参数的Thread.join()方法。两个线程对象thread A和thread B,当theadB调用了A.join(), thread B就会等待thread A执行完,而threa B等待时候状态为WAITING,thread A执行完后,thread的状态又为RUNNABLE
c. 调用 LockSupport.park() 方法,当前线程会阻塞,线程状态变为WAITING,调用LockSupport.unpark(Thread thread)可以唤醒目标线程,线程又变回RUNNABLE
RUNNABLE与WIMED_WAITING(跟WAITING比就是多了超时参数)
1、调用带超时参数的Thead.sleep(long millis)方法;
2、获得synchronized隐式锁的线程,调用带超时参数的Object.wait(long timeout)方法;
3、调用带超时参数的Thread.join(long millis)方法;
4、调用带超时参数的LockSupport.parkNanos(Object blocker,long deadline)方法;
5、调用带超时参数的LockSupport.parkUnitl(long deadline)方法
NEW状态
java刚创建出来的Thread对象就是NEW状态,方法有两种,一种是继承Thread对象,重写run()方法。
// 自定义线程对象
class MyThread extends Thread {
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
MyThread myThread = new MyThread();
另一种是实现Runnable接口,重写run()方法,并将该实现类作为创建Thread对象的参数
// 实现 Runnable 接口
class Runner implements Runnable {
@Override
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
Thread thread = new Thread(new Runner());
NEW转RUNNABLE
调用线程对象start()方法就可以
MyThread myThread = new MyThread();
// 从 NEW 状态转换到 RUNNABLE 状态
myThread.start();
RUNNABLE到TERMINATED
1、线程执行完run()方法后,自动转换到TERMINATED状态
2、run()执行时异常抛出
3、我们强行中断run()方法执行(如中断一个访问很慢点网络),建议用interrput(),不建议stop()
stop()与interrupt()区别
stop()方法会真杀死线程,使线程没有后续操作,如果线程持有ReentrantLock锁,调用了stop()方法后线程就不会去调用ReentrantLock的unlock()方法去释放锁,其它线程就没机会获得ReentrantLock锁。suspend()与resume()这两个方法类似
interrupt()方法只是通知线程,让线程有后续操作
使用多线程原因*
为了提供程序性能,而描述程序性能有两个核心:延迟和吞吐量。
延迟:发出请求到响应请求这个过程的时间,越短越好
吞吐量:单位时间内能处理请求的最大数,越多越好
同等条件下,延迟越短,吞吐量越大,所以要提高性能,就要降低延迟,提高吞吐量
如何降低延迟,提高吞吐量
1、优化算法
2、将硬件性能发挥到极致
计算机主要硬件有两类:I/O和CPU,在并发编程领域,提升性能本质上就是提升硬件的利用率,具体是提升I/O利用率和CPU利用率,操作系统解决了单一设备的问题,而我们需要自己利用多线程去解决CPU和I/O设备综合利用率的问题

创建多少线程合适
分两个应用场景
1、对于CPU密集型运算
理论上:线程数量=CPU核数目,一般会设置为线程数量=CPU核素+1,因为当线程因为偶尔的内存也失效或其他原因导致阻塞时,额外的线程可以顶上
2、对于I/O密集型运算
单核:最佳线程数 = 1+(I/O耗时 / CPU耗时)
多核:最佳线程数 = CPU核数*[1+(I/O耗时 / CPU耗时)]

如何测试IO/CPU这个耗时比,用工具如apm
算法优化和线程池配置,按照经验配置一个全局大小线程池,遇到异步执行任务扔到这个全局线程池处理,通过打印线程池的利用率来自己分配线程池的大小。大多数时候可以通过缓存,优化业务逻辑,提前算好等方式来提高吞吐量
局部变量是线程安全
局部变量是放到了CPU的堆栈寄存器(调用堆)里,方法与栈帧共存亡,而局部变量在栈帧里面,而new出来的对象是在堆里,一个变量想要跨过方法边界,就必须创建在堆里

每个线程都有自己独立的调用栈 所以局部变量不存在并发问题
线程封闭
仅在单线程内访问数据,不共享就不用同步也不会有并发问题,采用线程封闭技术案例有:数据库连接池里获取的连接Connection,数据库连接池通过线程封闭技术,保证一个Connection一旦被一个线程获取之后,在这个线程关闭Connection之前的世界里,不会在分配给其他线程,保证了Connnection不会有并发问题。
递归太深可能导致栈溢出
原因:每递归一次,就要创建一个新的栈帧,而栈的大小不是无限的
解决:
1、不用递归,用循环代替,缺点是代码逻辑不够清晰;
2、限制递归次数
3、使用尾递归,尾递归是指在方法返回时只调用自己本身,且不能包含表达式。编译器或者解释器会把尾递归做优化,使递归无论调用多少起,都只占用一个栈帧,所以无栈溢出,但是JAVA没有尾递归优化
面向对象思想来写并发
可以从***封装共享变量、识别共享变量间的约束条件和制定并发访问策略***这三个方面入手
将共享变量作为对象属性封装在内部,对所有公共发方法指定并发访问策略
public class Counter {
private long value;
synchronized long get(){
return value;
}
synchronized long addOne(){
return ++value;
}
}
如果共享变量很多,而且这些共享变量不会变(如身份证,姓名,信用卡账户卡号),可以用final关键字来修饰。
识别共享变量的约束条件,决定了并发访问策略
比如合理库存,库存不能太高又不能太低,它有上限upper和下限lower两个成员变量,由于变量使用了AtomicLong原之类,原子线程是安全的,所以这两个变量的set方法不需要同步
public class SafeWM {
// 库存上限
private final AtomicLong upper =
new AtomicLong(0);
// 库存下限
private final AtomicLong lower =
new AtomicLong(0);
// 设置库存上限
synchronized void setUpper(long v){
// 检查参数合法性 这里使用了if就要考虑竞争条件的问题,也会是由于这问题,这个方法要用synchronized来修饰保证原子性
if (v < lower.get()) {
throw new IllegalArgumentException();
}
upper.set(v);
}
// 设置库存下限
synchronized void setLower(long v){
// 检查参数合法性
if (v > upper.get()) {
throw new IllegalArgumentException();
}
lower.set(v);
}
// 省略其他业务代码
}
}
制定并发访问策略
1、避免共享模式:技术主要是利用线程本地存储以及为每个任务分配独立线程
2、不变模式:
3、管程及其他同步工具:管程是java领域万能及解决方案,特定场景用java并发提供的读写锁、并发容器同步工具会更好
并发良好原则
1、优先使用成熟的工具类:熟悉java sdk并发包提供的工具类并用好他们
2、迫不得已才用低级的同步原语:这里低级同步原语指是synchronized、Lock、Samaphore等,小心使用
3、避免过早优化:安全第一,并发程序先保证安全,出现性能瓶颈后再优化。性能瓶颈不是你想预估就能预估的
理论基础图

用锁最佳实践
1、synchronized(new Object)在JVM开启逃逸分析后,会被优化掉,在真正执行时候不存在
2、锁应该是私人的,不可变不可重用的,像Integer、Boolean和String类型对象在JVM里斯可能被重复用到,如果其他代码synchronized(你的锁)且不释放,你的代码可能拿不到锁
示例代码: 可以参考《JAVA安全编码标准》
// 普通对象锁
private final Object
lock = new Object();
// 静态对象锁
private static final Object
lock = new Object();
锁性能看场景
根据场景找适用方案,如While(!actr.apply(this.target));这个方法在允许转账并行,在转账操作多时候,就比synchronized(Account.class)更适合
竞态条件
下面的add()和contain()方法线程安全,但是组合在一起时候,程序结果依赖线程执行顺序,即存在竞争条件问题,(if判断的语句要注意可能存在竞争问题)
void addIfNotExist(Vector v,
Object o){
//if判断可能存在条件竞争问题
if(!v.contains(o)) {
v.add(o);
}
}
解决思路是用面向对象思想里的(1、将共享变量封装在对象内部 2、控制并发访问路径)来防止共享变量v的滥用而导致并发问题
class SafeVector{
private Vector v;
// 所有公共方法增加同步控制
synchronized
void addIfNotExist(Object o){
if(!v.contains(o)) {
v.add(o);
}
}
}
方法调用是先计算参数
set(get()+1)这条语句先进入get()方法,再执行set()方法
InterrupteException异常处理需要小心
Thread th = Thread.currentThread();
while(true) {
//本意通过th.isInterrupted()检查线程是否被中断了,中断就退出whie循环
if(th.isInterrupted()) {
break;
}
// 省略业务代码无数
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
}
当其它线程调用th.interrupt()来中断线程时,会设置th线程的中断标志位,从而使th.isInterrupted()返回true
实际上,由于大多数线程会在Thread.sleep(100)处阻塞从而触发InterrputedException,同时会把th线程的中断标志位清楚,所以正确做法是在捕捉错误后,再重新设置中断标志位
try {
Thread.sleep(100);
}catch(InterruptedException e){
// 重新设置中断标志位
th.interrupt();
}
最佳线程数的理论值与经验值*
对于很多“I/O耗时 / CPU耗时”不太容易确定的系统来说,经验值“最佳线程 = 2×CPU的核素+1”可以得到较好初始值
在实际工作中,最佳线程数通过压测来确定的,“I/O耗时 / CPU耗时”往往都大于1,所以基本在这初始值上增加。一般来说,随线程数增加,吞吐量也会增加,延迟也会缓慢增加;但是当线程增加到一定程度,吞吐量就会下降,延迟就会迅速增加,这时候基本上就是线程能够设置的最大值
并发要关注细节,可阅读《JAVA安全编码标准》
Lock和Condition
Lock解决互斥,Condition解决同步
java语言本身提供了synchronized来实现管程,而java sdk并发包通过Lock和Condition两个接口来实现管程
两者的区别是:
1、Lock接口能破坏死锁形成的条件之一“破坏不可抢占条件”,而synchronized不能
具体看Lock接口的三个方法
// 支持中断的 API 用synchronized来锁的线程一旦死锁就没机会唤醒,这里如果能够支持中断唤醒线程,就能使线程有机会释放曾经拥有的锁
void lockInterruptibly()
throws InterruptedException;
// 支持超时的 API 线程在一段时间后获取不到锁不是进入死锁而是返回错误,这样线程也有机会释放曾经有的锁
boolean tryLock(long time, TimeUnit unit)
throws InterruptedException;
// 支持非阻塞获取锁的 API 如果尝试获取锁失败不是进入阻塞,而是返回,也可以使线程有机会释放曾经有的锁
boolean tryLock();
Lock如何保证可见性
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public void addOne() {
// 获取锁
rtl.lock();
try {
value+=1;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}
简单来说利用了volatile相关的happens-before规则
可重入锁
指的是线程可以重复获取同一把锁
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public int get() {
// 获取锁
rtl.lock(); //3
try {
return value;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
public void addOne() {
// 获取锁
rtl.lock(); //1
try {
value = 1 + get();//2
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}
先理解程序执行顺序是123,在1处已经获取了锁rtl,然后通过2在3这里再次对锁rtl执行加锁操作,如果是可重入锁,再次加锁成功,否则线程被阻塞
可重入函数
指的是多个线程可同时调用该函数,每个线程都能得到则正确结果;同时在一个线程内支持线程切换,所以锁线程是安全的
公平锁与非公平锁
// 无参构造函数:默认非公平锁 唤醒策略是随机
public ReentrantLock() {
sync = new NonfairSync();
}
// 根据公平策略参数创建锁 唤醒策略是谁等待时间长就唤醒谁
public ReentrantLock(boolean fair){
sync = fair ? new FairSync()
: new NonfairSync();
}
用锁最佳实践
在并发大师Doug Lea《JAVA并发编程:设计原则与模式》推荐的三个用锁的最佳实践分别是:
1、永远只在更新对象的成员变量时加锁
2、永远只在访问可变的成员变量时加锁
3、永远不在调用其他对象的方法时加锁
第三点是因为”其它方法“里可能有sleep()调用,也有可能有很慢的I/O操作,更有可能加锁,导致双重加锁导致死锁
还可以参考减少锁的持有时间、减少锁的粒度等业界广为人知的规则
阻塞队列
队列是先进先出的,阻塞队列就是队列附加两个操作:队列为满的时候阻塞线程进来,队列为空的时候不允许出列
利用两个条件写的代码:
public class BlockedQueue<T>{
final Lock lock =
new ReentrantLock();
// 条件变量:队列不满
final Condition notFull =
lock.newCondition();
// 条件变量:队列不空
final Condition notEmpty =
lock.newCondition();
// 入队
void enq(T x) {
lock.lock();
try {
while (队列已满){
// 等待队列不满 用Lock和Condition实现的方法只能用awit()方法,语义和wait()一样
notFull.await();
}
// 省略入队操作...
// 入队后, 通知可出队 这里signal()语义和notify()一样
notEmpty.signal();
}finally {
//这里语义unlock()语义和nitifyAll()一样
lock.unlock();
}
}
// 出队
void deq(){
lock.lock();
try {
while (队列已空){
// 等待队列不空
notEmpty.await();
}
// 省略出队操作...
// 出队后,通知可入队
notFull.signal();
}finally {
lock.unlock();
}
}
}
Semaphore
Semaphore翻译为信号量,可以实现线程互斥,并且允许固定数目的线程进入临界区,但是让线程去争锁,所以只能唤醒阻塞一个线程,唤醒一个线程,因为允许多个线程访问临界区,所以需要访问的共享变量可能存在并发问题,就需要加锁,即锁中锁
信号量模型
简单的有:一个计数器,一个等待队列,三个方法;

三个方法
init():设置计数器的初始值
down():计数器值-1,如果此时计算器值小于0,则当前线程阻塞,否则当前线程可以继续执行
up():计算器值+1,如果此时计算器值<=0,则唤醒等待队列中的一个线程,并将其从等待队列移除
class Semaphore{
// 计数器
int count;
// 等待队列
Queue queue;
// 初始化操作
Semaphore(int c){
this.count=c;
}
//
void down(){
this.count--;
if(this.count<0){
// 将当前线程插入等待队列
// 阻塞当前线程
}
}
void up(){
this.count++;
if(this.count<=0) {
// 移除等待队列中的某个线程 T
// 唤醒线程 T
}
}
}
实现互斥的代码
static int count;
// 初始化信号量 这里1的意思可以运行1个线程进入临界区,可以自己定义数目
static final Semaphore s
= new Semaphore(1);
// 用信号量保证互斥
static void addOne() {
/**
* 在 semaphore.acquire() 和 semaphore.release()之间的代码,同一时刻只允许制定个数的线程进入,
* 因为semaphore的构造方法是1,则同一时刻只允许一个线程进入,其他线程只能等待。
* */
s.acquire();
try {
count+=1;
} finally {
s.release();
}
}
对象池限流的示例代码
class ObjPool<T, R> {
final List<T> pool;
// 用信号量实现限流器
final Semaphore sem;
// 构造函数
ObjPool(int size, T t){
//因为允许多个线程访问,所以这里Vector不能更换成ArrayList,ArrayList是线程不安全的
pool = new Vector<T>(){};
for(int i=0; i<size; i++){
pool.add(t);
}
sem = new Semaphore(size);
}
// 利用对象池的对象,调用 func
R exec(Function<T,R> func) {
T t = null;
sem.acquire();
try {
t = pool.remove(0);
return func.apply(t);
} finally {
pool.add(t);
sem.release();
}
}
}
// 创建对象池
ObjPool<Long, String> pool =
new ObjPool<Long, String>(10, 2);
// 通过对象池获取 t,之后执行
pool.exec(t -> {
System.out.println(t);
return t.toString();
});
ReadWriteLock实现完备缓存
虽然已经有管程和信号量这两个同步语言可以解决所有并发问题,但是针对不同场景,可以有不同优化提升易用性
针对读多写少的并发场景,可以使用JAVA SDK并发包提供的读写锁----ReadWriteLock
读写锁
读写锁是广为使用的通用技术,所有读写锁都遵守三个基本原则:
1、允许多个线程同时读共享变量(互斥锁不行)
2、只允许一个线程写共享变量
3、如果一个线程正在执行写操作,此时禁止多线程读共享变量(写操作是互斥的)
快速实现一个缓存
class Cache<K,V> {
// map来装缓存里面的东西
final Map<K, V> m =
new HashMap<>();
//用ReentrantReadWriteLock()来实现ReadWriteLock接口,支持可重入
final ReadWriteLock rwl =
new ReentrantReadWriteLock();
// 读锁
final Lock r = rwl.readLock();
// 写锁
final Lock w = rwl.writeLock();
// 读缓存
V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
V put(String key, Data v) {
w.lock();
try { return m.put(key, v); }
finally { w.unlock(); }
}
}
缓存初始化问题
如果源头数据量不大,可以在应用启动时候把源头数据查询出来,依次调用类似上面的put()方法就可以了

如果源头数据量大,则需要按需加载数据,也叫懒加载

缓存的按需加载实现
class Cache<K,V> {
final Map<K, V> m =
new HashMap<>();
final ReadWriteLock rwl =
new ReentrantReadWriteLock();
final Lock r = rwl.readLock();
final Lock w = rwl.writeLock();
V get(K key) {
V v = null;
// 读缓存
r.lock(); //1
try {
v = m.get(key); //2
} finally{
r.unlock(); //3
}
// 缓存中存在,返回
if(v != null) { //4
return v;
}
// 缓存中不存在,查询数据库
w.lock(); //5
try {
// 再次验证 这里再次验证是为了当有多条线程同时调用了get()方法,当缓存不存在时候,只有一个线程获取了写锁w.lock()其它线程都在等待,而那个线程往缓存列更新值并释放锁后,其它线程就可以直接从缓存中读取,不需要再去查找数据库,提升了性能
// 其他线程可能已经查询过数据库
v = m.get(key); //6
if(v == null){ //7
// 查询数据库
v= 省略代码无数
m.put(key, v);
}
} finally{
w.unlock();
}
return v;
}
}
读写锁升级与降级
锁升级
如果先获取读锁并且在去获取写锁,这种情况叫做锁的升级,读锁没有释放就去获取写锁会导致写锁永久等待,最终导致相关线程被阻塞也没机会唤醒
// 读缓存
r.lock(); //1
try {
v = m.get(key); //2
if (v == null) {
//没有释放读锁情况下就去获取写锁,会导致写锁永久等待
w.lock();
try {
// 再次验证并更新缓存
// 省略详细代码
} finally{
w.unlock();
}
}
} finally{
r.unlock(); //3
}
锁降级
先获取写锁再去获取读锁是允许,叫锁降级
class CachedData {
Object data;
volatile boolean cacheValid;
final ReadWriteLock rwl =
new ReentrantReadWriteLock();
// 读锁
final Lock r = rwl.readLock();
// 写锁
final Lock w = rwl.writeLock();
void processCachedData() {
// 获取读锁
r.lock();
if (!cacheValid) {
// 释放读锁,因为不允许读锁的升级
r.unlock();
// 获取写锁
w.lock();
try {
// 再次检查状态
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 释放写锁前,降级为读锁
// 降级是可以的
r.lock(); ①
} finally {
// 释放写锁
w.unlock();
}
}
// 此处仍然持有读锁
try {use(data);}
finally {r.unlock();}
}
}
缓存数据与源头数据同步问题
上面办法解决了缓存初始化问题,但是没有解决缓存数据与源头数据同步问题,这里有个简单办法是超时机制,指的是缓存里的数据是有时间性的,当过了这段时间之后,缓存里的数据就会失效,当再访问缓存里失效数据时候,就会触发缓存重新从源头数据加载数据进缓存。
另一种办法是源头数据发生变化时候快速反馈给缓存,如MYSQL作为数据源头时候,可以通过实时解析binlog来识别源头数据是否发生了变化,如果变化了就将最新数据推送给缓存。
还有一种方案是数据库和缓存双写方案
StampedLock比读写锁性能更快
在JAVA1.8之后,推出有一适合多读少写场景的锁----StampedLock,性能比读写锁更好,
三种模式
StampedLock支持写锁,悲观读锁=约等于=ReadWriteLock支持的写锁和读锁
不同是StampedLock写锁和悲观读锁加锁成功之后都会返回一个stamp,然后解锁时候返回这个stamp(有点类似数据库乐观锁的Version)
StampedLock的写锁和悲观读锁的例子
final StampedLock sl =
new StampedLock();
// 获取 / 释放悲观读锁示意代码
long stamp = sl.readLock();
try {
// 省略业务相关代码
} finally {
sl.unlockRead(stamp);
}
// 获取 / 释放写锁示意代码
long stamp = sl.writeLock();
try {
// 省略业务相关代码
} finally {
sl.unlockWrite(stamp);
}
但是StampedLock还支持乐观读(注意是无锁的),而且这乐观读允许多个线程同时读的时候,一个线程获取写锁。而ReadWriteLock当多个线程同时读时候所有写操作都会被阻塞
class Point {
private int x, y;
final StampedLock sl =
new StampedLock();
// 计算到原点的距离
int distanceFromOrigin() {
// 乐观读
long stamp =
sl.tryOptimisticRead();
// 读入局部变量,
// 读的过程数据可能被修改
int curX = x, curY = y;
// 判断执行读操作期间,
// 是否存在写操作,如果存在,
// 则 sl.validate 返回 false
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
curX = x;
curY = y;
} finally {
// 释放悲观读锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(
curX * curX + curY * curY);
}
}
StampedLock使用注意事项
1、StampedLock的功能只是ReadWriteLock的子集
2、StampedLock不支持重入
3、StampedLock的悲观读锁、写锁不支持条件变量
4、如果线程阻塞在StampedLock的readLock()或者writeLock()上,此时调用该阻塞线程的interrupt()方法会导致CPU飙升
所以使用StampedLock一定不要调用中断操作,如果支持中断操作,一定要使用可中断的悲观读锁readLockInterruptibly()和写锁writeLockInterryptibly()
5、StamepdLock支持锁的降级(通过tryConvertToReadLock()方法实现)和升级(通过tryConvertToWriteLock()方法实现)
StampedLock读模板
final StampedLock sl =
new StampedLock();
// 乐观读
long stamp =
sl.tryOptimisticRead();
// 读入方法局部变量
......
// 校验 stamp
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
// 读入方法局部变量
.....
} finally {
// 释放悲观读锁
sl.unlockRead(stamp);
}
}
// 使用方法局部变量执行业务操作
......
StampedLock写模板
long stamp = sl.writeLock();
try {
// 写共享变量
......
} finally {
sl.unlockWrite(stamp);
}
锁的申请和释放要成对出现,这里小心因为锁升级而导致释放的锁不同的问题
/**
* StampedLock适合多读写少的场景
* 要注意的是锁的申请和释放要成对出现
*/
public class MyStampedLock {
private double x,y;
final StampedLock s1 = new StampedLock();
//
void moveIfAtOrigin(double newX,double newY){
long lock = s1.readLock();
try{
while(x==0.0&&y==0.0){
//tryConvertToWriteLock期望把stamp标示的锁升级为写锁,这个函数会在下面几种情况下返回一个有效的 stamp(也就是晋升写锁成功):
long ws = s1.tryConvertToWriteLock(lock);
//ws=0L的话表示升级失败,可能已经有写锁了
if(ws!=0L){
//因为锁升级了,所以finally释放的锁也要对应成升级的锁
lock = ws;
x = newX;
y = newY;
break;
}else{
s1.unlockRead(lock);
lock = s1.writeLock();
}
}
}finally{
s1.unlock(lock);
}
}
}
CountDownLatch和CyclicBarrierr让多线程同步
业务背景:优化对账系统,用户在商城下单后会生成订单号保存在订单库;之后物流派送单给用户发货,派送单保存在派送库;每天对账系统会查询未校验的订单与派送单校验,将差异写入差异库
逻辑图:

代码实现:
while(存在为未对账订单){
//查询未对账订单
pos = getPOrders();
//查询派送单
dos = getDOrders();
//执行对账操作
diff = check(pos,dos);
//差异写入差异库
save(diff);
}
一开始用单线程可以实现这个操作,时间分配如下:

这里getPOrders()和getDOrders()方法明显可以并行执行,比如下面
实现代码思路:创建俩个线程T1和T2,并执行查询未对账订单getPOrders()和查询派送单getDOrders(),然后主线程执行对账操作check()和写入差异操作save()。要注意的是主线程需要等待T1和T2执行后才能执行check()和save(),为此通过T1.join()和T2.join()来实现等待,当T1和T2线程退出时,调用T1.join()和T2.join()的主线程就会从阻塞状态被唤醒,之后再执行check()和save().
while(存在未对账订单){
//查询未对账订单
Thread T1 = new Thread(()->{
pos = getPOrders();
});
T1.start();
//查询派送单
Thread T2 = new Thread(()=>{
dos = getDOrders();
})
T2.start();
//等待T1、T2结束
T1.join();
T2.join();
//执行对账操作
diff = check(pos,dos);
//差异写入差异库
save(diff);
}
继续优化
上面代码有个不足地方是,while循环里每次都会创建新的线程,最后是创建出来的线程能够循环利用,就像线程池那样。
//创建2个线程的线程池
Executor executor = Executors.newFixedThreadPool(2);
while(存在未对账订单){
//查询未对账订单
executor.execute(()->{
pos = getPOrders();
});
//查询派送单
executor.execute(()->{
dos = getDOrders();
})
/**??如何实现等待??**/
//执行对账操作
diff = check(pos,dos);
//差异写入差异库
save(diff);
}
这里有个问题是,因为线程不会退出,所以jion()方法也不会生效,那么要考虑其它方式实现等待
可以考虑下计数器,初始值设置策成2,等执行完pos = getPOrders()时,数值减1,执行完dos = getDOrders()时,数值再减1,结果为0,这时候就代表两个查询操作都完成了。而在实际中,java并发包里已经提供了实现类似功能的工具类:CountDownLatch,对计数器减1通过latch.countDown()来实现,主线程中通过latch.await()来实现计数器等于0的等待
//创建2个线程的线程池
Executor executor = Executors.newFixedThreadPool(2);
while(存在为对账订单){
//计数器初始化为2
CountDownLatch latch = new CountDownLatch(2);
//查询未对账订单
executor.execute(()-{
pos = getPOrders();
latch.countDown();
});
//查询派送单
executor.execute(()->{
dos = getDOrders();
latch.countDown();
});
//等待两个查询操作结束
latch.await();
//执行对账操作
diff = check(pos.dos);
//差异写入差异库
save(diff);
}
进一步优化
两个查询操作和对账操作check()、save()之间是串行的,实际上是可以串行的,等执行对账操作时候可以去执行下一轮的查询操作

两次查询操作能够和对账操作并行,对账操作还依赖查询操作的结果,有点类似生产者-消费者意思,两次查询操作时生产者,对账操作是消费者,那就需要个队列来保存生产者生产的数据,而消费者则从这个队列消费数据
不过这里设计了两个队列,而且两个队列的元素之间还有对应关系,这样做好处是对账操作可以每次从订单类出一个元素,从排送单队列出一个元素,然后对这个元素执行对账操作,这样数据一定不会乱掉
T1线程和T2线程步调一致去执行自己查询工作,然后再去通知线程T3执行对账工作

用CyclicBarrier实现线程同步
两个技术点:1、线程T1和线程T2要同步2、能通知线程T3
思路:利用个计数器初始化为2,线程T1和T2生产完数据后,都将计数器减1,如果计数器大于0则线程T1或T2等待。如果计数器等0则唤醒线程T3,并重置计数器为2
java并发包提供相关的工具类CyclicBarrier来实现这功能,CyclicBarrier的计数器有重置功能,当减到0的时候,会自动重置你设置的初始值。
//订单队列
Vector<P> pos;
//派送单队列
Vector<D> dos;
//执行回调的线程池
Executor executor = Executors.newFixedThreadPool(1); //这里设置单线程是为了保证对账操作按顺序执行,查订单-》查派单-》对账
final CyclicBarrier barrier = new CyclicBarrier(2,()->{
executor.execute(()->check());
})
void check(){
P p = pos.remove(0);
D d = dos.remove(0);
//执行对账操作
diff = check(p,d);
//差异写入差异库
save(diff);
}
void checkAll(){
//循环查询订单库
Thread T1 = new Thread(()->{
while(存在未对账订单){
//查询订单库
pos.add(getPOrders());
//计数器减1,然后等待计数器为0时候
barrier.await();
}
});
T1.start();
//循环查询运单库
Thread T2 = new Thread(()->{
while(存在未对账订单){
//查询运单库
dos.add(getDOrders());
//计数器减1,然后等待计数器为0时候
barrier.await();
}
});
T2.start();
}
CountDownLatch和CyclicBarrier区别
CountDownLatch主要用来解决一个线程等待多个线程的场景,比如导游等所有游客齐了后才去下个景点
计数器不能循环利用,就是计数器为0,再有线程调用await()时,线程会通过
CyclicBarrier是一组线程之间互相等待,更像几个驴友之间不离不弃
计数器能循环利用,并且有自动重置功能,当计数器减为0会自动重置为你设置的初始值
还可以设置回到函数
并发容器之坑
同步容器注意事项
java容器主要分为四大类:List,Map,Set和Queue,这里不是所有java容器都是线程安全,比如ArrayList、HashMap就不是,那就有个问题需要解决:如何将非线程安全的容器变成线程安全的容器?
比如ArrayList作为例子:
SafeArrayList<T>{
//封装ArrayList
List<T> c = new ArrayList<>();
//控制访问路径
synchronized T get(int idx){
return c.get(idx);
}
synchronized void add(int idx,T t){
c.add(idx,t);
}
synchronized boolean addIfNotExist(T t){
// 可能存在竞争条件问题 就是
if(!c.contains(t)){
c.add(t);
return true;
}
return false;
}
}
根据这种包装方式,JAVA SDK的开发人员也在Collections这个类中提供了一套完备的包装类,比如下面把ArrayList、HashSet和HashMap包装成了线程安全的List、Set和Map
List lsit = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());
addIfNotExist()方法包含组合操作。即便每个操作都能保证原子性,也并不能保证组合操作的原子性。
迭代容器
这里组合操作就不具备原子性
List list = Collections.synchronizedList(new ArrayList());
Iterator i = list.iterator();
while(i.hasNext()){
foo(i.next());
}
正确方法是把list锁住再执行遍历操作
List list = Collections.synchronizedList(new ArrayList<Object>());
synchronized(list){
Iterator i = list.iterator();
while(i.hasNext()){
foo(i.next());
}
}
包装后的线程安全容器都是基于synchronized这个同步关键字实现,被称为同步容器,同步容器还有Vector、Stack和Hashtable,这三个容器不是基于包装类实现,但是也是基于synchronized实现,对这三个容器遍历同样要加锁包装互斥。
而且同步容器因为所有方法都用synchronized来保证互斥,串行度太高了,所有性能差
并发容器注意事项
并发容器也可以分为四大类:List、Map、Set和Queue
(一)List
List只有一个实现类CopyOnWriteArrayList,意思是写的时候会把共享变量新复制一份出来,这样好处是读操作完全无锁。
原理:CopyOnWriteArrayLIst内部维护了一个数组,成员变量array指向这个数组
增加操作时候,CopyOnwriteArrayList会复制出新数组进行增加操作,在旧数组进行写操作
这里有两个不足:1、CopyOnWriteArrayList适合写操作少的场景,而且要容忍读写的短暂不一致;
2、CopyOnWirteAyyayList迭代器只是只读,不支持增删该,因为读的是旧的数组
(二)Map
Map有两个实现类ConcurrentHashMap(key无序)和ConcurrentSkipListMap(key有序,SkipList本身就是一种数据结构),并且两者key和value都不能为空,否则抛出空指针异常
(三)Set
Set两个实现接口CopyOnWriteArraySet和ConcurrentSkipListSet,这两个跟CopyOnWriteArrayList和ConcurrentSkiplIstMap一样的
(四)Queue
可以从两个维度分类:阻塞和非阻塞
阻塞队列:当队列为满的时,入队操作阻塞;单队列为空时候,出队操作阻塞。java并发包里阻塞队列用Blocking关键字识别
另一个维度:单端与双端
单端指的是队尾入列,队首出队,单端队列使用Queue标识;
双端指的是队首队尾皆可入队出队,双端队列使用Deque标识;
将Queue细分为四大类
1、单端阻塞队列:其实现有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue和DelayQueue。
内部一般会持有一个队列,这个队列可以是数组(其实现是 ArrayBlockingQueue)也可以是链表(其实现是 LinkedBlockingQueue);甚至还可以不持有队列(其实现是 SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作。而 LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好;PriorityBlockingQueue 支持按照优先级出队;DelayQueue 支持延时出队。

2、双端阻塞队列:实现是LinkedBlockingDeque

3、单端非阻塞队列:实现是ConcurrentLinkedQueue
4、双端非阻塞队列:实现是ConcurrentLinkedDeque
使用队列时候,一般不建议使用无界队列,数据大了后容易导致OOM(程序申请内存过大,虚拟机无法满足我们,然后自杀了),这些Queue里只有ArrayBlockingQueue和LinkedBlockingQueue支持有界,其它要考虑OOM
java1.8之前使用HashMap.put()可能导致cpu飙升到100%
原子类:无锁工具类的典范
累加器例子:
public class Test{
long count = 0;
void add10K(){
int idx = 0;
while(idx++<1000){
count +=1;
}
}
}
add10k()这个方法不是线程安全的,两个问题:
1、变量count 的可见性,该问题可用volatile来解决;
2、count+=1的原子性上,之前采用互斥锁方案,现在还有种方案:无锁方案
public class Test{
AtomicLong count = new AtomicLong(0);
void add10K(){
int idx = 0;
while(idx++ < 1000){
count.getAndIncrement();//加1操作
}
}
}
这样用的无锁方案最大好处是性能。互斥锁为了保证互斥性,会执行加锁、解锁操作,而这些操作会消耗性能;同时拿不到锁的线程进入阻塞状态进而触发线程切换,线程切换也消耗性能,无锁方案完美解决这些。、
无锁方案实现原理
CPU为了解决高并发问题,提供了CAS指令(CAS=Compare And Swap,即“比较并交换”)。CAS指令包括三个参数:共享变量内存地址A,用于比较的值B和共享变量新值C,只有A处值=B,才能把A的值更新为C。作为一条CPU指令,CAS指令本事能够保证原子性
模拟代码
class SimulatedCAS{
int count;
synchronized int cas(int expect,int newValue){
//读目前count值
int curValue = count;
//比较目前count值==期望值
if(curValue == expect){
//如果是,更新curValue值
count = newValue;
}
//返回写入值
reutrn curValue;
}
}
这段代码结合count +=1来看的话,就是+1后的值为newValue,去覆盖curValue的时候,要去对比一下看原来的值有没有被修改
自旋 = 循环尝试,“CAS+自旋”的实现方案,写入时候发现值被更改了就去重新读值,重复到值对了
public SimulatedCAS{
volatile int count;
//实现 count+=1
addOne(){
do{
newValue = count+1;//1
}while(count!=cas(count,newValue))//2
}
//模拟实现 CAS,
synchronized int cas(int expect,int newValue){
//读目前count值
int curValue = count;
//比价目前count值==期望值
if(curValue==expect){
//如果是,则更新count值
count = newValue;
}
//返回写入前的值
return curValue;
}
}
ABA问题
就是cas(count,newValue)返回值不等count,就代表在步骤1和步骤2之间,count值被修改过;如果cas()方法返回值等于count,那count值也有可能被T2修改为其它值,然后T3修改会原来的值,这就是ABA问题。这问题关心情况并不多,如原子化更新对象就要关心ABA问题
原子类概览
五类:原子化的基本数据类型、原子化的对象引用类型、原子化数组、原子化对象属性更新器和原子化的累加器
1、原子化的基本数据类型
相关实现有AotmicBoolean、AtomicInteger和AtomicLong
getAndIncrement() // 原子化 i++
getAndDecrement() // 原子化的 i--
incrementAndGet() // 原子化的 ++i
decrementAndGet() // 原子化的 --i
// 当前值 +=delta,返回 += 前的值
getAndAdd(delta)
// 当前值 +=delta,返回 += 后的值
addAndGet(delta)
//CAS 操作,返回是否成功
compareAndSet(expect, update)
// 以下四个方法
// 新值可以通过传入 func 函数来计算
getAndUpdate(func)
updateAndGet(func)
getAndAccumulate(x,func)
accumulateAndGet(x,func)
2、原子化的对象引用类型
实现有AtomicReference、AtomicStampedReference和AtomicMarkableReference。AtomicReference提供方法跟原子化基本数据类下差不多,而AtomicStampedReference和AtomicMarkableReference会通过增加版本号来解决ABA问题。
3、原子化数组
实现类:AtomictIntegerArray、AtomicLongArray和AtomicReferenceArray,用这些原子类可以原子化更新数组里的元素,提供方法跟原子化基本数据类型比就是多了个数组的索引参数
4、原子化对象属性更新器
实现有:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater,可以原子化地更新对象属性,都是用反射机制实现的,并且对象属性必须是volatile类型,否则newUpdater抛出IIlegalArtumentException 创建更新器方法如下
public static<U>
AtomicXXFieldUpdater<U>
newUpdater(Class<U> tclass,String fieldName)
5、原子化累加器
DoubleAccumulator、DoubleAdder、LongAccumulator和LongAdder,这四个仅仅用来执行累加操作,比原子化基本数据类型速度更快,但不支持compareAndSet()方法
总结:原子类虽然性能好,但大多数方法是针对一个共享变量的,如果要解决多个共享变量的原子性问题,还是建议使用互斥锁方案
Executor与线程池
使用线程池原因:
创建对象只是在JVM堆里分配一块内存而已,而创建线程需要调用到操作系统内核的API,然后操作系统为线程分配一系列资源。所以线程是重量级对象,要避免频繁创建和销毁,采用的办法就是线程池
生产者-消费者:
目前线程池普遍采用生产者-消费者模式
/ 简化的线程池,仅用来说明工作原理
class MyThreadPool{
// 利用阻塞队列实现生产者 - 消费者模式
BlockingQueue<Runnable> workQueue;
// 保存内部工作线程
List<WorkerThread> threads
= new ArrayList<>();
// 构造方法
MyThreadPool(int poolSize,
BlockingQueue<Runnable> workQueue){
this.workQueue = workQueue;
// 创建工作线程
for(int idx=0; idx<poolSize; idx++){
WorkerThread work = new WorkerThread();
work.start();
threads.add(work);
}
}
// 提交任务 将人物添加到workQueue
void execute(Runnable command){
workQueue.put(command);
}
// 工作线程负责消费任务,并执行任务
class WorkerThread extends Thread{
public void run() {
// 循环取任务并执行
while(true){ ①
Runnable task = workQueue.take();
task.run();
}
}
}
}
/** 下面是使用示例 **/
// 创建有界阻塞队列
BlockingQueue<Runnable> workQueue =
new LinkedBlockingQueue<>(2);
// 创建线程池
MyThreadPool pool = new MyThreadPool(
10, workQueue);
// 提交任务
pool.execute(()->{
System.out.println("hello");
});
如何使用java中的线程池
java提供的线程池相关的工具类镇南关,最核心的是ThreadPoolExecutor,下面是构造函数
/**
corePoolSize表示线程池最小线程数
maximumPoolSize表示线程池最大线程数
keepAliveTime&unit表示规定的“一段空闲时间”,如果一个线程空闲了这个“一端空闲时间”这么久,且线程池线程数大于corePoolSize,该空闲线程会被回收
workQueue表示工作队列
threadFactory自定义如何查创建线程,例如给线程指定名字
handler 自定义任务拒绝策略,如果线程池里所有线程都在忙碌且工作队列也满了,此时提交任务,线程池就会拒绝接收。
CallerRunsPolicy:提交任务的线程自己去执行该任务
AbortPolicy:默认的拒绝策略,会throws RejectedExecutionException 运行异常
DiscardPolicy:直接丢弃任务,不抛出异常
DiscardOldestPolicy:丢弃最老的任务,把最早进入队列的任务丢弃,加入新任务到工作队列里
allowCoreThreadTimeOut(boolean value)可以让所有线程都支持超时,如果项目很闲,会将项目组的成员撤走
**/
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
无界队列容易导致OOM,所有不建议使用Executors,因为它听供很多默认方法是LinkedBlockingQueue,建议使用有界队列
异常处理
使用ThreadPoolExecutor对象的execute()方法提交任务时候遇到异常会导致任务线程终止但却收不到通知,需要捕获该异常
try{
//业务逻辑
}catch(RuntimeException x){
//按需处理
}catch(Throwable x){
//按需处理
}
给线程池创建的线程起名字
默认线程池创建的线程名字类似pool-1-thread-2这样,下面的方法可以给线程池里的线程指定名字:
//1、给线程池设置名称前缀
ThreadPoolTaskExecutor threadPoolTashExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setThreadNamePrefix("CUSTOM_NAME_PREFIX");
//2、在ThreadFactory中自定义名称前缀
class CustomThreadFactory implements TreadFactory{
@Override
public Thread newThread(Runnable r){
Thread thread = new Thread("CUSTOM_NAME_PREFIX");
reutrn thread;
}
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10,100,120,TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
new CustomThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
}
Future:用多线程实现“烧水泡壶”
上面使用了ThreadPoolExecutor的void execute(Runnable comand)方法提交了任务,但是没有获取任务的执行结果,那要如何获取任务执行结果呢
获取任务执行结果
通过ThreadPoolExecutor提供的3个submit()方法和1个FutureTask工具类来支持获取任务执行结果
3个submit()方法
//提交Runnable任务 返回Future只可以断言任务结束,类似Thread.join()
Future<?> submit(Runnable task);
//提交Callable任务 通过返回的Future调用get()方法来获取任务执行结果
<T> Future<T> submit(Callable<T> task);
//提交Runnable任务及结果引用
<T> Future<T> submit(Runnbale task,T result);
Future接口5个方法
//取消任务
boolean cancel(boolean mayInterruptIfRunning);
//判断任务是否已取消
boolean isCancelled();
//判断任务十分已结束
boolean isDone();
//获得任务执行结果 阻塞式的,会等任务执行完先
get();
//获得任务执行结果,支持超时 阻塞式的,会等任务执行完先
get(long timeout,TimeUnit unit);
提交Runnable任务及结果引用的具体代码
ExecutorService executor
= Executors.newFixedThreadPool(1);
// 创建 Result 对象 r
Result r = new Result();
r.setAAA(a);
// 提交任务
Future<Result> future =
executor.submit(new Task(r), r);
Result fr = future.get();
// 下面等式成立
fr === r;
fr.getAAA() === a;
fr.getXXX() === x
class Task implements Runnable{
Result r;
// 通过构造函数传入 result
Task(Result r){
this.r = r;
}
void run() {
// 可以操作 result
a = r.getAAA();
r.setXXX(x);
}
}
FutureTask工具类
该工具类实现了Future和Runnable接口,所以Future对象作为可作为任务提交给ThreadPoolExecutor去执行,也可以直接被Thread执行。
下面是FutrueTask对象提交给ThreadPoolExecutor去执行
//创建FutureTask
Future<Integer> futrueTask = new FutureTask<>(()->12);
//创建线程池
ExecutorService es = Executors.newCachedThreadPool();
//提交 FutureTask
es.submit(futureTask);
//获取计算结果
Integer result = futureTask.get();
FutureTask对象直接被Thread执行的代码如下
//创建FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(()->1+2);
//创建线程并启动
Thread T1 = new Thread(futureTask);
T1.start();
//获取计算结果
Integer result = futureTask.get();
最优的烧水泡茶程序
烧水泡茶最优工序
烧水泡茶最优分工方案

// 创建任务 T2 的 FutureTask
FutureTask<String> ft2
= new FutureTask<>(new T2Task());
// 创建任务 T1 的 FutureTask
FutureTask<String> ft1
= new FutureTask<>(new T1Task(ft2));
// 线程 T1 执行任务 ft1
Thread T1 = new Thread(ft1);
T1.start();
// 线程 T2 执行任务 ft2
Thread T2 = new Thread(ft2);
T2.start();
// 等待线程 T1 执行结果
System.out.println(ft1.get());
// T1Task 需要执行的任务:
// 洗水壶、烧开水、泡茶
class T1Task implements Callable<String>{
FutureTask<String> ft2;
// T1 任务需要 T2 任务的 FutureTask
T1Task(FutureTask<String> ft2){
this.ft2 = ft2;
}
@Override
String call() throws Exception {
System.out.println("T1: 洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T1: 烧开水...");
TimeUnit.SECONDS.sleep(15);
// 获取 T2 线程的茶叶
String tf = ft2.get();
System.out.println("T1: 拿到茶叶:"+tf);
System.out.println("T1: 泡茶...");
return " 上茶:" + tf;
}
}
// T2Task 需要执行的任务:
// 洗茶壶、洗茶杯、拿茶叶
class T2Task implements Callable<String> {
@Override
String call() throws Exception {
System.out.println("T2: 洗茶壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T2: 洗茶杯...");
TimeUnit.SECONDS.sleep(2);
System.out.println("T2: 拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return " 龙井 ";
}
}
// 一次执行结果:
T1: 洗水壶...
T2: 洗茶壶...
T1: 烧开水...
T2: 洗茶杯...
T2: 拿茶叶...
T1: 拿到茶叶: 龙井
T1: 泡茶...
上茶: 龙井
下面代码可以改进,由于是串行的,性能慢
//向电商S1询价,并保存
r1 = getPriceByS1();
save(r1);
//向电商S2询价,并保存
r2 = getPriceByS2();
save(r2);
//向电商S3询价,并保存
r3 = getPriceByS();
save(r3);
思路:现在是主线程串行完成3个任务,第一个任务执行时候,其它两个只能等待,可以用futuretask,三个任务改成futuretask并行执行
CompletetableFuture:异步编程
异步化代码
//下面两个都是耗时操作
doBizA();
doBizB();
//并行方案
new Thread(()->doBizA()).start();
new Thread(()->doBizA()).start();
异步化:利用多线程优化性能这个核心方案得以实施的基础
CompletetableFuture核心优势
这里再用烧水泡茶程序做例子
// 任务 1:洗水壶 -> 烧开水
CompletableFuture<Void> f1 =
CompletableFuture.runAsync(()->{
System.out.println("T1: 洗水壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T1: 烧开水...");
sleep(15, TimeUnit.SECONDS);
});
// 任务 2:洗茶壶 -> 洗茶杯 -> 拿茶叶
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(()->{
System.out.println("T2: 洗茶壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T2: 洗茶杯...");
sleep(2, TimeUnit.SECONDS);
System.out.println("T2: 拿茶叶...");
sleep(1, TimeUnit.SECONDS);
return " 龙井 ";
});
// 任务 3:任务 1 和任务 2 完成后执行:泡茶
CompletableFuture<String> f3 =
f1.thenCombine(f2, (__, tf)->{
System.out.println("T1: 拿到茶叶:" + tf);
System.out.println("T1: 泡茶...");
return " 上茶:" + tf;
});
// 等待任务 3 执行结果
System.out.println(f3.join());
void sleep(int t, TimeUnit u) {
try {
u.sleep(t);
}catch(InterruptedException e){}
}
// 一次执行结果:
T1: 洗水壶...
T2: 洗茶壶...
T1: 烧开水...
T2: 洗茶杯...
T2: 拿茶叶...
T1: 拿到茶叶: 龙井
T1: 泡茶...
上茶: 龙井
创建CompletableFuture对象
主要靠4个静态方法,默认CompletetableFuture会使用公共的ForJoinPool线程池,该线程池默认创建线程数是CPU核素(也可以通过JVM option:-Djava.util.concurrent.ForkJoinPool.common.parallelism来设置ForkJoinPool线程池的线程数)。要根据业务类型创建不同的线程池,互不干扰,如果所有任务共享同一个线程池,一旦有任务进行很忙I/O操作,会造成线程池的里线程阻塞
//使用你默认线程池
static CompletableFuture<Void> runAsync(Runnable runnable) //Runnable接口的run()没有返回方法
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)//Supplier结果的get方法有返回值
//可以指定线程池参数
static CompletableFuture<Void> runAsync(Runnable runnable,Executor executor);
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier,Executor executor);
创建好CompletableFuture对象之后,会自动异步执行runnable.run()或者supplier.get()方法。因为CompletableFutrue类实现了Future接口,通过该接口,可以解决:1、异步操作什么时候结束2、如何获取异步操作的执行结果
理解CompletionStage接口
任务是有时序关系的,比如串行关系、并行关系、汇聚关系等。
在烧水泡茶例子中,洗水壶和烧开水就是串行关系

洗水壶、烧开水和洗茶壶、洗茶杯这两组任务是并行关系
 烧开水、拿茶叶和泡茶就是汇聚关系,而且是AND聚合关系(烧开水和拿茶叶完成才能进行泡茶)。OR聚合关系指其中一个完成就可以执行当前任务。
烧开水、拿茶叶和泡茶就是汇聚关系,而且是AND聚合关系(烧开水和拿茶叶完成才能进行泡茶)。OR聚合关系指其中一个完成就可以执行当前任务。
 1、描述串行关系
1、描述串行关系
主要是CompletionStage接口里面thenApply、thenAccept、thenRunn和thenCompose这是个系列的接口
thenApply系列函数里参数fn的类型是接口Function
thenAccept系列方法里参数consumer的类型接口Consumer,这个接口里与CompletionStage相关的方法是void accept(T t),该方法支持参数不返回值,所有thenAccept系列方法返回是CompletionStage
thenRun系列方法里action的参数是Runnable,所以action不能接收尝试不返回值,所有thenRun系列方法返回的也是CompletionStage
这些方法里Async代表是异步执行fn、consumer或者actoin。而thenCompose系列方法会新创建出一个子流程,最终结果和thenApply系列一样
CompletionStage<R> thenApply(fn);
CompletionStage<R> thenApplyAsync(fn);
CompletionStage<Void> thenAccept(consumer);
CompletionStage<Void> thenAcceptAsync(consumer);
CompletionStage<Void> thenRun(action);
CompletionStage<Void> thenRunAsync(action);
CompletionStage<R> thenCompose(fn);
CompletionStage<R> thenComposeAsync(fn);
thenApply()示例代码
/**
先通过supplyAsync()启动异步流程,之后是两个串行操作,虽然是异步流程,单任务123却是串行执行,2依赖1执行结果,3依赖2执行结果
**/
CompletableFuture<String> f0 =
CompletableFuture.supplyAsync(
() -> "Hello World") //①
.thenApply(s -> s + " QQ") //②
.thenApply(String::toUpperCase);//③
System.out.println(f0.join());
// 输出结果
HELLO WORLD QQ
2、描述AND汇聚关
CompletionStage接口里描述AND汇聚关系,主要是thenCombine、thenAcceptBoth和runAfterBoth系列接口,
CompletionStage<R> thenCombine(other, fn);
CompletionStage<R> thenCombineAsync(other, fn);
CompletionStage<Void> thenAcceptBoth(other, consumer);
CompletionStage<Void> thenAcceptBothAsync(other, consumer);
CompletionStage<Void> runAfterBoth(other, action);
CompletionStage<Void> runAfterBothAsync(other, action);
3、描述OR汇聚关系
CompletoinStage接口里描述OR汇聚关系,主要是applyToEither、acceptEither和runAfterEither系列接口
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
如何使用applyToEither()来描述OR汇聚关系
CompletableFuture<String> f1 =
CompletableFuture.supplyAsync(()->{
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(()->{
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f3 =
f1.applyToEither(f2,s -> s);
System.out.println(f3.join());
异常处理
fn、consumer、actoin它们的核心方法不允许抛出检查异常,但是无法限制他们抛出运行异常,下面这些方法支持进异常处理和串行操作一样,都支持链式编程
CompletionStage exceptionally(fn);//用来处理异常,类似catch{}
CompletionStage<R> whenComplete(consumer);//类似finally{} 不支持返回结果 无论是否发生异常都会执行回调函数consumer和handle()中的回调函数fn
CompletionStage<R> whenCompleteAsync(consumer);
CompletionStage<R> handle(fn);//类似finally{}//类似finally{} 支持返回结果
CompletionStage<R> handleAsync(fn);
例子
CompletableFuture<Integer>
f0 = CompletableFuture
.supplyAsync(()->7/0))
.thenApply(r->r*10)
.exceptionally(e->0);
System.out.println(f0.join());
CompletionService:批量执行异步操作
用"ThreadExecutorPool+Future"方案优化询价应用
//创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
//异步向电商S1询价
Future<Integer> f1 = executor.submit(()->getPriceByS1());
//异步向电商S2询价
Future<Integer> f2 = executor.submit(()->getPriceByS2());
//异步向电商S3询价
Future<Integer> f3 = executor.submit(()->getPriceByS3());
//获取电商S1报价并保存
r = f1.get();
executor.execute(()->save(r));
//获取电商S2报价并保存
r = f2.get();
executor.execute(()->save(r));
//获取电商S3报价并保存
r = f3.get();
executor.execute(()->save(r));
这段代码有个缺点就是保存串行,如果f2比f1很快查出,也没办法先保存S2报价,因为卡在了S1报价保存这里。解决办法是增加个阻塞队列,获取到S1、S2和S3的报价都进入阻塞队列,然后在主线程从消费阻塞队列,这样就实现先到先保存了
//创建阻塞队列
BlockingQueue<Interger> bq = new LinkedBlockingQueue<>();
//电商S1报价异步进入阻塞队列
executor.execute(()->bq.put(f1.get()));
//电商S2报价异步进入阻塞队列
executor.execute(()->bq.put(f2.get()));
//电商S3报价异步进入阻塞队列
executor.execute(()->bq.put(f3.get()));
//异步保存所有报价
for(int i=0;i<3;i++){
Integer r = bq.take():
executor.execute(()->save(r));
}
而在实际项目中,JAVA SDK并发包提供了CompletionService来帮忙解决先到报价先处理的问题,而且代码更简练。其原理也是内部维护了阻塞对了,任务结束就把任务结果加到阻塞队列去,不同的是这里是把任务结果加到阻塞队列,上面是把任务最终执行结果放入阻塞队列
创建CompletionService
其接口实现类是ExecutorCompletionService,构造方法:
//默认使用无界的LinkedBlockingQueue
ExecutorCompletionService(Executor executor);
//任务执行结果Future对象就是加入到completionQueue中
ExecutorCompletionService(Executor executor,BlockingQueue<Futur<V>> completionQueue);
使用例子:
//创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
//创建CompletionService
CompletionService<Integer> cs = new ExecutoCompletionService<>(executor);
//异步向电商1询价
cs.submit(()->getPriceByS1());
//异步向电商2询价
cs.submit(()->getPriceByS2());
//异步向电商3询价
cs.submit(()->getPriceByS3());
//将异步结果保存到数据库
for(int i=0;i<3;i++){
//take()方法获取的是Future对象,再调用get()方法就能获取结果
Integer r = cs.take().get();
executor.execute(()->save(r));
}
CompletinService接口说明
有5个
Future<V> submit(Callable<V> task);
//类似ThreadPoolExecutor的 Future submit(Runnable task,T result)
Future<V> submit(Runnable task,V result);
//类似阻塞队列,队列空的时候取出被阻塞
Future<V> tkae() throws InterruptedExceptions;
//如果阻塞队列为空,则返回null值
Future<V> pool();
//支持以超时方式获取并移除阻塞队列头部第一个元素,如果超过了等待时间,队列还是空,则返回null
Future<V> pool(long timeout,TimeUnit unit)thorws InterruptedException;
利用CompletionService实现Dubbo的Forking Cluster
Dubbo的Forking的集群模式支持并行调用多个查询服务,只要有一个成功返回结果,整个服务就能返回。比如用一个地址坐标去调用三个地图服务商api,只要有一个返回了正确结果r,就可以直接采用r了,这种集群模式可以容忍2个地图服务商异常,缺点是消耗资源偏多。
geocoder(addr){
//并行执行以下3个查询服务
r1 = geocoderByS1(addr);
r2 = geocoderByS1(addr);
r3 = geocoderByS2(addr);
//只要r1,r2,r3有一个返回
//则返回
return r1|r2|r3;
}
用CompletionService实现这效果
//创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
//创建CompletionService
CompletionService<Integer> cs = new ExecutorCompleTionService<>(executor);
//用于保存Future对象
List<FUture<Integer>> futures = new ArrayList<>(3);
//提交异步任务,并保持future到futres
futures.add(cs.submit(()->geocoderByS1()));
futures.add(cs.submit(()->geocoderByS2()));
futures.add(cs.submit(()->geocoderByS3()));
//获取最快返回的任务执行结果
Integer r = 0;
try{
for(int i=0;i<3;i++){
r = cs.take().get();
//简单通过判断空检查是否成功返回
if(r1!=null){break;}
}
}finally{
//取消所有任务
for(Future<Integer> f : futures)
f.cancel(true);
}
//执行结果
return r
计算出最低价并返回
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 创建 CompletionService
CompletionService<Integer> cs = new
ExecutorCompletionService<>(executor);
// 异步向电商 S1 询价
cs.submit(()->getPriceByS1());
// 异步向电商 S2 询价
cs.submit(()->getPriceByS2());
// 异步向电商 S3 询价
cs.submit(()->getPriceByS3());
// 将询价结果异步保存到数据库
//return m需要等待三个线程执行完成
AtomicReference<Integer> m = new AtomicReference<>(Integer.MAX_VALUE);
CountDownLatch latch = new CountDownLatch(3);
for(int i=0;i<3;i++){
executor.execute(()->{
Integer r = null;
try{
r=cs.take().get();
}catch(Exception e){
save(r);
m.set(Integer.min(m.get(),r));
latch.countDown();
}
});
latch.await();
return m
}
Fork/Join 单机版的MapReduce
之前的线程池、Future、CompletableFuture和CompletionService都是在任务角度来解决并发问题.。对于简单任务,可以通过“线程池+Future”的方案来解决;如果任务之间有聚合关系,无论是AND聚合还是OR聚合,都可以通过CompletableFuture来解决;而批量的并行任务,则可以通过CompletionService来解决
用现实世界工作流程图描述了并发编程领域简单的并行任务、聚合任务和批量并行任务,从上到下为简单并行、聚合任务和批量并行任务

还有一种任务模型:分治,指的是把一个复杂的问题分解成多个相似的值问题,然后再把子问题分解成更小的子问题,直接子问题简单到可以直接求解,在算法领域有分治算法(归并排序、快速排序和二分法查找);大数据领域知名的计算机框架MapReduce背后思想也是分治。Java 并发包里提供了 Fork/Join的并行计算框架来支持分治这种任务模型
分治模型
有两个阶段:
任务分解就是将任务迭代地分解为子任务直到子任务能直接计算出结果;
结果合并逐层合并子任务的结果,直到最终结果

Fork/Join的使用
Fork/Join是并行计算框架,Fork对应任务分解,Join对应结果合并。框架分为两部分,一是任务分治任务的线程池ForkJoinPool,另一部分是分治任务ForkJoinTask,两者关系类似ThreadExecutor和Runnable的关系。
ForkJoinTask是一个抽象类,最核心方法是fork()和join(),fork会异步执行一个子任务,而jion()会阻塞当前线程来等待子任务的执行结果。两个子类RecursiveAction和RecursiveTask,这两个递归方式来处理分支任务
static void main(String[] args){
// 创建分治任务线程池
ForkJoinPool fjp =
new ForkJoinPool(4);
// 创建分治任务
Fibonacci fib =
new Fibonacci(30);
// 启动分治任务
Integer result =
fjp.invoke(fib);
// 输出结果
System.out.println(result);
}
// 递归任务
static class Fibonacci extends
RecursiveTask<Integer>{
final int n;
Fibonacci(int n){this.n = n;}
protected Integer compute(){
if (n <= 1)
return n;
Fibonacci f1 =
new Fibonacci(n - 1);
// 创建子任务
f1.fork();
Fibonacci f2 =
new Fibonacci(n - 2);
// 等待子任务结果,并合并结果
return f2.compute() + f1.join();
}
}
ForkJoinPool工作原理
模拟MapReduce统计单词数量
static void main(String[] args){
String[] fc = {"hello world",
"hello me",
"hello fork",
"hello join",
"fork join in world"};
// 创建 ForkJoin 线程池
ForkJoinPool fjp =
new ForkJoinPool(3);
// 创建任务
MR mr = new MR(
fc, 0, fc.length);
// 启动任务
Map<String, Long> result =
fjp.invoke(mr);
// 输出结果
result.forEach((k, v)->
System.out.println(k+":"+v));
}
//MR 模拟类
static class MR extends
RecursiveTask<Map<String, Long>> {
private String[] fc;
private int start, end;
// 构造函数
MR(String[] fc, int fr, int to){
this.fc = fc;
this.start = fr;
this.end = to;
}
@Override protected
Map<String, Long> compute(){
if (end - start == 1) {
return calc(fc[start]);
} else {
int mid = (start+end)/2;
MR mr1 = new MR(
fc, start, mid);
mr1.fork();
MR mr2 = new MR(
fc, mid, end);
// 计算子任务,并返回合并的结果
return merge(mr2.compute(),
mr1.join());
}
}
// 合并结果
private Map<String, Long> merge(
Map<String, Long> r1,
Map<String, Long> r2) {
Map<String, Long> result =
new HashMap<>();
result.putAll(r1);
// 合并结果
r2.forEach((k, v) -> {
Long c = result.get(k);
if (c != null)
result.put(k, c+v);
else
result.put(k, v);
});
return result;
}
// 统计单词数量
private Map<String, Long>
calc(String line) {
Map<String, Long> result =
new HashMap<>();
// 分割单词
String [] words =
line.split("\\s+");
// 统计单词数量
for (String w : words) {
Long v = result.get(w);
if (v != null)
result.put(w, v+1);
else
result.put(w, 1L);
}
return result;
}
}
并发工具类模块热点问题
while(true)
下面代码有两个问题,while为true引起死循环和活锁问题
/**
* 本意通过破坏死锁条件:占有且等待,一次申请所有资源
* 判断是否存在死锁问题
*
*/
public class Account {
private int balance;
private final Lock lock = new ReentrantLock();
//转账
void transfer(Account tar,int amt){
//while中没有break条件导致死循环 除此之外还存在活锁问题
while(true){
if(this.lock.tryLock()){
try{
if(tar.lock.tryLock()){
try{
this.balance -= amt;
tar.balance += amt;
//新增加brak,退出循环
break;
}finally {
tar.lock.unlock();
}
}
//新增一个随机时间避免活锁
int waitTime = new Random().nextInt(100);
Thread.sleep(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
} finally{
this.lock.unlock();
}
}
}
}
}
还有个隐蔽的
/**
* 合理库存的原子化实现
* 这里仅仅实现了设置库存上限setUpper()方法
*/
public class SafeWM {
class WMRange{
final int upper;
final int lower;
WMRange(int upper,int lower){
this.upper=upper;
this.lower=lower;
}
}
final AtomicReference<WMRange> rf = new AtomicReference(
new WMRange(0,0)
);
//设置库存上限
void setUpper(int v){
WMRange nr;
WMRange or;
//这里or赋值在循环之外,所以每次循环or的值都不会变化
//WMRange or = rf.get();
do{
//每个回合都获取旧值
or = rf.get();
//检查参数合法性
if(v < or.lower){
throw new IllegalArgumentException();
}
nr = new WMRange(v,or.lower);
}while (!rf.compareAndSet(or,nr));
}
}
signalAll()会安全些
推荐使用signalAll()来代替signal(),Dubbo已经用signalAll()来代替了。
//RPC结果返回时调用该方法
private void doReceived(Response res){
lock.lock();
try{
response = res;
done.signalAll();
}finally{
lock.unlock();
}
}
共享线程池要用有福同享有难同当
//采购订单
PurchersOrder po;
CompletableFuture<Boolean> cf = Completable.supplyAsync(()->{
//在数据库查询规则
return findRuleByJdbc();
}).thenApply(r->{
//规则校验
return check(po,r);
});
Boolean isOk = cf.join();
线上问题定位的利器:线程栈dump
为了方便分析线程定位问题,需要给线程赋予有意义名字,可以通过TreadFactory给线程池中的线程赋予有意义的名字,也可以在执行run()方法时候通过Thread.currentThread().setName()来给线程赋予一个更贴近业务的名字。