Redsi存储结构和数据复制
redis被很多的公司使用,这一篇主要针对redis的数据结构和数据复制,因为这二块是redis比较核心的地方,当然redis的slot和哨兵这些也很优秀,不在本篇的讨论范围。
1:redis的组织形式
众所周知,实现索引的形式一般:b+树或者hash索引,redis大家所熟知的key,value的结构,也就是后者,这种结构一般我们称之为字典,在java当中我们也不陌生,HashMap和HashTable也是实现字典的具体形式,redis如何实现字典的呢?下面我们进入正题,redis的内存组织形式。

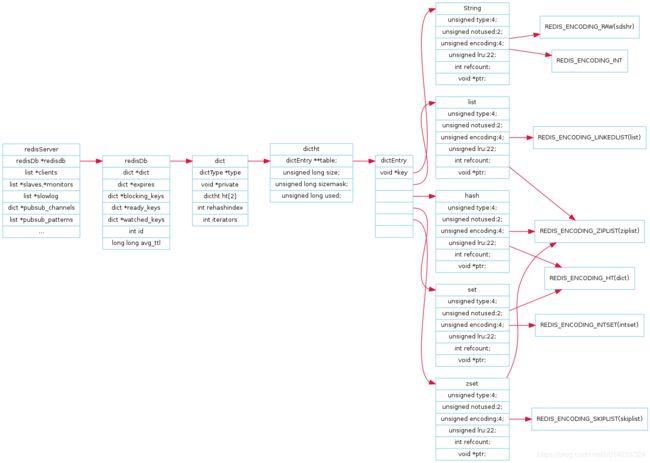 上面贴了二张图,redis的整体的组织形式是上面的形式,下面我将主要针对这二张图进行介绍:
上面贴了二张图,redis的整体的组织形式是上面的形式,下面我将主要针对这二张图进行介绍:
1.1:redisServer
struct redisServer {
/* General */
pid_t pid; /* Main process pid. */
char *configfile; /* Absolute config file path, or NULL */
char *executable; /* Absolute executable file path. */
char **exec_argv; /* Executable argv vector (copy). */
int hz; /* serverCron() calls frequency in hertz */
redisDb *db;
dict *commands; /* Command table */
dict *orig_commands; /* Command table before command renaming. */
aeEventLoop *el;
unsigned int lruclock; /* Clock for LRU eviction */
int shutdown_asap; /* SHUTDOWN needed ASAP */
int activerehashing; /* Incremental rehash in serverCron() */
int active_defrag_running; /* Active defragmentation running (holds current scan aggressiveness) */
char *requirepass; /* Pass for AUTH command, or NULL */
char *pidfile; /* PID file path */
int arch_bits; /* 32 or 64 depending on sizeof(long) */
int cronloops; /* Number of times the cron function run */
char runid[CONFIG_RUN_ID_SIZE+1]; /* ID always different at every exec. */
int sentinel_mode; /* True if this instance is a Sentinel. */
size_t initial_memory_usage; /* Bytes used after initialization. */
int always_show_logo; /* Show logo even for non-stdout logging. */
/* Modules */
dict *moduleapi; /* Exported APIs dictionary for modules. */
list *loadmodule_queue; /* List of modules to load at startup. */
int module_blocked_pipe[2]; /* Pipe used to awake the event loop if a
client blocked on a module command needs
....................
};由于代码太多,我只粘贴了一部分,redisServer从字面上的意思就是redis的实例,类似于我们的mysql实例,redis实例上会有很多的redisDb(单机才有多个,集群下只有一个),类似于我们 mysql的实例上会有很多的database,就是库的意思。redis默认创建16个库,默认选中第1个,下标为0;redisServer主要包含了这些内容:rdb,aof,configouration,netWorking,log等等内容。
1.2:redisDb
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;如果我们实例上的单个库数据太多的话,还是会影响查询的速度的,还有就是我们希望进行业务上的区分时,也需要多个库。这个时候我们就需要多个redisDb了,redisDb主要包含下面几个属性:
*dict:表示整个redisDb所包含的所有的key,value数据,也就是hashTable的数据,下面还有层级划分,这里不讨论。
*expires:所有过期的key
*blocking_keys:所有正在阻塞的key,也就是客户端发送的请求阻塞的key,比如BLPOP,value是client。
*ready_keys:当下次push命令发出时,服务器检查blocking_keys当中是否存在对应的key,如果存在,
则将key添加到ready_keys链表当中。
*watched_keys:用于实现watch命令。
这里需要说下redis阻塞的原理:
redis在blpop命令处理过程时,首先会去查找key对应的list,如果存在,则pop出数据响应给客户端。否则将对应的key push到blocking_keys数据结构当中,对应的value是被阻塞的client。当下次push命令发出时,服务器检查blocking_keys当中是否存在对应的key,如果存在,则将key添加到ready_keys链表当中,同时将value插入链表当中并响应客户端。
服务端在每次的事件循环当中处理完客户端请求之后,会遍历ready_keys链表,并从blocking_keys链表当中找到对应的client,进行响应,整个过程并不会阻塞事件循环的执行。所以, 总的来说,redis server是通过ready_keys和blocking_keys两个链表和事件循环来处理阻塞事件的。
1.3:dict
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表 实际是dictht
dictht ht[2];
// rehash 索引,第几个Hash桶处于rehash状态
// 当 rehash 不在进行时,值为 -1
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;dict顾名思义字典,这里其实不应该单独拿出来说,单独拿出来说事因为ht[2],这里为什么是2个?因为用过HashMap的都知道要扩容,但是redis是单线程的,如果你的ht很大,那么复制的过程是极其耗费时间的,所以不可能一下子就复制完全,这里就用到了渐进式hash扩容。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}从上面的代码也可以看出来,我简单的说一下:
1:dictIsRehashing(d)判断是不是处于rehash的状态,也即是判断rehashidx是不是等于-1,-1代表不是。
2:while(n-- && d->ht[0].used != 0) 一次rehash最多进行n个桶,ht[0]是不是为空,为空代表已经rehash完了。
3:assert判断size>rehashidx,这代表rehash是不是完毕了。
4:while(d->ht[0].table[d->rehashidx] == NULL) 这个while判断是不是已经空轮训了n个桶,
一次rehash最多允许空轮训n*10个空桶。
5:while(de) 移动单个桶的所有key到新的hashtable的ht[1];
6:if (d->ht[0].used == 0) 判断是不是rehash完毕,完毕代表ht=0
7:执行上面的6步直到n=0。
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
1.4:dictht和dictEntry
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;这个大家无比熟悉了,就是HashMap的实现底层的数据结构,hash表。dictEntry **table这个表示的就是hash表。

这里借用一下jdk1.8的 hash表,dictEntry代表的是一个key value,dictEntry里有一个属性 *next,
代表链的下一个相同hash值的dictEntry,这些dicEntry组成了一个hash桶。那么这里的value怎么进行保存的,
其实这里的value是一个redisObject对象,redisObject对象就是我们所熟知的value的数据结构对象了。
1.5:redisObject
typedef struct redisObject {
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//最后一次的访问时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
//指向实际值指针
void *ptr;
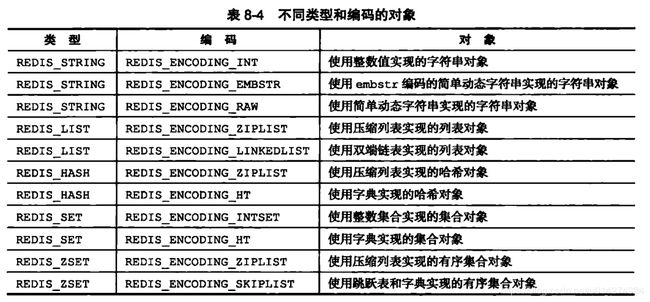
} robj;1:type 记录了对象的类型,所有的类型如下

2:encoding编码的数据结构,真正的储存结构。
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
每种类型的对象都至少使用了两种不同的编码,对象和编码的对应关系如下:
下面详细的介绍这一块的使用。
2:redis的数据结构
2.1:string
string类型可以分为:OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_RAW。
robj *tryObjectEncoding(robj *o) {
if (len <= 20 && string2l(s,len,&value)) {
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
if (o->encoding == OBJ_ENCODING_RAW &&
sdsavail(s) > len/10)
{
o->ptr = sdsRemoveFreeSpace(o->ptr);
}
}代码太多,只挑了一些关键的代码进行粘贴:
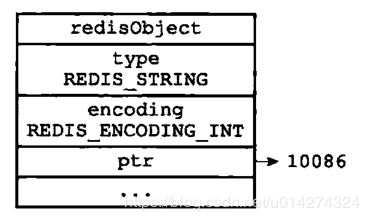
1:长度<=20,如果还是数字,将采用OBJ_ENCODING_INT的编码方式,在转成long成功时,又分为两种情况。
- 第一种情况:如果Redis的配置不要求运行LRU替换算法,且转成的long型数字的值又比较小(小于OBJ_SHARED_INTEGERS,在目前的实现中这个值是10000),那么会使用共享数字对象来表示。之所以这里的判断跟LRU有关,是因为LRU算法要求每个robj有不同的lru字段值,所以用了LRU就不能共享robj。shared.integers是一个长度为10000的数组,里面预存了10000个小的数字对象。这些小数字对象都是encoding = OBJ_ENCODING_INT的string robj对象。
- 第二种情况:如果前一步不能使用共享小对象来表示,那么将原来的robj编码成encoding = OBJ_ENCODING_INT,这时ptr字段直接存成这个long型的值。注意ptr字段本来是一个void *指针(即存储的是内存地址),因此在64位机器上有64位宽度,正好能存储一个64位的long型值。这样,除了robj本身之外,它就不再需要额外的内存空间来存储字符串值。
具体如下:
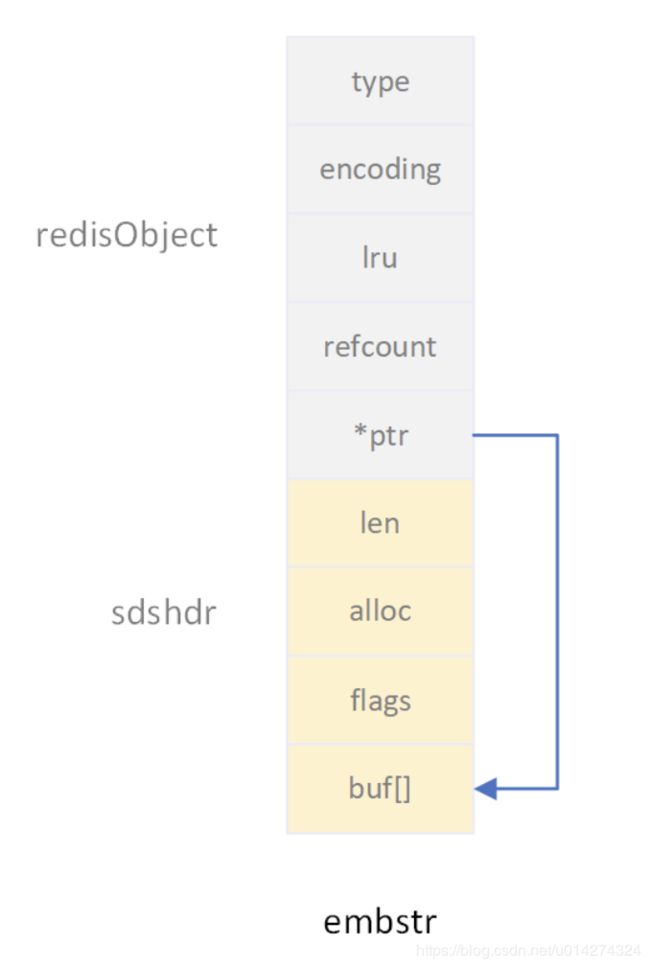
2:长度<=44,并且是字符串,数字的话要20<长度<=44,采用OBJ_ENCODING_EMBSTR的编码方式,对sds重新分配内存createEmbeddedStringObject,将robj和sds放在一个连续的内存块中分配,这样对于短字符串的存储有利于减少内存碎片。这个连续的内存块包含如下几部分:
- 16个字节的robj结构。
- 3个字节的sdshdr8头。
- 最多44个字节的sds字符数组。
- 1个NULL结束符。
加起来一共不超过64字节(16+3+44+1),因此这样的一个短字符串可以完全分配在一个64字节长度的内存块中。
3:长度大于44,采用OBJ_ENCODING_RAW的编码方式。
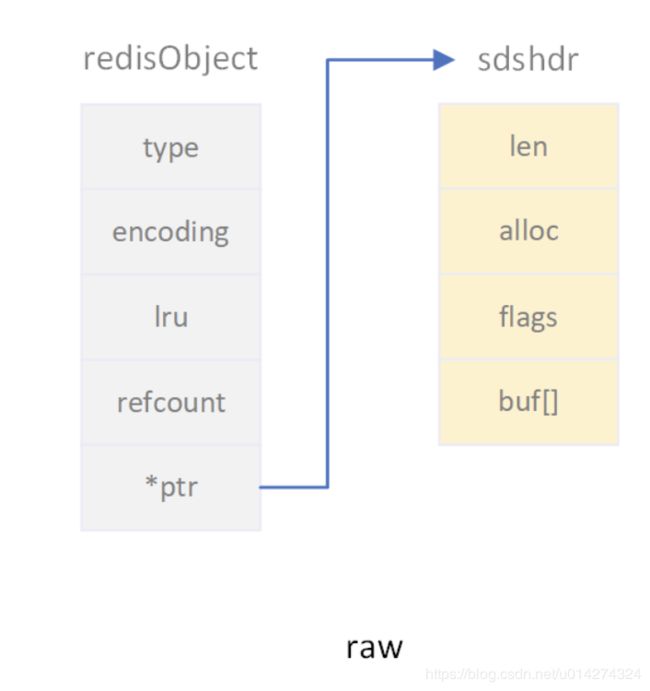
2和3采用的都是sds,这里说一下sds:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
//代表最大2^8 - 1
struct __attribute__ ((__packed__)) sdshdr8 {
//使用的长度
uint8_t len; /* used */
//当前字符数组总共分配的内存大小
uint8_t alloc; /* excluding the header and null terminator */
//标记使用的那种sdshdr
unsigned char flags; /* 3 lsb of type, 5 unused bits */
//保存数据的数组
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};为什么采用sds,而不采用原生的char[]数组,这就和java的数组和List一样,List更易用,不用关心扩容的操作,我们只需要往List添加元素就可以了,不用担心是不是满了,遍历也更加方便,但是这里有二种sds,一种是EMBSTR,一种是RAW,为什么是二种,在数据很小的话,采用EMBSTR,这种结构是连续的内存空间,一次内存分配就可以,可以加快数据的查询,当数据很大的时候需要采用RAW,单独分配一块内存空间存放sds,如果和原来的redisObject对象放到一块,分配连续的内存空间是一个问题。
2.2:List
List的类型主要是OBJ_ENCODING_QUICKLIST,OBJ_ENCODING_QUICKLIST可以说是由OBJ_ENCODING_LINKEDLIST和OBJ_ENCODING_ZIPLIST构成,只是意义上的,实际上有所不同。
void pushGenericCommand(client *c, int where) {
int j, pushed = 0;
//判断该key是否存在
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);
if (lobj && lobj->type != OBJ_LIST) {
addReply(c,shared.wrongtypeerr);
return;
}
for (j = 2; j < c->argc; j++) {
if (!lobj) {
//不存在就创建QuickList
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
//存在就push
listTypePush(lobj,c->argv[j],where);
pushed++;
}
addReplyLongLong(c, (lobj ? listTypeLength(lobj) : 0));
if (pushed) {
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
server.dirty += pushed;
}
void listTypePush(robj *subject, robj *value, int where) {
//判断是不是OBJ_ENCODING_QUICKLIST,不是就报错
if (subject->encoding == OBJ_ENCODING_QUICKLIST) {
int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;
value = getDecodedObject(value);
size_t len = sdslen(value->ptr);
quicklistPush(subject->ptr, value->ptr, len, pos);
decrRefCount(value);
} else {
serverPanic("Unknown list encoding");
}
}redis的list采用的是OBJ_ENCODING_QUICKLIST,主要分析下quicklist。
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previos entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;从上面的结构可以看出下面的结构:
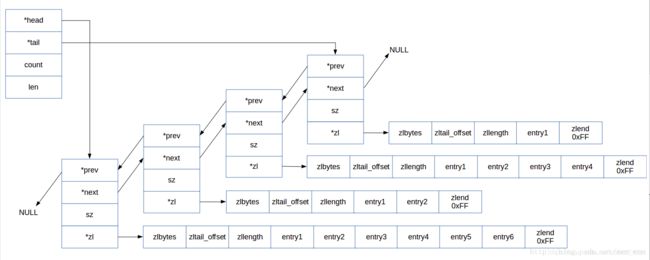
结合了双向链表和ziplist的优点,quicklist就应运而生了。
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
- 每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
- 每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
list-max-ziplist-size -2
我们来详细解释一下这个参数的含义。它可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
quickList是LinkedList和ZipList的结合体,quickList本身是个LinkedList,LinkedList的每个node上是zipList,所以我才说是这二个的结合体,真正保存数据的是ZipList,我们这里主要说下ZipList。
... 
| 属性 | 类型 | 长度字节 | 用途 |
| zlbytes | uint32_t | 4 | 记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算zlend的位置时使用。 |
| zltail_offset | uint32_t | 4 | 记录压缩列表尾节点距离压缩列表起始地址有多少个字节,通过这个偏移量,程序可以直接获得压缩列表的表尾节点地址,这个的作用就是能够从尾开始遍历到头。 |
| zllength | uint16_t | 2 | 记录了压缩列表的节点数量。当这个属性的值小于65535时(即:小于UINT16_MAX),这个属性的值就是压缩列表的节点数量,但是当这个值等于UINT16_MAX时,需要遍历整个压缩列表才能获得其节点数量 |
| entryX | 列表节点 | 不定 | 压缩表的各个节点,X代表数量不定 |
| zlend | uint8_t | 1 | 特殊常数值(OxFF,也就是255)。用于标记压缩列表的末端。 |
我们再来看一下每一个数据项
我们看到在真正的数据()前面,还有两个字段:
部分的长度)。也采用变长编码。
那么
- 如果前一个数据项占用字节数小于254,那么
- 如果前一个数据项占用字节数大于等于254,那么
为什么没有255的情况呢?
这是因为:255已经定义为ziplist结束标记
而
- |00pppppp| - 1 byte。第1个字节最高两个bit是00,那么
- |01pppppp|qqqqqqqq| - 2 bytes。第1个字节最高两个bit是01,那么
- |10__|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes。第1个字节最高两个bit是10,那么len字段占5个字节,总共使用32个bit来表示长度值(6个bit舍弃不用),最高可以表示2^32-1。需要注意的是:在前三种情况下,
都是按字符串来存储的;从下面第4种情况开始,开始变为按整数来存储了。 - |11000000| - 1 byte。
存储为2个字节的int16_t类型。 - |11010000| - 1 byte。
存储为4个字节的int32_t类型。 - |11100000| - 1 byte。
存储为8个字节的int64_t类型。 - |11110000| - 1 byte。
存储为3个字节长的整数。 - |11111110| - 1 byte。
存储为1个字节的整数。 - |1111xxxx| - - (xxxx的值在0001和1101之间)。这是一种特殊情况,xxxx从1到13一共13个值,这时就用这13个值来表示真正的数据。注意,这里是表示真正的数据,而不是数据长度了。也就是说,在这种情况下,后面不再需要一个单独的
字段来表示真正的数据了,而是合二为一了。另外,由于xxxx只能取0001和1101这13个值了(其它可能的值和其它情况冲突了,比如0000和1110分别同前面第7种第8种情况冲突,1111跟结束标记冲突),而小数值应该从0开始,因此这13个值分别表示0到12,即xxxx的值减去1才是它所要表示的那个整数数据的值。
ziplist是由一系列特殊编码的连续内存块组成的顺序存储结构,类似于数组,ziplist在内存中是连续存储的,但是不同于数组,为了节省内存 ziplist的每个元素所占的内存大小可以不同(数组中叫元素,ziplist叫节点entry,下文都用“节点”),每个节点可以用来存储一个整数或者一个字符串。
2.3:hash
hash类型主要分为OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_HT,OBJ_ENCODING_ZIPLIST的value的sds大小超过64之后或者entry的长度超过128之后转化为OBJ_ENCODING_HT。
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyError(c,"wrong number of arguments for HMSET");
return;
}
//1. 查找hash的key是否存在,不存在则新建一个,然后在其上进行数据操作
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//2. 检查2-3个参数是否需要将简单版(ziplist)hash表转换为复杂的hash表,
//转换后的表通过o->ptr 体现
hashTypeTryConversion(o,c->argv,2,c->argc-1);
// 3. 添加kv到 o 的hash表中
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty++;
}
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
//hash_max_ziplist_value的值为64
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}从上面的代码可以看出,redis的hash采用的是OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_HT,OBJ_ENCODING_ZIPLIST在上面已经介绍了,这里就不介绍了,看上面,这里主要介绍OBJ_ENCODING_HT,也就是value的sds大小超过64之后或者entry的长度超过128之后 OBJ_ENCODING_ZIPLIST就会转换成OBJ_ENCODING_HT。
int hashTypeSet(robj *o, sds field, sds value, int flags) {
if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
}
//hash_max_ziplist_entries为512
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
}通过上面的代码也看的出来,本身redis就是一个hash表,通过dictFind找到hashTable的位置,然后更新sds。
2.4:set
set的类型主要为:OBJ_ENCODING_INTSET和OBJ_ENCODING_HT,set的value不是数字,或者OBJ_ENCODING_INTSET数量超过512之后转化为OBJ_ENCODING_HT。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
void saddCommand(client *c) {
robj *set;
int j, added = 0;
//查询该key是不是存在
set = lookupKeyWrite(c->db,c->argv[1]);
if (set == NULL) {
//不存在就创建
set = setTypeCreate(c->argv[2]->ptr);
dbAdd(c->db,c->argv[1],set);
} else {
if (set->type != OBJ_SET) {
addReply(c,shared.wrongtypeerr);
return;
}
}
// 对于n个member
for (j = 2; j < c->argc; j++) {
if (setTypeAdd(set,c->argv[j]->ptr)) added++;
}
if (added) {
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
server.dirty += added;
addReplyLongLong(c,added);
}
robj *setTypeCreate(sds value) {
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
return createIntsetObject();
return createSetObject();
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
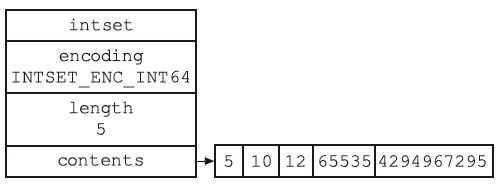
encoding: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。contents: 是一个柔性数组(flexible array member),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于encoding * length。柔性数组在Redis的很多数据结构的定义中都出现过(例如sds, quicklist, skiplist),用于表达一个偏移量。contents需要单独为其分配空间,这部分内存不包含在intset结构当中。
从代码上看出来,一开始set创建的数据结构就是OBJ_ENCODING_INTSET,int_set从上面看和sds基本上一样,可以理解为List,也可以说是数组组成,那么数据多了之后怎么转换呢?
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) {
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) {
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
/* Convert to regular set when the intset contains
* too many entries. */
//set_max_intset_entries=512
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
/* Failed to get integer from object, convert to regular set. */
setTypeConvert(subject,OBJ_ENCODING_HT);
/* The set *was* an intset and this value is not integer
* encodable, so dictAdd should always work. */
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
serverPanic("Unknown set encoding");
}
return 0;
}
从上面可以看出来set_max_intset_entries=512,也就是entry的数量超过512之后转变为ht,ht就是redis的hash表。
2.5:zset
zset的类型主要为:OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_SKIPLIST,当value的sds的大小超过64,或者当entry的数量超过128之后就由OBJ_ENCODING_ZIPLIST转化为OBJ_ENCODING_SKIPLIST,值得注意的是OBJ_ENCODING_SKIPLIST这里不仅仅指skipList,这里还用到了hashTable,一般我们都是底层存储用hashTable存储数据,上层为了快速查询,构建顺序的跳表,为什么构建跳表?hash索引是不能排序的,所有要做range的时候是很可怕的,所以构建跳表,当我们查询5-8的时候,快速定位5,往后查到8就可以了。
void zaddGenericCommand(client *c, int flags) {
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
} else {
if (zobj->type != OBJ_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
for (j = 0; j < elements; j++) {
double newscore;
score = scores[j];
int retflags = flags;
ele = c->argv[scoreidx+1+j*2]->ptr;
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0) {
addReplyError(c,nanerr);
goto cleanup;
}
if (retflags & ZADD_ADDED) added++;
if (retflags & ZADD_UPDATED) updated++;
if (!(retflags & ZADD_NOP)) processed++;
score = newscore;
}
server.dirty += (added+updated);
}
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
//zset_max_ziplist_entries为128
//zset_max_ziplist_value为64
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
if (sdslen(ele) > server.zset_max_ziplist_value)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
if (newscore) *newscore = score;
*flags |= ZADD_ADDED;
}从上面的代码中也可以看出来当value的sds的大小超过64,或者当entry的数量超过128之后就由OBJ_ENCODING_ZIPLIST转化为OBJ_ENCODING_SKIPLIST,OBJ_ENCODING_ZIPLIST这里就不介绍了,可以看上面,这里主要说OBJ_ENCODING_ZIPLIST。
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
de = dictFind(zs->dict,ele);
if (de != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*flags |= ZADD_NOP;
return 1;
}
curscore = *(double*)dictGetVal(de);
/* Prepare the score for the increment if needed. */
if (incr) {
score += curscore;
if (isnan(score)) {
*flags |= ZADD_NAN;
return 0;
}
if (newscore) *newscore = score;
}
/* Remove and re-insert when score changes. */
if (score != curscore) {
zskiplistNode *node;
serverAssert(zslDelete(zs->zsl,curscore,ele,&node));
znode = zslInsert(zs->zsl,score,node->ele);
/* We reused the node->ele SDS string, free the node now
* since zslInsert created a new one. */
node->ele = NULL;
zslFreeNode(node);
/* Note that we did not removed the original element from
* the hash table representing the sorted set, so we just
* update the score. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
*flags |= ZADD_UPDATED;
}
return 1;
}
/* 有序集合结构体 */
typedef struct zset {
// 字典,维护元素值和分值的映射关系
dict *dict;
// 按分值对元素值排序序,支持O(longN)数量级的查找操作
zskiplist *zsl;
} zset;
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
具体的结构就是hashtable和skipList,跳表我是比较熟悉的,这块代码我就不分析了,等我后面有时间再加注释。
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level跳跃表最低层(第一层)是一个拥有跳跃表所有节点的普通链表,每次在往跳跃表插入链表节点时一定会插入到这个最低层,至于是否插入到上层,就由随机数决定,ZSKIPLIST_P=0.25,从上面的代码可以看待,插入上层的概率是1/4;假设已经有一个跳跃表,其高度只有一层:

往表中插入节点“7”时,假设插入7时随机的结果小于0.25,则在第二层中插入“7”节点,继续随机一次看看还能不能上到第三层,小于0.25则停止插入,上层不再插入“7”节点了:

同理插入“4”节点假设连续两次随机都小于0.25,第三次大于0.25,则“4”节点会插入到2、3层:
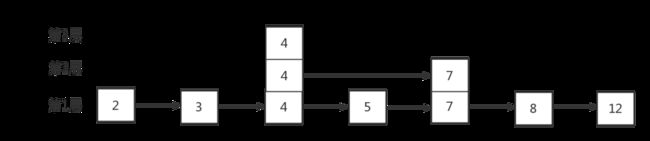
以此类推用这种方式构建的skipList,如果我没看过别的跳表,觉得还挺好,看过lucene的跳表,再看redis的,感觉有点low,其实从我看到的代码层面,redis的很多设计并不那么好,但是够快,因为计算机的内存最小单位是字节而不是位,操作位的性能不如字节,我猜redis因为这种原因采用的字节压缩,而没采用位压缩,但是我仍然认为redis没有lucene写的好。
3:redis数据复制(主从同步)
服务器运行ID(run_id):每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;run_id用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的run_id。
3.1:全量复制

- Redis内部会发出一个同步命令,刚开始是Psync命令,Psync ? -1表示要求master主机同步数据
- 主机会向从机发送run_id和offset,因为slave并没有对应的 offset,所以是全量复制
- 从机slave会保存主机master的基本信息
- 主节点收到全量复制的命令后,执行bgsave(异步执行),在后台生成RDB文件(快照),并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令
- 主机发送RDB文件给从机
- 发送缓冲区数据
- 刷新旧的数据。从节点在载入主节点的数据之前要先将老数据清除
- 加载RDB文件将数据库状态更新至主节点执行bgsave时的数据库状态和缓冲区数据的加载。
3.2:部分复制
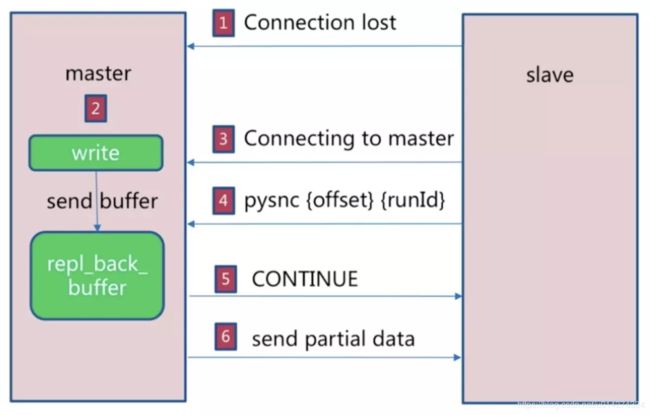
- 如果网络抖动(连接断开 connection lost)
- 主机master 还是会写 repl_back_buffer(复制缓冲区)
- 从机slave 会继续尝试连接主机
- 从机slave 会把自己当前 run_id 和偏移量传输给主机 master,并且执行 pysnc 命令同步
- 如果master发现你的偏移量是在缓冲区的范围内,就会返回 continue命令
- 同步了offset的部分数据,所以部分复制的基础就是偏移量 offset。
主从同步比zookeeper的要简单不少,但是很多地方是很相同的,我不单独介绍了。
3.3:积压空间
// call() 函数是执行命令的核心函数,真正执行命令的地方
/* Call() is the core of Redis execution of a command */
void call(redisClient *c, int flags) {
......
/* Call the command. */
c->flags &= ~(REDIS_FORCE_AOF|REDIS_FORCE_REPL);
redisOpArrayInit(&server.also_propagate);
// 脏数据标记,数据是否被修改
dirty = server.dirty;
// 执行命令对应的函数
c->cmd->proc(c);
dirty = server.dirty-dirty;
duration = ustime()-start;
......
// 将客户端请求的数据修改记录传播给 AOF 和从机
/* Propagate the command into the AOF and replication link */
if (flags & REDIS_CALL_PROPAGATE) {
int flags = REDIS_PROPAGATE_NONE;
// 强制主从复制
if (c->flags & REDIS_FORCE_REPL) flags |= REDIS_PROPAGATE_REPL;
// 强制 AOF 持久化
if (c->flags & REDIS_FORCE_AOF) flags |= REDIS_PROPAGATE_AOF;
// 数据被修改
if (dirty)
flags |= (REDIS_PROPAGATE_REPL | REDIS_PROPAGATE_AOF);
// 传播数据修改记录
if (flags != REDIS_PROPAGATE_NONE)
propagate(c->cmd,c->db->id,c->argv,c->argc,flags);
}
......
}
// 向 AOF 和从机发布数据更新
/* Propagate the specified command (in the context of the specified database id)
* to AOF and Slaves.
*
* flags are an xor between:
* + REDIS_PROPAGATE_NONE (no propagation of command at all)
* + REDIS_PROPAGATE_AOF (propagate into the AOF file if is enabled)
* + REDIS_PROPAGATE_REPL (propagate into the replication link)
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
// AOF 策略需要打开,且设置 AOF 传播标记,将更新发布给本地文件
if (server.aof_state != REDIS_AOF_OFF && flags & REDIS_PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
// 设置了从机传播标记,将更新发布给从机
if (flags & REDIS_PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}
// 向积压空间和从机发送数据
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
listNode *ln;
listIter li;
int j, len;
char llstr[REDIS_LONGSTR_SIZE];
// 没有积压数据且没有从机,直接退出
/* If there aren't slaves, and there is no backlog buffer to populate,
* we can return ASAP. */
if (server.repl_backlog == NULL && listLength(slaves) == 0) return;
/* We can't have slaves attached and no backlog. */
redisAssert(!(listLength(slaves) != 0 && server.repl_backlog == NULL));
/* Send SELECT command to every slave if needed. */
if (server.slaveseldb != dictid) {
robj *selectcmd;
// 小于等于 10 的可以用共享对象
/* For a few DBs we have pre-computed SELECT command. */
if (dictid >= 0 && dictid < REDIS_SHARED_SELECT_CMDS) {
selectcmd = shared.select[dictid];
} else {
// 不能使用共享对象,生成 SELECT 命令对应的 redis 对象
int dictid_len;
dictid_len = ll2string(llstr,sizeof(llstr),dictid);
selectcmd = createObject(REDIS_STRING,
sdscatprintf(sdsempty(),
"*2\r\n$6\r\nSELECT\r\n$%d\r\n%s\r\n",
dictid_len, llstr));
}
// 这里可能会有疑问:为什么把数据添加入积压空间,又把数据分发给所有的从机?
// 为什么不仅仅将数据分发给所有从机呢?
// 因为有一些从机会因特殊情况(???)与主机断开连接,注意从机断开前有暂存
// 主机的状态信息,因此这些断开的从机就没有及时收到更新的数据。redis 为了让
// 断开的从机在下次连接后能够获取更新数据,将更新数据加入了积压空间。
// 将 SELECT 命令对应的 redis 对象数据添加到积压空间
/* Add the SELECT command into the backlog. */
if (server.repl_backlog) feedReplicationBacklogWithObject(selectcmd);
// 将数据分发所有的从机
/* Send it to slaves. */
listRewind(slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
addReply(slave,selectcmd);
}
// 销毁对象
if (dictid < 0 || dictid >= REDIS_SHARED_SELECT_CMDS)
decrRefCount(selectcmd);
}
// 更新最近一次使用(访问)的数据集
server.slaveseldb = dictid;
// 将命令写入积压空间
/* Write the command to the replication backlog if any. */
if (server.repl_backlog) {
char aux[REDIS_LONGSTR_SIZE+3];
// 命令个数
/* Add the multi bulk reply length. */
aux[0] = '*';
len = ll2string(aux+1,sizeof(aux)-1,argc);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBacklog(aux,len+3);
// 逐个命令写入
for (j = 0; j < argc; j++) {
long objlen = stringObjectLen(argv[j]);
/* We need to feed the buffer with the object as a bulk reply
* not just as a plain string, so create the $..CRLF payload len
* ad add the final CRLF */
aux[0] = '$';
len = ll2string(aux+1,sizeof(aux)-1,objlen);
aux[len+1] = '\r';
aux[len+2] = '\n';
/* 每个命令格式如下:
$3
*3
SET
*4
NAME
*4
Jhon*/
// 命令长度
feedReplicationBacklog(aux,len+3);
// 命令
feedReplicationBacklogWithObject(argv[j]);
// 换行
feedReplicationBacklog(aux+len+1,2);
}
}
// 立即给每一个从机发送命令
/* Write the command to every slave. */
listRewind(slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
// 如果从机要求全同步,则不对此从机发送数据
/* Don't feed slaves that are still waiting for BGSAVE to start */
if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START) continue;
/* Feed slaves that are waiting for the initial SYNC (so these commands
* are queued in the output buffer until the initial SYNC completes),
* or are already in sync with the master. */
// 向从机命令的长度
/* Add the multi bulk length. */
addReplyMultiBulkLen(slave,argc);
// 向从机发送命令
/* Finally any additional argument that was not stored inside the
* static buffer if any (from j to argc). */
for (j = 0; j < argc; j++)
addReplyBulk(slave,argv[j]);
}
}为什么需要积压空间?为什么这里单独拉出来积压空间?这个问题要追溯到很久以前,redis是没有部分复制的,如果你的网络闪断,那么你只能全量复制数据,这样很恐怖,网络开销有时候可能会崩溃,那么后面就有了部分复制。部分复制和积压空间什么关系?部分复制的offset判断在积压空间里是不是有,这和zookeeper缓存部分事务日志异曲同工,用不分的空间来换取了时间上的自由,积压空间基本可以理解为命令缓存日志,在zookeeper叫事务缓存日志,这也是我说zookeeper和redis很像的原因,不过别的中间件也有类似的东西,因为这些思想在中间件里是被大家所广为认同的,上面的代码还包含了命令传播,这个大家可以自己看。到此结束了,也已经后半夜了,写这个真的太累了,我希望在别人的基础上写出来自己得到的东西,毕竟我不可能站的高度比别人高,我只希望站在别人的肩膀上说下自己的东西而已。