【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】1、回归问题(Regression)
【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】3、gradient descent
【李宏毅机器学习笔记】4、Classification
【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
【李宏毅机器学习笔记】7、反向传播(Backpropagation)
【李宏毅机器学习笔记】8、Tips for Training DNN
【李宏毅机器学习笔记】9、Convolutional Neural Network(CNN)
【李宏毅机器学习笔记】10、Why deep?(待填坑)
【李宏毅机器学习笔记】11、 Semi-supervised
【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】 13、Unsupervised Learning - Word Embedding(待填坑)
【李宏毅机器学习笔记】 14、Unsupervised Learning - Neighbor Embedding(待填坑)
【李宏毅机器学习笔记】 15、Unsupervised Learning - Auto-encoder(待填坑)
【李宏毅机器学习笔记】 16、Unsupervised Learning - Deep Generative Model(待填坑)
【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】 18、支持向量机(Support Vector Machine,SVM)
【李宏毅机器学习笔记】 19、Structured Learning - Introduction(待填坑)
【李宏毅机器学习笔记】 20、Structured Learning - Linear Model(待填坑)
【李宏毅机器学习笔记】 21、Structured Learning - Structured SVM(待填坑)
【李宏毅机器学习笔记】 22、Structured Learning - Sequence Labeling(待填坑)
【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】 24、集成学习(Ensemble)
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=30
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
-------------------------------------------------------------------------------------------------------
Transfer Learning

在训练中,训练数据不一定要和任务的种类是相同的。如上图,虽然是训练猫狗的分类器,但是也可以使用大象老虎的照片或者是卡通的猫和狗作为一部分训练数据。

之所以需要迁移学习是因为,在现实中,符合要求的图片相对较少。如上图,如果要分析一张医学方面的图片,但是相关的数据很少,这时可以给训练数据加进去一些猫狗等其它的图片。
Overview

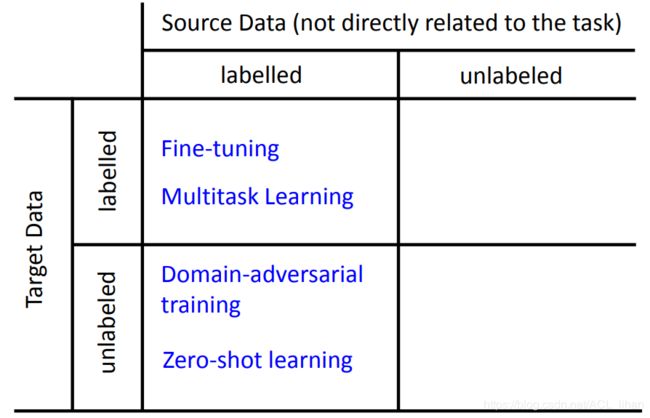
source data指和任务比较不相关的data,而target data就是和任务相关的data。
拥有的数据种类不同,要的方法也不同。
source data有label,target data有label
Model Fine-tuning

如果我们的target data 和source data都是有label的,那这时可以使用Model Fine-tuning。
做法是:
- 用source data作为训练数据,去训练模型。
- 将第一步训练而出的模型的参数作为此时的初始值,改成用target data去训练模型。
专业词汇:One-shot learning,指这种只有很少的target data的训练。
这个方法很简单,但是要注意,如果target data的数据非常少,需要加一些技巧(Conservative Training、Layer Transfer)来防止模型发生过拟合。
Conservative Training
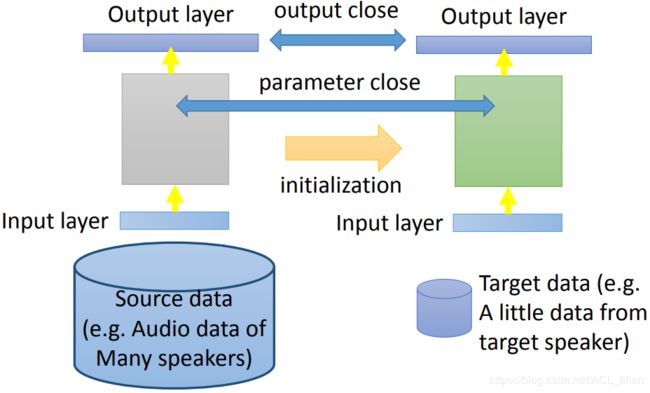
如果target data很少,为了防止使用target data训练时发生过拟合,可以在训练时加一些限制(比如加一些像L1、L2之类的正则项),让两边产生的模型不要相差太远。
Layer Transfer
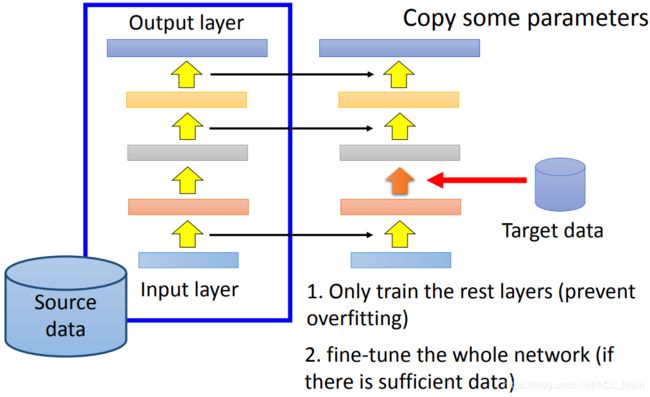
另一个防止使用target data训练时发生过拟合的方法,是 Layer Transfer 。
- 用source data训练出一个neural network后,把其中的一些layer的参数(黄色的箭头)复制到右边去训练。
- 用target data来调剩下的layer(橙色的箭头)
这样使用target data的训练过程就只调了部分的参数,减少了发生过拟合的风险。
当然,如果target data足够多的话,还是可以在用source data训练出模型后,用target data去微调整个模型的参数。
现在有一个问题,我们要决定那些layer应该是copy的呢?
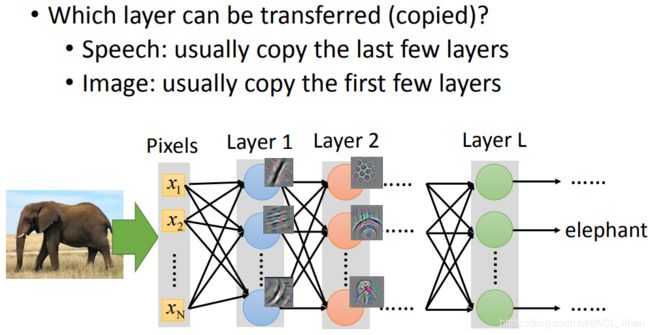
- 语音辨识:通常保留后几层layer,因为靠近input的layer,会受不同人的声音信号所影响。而越到后面,和人的发音方法越不相关,所以可以保留。
- 图像辨识:通常保留前几层layer,因为靠近input的layer,只是识别一些简单的特征(直线、斜线等),所以不同的任务在前几层做的事情都差不多。
Layer Transfer 在 Image上的效果
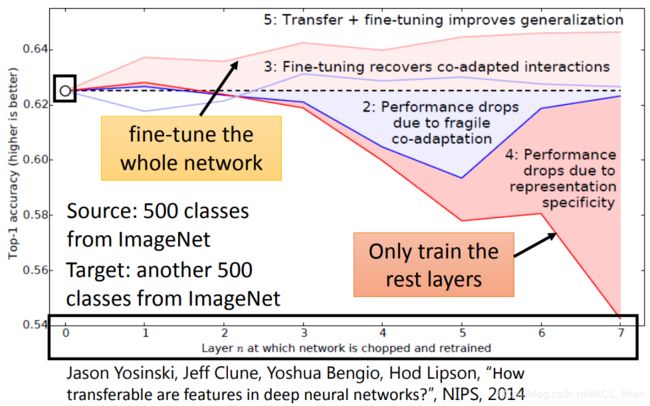
X轴代表复制多少layer,Y轴代表准确度。下面数字代表上图不同的线
- 没做Layer Transfer
- (和Layer Transfer无关的实验)使用target data先训练,然后固定住前几层(多少层对应X轴)的参数。然后继续用target data去调整后面剩下的layer。可以看到固定越多层,效果越差。因为不同的layer是有互相协调的。
- (和Layer Transfer无关的实验)使用target data先训练,然后固定住前几层(多少层对应X轴)的参数。然后继续用target data去fine-tune整个模型。
- 做了Layer Transfer的结果。复制越多层,效果慢慢变差。
Multitask Learning
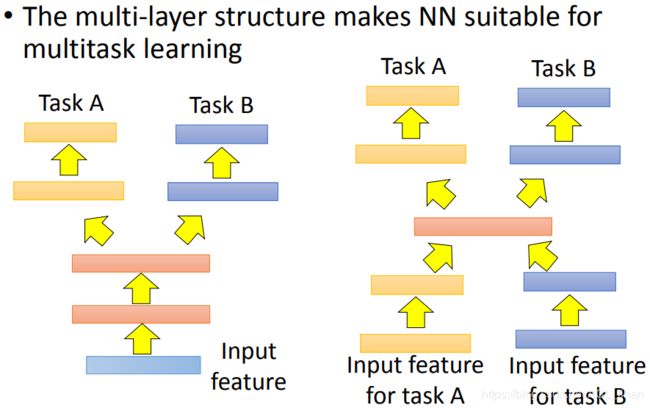
Multitask Learning能让机器学会多个任务。Multitask Learning很适合用neural network 来做。
上图左边,在network的前几层共用layer,到了后面要细分任务的时候再分为多个layer。
如果两个任务只有中间比较像,那就可以用上图右边的做法。
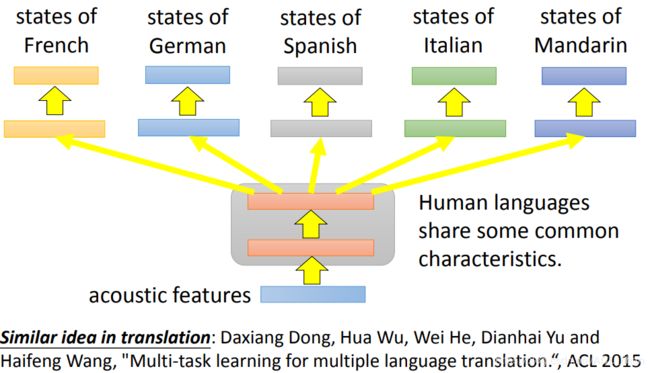
Multitask Learning一个很成功的的应用就是 多语言的语音辨识。
虽然是不同语言,但是声音的信号都差不多,所以前面的layer可以共用。到了细分语言再拆成多个layer。

上图是一个普通话(mandarin)的识别。 X轴是普通话的数据的时长,Y轴是错误率。
可以看到,虽然欧洲语言和普通话好像一点都不像。但是把欧洲语言和普通话一起做 Multitask Learning,让欧洲语言去帮忙调整前几层layer的参数,可以看到训练出来的结果会比只有普通话作为训练数据要好。
从图中横线的位置可以看出,Multitask Learning 达到和 Mandarin only 相同的错误率,Multitask Learning使用的训练数据明显更少。
Progressive Neural Networks
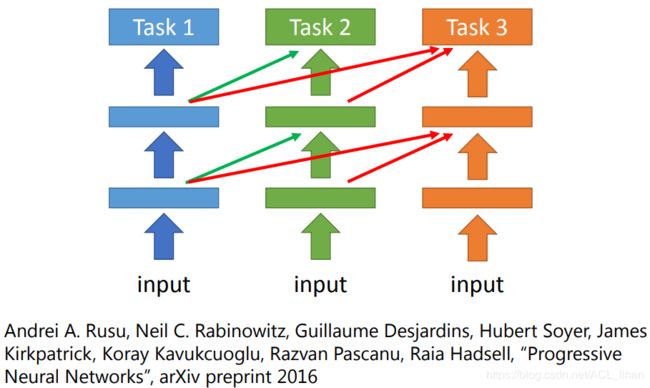
这个方法是这样:
- 先训练一个network解决task 1 。
- 固定住task 1 的network的参数,把task 1的network 的layer复制到task 2 的network中。
好处:即便在训练task 2时,也不会影响原来task 1的model的参数。同时,如果task 1的参数不适用于task 2,也会在训练时被慢慢调整好,不会对task 2造成影响。
source data有label,target data没label
Domain-adversarial training

这里source data是有label,而target data没有label。
以手写数字识别为例,source data是MNIST数据集,而target data是MNIST-M。
这时可以把source data看做training data,而target data看做testing data。但是这里有一个问题是,这两者的特征不是很像。
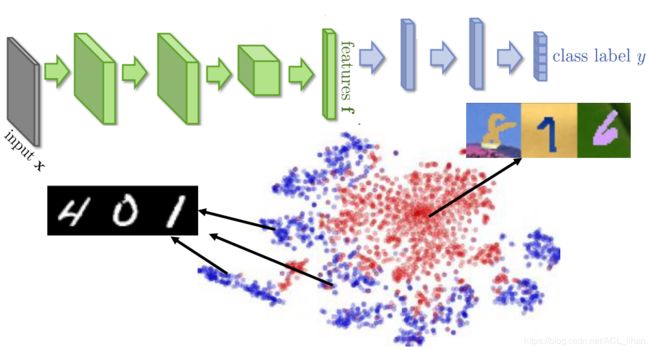
如上图,把model前几层提取的特征显示出来,可以看到source data和target data的特征是很不一样的(图中的红色和蓝色点有明显的分界线)。所以如果用source data去learn一个model后,直接以target data作为input去预测,结果肯定是很差的。

所以我们要使得source data和target data输入model后,经过feature extractor后,所得到的特征是比较像的,即如上图是“混在一起”的。
所以这里将feature extractor的output接到一个domain classifier。domain classifier是分类source data和target data的特征,所以最好的情况是feature extrator的output,能使的domain classifier的准确率达到最低(即代表source data和target data的特征没被区分开)。
但这里有个漏洞,如果要使domain classifier的准确率很低,那feature extractor可以不管input是什么,都output 同一个数值。这明显是不对的,所以还要加一个限制。如下。

在刚才的基础上,再加一个label predictor。所以现在feature extractor不仅要能最小化domain classifier的准确度,还要最大化分类的准确率。

实做时用gradient descent,然后在做反向传播的时候,如果domain classifier要更新的参数是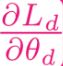 ,那传递回feature extractor的时候,就把这个参数更新量颠倒,就能使feature extractor往domain classifier 准确度下降的方向去更新。
,那传递回feature extractor的时候,就把这个参数更新量颠倒,就能使feature extractor往domain classifier 准确度下降的方向去更新。
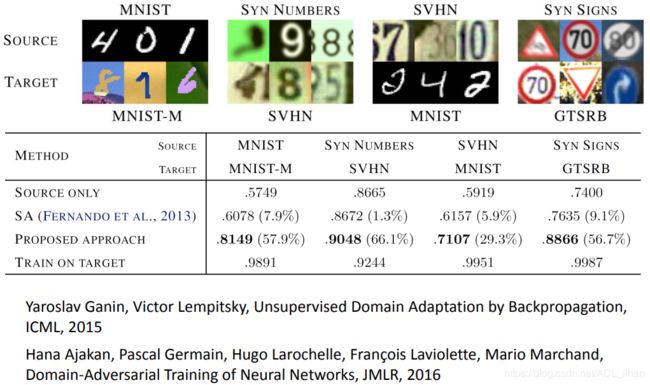
上图是使用有无Domain-adversarial training的对比结果。
Zero-shot Learning

在刚才 Domain-adversarial training 的例子中,source data和target data比较不像。
但在 Zero-shot Learning 里,source data和target data是两种不同task。如上图,source data是分类猫狗的data,而target data则是分类羊驼的任务。这时可以有两个方法可以做:Representing each class by its attribute、Attribute embedding。
Representing each class by its attribute
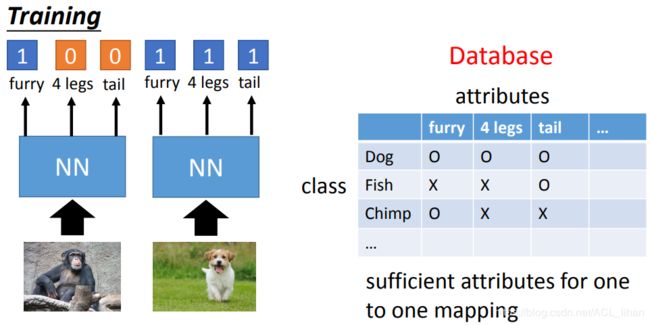
既然使用target data没办法直接预测图中的物体是什么,那就换一种角度。
- 让neural network去预测图中物体有哪些特征(例如毛茸茸,4条腿,有尾巴等)。
- 知道图中物体有哪些特征之后,查数据库(这个是人工建立的),看拥有此特征对应哪种物体。
Attribute embedding

步骤如下:
- 把所有类别各自的描述(attribute,也可以理解为特征)先定义好。(这一步需要人工来定义,也可能能用机器自动去定义)
- 把image
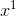 和它的描述
和它的描述 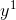 ,分别通过 f 和 g 两个NN,映射到embedding space上。要训练模型使得这两个output越接近越好。
,分别通过 f 和 g 两个NN,映射到embedding space上。要训练模型使得这两个output越接近越好。 - 把unlabel 的
 通过 f 映射到embedding space上(上图写错了,是
通过 f 映射到embedding space上(上图写错了,是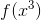 ),看得出它和
),看得出它和 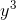 的描述(attribute)的映射比较接近,所以判定 属于羊驼。(这个例子虽然训练集没有羊驼的图像数据,但是有羊驼的描述,这个描述是人工事先定义的,或者可能机器也可以定义)
的描述(attribute)的映射比较接近,所以判定 属于羊驼。(这个例子虽然训练集没有羊驼的图像数据,但是有羊驼的描述,这个描述是人工事先定义的,或者可能机器也可以定义)

前面说过要使 f 和 g 的 output 尽可能接近,但如果用上图第一行的公式去训练会有问题(如果 f 和 g 不管input是什么,output都一样,这样它们的距离就一直是0),所以要用第二行公式的做法。
这个公式的最好情况是 0 ,即max()的第二项(也叫zero loss)要小于0。
zero loss整理一下,可以看出,就是两项内积相减要大于k(k代表margin,是人工设置的)。
f 和 g 的内积在几何上可以想象成投影。现在看zero loss的两项。
- 第一项:如果f 和 g 的偏差较小,f 和 g 的内积就会相对较大。
- 第二项:
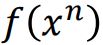 和其他除了n的
和其他除了n的 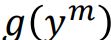 的内积。
的内积。
所以如果 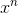 和
和 ![]() 是匹配的,那么第一项的内积肯定会大于第二项的内积,如果两者内积的差大于k,则判定loss为0 。
是匹配的,那么第一项的内积肯定会大于第二项的内积,如果两者内积的差大于k,则判定loss为0 。
刚才讲的是需要image和对应class的描述(attribute)。 而如果根本不知道每一个动物的attribute是什么怎么办?这时可以用Attribute embedding + word embedding。
Attribute embedding + word embedding
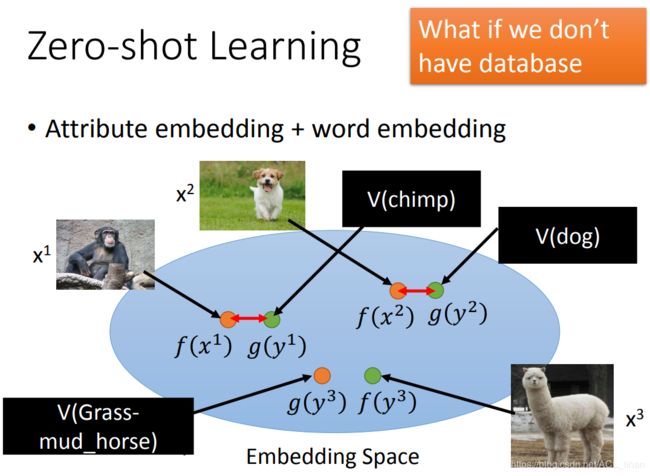
这里需要引进word vector。word vector的每一维代表这个word的某一种attribute。
现在直接把动物的名字所对应的word vector来代替每一种动物的attribute。其他步骤和刚才Attribute embedding一样。
Convex Combination of Semantic Embedding
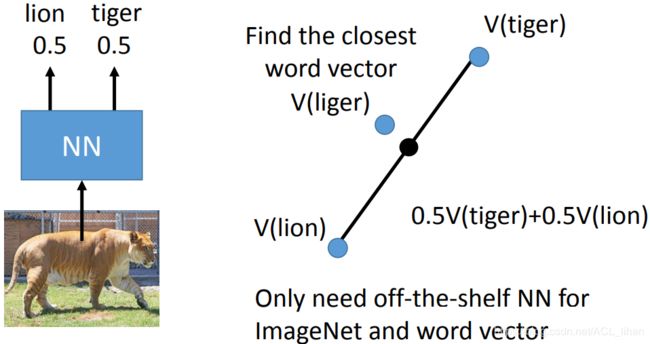
这个方法的好处是不用训练。
步骤如下:
- 把image输入到一个NN(随便找个现成的NN就行),NN输出这张图片属于不同种类的几率。比如上图属于狮子和老虎的几率都是0.5 。
- 去找lion和tiger的word vector,把它们按各自0.5融合,得到图中黑色的点。
- 去找其他word vector看哪个点和这个黑色点距离比较近。如上图liger的word vector和这个黑色点比较近,就说明 image 的物体属于这个liger 。
Example of Zero-shot Learning
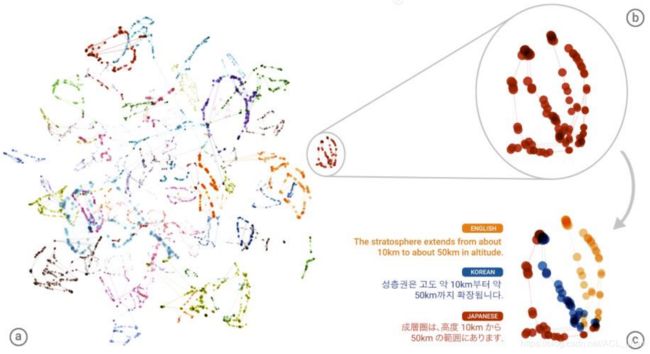
上面两张图是Zero-shot Learning应用在翻译的例子。这个例子的training data除了日转韩,其它都有。所以使用Zero-shot Learning后就能实现日转韩的翻译。
它的步骤大概可以理解为:
- 输入的英语日语韩语到机器中。
- 机器将data投射到另一个space上(转换为另一种机器自己看得懂的语言)。不同语言但是同一个意思的词在这个space上的位置都差不多。
- 最终输出翻译的时候就把这个space上的点转换为人类看得懂的语言。
More about Zero-shot learning

这边是更多关于 Zero-shot learning 的论文。
source data有label,target data没label
Self-taught learning
这个方法步骤如下:
- 从source data里去learn 一个性能更好的feature extractor
- 用这个性能更好的feature extractor去target data上提取feature。
source data没label,target data没label
Self-taught Clustering
这边没讲。。可以看图中的论文去了解。