Pandas引入外部文件数据
Pandas引入外部文件数据
- 1. 读取文本文件
- 文本文件读取方法及参数解读
- 实例演示
- 1)规则文件处理
- 2)不规则文件处理
- 2. 分块读取数据
- 文件很大但是只需读取其中前几行内容
- 文件很大且需要读取全部内容
- 3. 读取json数据
- 4. 读取Excel文件数据
- 方法及参数说明
- 使用演示
- 5. 读取SQL文件
一般而言,IO操作有如下几种:
1.读取文本文件和其他类型的磁盘存储格式
2.加载数据库中数据
3.利用web API操作网络资源
1. 读取文本文件
文本文件读取方法及参数解读
读取文本文件所用的函数一般有两个,read_csv() 和 read_table() ,

文本文件一般读取的是csv格式和txt格式,上面几个函数共有的重要功能,
(1)类型推断:不需要在读取的时候指明文件中每列的数据类型,在读取的时候pandas的函数会自动获取这些信息并赋予合适的类型。
(2)索引:在不指定的情况下,将各列的列名自动获取。也可以不获取文件中的列名,自定义列名。同时可以指定其中一列为索引列。
#-*- coding:utf-8 -*-
import pandas as pd
res = pd.read_table('sale.txt', sep = '\t',
header = None,
usecol = [1,3,4],
names = ['goods','quantity','price'])
上方代码是 read_table() 方法的基本的使用,该方法中常用的参数如下:
| 参数 | 说明 |
|---|---|
| filepath_or_buffer | 这个是第一个参数,可以是字符串也可以是一个代表着文件路径的变量,是所要读取的文件的路径。 |
| sep | 是separate的缩写,在文本文件中不同列的数据通常情况下是用相同的字符间隔开的,常用的有逗号、制表符、空格等。该参数默认是制表符,如果是其他形式的间隔应在方法中设置该参数。 |
| header | 设置某行作为字段名,默认是索引值为0的行(第一行)。如果文件中没有列名,应设置该值为 None。 |
| names | 一个list,元素是DataFrame的列名,在文件中没有header列且明确指明参数 header = None时使用。list中的元素个数一定与DataFrame的列数相同。 |
| index_col | 是一个int、序列或者是False,默认值是None。这个参数的作用是选文件中的一列数据作为DataFrame的索引值。int是文件中列对应的索引;输入的序列是文件中该列的列名(这个比较常用);Flase则是强制pandas不选用文件的第一列作为DataFrame的索引。 |
| usecols | 当不必要加载文件中所有列进入DataFrame时,可以指定加载的列。官方文档中说明 ‘a valid array-likeusecols parameter would be [0, 1, 2] or [‘foo’, ‘bar’, ‘baz’].’,即usecols的形式有两种,一种是数值类型的list,数值对应的是相应列在文件中的索引;另一种是字符串类型的list,其中的元素对应的是文件中对应列的列名。 |
| nrows | int, default None,这个参数是需要读取的行数(从文件头开始算起)。 |
| na_values | scalar, str, list-like, or dict, 默认是 None,这个参数设定的是一组被视为NA/NaN的值。 |
| true_values | list, 默认是None。官方文档解释’Values to consider as True’,被认定为是’真‘的值。 |
| false_values | list, 默认为None,与true_values相似,是一组被视为’假‘得值。 |
| chunksize | 这个参数指定分批读取文件,以后详细说明。 |
read_csv() 和 read_table()很相似,两个都常被用于读取文本文件,区别是二者sep参数的默认值不同。前者的sep默认为逗号;后者则是默认为制表符。
实例演示
1)规则文件处理
假设现在有一个逗号分隔的文本文件,

可以直接使用read_csv方法读取该文件,

也可以自定义列名,通过name参数,

同时可以指定某一列作为索引列,使用的是index_col参数,

这里只是将“message“列作为索引,设置多层索引也是可以的,只要将多个列的列名以列表的形式传递给index_col参数即可。
2)不规则文件处理
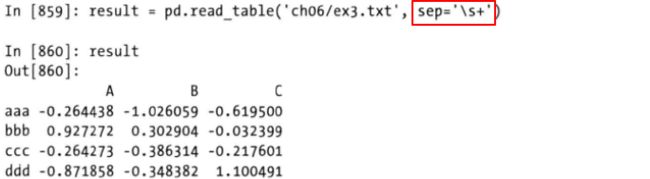
对于一些不规则的表格而言,比如说分隔符不是逗号、不是tab、空白符等有严格规律的符号分割时,可以传递一个正则表达式给sep参数,比如下放这种情况。文件中内容由不等的空格分隔,

传入一个正则表达式,比如这个例子中传入的是一个或多个space组成的分隔符,
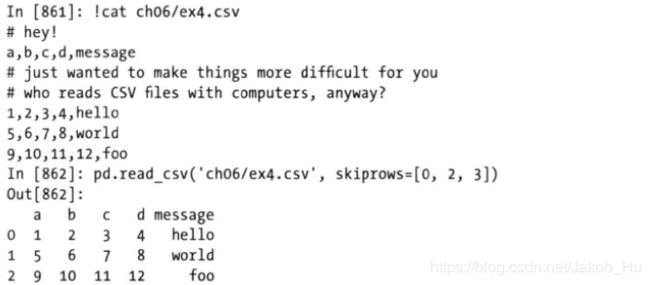
如果文件中存在几行数据是不希望被读取到dataframe中的,可以使用skiprows参数,将这几行的行索引(从0开始)一列表的形式传递过来,
缺失值的处理使用的是 na_values参数,如果不指定,默认缺失值使用NaN表示。
2. 分块读取数据
当要处理的文件很大的时候,像上面那样直接将整个文件读入内存有时候是不可取的。对于大文件的处理,可能存在以下几种情况,
文件很大但是只需读取其中前几行内容
此时可以使用 nrows参数进行指定,

读取了csv文件的前五行。
文件很大且需要读取全部内容
此时可以逐块读取,只需设置chunksize参数,这个参数传入的值是每次所要读取的行数。

每个chunker是pandas的TextParser类对象,该对象能够对文件进行迭代,
每次迭代的产内容都可以视为一个DataFrame进行相应的操作,


TextParser对象还具有 get_chunk方法,可以取出任意大小的块,同时最好配合iterator参数,

3. 读取json数据
JSON(JavaScript Object Notation)是常用的结构化数据之一。比一般的文本格式灵活,基本的形式如下,

json的格式就像是整合了Python多种的基本类型,如dict、list、string、int、float、Boolean和null。Python的很多标准库都可以读写json数据,最常用的是Python的json库,通过json.loads方法即可将JSON字符串转换为Python的基本形式,

将JSON数据解析成Python的字典。相反的,json.dumps方法是将Python的字典打包成JSON格式。
![]()
将JSON数据解析后,转化为Series或者Dataframe是一个对字典对象进行转换的过程,
![]()


4. 读取Excel文件数据
方法及参数说明
pandas模块中,read_excel() 方法用于读取 .xls和 .xlsx文件,要求excel版本高于2003,需要 xlrd和xlwt两个模块的支持,

重要参数有,
| 参数 | 说明 |
|---|---|
| io | io变量是所读取文件的路径,是必填参数。 |
| sheetname | excel表格中存在着不同的sheet,读取时如果对sheet没要求则pandas默认读取索引为0的sheet。官方文档中的解释“string, int, mixed list of strings/ints, or None, default 0”,即 sheetname参数可以是整数、字符串、列表或者None。当为int时,指的是sheet的索引;string是相应的sheet的名称;list中元素可以是sheet的索引也可以是sheet的名称;当定义该变量为None时,是该excel表格中所有的sheet。 |
| index_col | 默认是None(就是没有作为索引的MySQL数据表的列),如果有要作为索引的列,则填入该列在数据表中的名称 。 |
| columns | 当不读取table中所有的列时,输入该参数,形式是list,元素是table中所要读取的列名。 |

其余参数可参考 read_csv和read_table方法。
使用演示
#-*- coding:utf-8 -*-
import pandas as pd
df = pd.read_excel(io='***.xlsx',
sheetname=1,
header=0,
index_col= None,
names = None,
dtype=None )
read_excel方法可以与Python的xlrd接口进行配合使用,

5. 读取SQL文件
使用Pandas模块中提供的 read_sql方法和read_sql_table 方法,
![]()
![]()
其中的一个参数:
con : SQLAlchemy connectable (or database string URI),是建立的与数据库之间的连接对象。
#-*- coding:utf-8 -*-
import pandas as pd
import MySQLdb as mdb # 如果是python3.x使用 sqlchemy模块
# 首先创建数据库连接
conn = mdb.connect(host = 'localhost',port=3306,user= 'root',passwd='*****',db = 'test')
df = pd.read_sql_table(table_name='table1',
con=conn,
index_col='col1',
columns=['col1','col2'...])
Python2中,conn可以使用 MySQLdb进行创建,但是在Python 3中,MySQLdb不再被支持,此时只能使用其他的如SQLAlchemy进行创建连接。
import pandas as pd
from sqlalchemy import create_engine
DATABASE = {
'host': 'localhost',
'user': 'username',
'password': 'pwd',
'db': "dbname",
}
engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s/%(db)s?charset=utf8' % DATABASE,encoding='utf-8')