网络爬虫之添加头信息、提交关键词、保存图片
本文为北理嵩天老师《Python网络爬虫与信息提取》学习笔记。
本文包含以下内容:
- 一、爬取亚马逊上的一本书
- 二、百度/360搜索关键词提交
- 三、网络图片的爬取和存储
- 四、IP地址归属地的自动查询
一、爬取亚马逊上的一本书
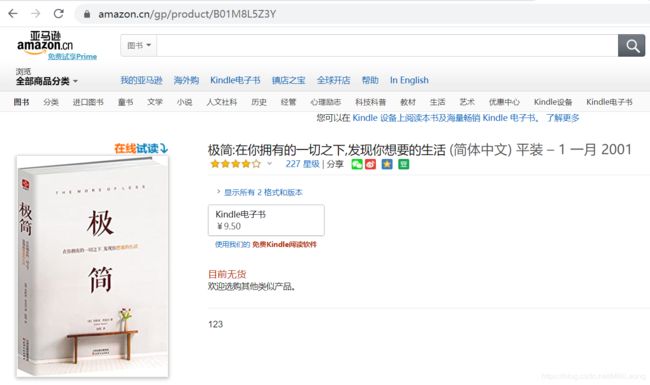
1.使用requests库的get方法获得链接信息,并查看状态码
import requests
r=requests.get("https://www.amazon.cn/gp/product/B01M8L5Z3Y")
r.status_code
输出的结果为:503,表明访问出现了错误
2.查看网页页面内容
r.encoding=r.apparent_encoding
r.text
结果如下:
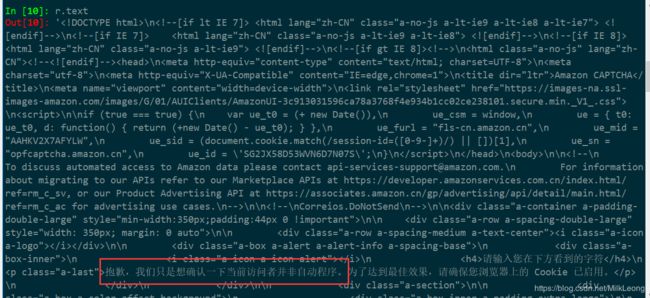
(或许英文中也有关于API的提醒)这表明访问出错,但这个错误是API造成的。如果我们已经从服务器获得了相关的页面信息回来,表明错误不是由网络造成的。
网络对爬虫的限制主要有两种:
(1)通过robots协议告诉爬虫哪些是允许的,哪些是不允许的
(2)通过判断对网站进行访问的http的头来查看这个访问是不是被爬虫执行的。对于爬虫的请求,网站是可以拒绝的。[来源审查]
3.查看执行访问的http的头部内容,以看错误是不是由网页的审查机制造成的。
r.request.headers
结果如下:

爬虫忠实地告诉了服务器,这次访问是由一个python的request库的程序产生的。
4.更改头部信息,让程序模拟浏览器发出爬虫请求
kv={'user-agent':'Mozilla/5.0'} #构造键值对
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url,headers=kv)
此时再查看r.status_code,返回的状态码为200,r.text中也不再有错误提醒
完整的爬取框架如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
二、百度/360搜索关键词提交
百度的关键词接口:
https://www.baidu.com/s?wd=keyword
360的关键词接口:
https://www.so.com/s?q=keyword
可通过params参数来提交关键词,基本的代码框架如下:
import requests
keyword="Python"
try:
kv={'wd':keyword}
r=requests.get("https://www.baidu.com/s",params=kv) #通过params将键值对输入进去并获得相关请求
print(r.request.url)
r.raise_for_status
print(len(r.text))
except:
print("爬取失败")
向360搜索提交关键词时,需将 kv={‘wd’:keyword} 的’wd’改为’q’。
三、网络图片的爬取和存储
网络图片链接的格式:
https://www.example.com/picture.jpg
即:url+picture.jpg
在某个url(如:https://www.nationalgeographic.com.cn/)中选择一个图片Web页面,可看到该图片的url
如果某个url链接是以.jpg结尾,说明它是一个图片链接,而且这个链接是个文件,如下图:

图片是二进制格式,将二进制的图片保存成文件,通常会用到一下代码:
path="E:\\Spider learning\\xunyi.jpg" #保存图片的位置和图片的名字
url="http://imgsrc.baidu.com/baike/pic/item/0d338744ebf81a4cb3f882fed82a6059252da63b.jpg"
r=requests.get(url)
#print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
with open() as f: 打开一个文件,并把它定义为一个文件标识符f
r.content: 在response对象中r.content表示以二进制格式呈现返回的内容
完整的代码框架如下:
import requests
import os
url="http://imgsrc.baidu.com/baike/pic/item/0d338744ebf81a4cb3f882fed82a6059252da63b.jpg"
root="E://Spider learning"
path=root+url.split('/')[-1] #图片原来的名字存储图片
try:
if not os.path.exists(root): //如果当前的根目录不存在,就建立一个根目录
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
网上的视频、动画、flash等都可以通过这样的方式修改代码以保存。
四、IP地址归属地的自动查询
要想判断一个地址的归属地必须有一个库,程序中无这样的库,可在网上找相关的资源。如IP138网站(https://www.ip138.com/)
在ip138网站中输入IP地址点击查询后,可看见地址栏的url发生了变化,其格式变为:
https://www.ip138.com/ip.asp?ip=ipaddress&action=2
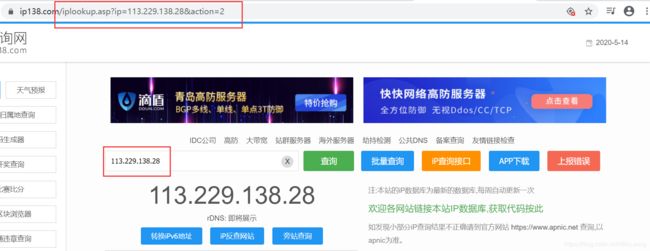
利用这样的url就可以通过提交IP地址来找到IP地址的归属地。
代码如下:
import requests
kv={'user-agent':'Mozilla/5.0'}
url="https://www.ip138.com/iplookup.asp?ip="
try:
r=requests.get(url+'202.204.80.112&action=2',headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding #可防止输出的网页内容中出现乱码
#print(r.text[-500:]) #返回文本的最后500个字节
print(r.text)
except:
print("爬取失败")
从输出的结果可知,这个IP地址对应的是北理的官网:
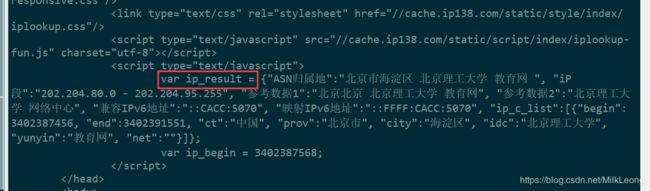
从这个例子中可以知道,我们有时在网站上看到的人机交互方式,比如图形、文本框等需要点击按钮的来向服务器提交的,其实都是以链接的方式提交的,只要能知道如何通过对网页的解析获取后台的提交形式,则可以用python代码来模拟向服务器提交。