LeNet和ResNet神经网络做CIFAR10图像分类(PyTorch)
图像分类的算法有很多,大部分其实都用CNN来提取图像的特征,今天我们一起来学习用PyTorch做CIFAR10数据集的分类。CIFAR10数据集是一个10个类的图像数据集,图片大小是32*32的。首先我们来看LeNet模型,这个模型进行图像识别的流程入下图所示:
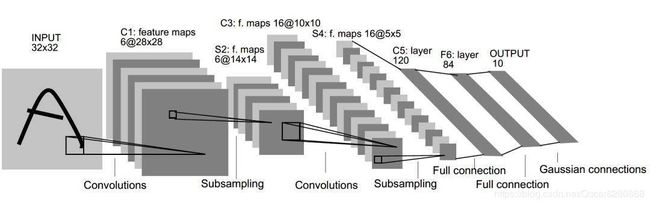
由上图可以清晰地看出整个的流程是经过一个卷积层,然后经过池化,再经过卷积,再进行一层池化层,最后是三个全连接层,最终输出10维的向量就是分类的结果,我们先来看看lenet5.py代码:
import torch
from torch import nn
#from torch.nn import functional as F
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积&池化
self.conv_unit = nn.Sequential(
# 卷积层,RGB3个channel,然后6个卷积核进行卷积,卷积核是5*5的,步长是1,没有zero padding
nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0),
# 这里选择的是最大值池化,因为均值池化的效果很差,池化核是2*2的,步长是2,没有 zero padding
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# 原理同上
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
# 原理同上
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 全连接
self.fc_unit = nn.Sequential(
# 线性层,输入维度是16*5*5,输出维度是120,在图中有标识
nn.Linear(16*5*5, 120),
# 使用激活函数ReLU
nn.ReLU(),
# 第二个全连接层
nn.Linear(120, 84),
# 激活函数
nn.ReLU(),
# 输出层
nn.Linear(84, 10)
)
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
print('conv out: ', out.shape)
# 正向传播函数
def forward(self, x):
# 数据集batch的数量
batch_size = x.size(0)
# 卷积&池化操作
x = self.conv_unit(x)
# 通过view函数来调整x的大小
x = x.view(batch_size, 16*5*5)
# 全连接层操作
logits = self.fc_unit(x)
return logits
def main():
# 实例化net模型
net = LeNet5()
# 初始化两张3通道的32*32的图像
tmp = torch.randn(2, 3, 32, 32)
进行lenet操作流程
out = net(tmp)
# print('LeNet out: ', out.shape)
if __name__ == '__main__':
main()
我们初始化好了lenet5神经网络之后,我们再来看看主函数的代码:
# 导入必要的python库
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from cifiar.lenet5 import LeNet5
from torch import nn, optim
import torch
from cifiar.resnet import ResNet
def main():
# 初始化batch size为32
batch_size = 32
# 定义cifar10训练集,确保训练集数据大小是32*32
cifar_train = datasets.CIFAR10('.', train=True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
]), download=True)
# 使用数据加载器加载训练集,并随机打乱
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
# 定义测试集
cifar_test = datasets.CIFAR10('.', train=False, transform=transforms.Compose([
transforms.Resize(32, 32),
transforms.ToTensor()
]), download=True)
# 使用数据加载器加载测试集
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
x, label = iter(cifar_train).next()
print('x: ', x.shape, 'label: ', label.shape)
#device = torch.device('cuda')
#model = LeNet5().to(device)
# 初始化LeNet5模型
model = LeNet5()
#model = ResNet()
# 模型优化的标准是交叉熵
criteon = nn.CrossEntropyLoss()
# 使用Adam进行优化,加载模型的参数,设置学习率为0.001
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
# 循环100个epoch
for epoch in range(100):
# 将 module 设置为 training mode
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
logits = model(x)
loss = criteon(logits, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, loss.item())
# 将模型设置成 evaluation
model.eval()
# 表示下面的部分不需要求梯度
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
logits = model(x)
# 预测的类别
pred = logits.argmax(dim=1)
# 总的正确分类数
total_correct += torch.eq(pred, label).float().sum().item()
total_num += x.size(0)
# 正确率
acc = total_correct / total_num
print(epoch, 'acc: ', acc)
if __name__ == '__main__':
main()
因为配置很挫,所以我就跑了10个epoch,然后我将前10个epoch的准确率画出来如下图所示:

可以看出,最后lenet模型的图片分类的准确度可以达到60%以上,效果不太好。针对这一问题,我们可以使用何恺明等华人学者提出的resnet,这个网络也被称作深度残差网络,这个模型允许网络尽可能加深,一般的神经网络如果加深的话很容易出现过拟合,而resnet模型中,如果这几个模块的网络效果不好,就将其shortcut,因此不会将前面几层的输出直接连接到后面几层中去。如图就是最经典的resnet神经网络模型:

可以看出整个的resnet网络模型是由很多个小的block级联起来的,每一个block都有一个像电路短路一样的shortcut,我们就可以根据resnet模型来编写模型的代码如下所示:
import torch
from torch import nn
from torch.nn import functional as F
# 定义resnet网络模型的block
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
# 对输入的数据进行卷积操作,卷积核是3*3,步长是1,有长为1的padding
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1)
# 进行batch normalization 操作,就是将数据分布批量规范化,方便后续的训练
self.bn1 = nn.BatchNorm2d(ch_out)
# 将上一层的输出作为这一层的输入进行训练,同样卷积核是3*3,步长是1,四周加了一层padding
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
# 将第二层的数据进行batch normalization操作
self.bn2 = nn.BatchNorm2d(ch_out)
# 需要保持输入和输出的size要相同,否则就加一个单元让输入和输出的size保持相同
self.extra = nn.Sequential()
# [b, ch_in, h, w] =>[b, ch_out, h, w]
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x:
:return:
"""
# 第一层卷积和batch norm操作,加一层ReLU激活函数
out = F.relu(self.bn1(self.conv1(x)))
# 第二层卷积和batch norm操作
out = self.bn2(self.conv2(out))
# 将shortcut输出的x和前面block卷积操作的结果进行叠加
out = self.extra(x) + out
return out
# 为了减轻CPU/GPU负担,我将输入和输出维度以及block的个数设置得很小,其实用GPU的话,可以适当增加维度和block的个数
class ResNet(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
# 定义卷积操作
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16)
)
# followed 4 blocks,这里我只用两个block,减轻CPU的负担
self.blk1 = ResBlk(16, 16)
self.blk2 = ResBlk(16, 32)
#self.blk3 = ResBlk(32, 64)
#self.blk4 = ResBlk(64, 128)
# 定义输出层,将维度降到10输出,完成图像分类
self.outlayer = nn.Linear(32 *32 * 32, 10)
# 进行前向传播操作
def forward(self, x):
"""
:param x:
:return:
"""
# 卷积核block级联
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
#x = self.blk3(x)
#x = self.blk4(x)
# 检查x的数据size并做调整
x = x.view(x.size(0), -1)
# 输出结果
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 32, 32)
out = blk(tmp)
print('blk: ', out.shape)
model = ResNet18()
tmp = torch.randn(2, 3, 32, 32)
out = model(tmp)
print('resnet: ', out.shape)
if __name__ == '__main__':
main()
写好了resnet网络模型之后,我们就可以将main.py中的模型设置改成model = ResNet(),将原先的model = LeNet5()屏蔽掉就可以了,然后我们就可以跑代码了:
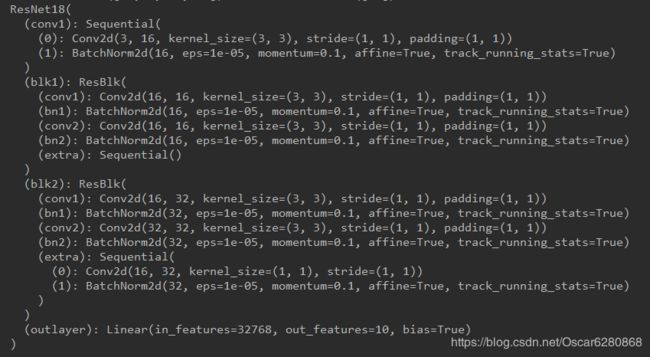
因为为了节省消耗,我把网络模型设置成最简单的了,各位朋友如果GPU牛逼的话,可以设置更复杂的维度和网络模型,可以输出更好的结果,上图是第一个卷积层和两个block中的参数信息,因为这块代码的网络模型很简单且维度很低,所以图片分类的结果准确率也在60%左右,但是相信网络模型block级联数和维度的增加,准确率也会随之增加的,因为resnet网络模型不会因为网络模型的深度增加而降低准确率。这只是一个最简单的resnet模型,希望可以帮助大家对大神何恺明的resnet模型有一个很好的理解。文中如有纰漏,也请大家不吝指教;如有转载,也请注明出处,谢谢大家。