反应式编程详解

| 导语 反应式编程是在命令式编程、面向对象编程之后出现的一种新的编程模型,是一种以更优雅的方式,通过异步和数据流来构建事务关系的编程模型。本文包括反应式编程的概述和 RxPy 实战,以及怎样去理解反应式编程才能更好的把它融入到我们的编程工作中,把反应式编程变成我们手中的利器。
1.1 背影趋势
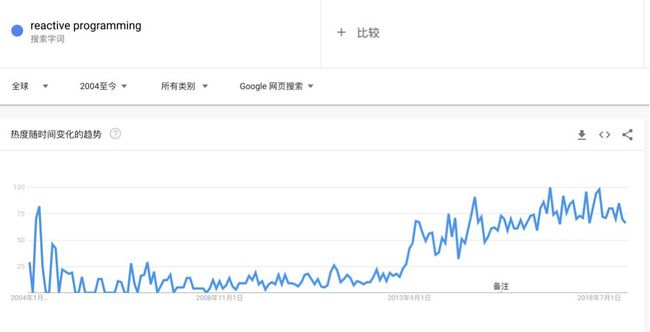
在 google 趋势中搜索反应式编程,可以看到其趋势在 2013 年后一直是往上走的。如图1所示:
[ 图1 google 趋势搜索结果 ]
为啥呢?为啥是 2013 年才有明显的变化,因为2013 年后才有可以大范围使用的框架和库出现,才有人专门投入去布道反应式编程这个事情。
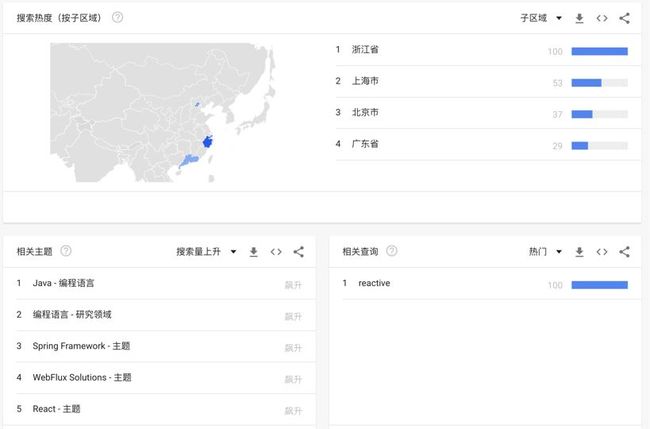
在范围缩小到中国,这个结果有点意思了,如图 2 所示:
[ 图2 google趋势搜索结果 ]
在中国主要是北上广深和杭州,说明什么,这些技术还是一线城市的开发同学才会使用,查看左下角主要是主题都是java相关,查看右上角,浙江省用得比较多,说明阿里是主要的使用方。
1.2 定义
反应式编程又叫响应式编程,在维基百科中,其属于声明式编程,数据流。
其定义为:
反应式编程 (reactive programming) 是一种基于数据流 (data stream) 和 变化传递 (propagation of change) 的声明式 (declarative) 的编程范式。
换句话说:使用异步数据流进行编程,这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
反应式编程提高了代码的抽象级别,可以只关注定义了业务逻辑的那些相互依赖的事件。
1.3 Rx的发展
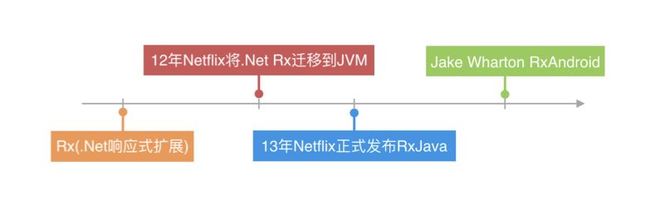
反应式编程最着名的实现是 ReactiveX,其为 Reactive Extensions 的缩写,一般简写为 Rx ,发展历程如图 3 所示:
[ 图3 Rx来历 ]
微软 2009 年 以 .Net 的一个响应式扩展的方式创造了Rx,其借助可观测的序列提供一种简单的方式来创建异步的,基于事件驱动的程序。2012 年 Netflix 为了应对不断增长的业务需求开始将 .NET Rx 迁移到 JVM 上面。并于 2013 年 2 月份正式向外发布了 RxJava 。
1.4 反应式宣言
在 2014 年 9 月 16 号,反应式宣言正式发布了 2.0 版本。在 2.0 之前,这份宣言的中文翻译标题,实际上是”响应式宣言“,而非”反应式宣言“
在反应式宣言中的 ”Reactive“ 实际上是指一个副词,表示系统总是会积极主动、甚至是智能地对内外的变化做出反应。所以这里叫反应式编程会更贴切一些.
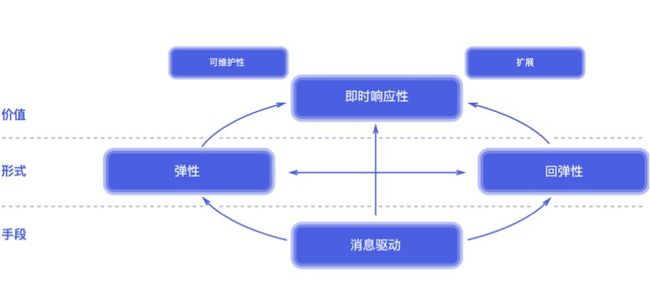
反应式宣言是一份构建现代云扩展架构的参考方案框架。这个框架主要使用消息驱动的方法来构建系统,在形式上可以达到弹性和回弹性,最后可以产生即时响应性的价值。如图 4 所示:
[ 图4 反应式编程 ]
反应式系统具有如图所示的4个特性:
即时响应性,对用户有反应: 对用户有反应我们才说响应,一般我们说的响应,基本上都说得针对跟用户来交互。只要有可能,系统就会及时响应。
回弹性,对失败有反应: 应用失败了系统不能无动于衷,不能等着它挂掉,要有反应,使其具备可恢复性。可恢复性可以通过复制、监控、隔离和委派等方式实现。在可恢复性的系统中,故障被包含在每个组件中,各组件之间相互隔离,从而允许系统的某些部分出故障并且在不连累整个系统的前提下进行恢复。当某个模块出现问题时,需要将这个问题控制在一定范围内,这便需要使用隔绝的技术,避免雪崩等类似问题的发生。或是将出现故障部分的任务委托给其他模块。回弹性主要是系统对错误的容忍。
弹性,对容量和压力变化有反应: 在不同的工作负载下,系统保持响应。系统可以根据输入的工作负载,动态地增加或减少系统使用的资源。这意味着系统在设计上可以通过分片、复制等途径来动态申请系统资源并进行负载均衡,从而去中心化,避免节点瓶颈。如果没有状态的话,就进行水平扩展,如果存在状态,就使用分片技术,将数据分至不同的机器上。
消息驱动,对输入有反应: 响应系统的输入,也可以叫做消息驱动。反应式系统依赖异步消息传递机制,从而在组件之间建立边界,这些边界可以保证组件之间的松耦合、隔离性、位置透明性,还提供了以消息的形式把故障委派出去的手段。
前三种特性(即时响应性, 回弹性, 弹性)更多的是跟你的架构选型有关,我们可以很容易理解像 Microservices、Docker 和 K8s 这样的技术对建立反应式系统的重要性。
1.5 回压
这里要特别要提一下回压(Backpressure), Backpressure 其实是一种现象,在数据流从上游生产者向下游消费者传输的过程中,上游生产速度大于下游消费速度,导致下游的 Buffer 溢出,这种现象就叫做 Backpressure 出现。这句话的重点不在于”上游生产速度大于下游消费速度”,而在于”Buffer 溢出”。回压和 Buffer 是一对相生共存的概念,只有设置了 Buffer,才有回压出现;只要设置了 Buffer,一定存在出现回压的风险。
比如我们开发一个后端服务,有一个 Socket 不断地接收来自用户的请求来把用户需要的数据返回给用户。我们服务所能承受的同时访问用户数是有上限的,假设最多只能承受 10000 的并发,再多的话服务器就有当掉的风险了。对于超过 10000 的用户,程序会直接丢弃。那么对于这个案例 10000 就是我们设置的 Buffer,当超过 10000 的请求产生时,就造成了回压的产生;而我们程序的丢弃行为,就是对于回压的处理。
对于回压我们一般有两种处理方式,一种就是上面举例中的拒绝或丢弃,这是否定应答的方式,另一种是肯定应答,先收下来,然后再慢慢处理。
1.6 Rx适用场景

[图5 适用场景 ]
Rx 适用于前端,跨平台,后端等场景,其中在Angular 2.x,vue,react版本中已经有了Rx的实现可以使用,并且作为其核心的特性在宣传;Rx支持多达18种语言,在各平台都可以使用,具有很强的跨平台特性;在后端,通过异步调用,简单的并发实现,可以实现松耦合的架构。
1.7 哪些语言或框架支持反应式编程
18种语言Rx系统的框架出现比较早,已经发布了v2版本了,Rx* 系列语言支持如下:
Java: RxJava
JavaScript: RxJS
C#: Rx.NET
C#(Unity): UniRx
Scala: RxScala
Clojure: RxClojure
C++: RxCpp
Lua: RxLua
Ruby: Rx.rb
Python: RxPY
Go: RxGo
Groovy: RxGroovy
JRuby: RxJRuby
Kotlin: RxKotlin
Swift: RxSwift
PHP: RxPHP
Elixir: reaxive
Dart: RxDart
框架支持:
RxCocoa: RxCocoa是RxSwift的一部分,主要是UI相关的Rx封装
RxAndroid: RxAndroid 源于RxJava,是一个实现异步操作的库,具有简洁的链式代码,提供强大的数据变换。
RxNetty: RxNetty 是一个响应式、实时、非阻塞的网络编程库,基于 Netty 这个著名的事件驱动网络库的强大功能。支持Tcp/Udp/Http/Https。支持>RxJava。RxNetty 在 NetFlix公司的各种产品中得到了广泛的应用。
Reactor: Reactor相对出生较晚,有发展前景Akka,scala系,用户基础薄弱
1.8. 哪些公司在用Rx

[ 图6 哪些公司在用Rx ]
2.1 Rx组成
Rx的组成包括5部分,被观察者或者叫发射源,观察者/订阅者或者叫接收源,订阅,调度器,操作符。
Observable 被观察者可以被观察者订阅,被观察者将数据push给所有的订阅者
Subscriber /Observer
Subscription 订阅可以被取消订阅
Schedulers 调度器是Rx的线程池,操作中执行的任务可以指定线程池,我们可以通过subscribeOn来指定Observable的任务在某线程池中执行Observable
也可以通过observeOn来指定订阅者/观察者们,在哪个线程执行onNext, onComplete, onError
Operators 操作符可以对数据流进行各种操作,包括创建,转换,过滤,组装,合并 ,筛选等等
我们经常用如图7所示的示例图来表示数据流动的过程。
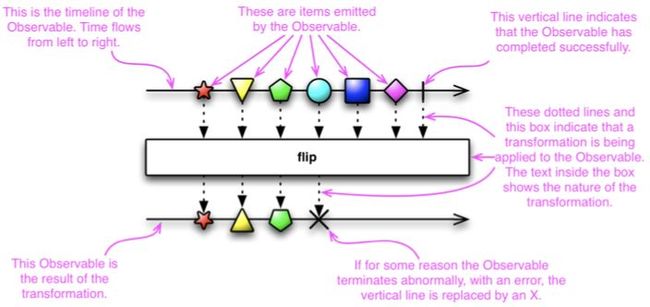
[ 图7 ]
图中上面这条线表示被观察者的时间线,表示输入,从左到右输入项,中间的各种颜色的块块是我们要观察的项,最后的竖线表示输入结束。
Flip是变换过程,对所有的项做变换。下面这条线是变换的结果,也就是输出,同样各种颜色的块块是要观察的结果的项,xx表示异常中断。
2.2 第一次体验Rx
需求如下:
从输入框获取输入,从第 10 次输入开始取前5次的输入,打印出来。
这是一个命令式编程的示例,我们需要将需求转换成命令式的描述,引入了计数变量,通过计数变量来跳过输入,然后再根据计算变量来标记取数的次数,打印出来,代码如图8所示:

[ 图8 ]
换成反应式编程,代码如图 9 所示:
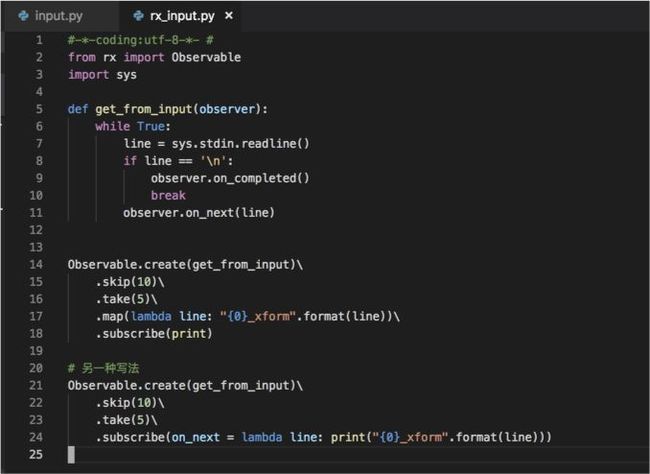
[ 图9]
这是一个反应式的面向数据流的示例,创建流,跳过前 10 个项,取前5次,打印出来。如图 10 所示为其数据流动示例。
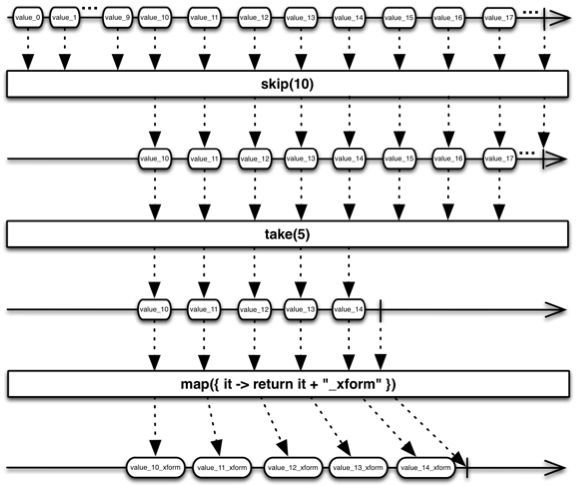
[ 图10 ]
图片来源:
https://github.com/ReactiveX/RxJava/wiki/How-To-Use-RxJava
对比命令式编程和反应式编程,区别如下:
命令式编程,重视控制(执行过程),以运算、循环、条件判断、跳转来完成任务;计算机为先的思维,指令驱动机器做事;容易引入大量状态变量
反应式编程,重视任务的解决(执行结果),关注数据转换和转换的组合;人脑思维,任务驱动,分治;明确的输入和输出状态
Rx主要是做三件事:
数据/事件的创建
组合/转换数据流
监听处理结果
下面我们以文档+代码的方式介绍这三件事情。
2.3 创建流
RxPy 有 10 种用于创建 Observable 的操作符,如下:
create – 使用 observer 方法,从头创建一个 Observable,在 observer 方法中检查订阅状态,以便及时停止发射数据或者运算。
defer — 只有当订阅者订阅才创建 Observable,为每个订阅创建一个新的 Observable。
empty/never/throw — 创建一个什么都不做直接通知完成的 Observable 创建一个什么都不做直接通知错误的 Observable 创建一个什么都不做的 Observable
from — 将一些对象或数据结构转换为 Observable
interval —创建一个按照给定的时间间隔发射从 0 开始的整数序列的 Observable
just — 将一个对象或对象集转换为发射这个或这些对象的 Observable
range — 创建一个发射指定范围的整数序列的 Observable
repeat — 创建一个重复发射特定项或序列的 Observable
start — 创建一个发射函数返回值的 Observable
timer — 创建一个在给定的延时之后发射单个数据项的 Observable
create 从头创建一个 Observable ,在 observer 方法中检查订阅状态,以便及时停止发射数据或者运算。
observer 包含三个基本函数:
onNext():基本事件,用于传递项。
onCompleted(): 事件队列完结。不仅把每个事件单独处理,还会把它们看做一个队列。当不会再有新的 onNext() 发出时,需要触发 onCompleted() 方法作为标志。
onError(): 事件队列异常。在事件处理过程中出异常时,onError() 会被触发,会发出错误消息,同时队列自动终止,不允许再有事件发出
在一个正确运行的事件序列中, onCompleted() 和 onError() 有且只有一个,并且是事件序列中的最后一个。如果在队列中调用了其中一个,就不应该再调用另一个。
示例代码见附件
2.4 变换
变换常见的操作符有 6 个:
buffer — 缓存,可以简单的理解为缓存,它定期从 Observable 收集数据到一个集合,然后把这些数据集合打包发射,而不是一次发射一个
flat_map — 扁平映射,将 Observable 发射的数据变换为 Observables 集合,然后将这些 Observable 发射的数据平坦化的放进一个单独的 Observable,可以认为是一个将嵌套的数据结构展开的过程。
group_by — 分组,将原来的 Observable 分拆为 Observable 集合,将原始 Observable 发射的数据按 Key 分组,每一个 Observable 发射一组不同的数据
map — 映射,通过对序列的每一项都应用一个函数变换 Observable 发射的数据,实质是对序列中的每一项执行一个函数,函数的参数就是这个数据项
scan — 扫描,对 Observable 发射的每一项数据应用一个函数,然后按顺序依次发射这些值
window — 窗口,定期将来自 Observable 的数据分拆成一些 Observable 窗口,然后发射这些窗口,而不是每次发射一项。类似于 Buffer,但 Buffer 发射的是数据,Window 发射的是 Observable,每一个 Observable 发射原始 Observable 的数据的一个子集
其中 flat_map 和 map 是两个非常重要的操作符,map 的操作很简单,就是传入一个函数,这个函数会将数据进行转换,一个输入对应一个输出
flat_map 和 map 不同,其返回值是一个 Observable,一个输入对应多个输出。
这两个操作的使用场景很好区分,当转换过程是同步过程时,使用 map,当转换过程是异步过程时使用 flat_map。
Group by 在工作中操作数据库的时候经常用到,就是按某个字段分组,在这里也是相同的意思,会按传递的函数生成的key来分组,注意这里的返回是一个分组的Observable,不能直接订阅,需要再做一次处理。
示例代码见附件
2.5 过滤
过滤用于从 Observable 发射的数据中进行选择,其常见操作符如下:
debounce —只有在空闲了一段时间后才发射数据,通俗的说,就是如果一段时间没有操作,就执行一次操作
distinct —去重,过滤重复数据
element_at — 取值,发射某一项数据
filter — 过滤,仅发射 Observable 中通过检测的项
first — 首项,只发射第一项(或者满足某个条件的第一项)数据
ignore_elements — 丢弃所有数据,只发射错误或正常终止的通知
last — 末项,只发射最后一项数据
sample — 取样,定期发射Observable最近的数据
skip — 跳过开始的N项数据
skip_last — 跳过最后的N项数据
take — 只发射开始的N项数据
take_last — 只发射最后的N项数据
其中最常用的是 filter,filter 就是过滤,对于数据流,仅发射通过检测的项,有点像 SQL 中的 where 条件,只是这里的条件是一个函数,他会遍历一个个项,并执行这个函数,看是否满足条件,对于 满足条件的才会给到输出流。
示例代码见附件
2.6 合并
合并操作符或者叫组合操作符,其常见如下:
and_/then/when — 通过模式 (And 条件)和计划 (Then 次序)组合两个或多个 Observable 发射的数据集
combine_latest — 当两个 Observables 中的任何一个发射了一个数据时,通过一个指定的函数组合每个 Observable 发射的最新数据(一共两个数据),然后发射这个函数的结果。类似于 zip,但是,不同的是 zip 只有在每个Observable都发射了数据才工作,而 combine_latest 任何一个发射了数据都可以工作,每次与另一个 Observable 最近的数据压合。
merge — 将多个 Observable 合并为一个。不同于concat,merge不是按照添加顺序连接,而是按照时间线来连接。
start_with — 在数据序列的开头增加一项数据。start_with 的内部也是调用了 concat
switch_latest/ — 将 Observable 发射出来的多个 Observables 转换为仅包括最近发射单个项的 Observable
zip — 使用一个函数组合多个 Observable 发射的数据集合,然后再发射这个结果。如果多个 Observable 发射的数据量不一样,则以最少的Observable 为标准进行压合。
concat — 按顺序连接多个 Observable。
其中 merge 和 concat 都是合并流,区别在于一个是连接,一个是合并,连接的时候是一个流接另一个流,合并的流是无序的,原来两个流的元素交错,当其中一个结束时,另一个就算是没有结束整个合并过程也会中断。
示例代码见附件
2.7 条件/布尔
这些操作符可用于单个或多个数据项,也可用于 Observable。其常见如下:
all — 判断所有的数据项是否满足某个条件
amb — 给定多个 Observable,只让第一个发射数据的 Observable 发射全部数据,其他 Observable 将会被忽略。
contains — 判断在发射的所有数据项中是否包含指定的数据
default_if_empty — 如果原始 Observable 正常终止后仍然没有发射任何数据,就发射一个默认值
sequence_equal —判断两个 Observable 是否按相同的数据序列
skip_until — 丢弃 Observable 发射的数据,直到第二个 Observable 发送数据。(丢弃条件数据)
skip_while — 丢弃 Observable 发射的数据,直到一个指定的条件不成立(不丢弃条件数据)
take_until — 当发射的数据满足某个条件后(包含该数据),或者第二个 Observable 发送完毕,终止第一个 Observable 发送数据。
take_while — 当发射的数据满足某个条件时(不包含该数据),Observable 终止发送数据。
示例代码见附件
实战包括以下内容:
读取QQ号码包并去重统计
从网络地址中获取数据
从数据库获取数据
文章信息关联作者名称
多线程获取网络地址中的股票数据并统计记录数
3.1 读取文件内容并统计行数
需求描述:
从文件中读取所有QQ号,并对QQ号去重统计
代码如下:
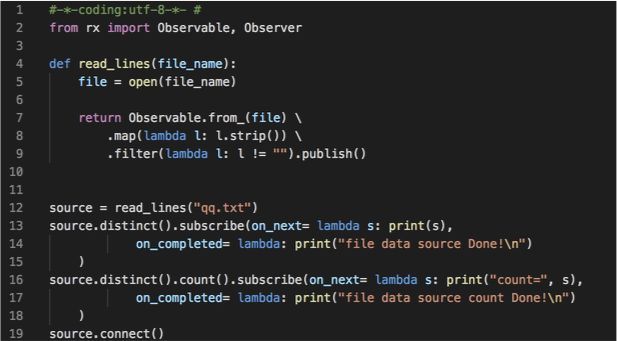
如果文件中有多列,或者是某些字符间隔,在返回的时候再多加一个map,做一次拆分即可,不用再写循环处理,更直接。这里和前面示例不同在于有一个publish。publish 将一个普通的 Observable 转换为可连接的,可连接的Observable 和普通的Observable差不多,不过它并不会在被订阅时开始发射数据,而是直到使用了 Connect 操作符时才会开始,这样可以更灵活的控制发射数据的时机。比如我们这里需要有多个观察者订阅的时候。
3.2 从网络地址中获取数据
需求描述:
获取新浪的美股接口数据,并打印出股票名和价格
代码如下:
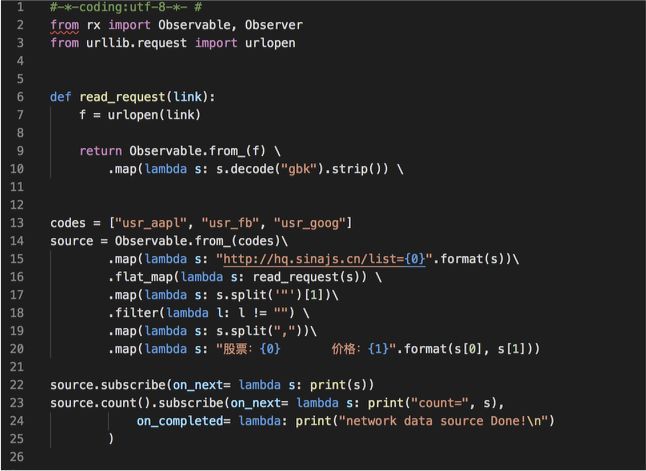
3.3 从数据库获取数据
需求描述:
从MySQL数据库中读取用户信息并打印出来
代码如下:
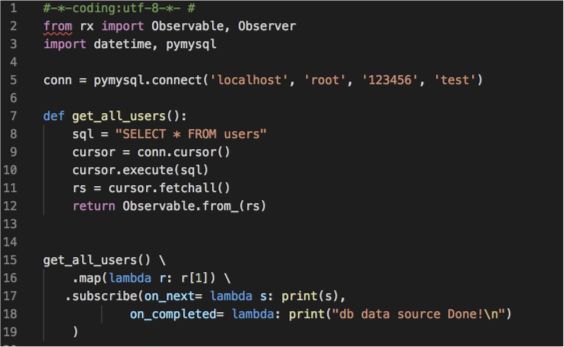
3.4 文章信息关联作者名称
需求描述:
将文章信息列表关联作者名称
代码如下:
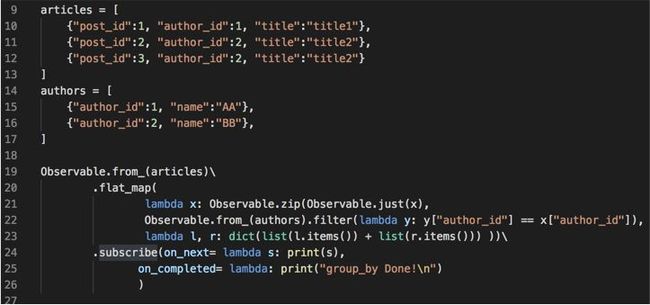
3.5 多线程获取网络地址中的股票数据
需求描述:
以多线程的方式,按列表读取新浪接口美股的数据
代码如下:
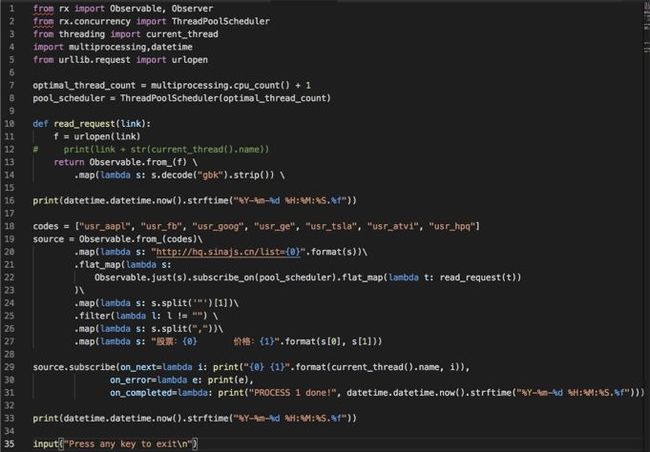
4. 小结
4.1 一些坑
理解 Rx 最关键的部分,就是理解 Rx 的流,包括流的源头(Observable)、操作 (Operation)、和终点 (Subscription)。
流的初始化函数,只有在被订阅时,才会执行。流的操作,只有在有数据传递过来时,才会进行,这⼀切都是异步的。(错误的理解了代码执行时机)
在没有弄清楚 Operator 的意思和影响前,不要使用它。
小心那些不会 complete 的 observable 和收集类型的操作符比如 reduce, to_list, scan 等,必须等到 Observable complete,才会返回结果。如果发现你的操作链条完全不返回结果,看看是不是在不会 complete 的observable 上使用了收集型的操作符
4.2 反应式思考
传统代码通常是命令式的,顺序的,并且一次只关注一个任务,而且还必须协调和管理数据状态
现实中的数据都是在运行中的,股市价格一直在变,微博不停的有新的话题出来,抖音不停的有人上传新的视频
现实中也有静态的数据,比如没有更新的数据库,文件等,我们通过查询这些静态数据,将静态数据建模为动态的,从而将其与实时的事件流组合到一起,将静的数据动起来。
事件驱动和反应式编程的区别:事件驱动式编程围绕事件展开,反应式编程围绕数据展开
当构建传统基于事件的系统时,我们经常依赖于状态机来决定什么时候从事件中退订,Rx允许我们以声明的方式指定结束条件的事件流,一旦事件流结束,它会清除所有未退订订阅
声明式编程,专注于要做什么(what to do),命令式编程,专注于该怎样做(how to do)
反应式编程已经在淘宝有一些应用,比如在淘宝的猜你喜欢,我的淘宝,都已经实践,其QPS,RT都有较大优化效率,这些点的应用需要对整个业务框架做一次升级 ,主要包括编程框架、中间件,以及业务方的升级等。
其中中间件的升级,包括服务框架(RPC)、网关、缓存、消息(MQ)、DB(JDBC)、限流组件、分布式跟踪系统、移动端 Rx 框架等等。这是一个很大的升级。而反应式架构在各个模块上基本都有成熟的方案,除了个别领域如数据库,基本没有特别的瓶颈。
学习反应式编程主要在于思维转换,因为之前主要使用同步式命令式编程的思维写程序,突然要换成以流的方式编写,思维必须要做转换,比如如何通过使用类似匹配、过滤和组合等转换函数构建集合,如何使用功能组成转换集合等等,当思维转变后,一切都会变得非常自然和顺滑。
这篇文章从网上找了很多的资料,面网上的资料非常有限,特别是RxPy的,基本只有官方的说明文档。
谨以此抛砖,希望有更多的同学可以了解多一种编程范式,把它融入到我们的编程工作中,把反应式编程变成我们手中的利器。
6. 参考资料
Rx(Reactive eXtension)官网 http://reactivex.io/
https://zhuanlan.zhihu.com/p/27678951
https://www.jianshu.com/p/757393ee4a2f
https://blog.csdn.net/maplejaw_/article/details/52396175
《维基:响应式编程》
《响应式架构与 RxJava 在有赞零售的实践》
《全面异步化:淘宝反应式架构升级探索》
