Learning Rich Features at High-Speed for Single-Shot Object Detection
Learning Rich Features at High-Speed for Single-Shot Object Detection
abstract
单级目标检测方法因其具有实时性强、检测精度高等特点,近年来受到广泛关注。通常,大多数现有的单级检测器遵循两个常见的实践:它们使用在ImageNet上预先训练的网络主干来完成分类任务,并使用自顶向下的特征金字塔表示来处理规模变化。作者研究了一个单阶段检测框架,它结合了微调预训练模型和从零开始训练的优点。作者的框架构成了一个标准的网络,使用一个预先训练的主干和一个并行的轻型辅助网络从零开始训练。此外,作者认为通常使用的自顶向下的金字塔表示只关注于将高级语义从顶层传递到底层。然而在作者的检测框架中引入了一个双向网络,它可以有效地传递中低层次和高层次的语义信息。
然后说了一下实验效果好。
1.Introduction
由于深度学习的发展,目标检测也进一步提高,现在的目标检测主要分为2中:一种是单阶段检测,还有一种是两阶段检测。一般来说,两阶段检测是控制准确度,而单阶段方法的主要优势是速度快。现在的目标是让单阶段的检测正确虑也有所提高,在大中型物体的检测中,结果还行,但是在小型物体上检测结果就一般。因此小对象检测是具有挑战性的。
现在的单级方法通常使用更深的网络主干为分类任务在数据集上预先训练。然后,这些检测框架对目标对象检测数据集上的预先训练的网络骨架进行细化,从而实现收敛。
研究表明,训练检测模型从零开始解决这个问题,导致精确定位。但是与基于微调的对应网络相比,从零开始训练时间花费多。因此作者引入一个训练模型,将训练前的和从零开始训练的优点结合起来,该框架使用一个虚报脸前的主干和一个从零开始训练的浅辅助网络。
2.Baseline fast detection framework
在这项研究中,作者采用零流行的ssd框架作为基线。标准的SSD采用的是VGG-16作为骨干网络的架构。SSD从conv4 3层开始,进一步包括从原来的VGG-16网络的fc7层(转换成conv层),同时截断网络的最后一个全连接(FC)层。然后,它添加几个逐渐变小的conv层,即在最后的conv8 2、conv9 2、conv10 2和conv11 2用于预测。
如前所述,标准SSD采用了金字塔式的特征层次结构,在不同分辨率的层上执行独立的预测。然而,这样的金字塔表现与大尺度的变化斗争,特别是在检测小尺寸的物体。这可能是由于与后一层相比,SSD的前一层(例如conv4 3)的语义信息有限。此外,标准SSD中的金字塔特征层次是从网络的上层开始的,如VGG-16中的conv4 3层。针对这一问题最常见的解决方案有:通过深化模型来更好地提取特征等方法,下面来说作者咋解决这些问题的。
3. Our Approach
Overall Architecture:
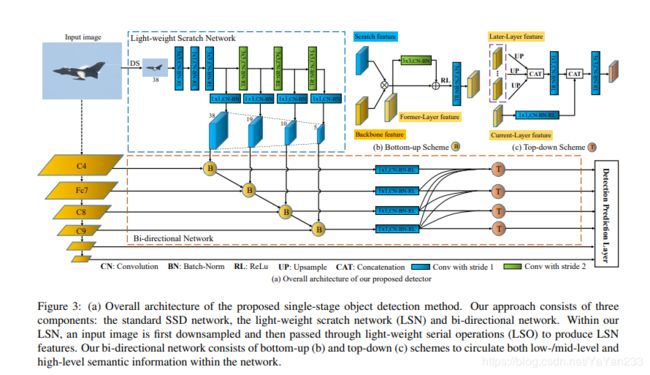
描述:作者说网络是由3个部分组成的:标准SSD网络 ,轻量级scratch网络(LSN)和双向网络组成。首先对输入的图像进行采样,然后通过轻量级串行操作(LSO)生成LSN特征,双向网络有自底向上和自顶向下两种方案组成,在网络中传递低/中级个高级语义信息。
用VGG-16作为主干,然后LSN产生一个低层/中层特征表示,然后注入到后续标准预测层的主干特征中,以提高性能。然后,将当前层和以前层的结果特性以自底向上的方式组合在双向网络中。双向网络中的自顶向下方案包含独立的并行连接,将高级语义信息从网络的后一层注入到前一层。
不同:
作者的双向网络与现有的几个单级检测器使用的特征金字塔网络(FPN)相比有以下不同之处。
首先,FPN的自底向上部分遵循了标准中使用的CNN的金字塔特征层次结构SSD的框架。FPN和SSD的自底向上部分都遵循骨干网的前馈计算,建立了特征层次结构。除了FPN/标准SSD中的自底向上部分外,我们的双向网络中的自底向上方案以级联的方式将前一层的特性传播到后一层。此外,FPN中的topdown金字塔通过级联操作逐层融合了许多CNN层。在双向网络的自顶向下方案中,预测层通过独立的并行连接进行融合,而不是逐层逐层的级联/顺序融合。
3.1. Light-Weight Scratch Network
LSN Feature Extraction:
现有检测框架中常用的特征提取策略是在多个卷积块和最大池化层的重复堆栈中从网络主干(如VGG-16)中提取特征,以产生语义强的特征。这种特征提取策略有利于更倾向于平移不变性的图像分类任务。与图像分类不同的是,目标检测还需要精确的目标轮廓,局部的中低层特征(如纹理)信息也是关键的。为了补偿来自预训练网络的主干特征信息的损失,我们的LSN采用了一种备选的特征提取方案。首先,通过池化操作将输入图像向下采样到第一个SSD预测层的目标大小,然后通过轻量级的串行操作传递图像(LSO)包括卷积、批处理模和ReLU层。我们的LSN是用随机初始化从零开始训练的。它遵循类似于标准SSD的金字塔特征层次结构,构造为:
![]()
其中n为匹配标准SSD预测层大小而选择的特征金字塔层数。我们首先将输入图像I向下采样到第一个SSD预测层的目标大小。然后,我们使用产生的下采样图像It生成初始LSN特征sint(0):
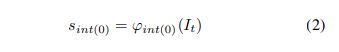
ϕint(0)表示连续操作,包括一个3×3和一个1×1 conv.块。然后使用初始特征sint(0)生成中间特征集sint。第k个中间特征是用
(k−1)中间特征:![]()
其中k =(1,…、n)和ϕint (k)(。)表示一个3×3 conv.块。当k = 1时,第(k - 1)个中间特征等于第一个LSN特征。接下来,我们对第k层中间特征应用1×1的对流块,生成Sp的第k层LSN特征:
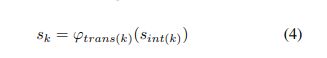
trans (k)(.)表示1×1 conv.块变换LSN特性渠道来匹配相应的标准SSD特性
3.2. Bi-directional Network
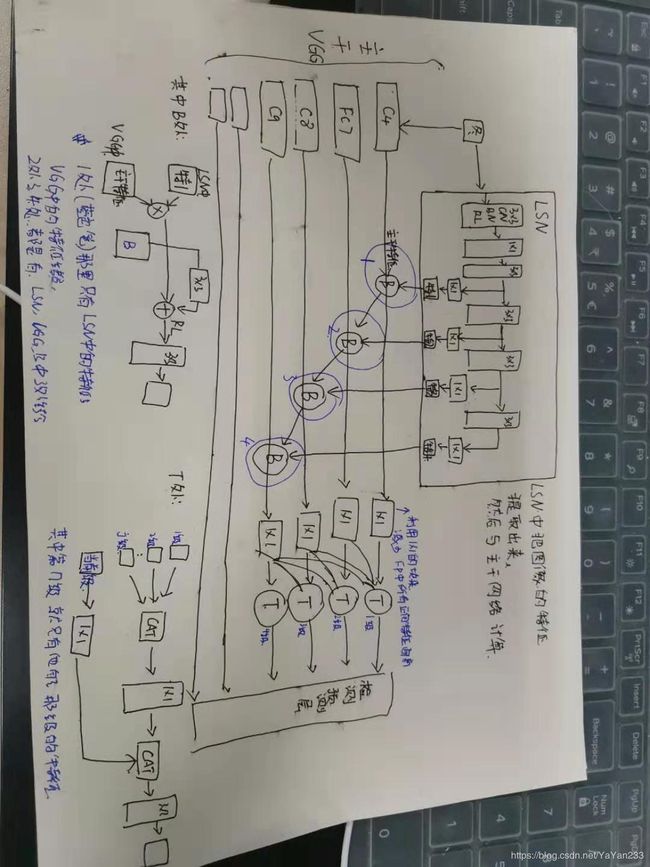
我理解的大致这样,,,实在不想翻译了。。。。 我实在不会旋转 我好菜啊

4.实验
说了一下作者用的数据集,以及一些测试数据,就证明这个网络比以前的好使
就这样把 不看了
对小对象的检测还不错,然后时间也OK