MMDetection: Open MMLab Detection Toolbox and Benchmark
Abstract:
本文提出了一个包含丰富的目标检测与实力分割算法以及相关组件与模块的目标检测工具箱,称为MMDetection。这个工具箱最开始是作为COCO Challenge2018检测跟踪冠军队伍的codebase。最终这个工具箱演化成了一个包括许多流行的目标检测方法与相关模块的统一平台。它不仅包括训练与推理代码,还提供了超过200种网络模型权重。我们认为这个工具箱是目前最完善的检测工具箱。本文中,我们会介绍这个工具箱的多样化特征。此外,我们还对不同方法、组件以及超参数进行了benchmark的研究。我们希望这个工具箱与benchmark可以快速发展的研究社区提供灵活的工具箱进行现有方法的复现与新检测器的开发。代码与模型可以在https: //github.com/open-mmlab/mmdetection找到。这个项目还在活跃的开发进程中,我们会保持这个文档的更新。
1、Introduction
目标检测与实例分割都是计算机视觉任务的基础。目标检测框架往往比分类任务要复杂的多,不同的实现设置可能导致结果很大的不同。为了实现提供高质量codebase与统一benchmark的目标,我们构建了MMDetection,一个基于PyTorch【24】的目标检测与实例分割CodeBase。
MMDetection的主要特征包括:(1)模块化设计。我们将目标检测框架分解成不同组件,使得可以很容易的通过不同模块的组合来构建一个用户化目标检测框架。(2)支持多个开箱即用的框架。工具箱支持流行的与最新的目标检测框架,见第二节中的详细列表。(3)高效。所有的基础bbox与mask操作都是跑到GPU上的。训练数据比其他codebase,例如Detectron【10】、maskrcnn-benchmark【21】与SimpleDet【6】等更快或者相当。(4)State of the art。这个工具箱源于由赢得COCO Detection Challenge 2018比赛的MMDet队的codebase,我们持续向前推进。
除了引入codebase与benchmark的结果,我们还报告了我们训练目标检测器过程中的经验与最好方式。我们还进行并讨论了超参数、结构、训练策略的消融实验。我们希望这些研究可以对后续的研究有用并且促进不同方法见的对比。
余下章节组织如下。我们首先介绍了MMDetection支持的一系列方法与其重要的高光特征,并展示了benchmark结果。最后,我们展示基于一些选出来baseline的消融研究。
2、Supported Frameworks
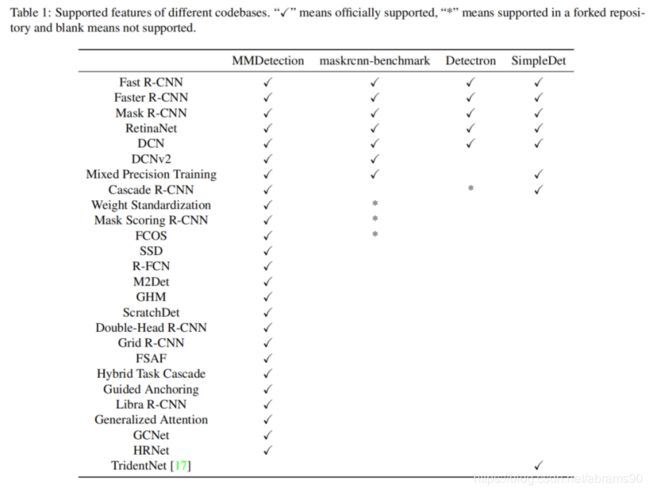
MMDetection包含了流行目标检测与实力分割方法的高质量复现。表1展示了MMDetection与其它框架相比的框架支持与特点。MMDetection比其它codebase支持更多的方法与特征,特别是新方法。下面给出了一个列表。
2.1 Single-stage Methods
- SSD【19】:一个典型且广泛应用简单模型结构的单阶段目标检测器,于2015年提出。
- RetinaNet【18】:2017年提出的一种使用Focal Loss的高性能单阶段目标检测器。
- GHM【16】:2019年提出的一种基于梯度协调机制优化单阶段目标检测器的方法。
- FCOS【32】:2019年提出的一种无锚点全卷积的单步检测器。
- FSAF【39】:2019年提出的一种基于无锚点特征选择模块的单步检测器。
2.2 Two-stage Methods
- Fast R-CNN【9】:2015年提出的一种需要预先计算proposal的一种经典目标检测器。
- Faster R-CNN【27】:2015年提出的一种经典切广泛使用的可以端到端训练的检测器。
- R-FCN【7】:2016年提出的一种比Faster R-CNN速度更快的全卷机检测器。
- Mask R-CNN【13】:2017年提出的一种广泛使用经典目标检测与实力分割方法。
- Grid R-CNN【20】:2018年提出的一种网格引导定位机制作为bbox回归的选择之一。
- Mask Scoring R-CNN【15】:2019年提出的一种通过预测mask IoU的基于mask R-CNN的改进。
- Double-Head R-CNN【35】:2019年提出的一种分类与定位利用不用head实现的方法。
2.3 Multi-stage Methods
- Cascade R-CNN【2】:2017年提出的一种强大的多阶段目标检测方法。
- Hybrid Task Cascade【4】:2019年提出的一种多阶段多分支检测与实力分割方法。
2.4 General Modules and Methods
- Mixed Precision Training【22】:2018年提出的一种利用半精度FP16训练的方法。
- Soft NMS【1】:2017年提出的一种新的NMS方法。
- OHEM【29】:2016年提出的一种在线挖掘困难样本的训练方法。
- DCN【8】:2017年提出的可行变卷积与可行变RoI Pooling方法。
- DCNv2【42】:2018年提出的模块化可形变操作。
- Train from Scratch【12】:2018年提出的一种用随机初始化代替ImageNet预训练模型的训练方法。
- ScratchDet【40】:2018年提出的从头训练另外一种尝试。
- M2Det【38】:2018年提出的用于构建更加有效的特征金字塔的新特征金字塔网络。
- GCNet【3】:2019年提出的可以高效建模全局上下问的全局上下文模块。
- Generalized Attention【41】:2019年提出的通用注意力机制。
- SyncBN【25】:跨GPU的同步BN方法,我们将官方实现适配到了PyTorch上了。
- Group Normalization【36】:2018年提出的BN的另外一种选择。
- Weight Standardization【26】:2019年提出的一种小批量训练过程中标准化卷健全权重的方法。
- HRNet【30,31】:2019年提出的一种专注于学习可依赖高分辨率表发的新backbone。
- Guided Anchoring【34】:2019年提出的一种预测稀疏与任意形状锚点的新锚点机制。
- Libra R-CNN【23】:2019年提出的一种检测器平衡训练的新框架。
3、Architecture
3.1 Model Representation
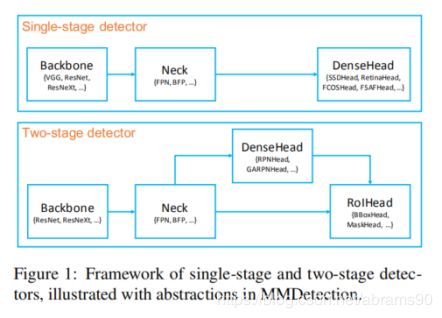
尽管不同检测器的模型结构是不同的,他们却又类似的组件,大致可以分到下列几个类别:
Backbone Backbone是将图片转化成特征图的步骤,例如没有最有一个全连接层的ResNet50。
Neck Neck是链接backbone与head的部分。它的作用是对Backbone产生的特征图进行一些优化或者重组。Feature Pyramid Network(FPN)就是一个典型的例子。
DenseHead(AnchorHead/AnchorFreeHead) DenseHead是在特征图上进行密集定位的操作之一,包括AnchorHead与AnchorFreeHead两种,例如RPN-Head,RetinaHead,FCOSHead。
RoIExtractor RoIExtractor是利用类RoIPooling操作从单个或者多个特征图提取RoIwise特征的部分。SingleRoIExtractor是从相应等级特征金字塔中提取RoI特征的例子。
RoIHead(BBoxHead/MaskHead) RoIHead是将RoI特征作为输入,进行RoIwise任务型预测的部分,例如bbox分类回归,掩膜预测。
通过上述抽象,单步与两步检测器框架如图1。我们可以通过简单的创建一个新组件并与现有的进行组合的方法开发我们自己的方法。
3.2 Training Pipline
我们利用连接机制创建统一的训练流水线。这个流水线不仅仅可以用在目标检测上,还可以用在其它例如图片分类与语义分割等计算机视觉任务上。
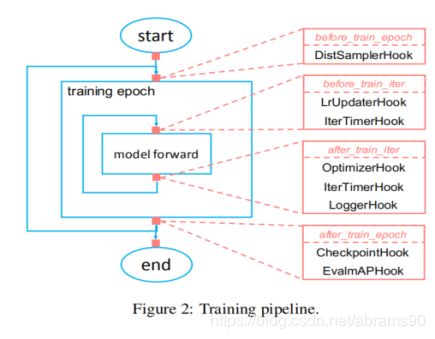
许多任务的训练过程共享类似的工作流,训练过程中训练迭代与验证迭代轮流进行,其中验证迭代是可选部分。每个epoch中,我们进行许多向前推理与向后传播。为了使得流水线更灵活更用户可定制,我们定义了一个最小化流水线仅仅重复进行模型前向运算。其它的通过连接 机制进行定义。为了运行一个用户自定义的训练过程,我们可能希望在一些特定步骤前后进行一些自定义操作。我们定义了一些时间点用户可以注册任何方法(hooks),包括before_run,before_train_epoch,after_train_epoch,before_train_iter,after_train_iter,before_val_epoch,after_val_epoch,before_val_iter,after_val_iter,after_run。注册连接依据优先级的原则在特定时间点出发。典型的MMDetection训练框架如图2所示。评估epoch由于我们在每一个epoch都进行评估所以就不做显示。如果指定就与训练epoch的流程一致。
4、Benchmarks
4.1 Experimental Setting
Dataset。MMDetection支持VOC与COCO样式数据集。由于更高的挑战性与更广泛的使用,我们将MS COCO 2017作为左右实验的主要benchmark。我们使用train部分训练,val部分报告表现。
Implementation details。如果没有另外指定,我们遵循以下设置。(1)在不改变长宽比的情况下最大尺寸resize到1333*800。(2)我们使用8块V100GPU进行训练,总batchsize为16(每块GPU2张样本),推理使用1张V100。(3)训练节点安排与Detectron【10】一致。“1x”“2x”分别表示12epoches与24epoches。“20e”用于cascade模型,表示20epoches。
Evaluation metrics。我们使用COCO数据集上的标准评估防范,这里使用了多个IoU阈值从0.5到0.95。RPN的结果通过平均召回率(AR)衡量,检测结果通过mAP评估。
4.2 Benchmarking Results
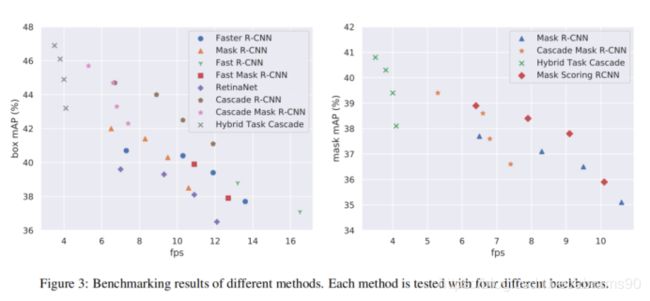
Main results。我们在COCO2017验证集上建立不同方法的基准,包括SSD【19】,RetinaNet【18】,Faster RCNN【27】,Mask RCNN【13】与Cascade R-CNN【18】,Hybird Task Cascade【4】与FCOS【32】。我们使用四个广泛使用的骨干网络评估所有方法的结果,例如ResNet-50【14】,ResNet-101【14】,ResNet-101-32x4d【37】与ResNetXt-101-64x4d【37】。我们在图3种报告了这些方法的速度与bbox/mask的AP。推理时间是在单张Tesla V100显卡上测试出来的。
Comparison with other codebases。除了MMDetection还有其他流行的codebase例如Detectron【10】,maskrcnn-benchmark【21】与SimpleDet【6】。他们分别基于例如caffe2、PyTorch【24】与MXNet【5】这样的深度学习框架构建的。我们从三个角度分别将MMDetection与Detectron、maskrcnn-benchmark和SimpleDet进行对比:性能、速度与内存。Mask R-CNN与RetinaNet分别用来代表两步与单步检测器。由于这些codebase也是在不断开发过程中,报告中的模型可能也不是最新的了,并且有可能是在不同硬件条件下测试出来的。为了进行公平的对比,我们pull最新的代码,并且在相同环境下进行测试。结果在表2种展示。不同框架对于内存占用的衡量方式不同。MMDetection记录的事所有GPU最大的内存占用,maskrcnn-benchmark报告的是GPU0,都是使用PyTorch API的 “torch.cuda.max memory allocated()”接口。Detectron利用caffe2的API报告内存“caffe2.python.utils.GetGPUMemoryUsageStats()”,SimpleDet通过英伟达官方提供的nvidia-smi命令来记录内存。整体来说,MMDetection与maskrcnn-benchmark实际内存使用量类似,比其它的框架要低。

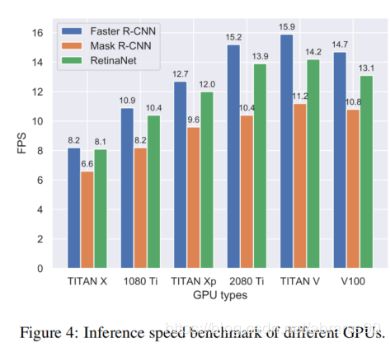
Inference speed on different GPUs。不同的研究人员可能使用不同种类的GPU,这里我们在通用GPU上展示速度的benchmark,例如TITAN X,TITAN Xp,TITAN V,GTX 1080Ti,RTX2080Ti与V100。我们在每种GPU上评估三个模型,在图4上展示了推理速度。要注意的是,这些服务器的硬件并不完全相同,例如CPU、硬盘等可能不一样,但是还是可以为我们提供一个速度benchmark的基本认知。
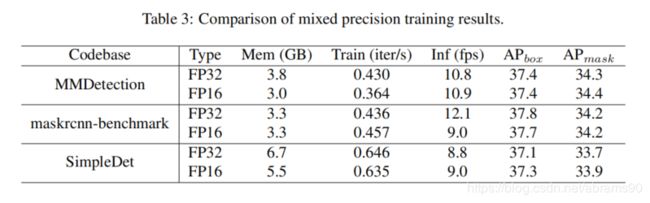
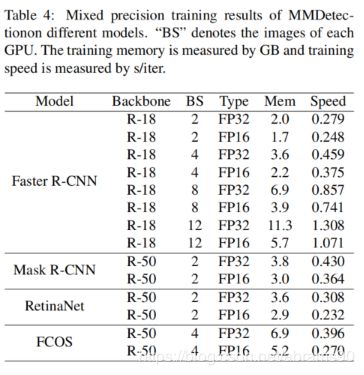
Mixed precision training。MMDetection支持混合精度训练从而降低GPU现存,加速模型训练,同时保持精度基本不变。Maskrcnn-benchmark通过apex支持混合精度训练,SimpleDet也有它自己的实现。Detectron目前还不支持。表3中我们介绍了实验结果以及与其它两个codebase的对比。我们相同的V100节点测试了所有的codebase。此外,我们还研究了更多的模型来探索混合精度训练的有效性。如表4所示,我们知道了大的batchsize会更省显存。当batchsize到12后,FP16训练的显存占用几乎只有FP32训练的一半。此外,混合精度训练当用在像RetinaNet这样的简单框架上时训练更高效。
Multi-node scalability。由于MMDetection支持多节点分布式训练,我们分别在8/16/32/64块GPU的场景下测试了他的扩展性。我们使用Mask R-CNN作为benchmark方法,在另外一个V100集群上进行了实验。依照【11】中的步骤,基础学习率根据batchsize的大小线性调节。实验结果如图5所示,多节点给MMDetection带来了几乎线性的加速。

5、Extensive Studies
通过MMDetection,我们对重要组件与参数进行了扩展学习。我们希望这项研究可以为不同方法与设置间的公平对比做出一点贡献。
5.1 Regression Loss
目标检测器训练过程中通常会使用多任务损失函数,包括分类与回归分支。最广泛应用的回归损失函数是Smooth L1 Loss。最近,越来越多的回归损失函数提了出来,例如,Bounded IoU Loss【33】,IoU Loss【32】,GIoU Loss【28】,Balanced L1 Loss【23】。L1 Loss也是一种简单的变体。然而这些损失函数通常在不同方法不同设置下实现。这里我们在相同的环境下评价所有损失函数。值得注意的是最终的表现与回归损失函数的权重有关,因此我们进行粗略的网格化搜索来寻找每种损失函数最佳的损失权重。
表5中展示的结果展示了简单增加Smooth L1 Loss权重的结果,最终的结果可以提升0.5%。不调整损失权重,L1 Loss比Smooth L1权重提升了0.6%,然而增加损失权重不会带来额外增加。L1 Loss比Smooth L1损失函数的值要大得多,特别是对于相对准确的BBOX来说。【23】中的分析指出,累积较好定位BBox的梯度可以更好的定位。L1 Loss已经相对较大,因此增加损失权重不会变的更好。Balanced L1 Loss在端到端Faster R-CNN上带来了0.3%的mAP提升,与【23】中使用预先计算好的proposal区域有些许不同。然而我们发现Balanced L1 Loss在提出的IoU balanced sampling或者balanced FPN带来更高的增益。IoU-based loss比L1-based Loss使用优化的损失权重效果要略好,除了Bounded IoU Loss。GIoU Loss比IoU Loss要高0.1%,Bounded IoU Loss与Smooth L1 Loss表现相似,但是需要更大的损失权重。
5.2 Normallization Layers
由于GPU显存限制,训练检测器时batchsize通常是1或2,因此BN层通常冻结成一种典型的计算方法。BN层有两种参数选项。(1)是否更新E(x)与Var(x),(2)是否优化仿射权重γ与β。遵从PyTorch参数命名方法,我们将(1)和(2)分别表示为eval与required_grad。Eval=True表示统计值没有更新,requires_grad=True表示γ与β在训练过程中也优化了。除了freezing BN层外,还有另外一种使用小batchsize解决问题的正则化层,例如Synchronized BN(SyncBN)【25】与Group Normalization(GN)【36】。我们首先backbones上的BN层不同设置,然后与SyncBN与GN进行对比。
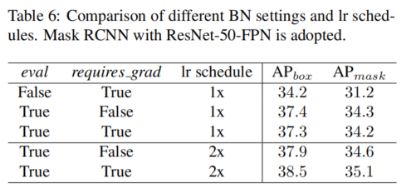
BN settings。我们Mask R-CNN上评估不同eval与required_grad组合,依照1x与2x的方法。表6种的结果展示了小batchsize更新statistics会严重的降低表现,当我们分别重新计算statistics(eval=false)并且固定仿射权重(requires_grad=True),bbox AP低了3.1%,mask AP低了3%。当使用1x学习率方法时,是否固定仿射权重带来与0.1%的细微差别。当使用更长的lr计划时,仿射权重可训练比固定带来与0.5%的提升。在MMDetection中,默认设置是eval=True,required_grad=True。
Different normalization layers。Batch Normalization(BN)广泛应用在现在的CNN模型上。然而它严重依赖大的batchsize来精确估计统计值E(x)与Var(x)。目标检测中,batchsize通常比分类中的小得多,典型的解决方案是用预训练backbone中的参数,在训练时不对他们进行更新,表示为FrozenBN。最近,SyncBN与GN方法提了出来,并证明了他们的有效性【36,25】。SyncBN跨多GPU计算均值与方差,GN将各个通道的特征分成组,计算每组的均值与方差,这些方法帮助战胜了小batchsize问题。在MMDetection中,FrozenBN、SyncBN与GN可以通过简单的配置文件修改设置。
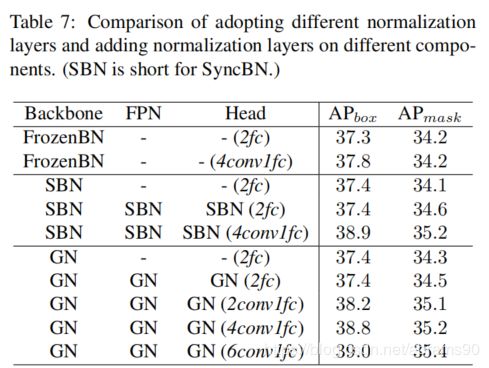
这里我们有两个研究问题。(1)不同的正则化方法如何进行对比(2)检测器中什么位置添加BN层。为了回答这两个问题,我们ResNet-50-FPN的Mask R-CNN进行了三个实验,将其中的BN层分别替代为FrozenBN,SyncBN与GN。按照【36】中设置将group参数设置为32。其它参数设置与模型结构保持一致。在【36】中,efcbbox的头替代为4conv2fc,GN层也添加到FPN与bbox/mask头。为了研究这两个变化,我们额外进行了两组实验。此外,我们探索了bbox head 卷积层数量的影响。
表7中的结果显示(1)FrozenBN,SyncBN与GN在我们仅仅将backbone中的BN替换的情况下表现相近。(2)将SyncBN或者GN加到FPN与bbox/mask head不会来带任何优化。(3)将2fc bbox head提黄为4conv1fc 并且在FPN与bbox/mask head中增加正则化层可以带来与1.5%的提升。(4)bbox head中更多的卷积层可以带来更多的表现提升。
5.3 Training Scales
常见的方式是将训练样本在不改变长宽比的前提下resize到预定吃尺寸。之前的研究通常将尺寸设置为1000x600,当前更多设置为1333x800。MMDetection中,我们将1333x800设置为预定义训练尺寸。作为一种数据扩展方法,多尺度训练的方法通常也被使用。没有系统性的研究来研究如何去评估选择训练的尺度。要知道这对于更有效更高效的训练十分重要。当使用多尺度训练的方法时,每次迭代中的尺度选择是随机的,图片会在每次迭代中resized到选择的大小。当前有两种主流的随机选择方法,一种是预定义一些列尺度并随机选择,另外一种是定义尺度范围,随机在最大最小值间选择。我们将第一种称为value模式,第二种称为range模式。Range模式可以看为value模式的一种,预定义的尺度间距为1。
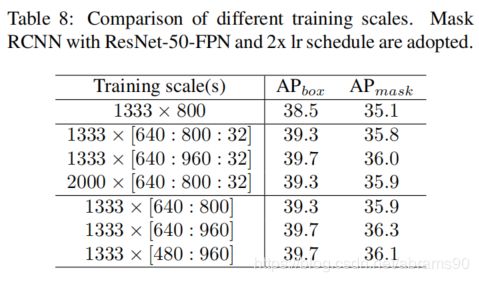
我们利用不同尺度与随机模式训练Mask R-CNN,使用2xlr计划,因为更多的数据扩展意味着更长的lr计划。结果如表8所示,其中1333x[640:800:32]意味着长边固定为1333,短边随机从{640,672,704,736,768,800}中选择,对应为value模式。1333x[640:800]这样的设置意味着短边随机从640到800间进行选择,对应range模式。结果中我们可知range模式与value模式在变化的最大最小尺度相同情况下相比基本一致或者稍微好一点。通常更宽的范围带来更多的改进,特别是对更大的最大值来说。特别指出,[640:960]比[640,800]的bbox与mask AP分别高0.4%与0.5%。但是更小的最小尺度例如480不会带来更好的表现。

5.4 Other Hyper-parameters
MMDetection主要遵循Detectron中的参数设置并且探索我们自己的实现。通过实验,我们发现Detectron中的超参并不是最优的,特别是对于RPN来说。在表9中我们列出了那些可以进一步优化RPN表现的方法。尽管tuning可能会带来优化,MMDetection中我们使用与Detectron一样的初始化设置,并且将此作为参考。
Smoothls_beta。大多数检测方法使用Smooth L1 loss作为回归损失函数,实现为![]() 。参数beta是L1 term与MSELoss term的阈值。RPN中默认设置为1/9,依据实验中回归误差的标准方差。实验结果显示,更小的beta可能可以带来RPN的average recall(AR)些许提升。在5.1的研究中,我们发现L1 Loss在权重为1时比Smooth L1表现更好。当将beta设置为更小的值时,Smooth L1 Loss会接近L1 Loss,并且相应的损失权重越大,表现越好。
。参数beta是L1 term与MSELoss term的阈值。RPN中默认设置为1/9,依据实验中回归误差的标准方差。实验结果显示,更小的beta可能可以带来RPN的average recall(AR)些许提升。在5.1的研究中,我们发现L1 Loss在权重为1时比Smooth L1表现更好。当将beta设置为更小的值时,Smooth L1 Loss会接近L1 Loss,并且相应的损失权重越大,表现越好。
Allowed_border。RPN中,特征图上的每个位置都会产生预定义的锚点。超过边界的锚点在训练时会被忽略。当设置为0时意味着所有越过边界的锚点都会被忽略。然而我们发现放宽这个约束是有益的。如果我们将它设置为无限,意味着没有锚点会被忽略,AR会从57.1%提升到57.7%。这样,靠近边界的GT在训练过程中会有更多的匹配。
Neg_pos_ub。我们新增了这个参数用于采样正负锚点样本。当训练RPN时,当正锚点样本不足情况出现的时候,通常会通过采样更多的负锚点样本来保证训练样本量。这里我们探索使用neg_pos_ub来控制正负样本比例的上限。将neg_pos_ub设置为无限带来之前提到的采样问题。这种默认方式有时候会带来正负样本分布失衡的问题。通过将参数设置为一个有效值,例如3或5,意味着我们最多可以采样比正样本多3、5倍的负样本,这带来了1.2%或1.1%的提升。
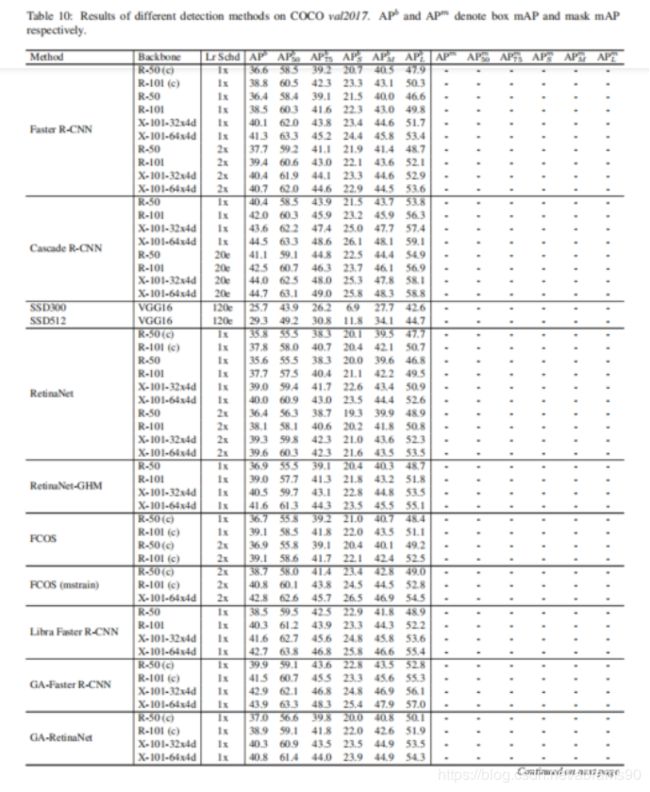
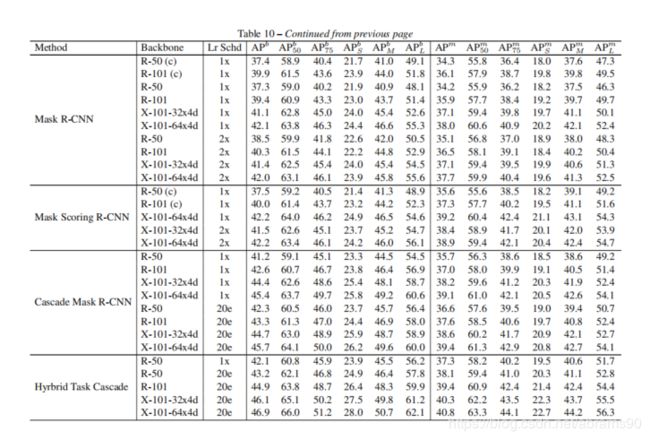
A Detailed Results
我们在表10中展示了一些方法的详细的benchmark。R-10与R-50(c)展示了pytorch与caffe风格的ResNet-50backbone。在bottleneck residual block,pytorch风格ResNet使用1x1 stride-1卷积,跟随3x3 stride-2卷积层,而caffe风格的ResNet使用1x1stride-2卷积层,跟随3x3 stride-1卷积层。更多设置与组件请参考https://github.com/open-mmlab/mmdetection/blob/master/MODEL_ZOO.md。