1-1 C语言手撕高斯朴素贝叶斯 - 通过身高和体重推测性别(机器学习)
目录
目录
目录
项目介绍
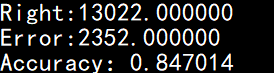
项目1-1的准确度
项目可行性:原理简介
高斯分布(正态分布)
朴素贝叶斯
代码流程
获取数据(数据清洗)
代码实现
头文件 allHead.h
源文件 handleData.cpp
源文件及主函数 naiveBayes.cpp
项目介绍
1-1 通过身高、体重推测性别
1-2 通过身高、体重、肺活量推测性别
1-3 MPI优化
1-4 OpenMP优化
项目1-1的准确度
本项目用了150行C语言代码实现高斯-朴素贝叶斯,虽受限于数据集的特征值少,但预测结果准确度仍有84.7%。

项目可行性:原理简介
高斯-朴素贝叶斯即高斯分布(正态分布)+朴素贝叶斯。
高斯分布和朴素贝叶斯都是高中知识这里就不科普了,具体百度就好。
高斯分布(正态分布)
通过以往的科学研究发现,人类的身高和体重基本满足高斯分布的。
找了许多资料发现,其实人类的身高在几个区间特别集中,图像是有几个峰值的高斯分布曲线。
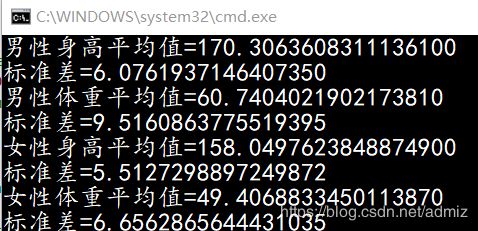
我们可以通过数据集来获取高斯分布所需要的:平均值(u)、标准差(p)。
//dataSet是数据集
double u=0; //平均值
double p=0; //标准差
//求平均值
for(i=0;i只要有了平均值和标准差,我们就能通过高斯分布的概率密度函数来获得以下这四个概率:
P(身高=160|性别=女性)、P(体重=50|性别=女性)
P(身高=160|性别=男性)、P(体重=50|性别=男性)
//正态分布 x:随机变量的值 u:样本平均值 p:标准差 y:概率
double gaussianDistribution(double x,double u,double p)
{
double y;
p=pow(p,2);
y = (1 / (2*PI*p)) * exp( -pow((x-u),2) / (2*p) );
return y;
}得到上述四个概率之后,就可以进行朴素贝叶斯分类了。
朴素贝叶斯
朴素贝叶斯有多朴素呢,基本上就是比较P1和P2 的大小,哪个概率大,结果就是哪个。
P1 = P(身高=160|性别=女性) * P(体重=50|性别=女性)
P2 = P(身高=160|性别=男性) * P(体重=50|性别=男性)
代码流程
- 获取数据(数据清洗)
- 读取数据
- 计算平均值(u)、标准差(p)
- 通过高斯分布的概率密度函数求出P(特征=xxx|性别=xx)的概率
- 求出P1、P2
- 通过P1、P2的大小判断性别
获取数据(数据清洗)
数据集可以在https://www.kaggle.com/找到,搜索关键词height等即可……

本次代码的数据集(韩国大学生的体测数据)如下:
第0列:性别(0表示未知、1代表男性、2代表女性)
第1列:身高(单位:cm)
第2列:体重(单位:kg)
P.S. 不分享该数据集

代码实现
头文件 allHead.h
//allHead.h
#ifndef _STDIO_H_
#define _STDIO_H_
#include
#include
#include
#include
#define PI 3.1415926535898
//单条数据的长度
#define MAX_LINE 100
//数据集的长度
#define DATA_LEN 15300
//特征值的个数
#define EIGEN_NUM 3
/*声明函数*/
//获取数据集
void getData(const char *fileLocation);
//获得平均值和标准差:给 Parameter 赋值
void getParameter();
//计算平均值和标准差
double* calParameter(int column,int sex);
//计算概率p(特征列column = x | 性别)
double getProbability(double x,int column,int sex);
//正态分布 x:随机变量的值 u:样本平均值 p:标准差
double gaussianDistribution(double x,double u,double p);
//返回性别字符结果
char* sexResult(float height,float weight);
//返回性别ID结果
int sexIDResult(float height,float weight);
//准确度判断
float precision();
#endif 源文件 handleData.cpp
//handleData.cpp
#include"allHead.h"
/*
basicData.csv:性别、身高、体重 [i][0,1,2]
addVitalCapacityData.csv:性别、身高、体重、肺活量 [i][0,1,2,3]
*/
//性别:0表示未知,1表示男,2表示女
float dataSet[DATA_LEN][EIGEN_NUM]; //数据集
double maleNum=0;//男性总数
double femaleNum=0;//女性总数
double meanValue[2][3]; //男性、女性的所有均值[0][0,1,2]=[男][身高、体重、肺活量]
double standardDeviation[2][3]; //男性、女性的所有标准差[0][0,1,2]=[男][身高、体重、肺活量]
int dataLen; //从1开始计算的数据集的长度,数学计算用的长度
char *basicInfo[] = {"性别","身高","体重","肺活量"};
//char *addVitalCapacityInfo[] = {"性别","身高","体重","肺活量"};
//读取数据
void getData(const char *fileLocation)
{
char buf[MAX_LINE]; //缓冲区
FILE *fp; //文件指针s
int len; //行字符个数
//printf("正在读取文件\n");
//读取文件
if((fp = fopen(fileLocation,"r")) == NULL)
{
perror("fail to read");
exit (1) ;
}
//逐行读取及写入数组
char *token;
const char s[2] = ",";
int i=0;
int j=0;
while(fgets(buf,MAX_LINE,fp) != NULL && i< DATA_LEN-1)
{
len = strlen(buf);
buf[len-1] = '\0'; //删去换行符
//分割字符串
token = strtok(buf, s);
//继续分割字符串
j = 0;
while( token != NULL ) {
dataSet[i][j]=atof(token);
//printf("dataSet[%d][%d] = %f\n", i,j, dataSet[i][j] );
//printf( "%f\n", dataRuslt[i][j]);
token = strtok(NULL, s);
j = j+1;
}
i = i + 1;
}
dataLen=i;
//printf("%d条数据读取完毕\n",dataLen);
//计算男女个数
for(i=0;i femaleP){return "男性";}
if(maleP < femaleP){return "女性";}
if(maleP == femaleP){return "未知";}
}
//返回性别ID结果
int sexIDResult(float height,float weight)
{
double maleP;//男性概率
double femaleP;//女性概率
double a=0.5; //男女比例各50%
maleP = a * getProbability(height,1,1) * getProbability(weight,2,1);
//printf("\n");
femaleP = a * getProbability(height,1,2) * getProbability(weight,2,2);
//printf("\n");
if(maleP > femaleP){return 1;}
if(maleP < femaleP){return 2;}
if(maleP == femaleP){return 0;}
}
//准确度判断
float precision()
{
int i;
float preSexID;
float right=0;
float error=0;
for(i=0;i 源文件(主函数) naiveBayes.cpp
//naiveBayes.cpp
#include"allHead.h"
extern float dataSet[DATA_LEN][EIGEN_NUM];
extern int dataLen;
/*
性别:0表示未知,1表示男,2表示女
basicData.csv:性别、身高、体重 [i][0,1,2]
*/
void main(){
//给全局变量dataSet赋值
getData("basicData.csv");
/*
//抽查数据集
int i = dataLen-1;
int j = 2;
printf("dataSet[%d][%d] = %f\n", i,j, dataSet[i][j] );
*/
//打印准确率
printf("Accuracy:%f\n",precision());
//抽查准确率
float Height=178;
float Weight=60;
printf("身高:%.2f,体重:%.2f\n根据高斯-朴素贝叶斯算法判断\n此人的性别可能为:%s\n\n",Height,Weight,sexResult(Height,Weight));
}