深度图转点云原理
深度图转点云的计算过程很简洁,而里面的原理是根据内外参矩阵变换公式得到,下面来介绍其推导的过程。
1. 原理
首先,要了解下世界坐标到图像的映射过程,考虑世界坐标点M(Xw,Yw,Zw)映射到图像点m(u,v)的过程,如下图所示:
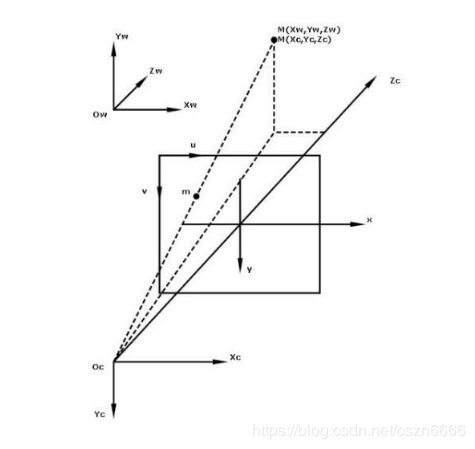
详细原理请参考教程"相机标定(2)---摄像机标定原理",这里不做赘述。形式化表示如下:
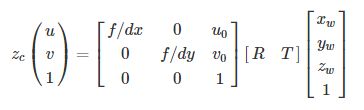
其中u,vu,v为图像坐标系下的任意坐标点。u₀,v₀分别为图像的中心坐标。Xw,Yw,Zw表示世界坐标系下的三维坐标点。Zc表示相机坐标的z轴值,即目标到相机的距离。R,T分别为外参矩阵的3x3旋转矩阵和3x1平移矩阵。
对外参矩阵的设置:由于世界坐标原点和相机原点是重合的,即没有旋转和平移,所以:

注意到,相机坐标系和世界坐标系的坐标原点重合,因此相机坐标和世界坐标下的同一个物体具有相同的深度,即zc=zwzc=zw.于是公式可进一步简化为:
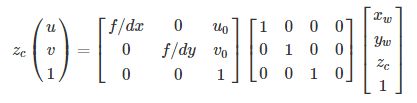
从以上的变换矩阵公式,可以计算得到图像点[u,v]T 到世界坐标点[Xw,Yw,Zw]T的变换公式:
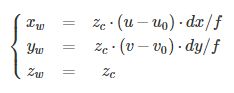
2. 代码
根据上述公式,再结合以下ROS给出的代码,就能理解其原理了。代码如下:
#ifndef DEPTH_IMAGE_PROC_DEPTH_CONVERSIONS
#define DEPTH_IMAGE_PROC_DEPTH_CONVERSIONS
#include
#include
#include
#include "depth_traits.h"
#include
namespace depth_proc {
typedef sensor_msgs::PointCloud2 PointCloud;
// Handles float or uint16 depths
template
void convert(
const sensor_msgs::ImageConstPtr& depth_msg,
PointCloud::Ptr& cloud_msg,
const image_geometry::PinholeCameraModel& model,
double range_max = 0.0)
{
// Use correct principal point from calibration
float center_x = model.cx();//内参矩阵中的图像中心的横坐标u0
float center_y = model.cy();//内参矩阵中的图像中心的纵坐标v0
// Combine unit conversion (if necessary) with scaling by focal length for computing (X,Y)
double unit_scaling = DepthTraits::toMeters( T(1) );//如果深度数据是毫米单位的,结果将会为0.001;如果深度数据是米单位的,结果将会为1;
float constant_x = unit_scaling / model.fx();//内参矩阵中的 f/dx
float constant_y = unit_scaling / model.fy();//内参矩阵中的 f/dy
float bad_point = std::numeric_limits::quiet_NaN();
sensor_msgs::PointCloud2Iterator iter_x(*cloud_msg, "x");
sensor_msgs::PointCloud2Iterator iter_y(*cloud_msg, "y");
sensor_msgs::PointCloud2Iterator iter_z(*cloud_msg, "z");
const T* depth_row = reinterpret_cast(&depth_msg->data[0]);
int row_step = depth_msg->step / sizeof(T);
for (int v = 0; v < (int)cloud_msg->height; ++v, depth_row += row_step)
{
for (int u = 0; u < (int)cloud_msg->width; ++u, ++iter_x, ++iter_y, ++iter_z)
{
T depth = depth_row[u];
// Missing points denoted by NaNs
if (!DepthTraits::valid(depth))
{
if (range_max != 0.0)
{
depth = DepthTraits::fromMeters(range_max);
}
else
{
*iter_x = *iter_y = *iter_z = bad_point;
continue;
}
}
// Fill in XYZ
*iter_x = (u - center_x) * depth * constant_x;//这句话计算的原理是什么,通过内外参数矩阵可以计算
*iter_y = (v - center_y) * depth * constant_y;//这句话计算的原理是什么,通过内外参数矩阵可以计算
*iter_z = DepthTraits::toMeters(depth);
}
}
}
} // namespace depth_image_proc
#endif
深圳辰视智能科技有限公司
深圳辰视智能科技有限公司是一家提供机器视觉、工业智能化设备的国家高新技术企业,是由中国科学院机器视觉技术研究团队创立,公司拥有快速三维建模、机器人运动控制、工件目标的分类与6D识别等方面的核心技术。
公司的主要产品有:机器人三维视觉引导系统、深度学习分类与检测系统、二维/三维视觉定位系统等,产品解决了机器人没有视觉感知与目标识别功能这个影响机器人便捷应用的关键问题;使机器人拥有“双眼”和“大脑”。
目前,公司产品已广泛应用到自动上下料、组装、分类分拣、铸造、喷涂与焊接引导等多种不同工业场景,极大地提高生产效果、节约人力成本。
深圳辰视智能科技有限公司将专注于工业视觉应用领域,致力于技术的不断研究、创新、突破,为合作伙伴提供全球领先的机器视觉产品及技术。
更多资讯,关注我们!
联系热线:0755-26920296
抖音号:CosmosVision
微博:辰视智能
微信搜索:辰视智能

