李宏毅《Deep Learning》学习笔记 - transformer
学习资料
视频:https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=61&t=1s
课件:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2019/Lecture/Transformer%20(v5).pdf
Transformer
Transformer是Seq2Seq with Self-Attention
BERT是unsupervised learning版本的Transformer
Seq2Seq Model的问题
Seq2Seq Model最大的问题就是慢,没法并行化。下图左侧是Seq2Seq的工作原理,右侧是使用CNN来做处理的过程。使用CNN最大的好处就是可以并行化处理。
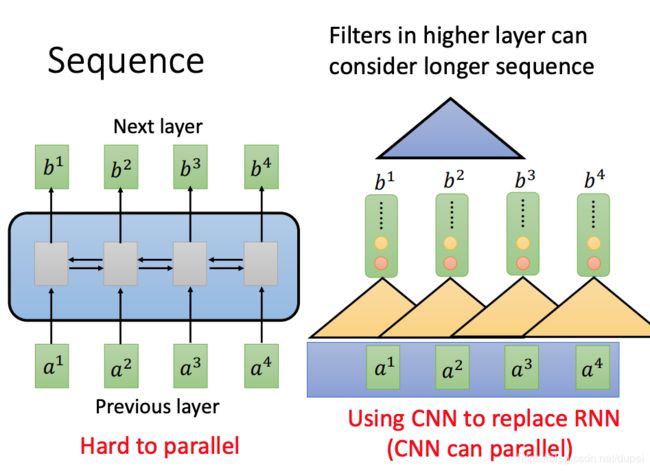
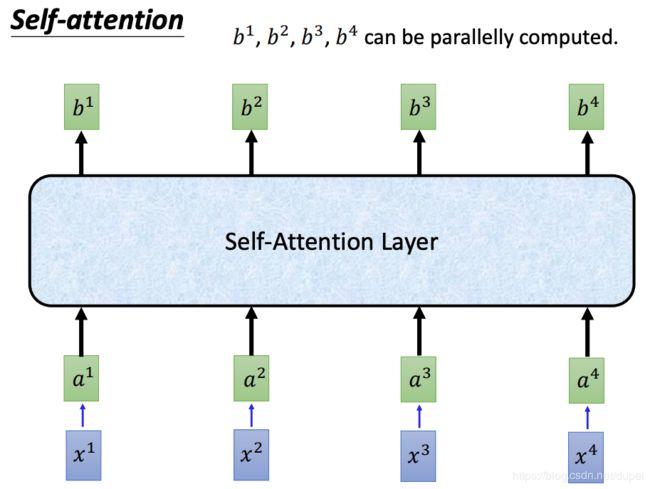
相较于Seq2Seq Layer而言,可以直接使用Self-Attention Layer替代原先的RNN层,同时,可以引入并行化的作用。输入和输出保持不变。
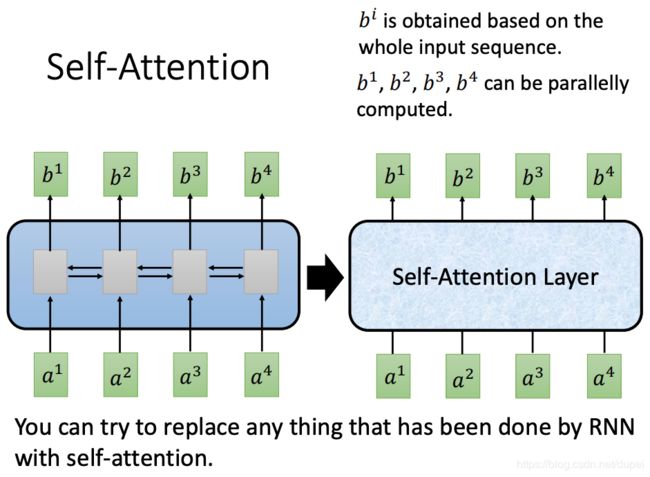
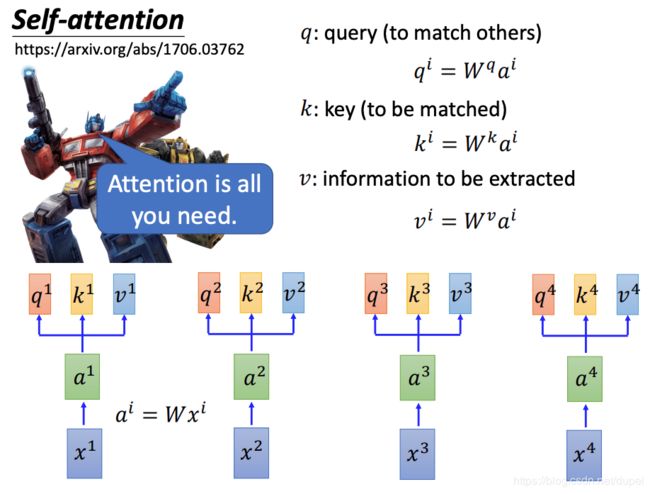
Self-Attention
对每一个Input都做变换,生成q,k,v三种向量。然后,用q与每一个k做attention(所谓的attention,就是计算两个vector的相关性,或者相似度)。
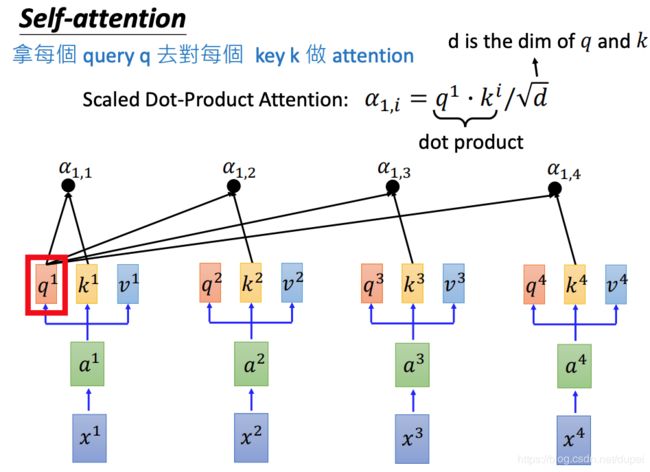
attention有多种计算方法,下面使用的是scaled dot-product attention。
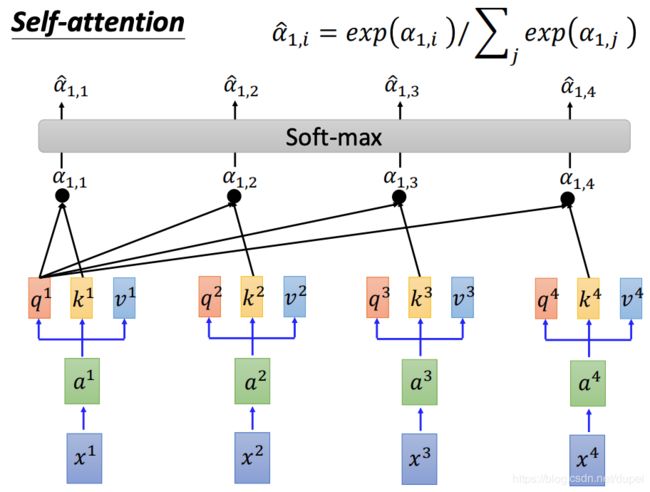
接着,将所有的attention value都做soft-max
将经过soft-max的值,与每一个v相乘,求和,求得 b 1 b^1 b1
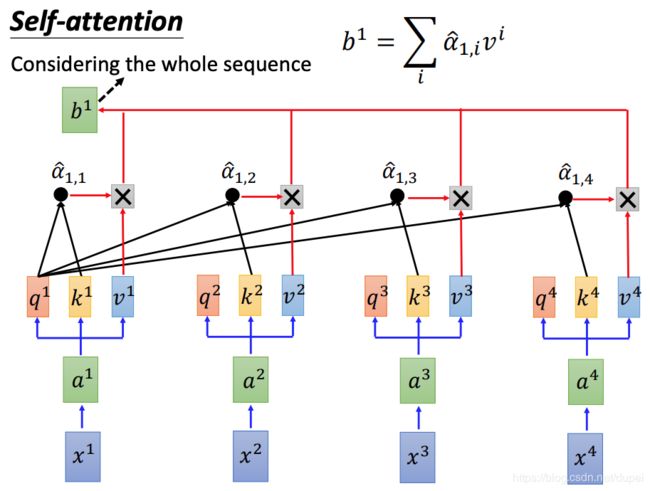
对于 b 2 b^2 b2的计算方法,也是类似
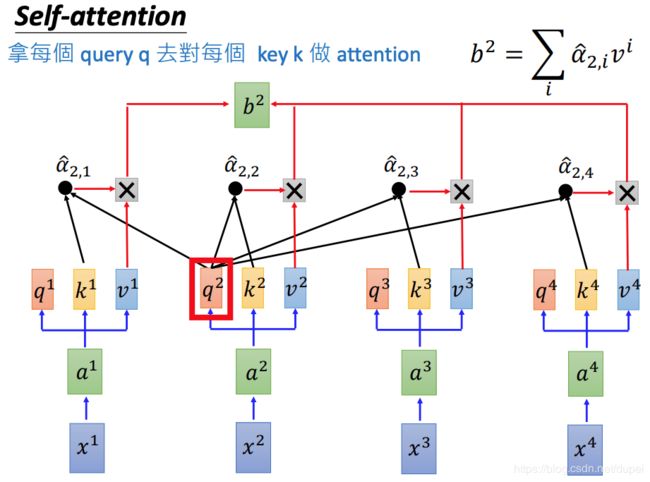
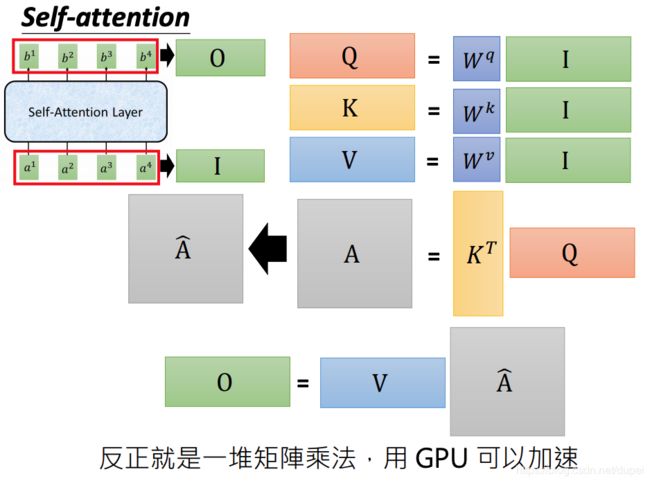
下面来看看如何使用矩阵计算来做并行计算。
将输入的 x 1 , x 2 , x 3 , x 4 x^1,x^2,x^3,x^4 x1,x2,x3,x4做变换以后,变成 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4。将 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4作为矩阵的每一列,组成一个 I I I,再分别乘以 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv,得到想相应的 Q , K , V Q,K,V Q,K,V。每一列就是前面介绍的 q i , k i , v i q^i,k^i,v^i qi,ki,vi
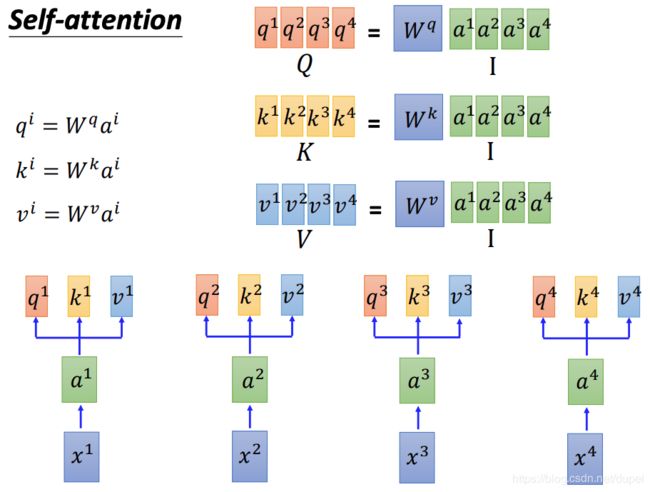
再看一下计算 α ^ \hat{\alpha} α^和 b b b的过程。
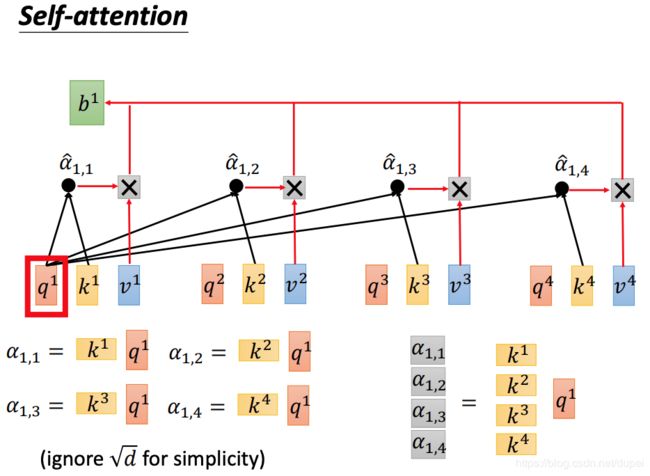
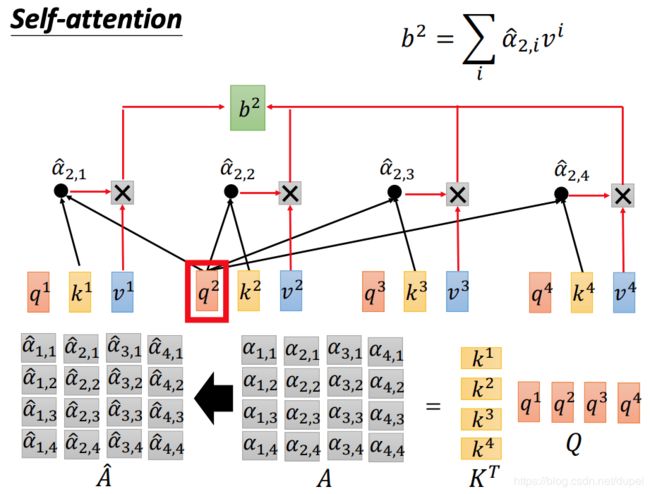
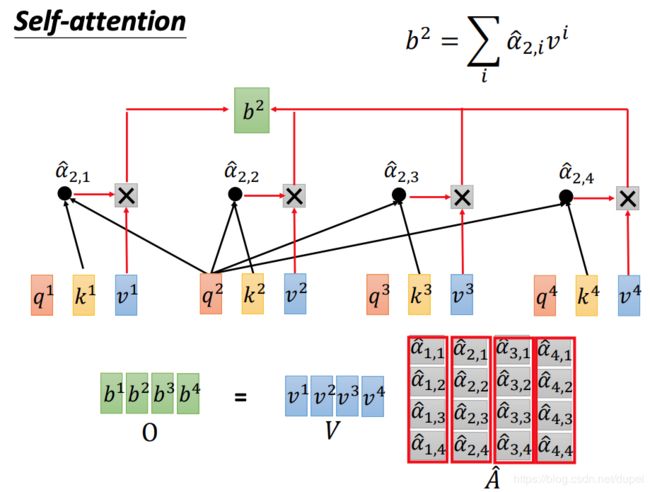
最后,我们再回顾一下,整个self-attention的计算过程。
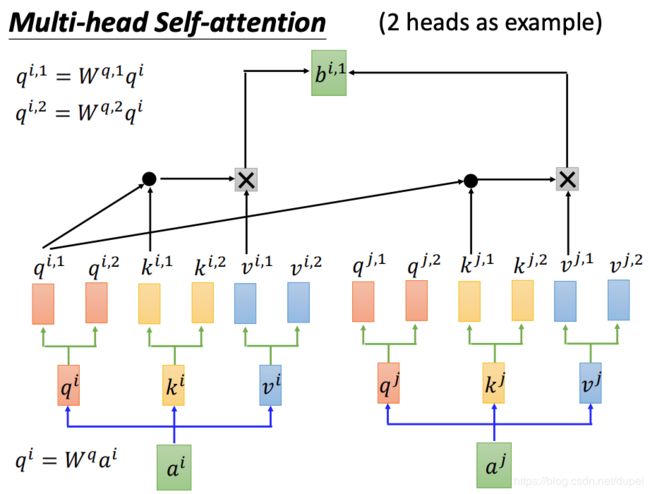
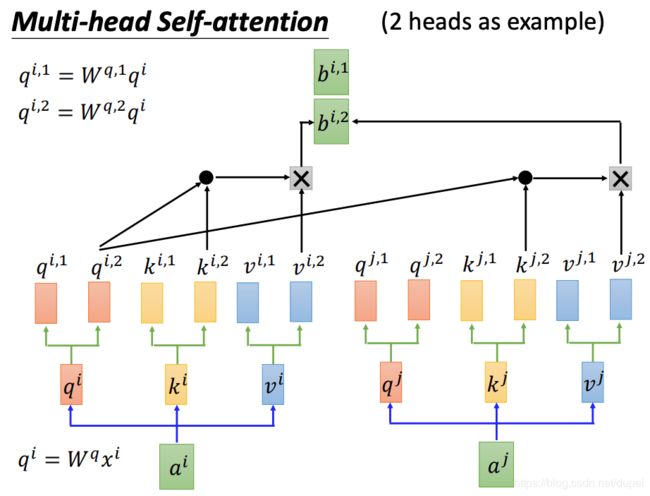
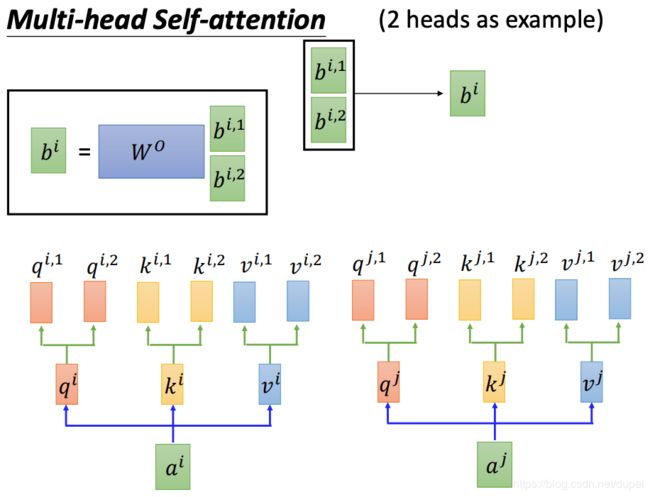
Multi-head Self-Attention
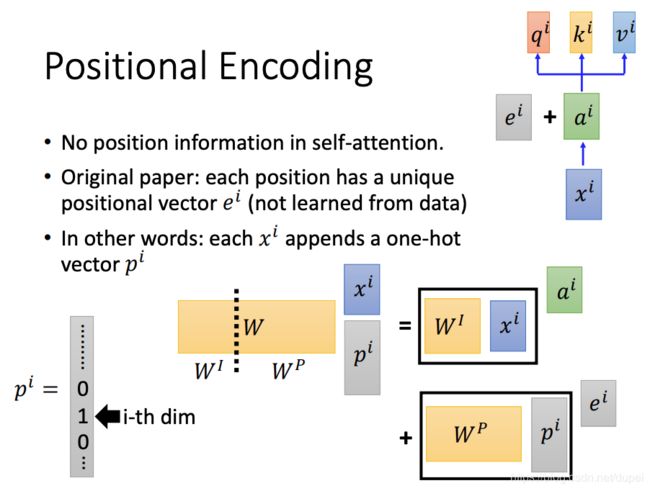
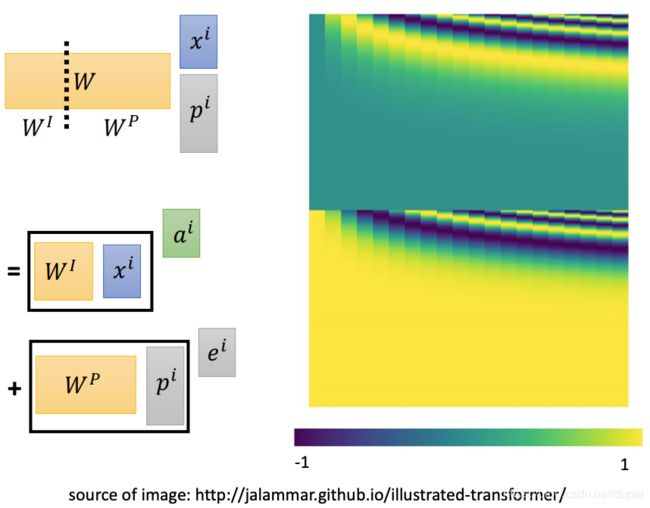
Positional Encoding
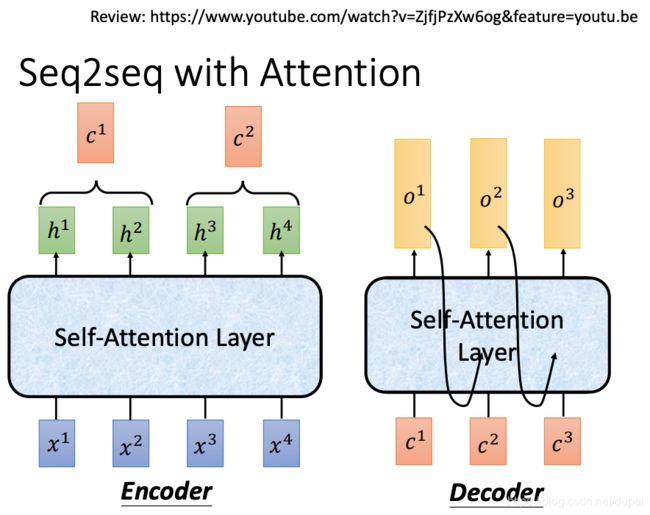
Seq2Seq with Attention
将原先的RNN层,用self-attention layer代替,就好了。
架构分析
下面是Transformer的完整架构,包括Encoder和Decoder。
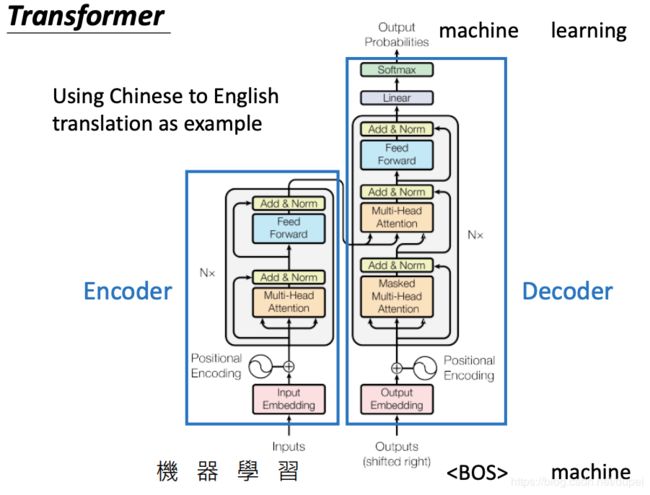
下面是对架构中每个组成部分的详细介绍。
其中,Multi-Head Attention就是上面介绍的self-attention layer。
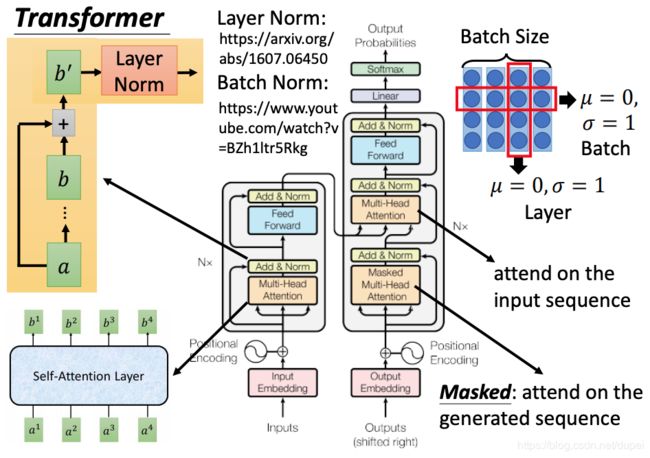
Add & Norn是下图左上黄色区域的解释。Add是将输入a与输出b相加。Norm是指Layer Norm。
这里将Layer Norm与Batch Norm进行对比,其中,Layer Norm是将一个样本中每个维度的值进行normaliztion,而Batch Norm是将一个batch中同一个dim的值做normalization。
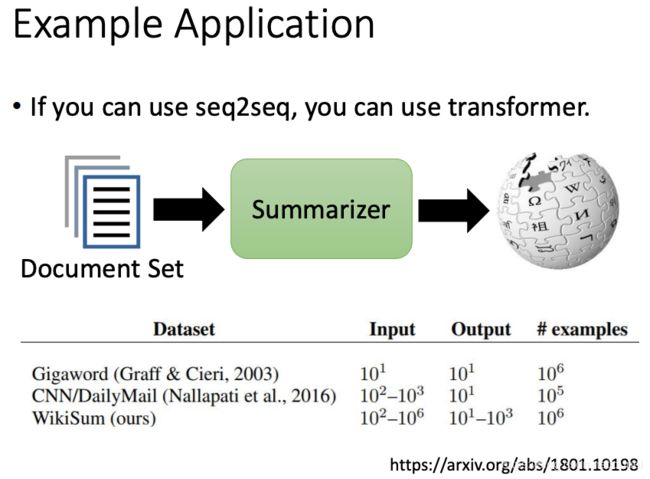
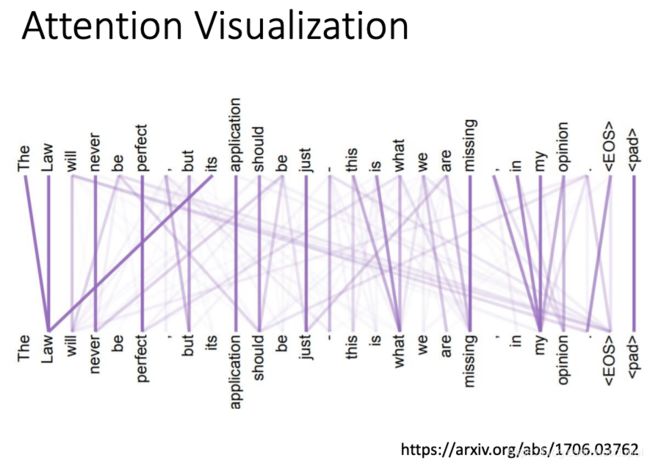
论文实验

其他应用