SVM算法(二)线性可分的SVM求解
回忆前文提到的感知机模型:对于线性可分的二分类问题,通过不断迭代错误分类样本点,直至最终的分割面。
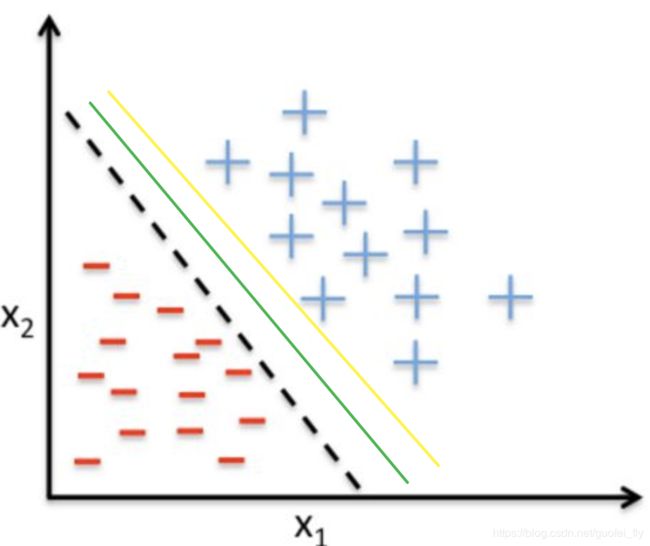
感知机是错误样本驱动的分类器,显然对于线性可分的数据,这样的分类器有无数个(见下图),那究竟哪一个更好呢?
直觉上,在下图给出的三个分割面上,绿色的分割面更佳。因为其离正、负样本更远,这意味着模型更能够忍受数据误差(测量或采样等导致),即模型更健壮。而这就是线性可分的SVM推导的切入点。
一、线性可分最优化问题的引出
设平面方程为 w x + b = 0 wx+b=0 wx+b=0,任意点 x i x_i xi到平面的距离可写成 1 ∣ ∣ w ∣ ∣ ∣ w x i + b ∣ \frac{1}{||w||}|wx_i+b| ∣∣w∣∣1∣wxi+b∣。显然若数据可分,则对于合适的分割面,有 y i ( w x i + b ) > 0 y_i(wx_i+b)>0 yi(wxi+b)>0。注意到 y i = { + 1 , − 1 } y_i=\{+1,-1\} yi={+1,−1},目标问题可表示为:
max γ γ = min i 1 ∣ ∣ w ∣ ∣ y i ( w x i + b ) \begin{aligned}&\max\space\gamma\\&\gamma=\min_i\frac{1}{||w||}y_i(wx_i+b)\end{aligned} max γγ=imin∣∣w∣∣1yi(wxi+b)
值的注意的是:对于任意一组 w w w、 b b b值,任意缩放若干倍,并不影响分隔面本身,也不影响目标问题的解。那我们不妨选择合适的一组 w w w、 b b b,使得 min i y i ( w x i + b ) = 1 \min\limits_iy_i(wx_i+b)=1 iminyi(wxi+b)=1。此时 γ = 1 ∣ ∣ w ∣ ∣ \gamma=\frac{1}{||w||} γ=∣∣w∣∣1,对应的目标问题可改写为:
max 1 ∣ ∣ w ∣ ∣ min i y i ( w x i + b ) = 1 \begin{aligned}&\max\frac{1}{||w||}\\&\min\limits_iy_i(wx_i+b)=1\end{aligned} max∣∣w∣∣1iminyi(wxi+b)=1将上式中的最小化条件改为不等式约束,可进一步得到优化目标为:
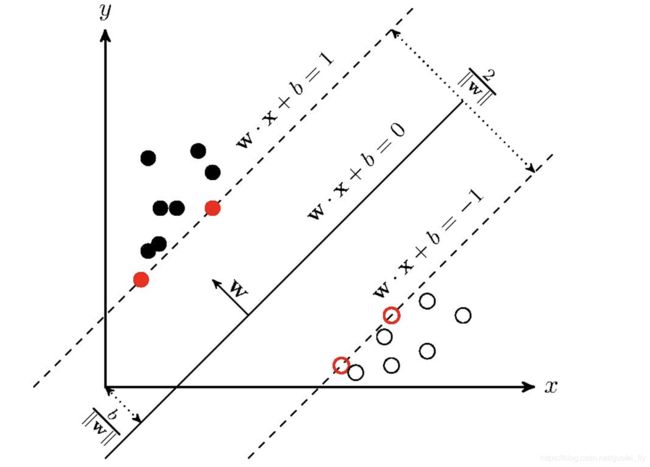
max 1 ∣ ∣ w ∣ ∣ s . t . y i ( w x i + b ) ≥ 1 \begin{aligned}&\max\frac{1}{||w||}\\&s.t.\space \space y_i(wx_i+b)\ge1\end{aligned} max∣∣w∣∣1s.t. yi(wxi+b)≥1需要强调的是,对于不等式约束条件,必然存在若干点 ( x j , y j ) (x_j,y_j) (xj,yj)使得等号成立,即 y j ( w x j + b ) = 1 y_j(wx_j+b)=1 yj(wxj+b)=1,否则可通过缩小 w , b w,b w,b使得等号成立,从而获得更大的 max 1 ∣ ∣ w ∣ ∣ \max\frac{1}{||w||} max∣∣w∣∣1。从几何意义上,这些点就是与分割面距离恰为 1 ∣ ∣ w ∗ ∣ ∣ \frac{1}{||w^*||} ∣∣w∗∣∣1的点,也称支持向量点,而 1 ∣ ∣ w ∗ ∣ ∣ \frac{1}{||w^*||} ∣∣w∗∣∣1称为间隔(margin),或几何间距。 2 ∣ ∣ w ∗ ∣ ∣ \frac{2}{||w^*||} ∣∣w∗∣∣2为分割面两侧支持点的距离,也是正负分类的最近距离(见下图)。
根据最优化理论,我们更习惯于求解最小化问题。因此,此最优化问题可写成: min 1 2 w 2 s . t . y i ( w x i + b ) ≥ 1 \begin{aligned}&\min\frac{1}{2}w^2\\&s.t.\space \space y_i(wx_i+b)\ge1\end{aligned} min21w2s.t. yi(wxi+b)≥1
注意到目标函数 min 1 2 w 2 \min\frac{1}{2}w^2 min21w2为凸函数,而约束条件 y i ( w x i + b ) ≥ 1 y_i(wx_i+b)\ge1 yi(wxi+b)≥1为仿射函数。根据二次规划理论,其可求解!
上文在推导过程, x i x_i xi为原始的输入特征,在实际操作中上可以通过 x i x_i xi的各种函数(非线性变换)得到海量的高维特征(甚至无穷维)。随着特征维度的扩张,使得计算量迅速扩大。
那是否有方法解决这种矛盾呢?下面来就来介绍解决这个问题的对偶算法。
二、SVM的对偶问题
根据优化目标和约束条件,定义广义拉格朗日函数: L ( w , b , α ) = 1 2 w 2 + ∑ i α i ( 1 − y i ( w x i + b ) ) , α ≥ 0 L(w,b,\alpha)=\frac{1}{2}w^2+\sum\limits_i\alpha_i(1-y_i(wx_i+b)),\alpha\ge0 L(w,b,α)=21w2+i∑αi(1−yi(wxi+b)),α≥0对于原始最大最小问题: min w , b max α L ( w , b , α ) \min_{w,b}\max_{\alpha}L(w,b,\alpha) w,bminαmaxL(w,b,α)如果存在不满足约束条件的 x i , y i x_i,y_i xi,yi,即 y i ( w x i + b ) ≤ 1 y_i(wx_i+b)\le1 yi(wxi+b)≤1,则可令 α i → + ∞ \alpha_i\rightarrow+\infin αi→+∞,使得 max α L ( w , b , α ) → + ∞ \max\limits_{\alpha}L(w,b,\alpha)\rightarrow+\infin αmaxL(w,b,α)→+∞
而对于满足约束的 x i , y i x_i,y_i xi,yi,考虑到 y i ( w x i + b ) ≥ 1 y_i(wx_i+b)\ge1 yi(wxi+b)≥1且 α i ≥ 0 \alpha_i\ge0 αi≥0,因此 max α L ( w , b , α ) = 1 2 w 2 \max\limits_{\alpha}L(w,b,\alpha)=\frac{1}{2}w^2 αmaxL(w,b,α)=21w2。所以原来的带约束的不等式问题,变成了如下的不带约束的拉格朗日最大最小值问题: min w , b max α 1 2 w 2 + ∑ i α i ( 1 − y i ( w x i + b ) ) , α ≥ 0 \min_{w,b}\max_{\alpha}\frac{1}{2}w^2+\sum\limits_i\alpha_i(1-y_i(wx_i+b)),\alpha\ge0 w,bminαmax21w2+i∑αi(1−yi(wxi+b)),α≥0对应的对偶问题,即拉格朗日最小最大值问题可写成:
max α min w , b 1 2 w 2 + ∑ i α i ( 1 − y i ( w x i + b ) ) , α ≥ 0 \max_{\alpha}\min_{w,b}\frac{1}{2}w^2+\sum\limits_i\alpha_i(1-y_i(wx_i+b)),\alpha\ge0 αmaxw,bmin21w2+i∑αi(1−yi(wxi+b)),α≥0
对于内部的最小化目标函数 min w , b L ( w , b ) \min_{w,b}L(w,b) minw,bL(w,b),将 α \alpha α作为定值,仅存在 w , b w,b w,b两个原始变量,可直接根据梯度为0求解最小值对应的点: ∇ w L ( w , b ) = w − ∑ i α i y i x i = 0 ∇ b = − ∑ i α i y i = 0 \begin{aligned}&\nabla_wL(w,b)=w-\sum\limits_i\alpha_iy_ix_i=0\\ &\nabla_b=-\sum\limits_i\alpha_iy_i=0\end{aligned} ∇wL(w,b)=w−i∑αiyixi=0∇b=−i∑αiyi=0将据此得到的 w , b w,b w,b代入上面的拉格朗日最小最大值函数,可将对偶问题简化为: max α 1 2 w 2 + ∑ i α i ( 1 − y i ( w x i + b ) ) = max α ( 1 2 w 2 + ∑ i α i − w ∑ i α i y i x i − b ∑ i α i y i ) = max α − 1 2 ( ∑ i α i y i x i ) 2 + ∑ i α i = max α − 1 2 ∑ i ∑ j α i α j y i y j ( x i x j ) + ∑ i α i \begin{aligned}&\max_{\alpha}\frac{1}{2}w^2+\sum\limits_i\alpha_i(1-y_i(wx_i+b))\\&=\max_{\alpha}(\frac{1}{2}w^2+\sum\limits_i\alpha_i-w\sum\limits_i\alpha_iy_ix_i-b\sum\limits_i\alpha_iy_i)\\&=\max_{\alpha}-\frac{1}{2}(\sum\limits_i{\alpha_iy_ix_i})^2+\sum\limits_i\alpha_i\\&=\max_{\alpha}-\frac{1}{2}\sum\limits_i\sum\limits_j\alpha_i\alpha_jy_iy_j(x_ix_j)+\sum\limits_i\alpha_i\end{aligned} αmax21w2+i∑αi(1−yi(wxi+b))=αmax(21w2+i∑αi−wi∑αiyixi−bi∑αiyi)=αmax−21(i∑αiyixi)2+i∑αi=αmax−21i∑j∑αiαjyiyj(xixj)+i∑αi这是典型的满足 α ≥ 0 \alpha\ge0 α≥0条件下的二次规划问题,有成熟的求解方案。通过对偶问题的转换,有如下好处:
(1) 无须直接求解可能无穷维的特征空间参数 w w w,而只需求解数据样本量维度的广义拉格朗日算子空间 α \alpha α。
(2) 原来的特征空间通过内积 x i x j x_ix_j xixj形式隐式表达,便于以后核技巧的引入。
三、线性可分最优化问题的最优解
根据SVM算法(一)预备知识中的推导,对偶问题的解不大于原始问题的解。而若满足强对偶,则两个最优问题同解,则可以直接通过求解对偶问题得到最优解。
在SVM问题中,必然存在最佳分割面意外的点,即满足Scaler条件(存在点 x i x_i xi,使得 y i ( w x i + b ) > 1 y_i(wx_i+b)>1 yi(wxi+b)>1),因此可通过KKT条件求得最优解:
∇ w L ( w ∗ , b ∗ , α ∗ ) = w ∗ − ∑ i α i ∗ y i x i = 0 ∇ b L ( w ∗ , b ∗ , α ∗ ) = − ∑ i α i ∗ y i = 0 α i ∗ ( 1 − y i ( w ∗ x i + b ∗ ) ) = 0 α i ∗ ≥ 0 1 − y i ( w ∗ x i + b ) ≤ 0 \begin{aligned}&\nabla_wL(w^*,b^*,\alpha^*)=w^*-\sum\limits_i\alpha_i^*y_ix_i=0\\ &\nabla_bL(w^*,b^*,\alpha^*)=-\sum\limits_i\alpha_i^*y_i=0\\& \alpha_i^*(1-y_i(w^*x_i+b^*))=0 \\ & \alpha_i^*\ge0 \\&1-y_i(w^*x_i+b)\le0 \end{aligned} ∇wL(w∗,b∗,α∗)=w∗−i∑αi∗yixi=0∇bL(w∗,b∗,α∗)=−i∑αi∗yi=0αi∗(1−yi(w∗xi+b∗))=0αi∗≥01−yi(w∗xi+b)≤0
注意若 α \alpha α均为0,则 w ∗ = 0 w^*=0 w∗=0,而这并非原问题的解。因此必存在某个 α j ≠ 0 \alpha_j\neq0 αj=0,此时的 1 − y j ( w ∗ x j + b ) = 0 1-y_j(w^*x_j+b)=0 1−yj(w∗xj+b)=0,而 y j ∈ { − 1 , 1 } y_j\in\{-1,1\} yj∈{−1,1},可得 b ∗ = y j − w ∗ x j b^*=y_j-w^*x_j b∗=yj−w∗xj。由此,可得到基于KKT条件的对偶问题完整的最优解: w ∗ = ∑ i α i ∗ x i y i b ∗ = y j − w ∗ x j , i f α j ∗ > 0 \begin{aligned}&w^*=\sum\limits_i\alpha_i^*x_iy_i\\&b^*=y_j-w^*x_j\space ,if\space\space\alpha_j^*>0\end{aligned} w∗=i∑αi∗xiyib∗=yj−w∗xj ,if αj∗>0而 α ∗ \alpha^* α∗可通过求解 max α − 1 2 ∑ i ∑ j α i α j y i y j ( x i x j ) + ∑ i α i \max\limits_\alpha-\frac{1}{2}\sum\limits_i\sum\limits_j\alpha_i\alpha_jy_iy_j(x_ix_j)+\sum\limits_i\alpha_i αmax−21i∑j∑αiαjyiyj(xixj)+i∑αi的二次规划问题求解得到。
而判断样本点 x k x_k xk的分类可根据 s i g n ( w ∗ x k + b ∗ ) sign(w^*x_k+b^*) sign(w∗xk+b∗)判断。
这里完整总结下基于广义拉格朗日对偶问题求解SVM问题的基本思路和流程:
(1)求解 max α − 1 2 ∑ i ∑ j α i α j y i y j ( x i x j ) + ∑ i α i \max\limits_\alpha-\frac{1}{2}\sum\limits_i\sum\limits_j\alpha_i\alpha_jy_iy_j(x_ix_j)+\sum\limits_i\alpha_i αmax−21i∑j∑αiαjyiyj(xixj)+i∑αi,得到最优的 α ∗ \alpha^* α∗,其中的样本内积 x i x j x_ix_j xixj可通过Gram矩阵进行存储;
(2)选择 α ∗ \alpha^* α∗中的非零项,记作 α ∗ ′ \alpha^{*'} α∗′
(3)根据 w ∗ = ∑ i α i ∗ x i y i w^*=\sum\limits_i\alpha_i^*x_iy_i w∗=i∑αi∗xiyi得到最优系数 w ∗ w^* w∗
(4)选择任意一个 α j ∈ α ∗ ′ \alpha_j\in\alpha^{*'} αj∈α∗′,根据 b ∗ = y j − w ∗ x j b^*=y_j-w^*x_j b∗=yj−w∗xj得到最优的偏置项 b ∗ b^* b∗
不难发现, w ∗ , b ∗ w^*,b^* w∗,b∗的取值仅与 α i > 0 \alpha_i>0 αi>0处的若干样本点有关,即这些点处 1 − y i ( w ∗ x i + b ∗ ) = 0 1-y_i(w^*x_i+b^*)=0 1−yi(w∗xi+b∗)=0,从几何意义上来说,这些点位于分隔面上,所以称为支持向量(support vector)。
四、线性可分SVM问题和感知机问题的关系
对比线性SVM问题的对偶求解和感知机问题的对偶求解,不难发现两者在表达方式上很雷同:
(1)均是基于样本驱动的算法,即可以通过样本点乘积 x i y i x_iy_i xiyi的线性组合得到目标的 w w w
(2)区别在于SVM中的 α \alpha α是通过求解二次规划得到,而MLP中的 α \alpha α是该点错误的次数。
(3)对偶问题均为原始问题的等效转化。前者
五、依旧留存的问题
上文已经较好的给出了线性可分SVM问题的解法,但仍存在存在如下不足:
(1)在计算 α ∗ \alpha^* α∗的过程中应用到样本特征内积 x i x j x_ix_j xixj,在特征空间维度较小情况下还能够计算,但若特征维度很大,则数据的计算和保存的空间性和时间性都将难以满足。
(2)整个推导的大前提是:数据线性可分。若该条件并不满足,如数据线性不可分割,或数据非线性呢?
后面的文章中将分别通过软间隔、特征非线性变换以及核技巧等方法,来解决这些问题,从而使得SVM算法更加普适。