Spark Streaming Demo练习
环境准备
- 版本
scala版本:2.11.8
spark版本:2.1.0 - pom.xml文件 添加依赖jar包
org.apache.spark
spark-streaming_2.11
${spark.version}
Spark Streaming wc练习
socket 统计WC nc -lk 9999 服务 的输入
- 代码
package com.imooc.spark.sparkStreaming
import org.apache.spark._
import org.apache.spark.streaming._ // not necessary since Spark 1.3
object NetworkWordCount {
def main(args: Array[String]): Unit = {
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("192.168.52.130", 9999)
//val lines = ssc.textFileStream("E:///dept.txt")
// Split each line into words
val words = lines.flatMap(_.split(",")) // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
ssc.sparkContext.setLogLevel("ERROR")
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
println(wordCounts)
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
- 演示结果:
[hadoop@hadoop001 conf]$ nc -lk 9999
hello,world
hello,world
hello,world,hello,world,hello,world
-------------------------------------------
Time: 1542353340000 ms
-------------------------------------------
-------------------------------------------
Time: 1542353345000 ms
-------------------------------------------
(hello,1)
(world,1)
-------------------------------------------
Time: 1542353350000 ms
-------------------------------------------
(hello,1)
(world,1)
-------------------------------------------
Time: 1542353355000 ms
-------------------------------------------
-------------------------------------------
Time: 1542353360000 ms
-------------------------------------------
(hello,3)
(world,3)
Basic Source
1. File Stream(本地文件读取)
- 代码
object FileStreams {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\soft\\winutils\\hadoop-common-2.2.0-bin-master")
val conf = new SparkConf().setMaster("local[4]").setAppName("FileStreams")
val ssc = new StreamingContext(conf, Seconds(6))
ssc.sparkContext.setLogLevel("ERROR")
val DStream = ssc.textFileStream("file:///E:/testData/SparkStreaming")
println(DStream)
DStream.print()
ssc.start()
ssc.awaitTermination()
}
- 写入文件
def main(args: Array[String]) {
val writer = new PrintWriter(new File("E://testData/SparkStreaming/33.txt"))
writer.write("哈喽啊,SparkStreamin,spark,java,spark,java")
writer.close()
}
- 结果演示
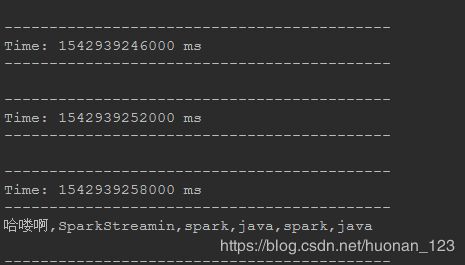
特别注意:
1.Spark Streaming 读取本地文件的时候,要先启动Spark Streaming 去监听要读取的文件夹,然后使用上面提供的写入文件的方法写入一个新文件到监听的文件夹下
2.其实就是Spark Streaming textFileStream方法只能监听到新进来的文件;如果是提前新建的,复制进去或者是继续往文件下写入数据,他也不会监听.只有监听开始后写入监听文件夹下才能读取到
2.DataFrame and SQL 操作
- 代码
package com.imooc.spark.sparkStreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
/**
* sparkStreaming DataFrame
*/
object SqlNetworkWordCount {
def main(args: Array[String]) {
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
//日志输出
ssc.sparkContext.setLogLevel("ERROR")
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("192.168.52.130", 9999)
//val lines = ssc.textFileStream("E:///dept.txt")
// Split each line into words
val words = lines.flatMap(_.split(","))
words.foreachRDD { (rdd: RDD[String], time: Time) =>
// Get the singleton instance of SparkSession
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on table using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
println(s"========= $time =========")
println(wordCountsDataFrame.show())
}
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
/** Case class for converting RDD to DataFrame */
case class Record(word: String)
/** Lazily instantiated singleton instance of SparkSession */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}
- 结果演示
[hadoop@hadoop001 conf]$ nc -lk 9999
hello,world
hello,world
hello,world,hello,world,hello,world
a,b,c,d,
e,a,c,a,
========= 1542353890000 ms =========
+----+-----+
|word|total|
+----+-----+
| d| 1|
| c| 1|
| b| 1|
| a| 1|
+----+-----+
()
========= 1542353895000 ms =========
+----+-----+
|word|total|
+----+-----+
| e| 1|
| c| 1|
| a| 2|
+----+-----+
========= 1542353915000 ms =========
3.读取HDFS
- 代码
参照
- File Stream(本地文件读取)
val DStream = ssc.textFileStream("hdfs://hadoop001:9000/user/hadoop/spark-streaming-test/")
- 结果
