ABAP程序优化笔记
昨天做了一个别人的程序优化,取数逻辑上基本都改了。做这个程序优化真是痛并快乐着,首先拿到一个程序,不完全不知道逻辑,那么首先得看懂它的逻辑,然后想办法去优化。趁着这次机会,写一下ABAP的优化吧。
总的来说,对于S4 HANA 数据库执行要优于应用层的执行,但是我们需要减少数据库和应用层的交互次数。
1.尽量明确自己要取得字段,
1 *优化之前 2 SELECT * FROM LIPS INTO TABLE @ITAB 3 WHERE ··· 4 5 6 *优化之后 7 SELECT VBELN,POSNR,MATNR INTO TABLE @ITAB WHERE ···
2.在select 查询时,特别是需要经过选择界面筛选处理得,尽量使用inner join ( left outer join) 一次性抓取出来。别使用for all entries in。
如:选择屏幕上有
1 SELECT-OPTIONS: 2 S_WADAT FOR LIKP-WADAT OBLIGATORY , " 交货日期 3 S_DN FOR LIKP-VBELN , " 交货订单 4 S_BSART FOR EKKO-BSART , " STO类型 5 S_EBELN FOR EKKO-EBELN , " 调拨单号 6 S_VBELN FOR VBAK-VBELN , "销售订单号 7 S_VKBUR FOR VBAK-VKBUR , "销售据点 8 S_AUART FOR VBAK-AUART."销售订单类型 9 *我们可以直接写sql 10 SELECT A~VBELN,A~VSTEL,A~LFDAT,A~WADAT,A~LFART, 11 A~WADAT_IST,A~VSBED,A~ERNAM,A~ERDAT,A~ERZET, 12 B~WERKS,B~VRKME,B~VGBEL,B~POSNR,B~VGTYP,B~MEINS, 13 B~BRGEW,B~LGMNG,B~MATNR,B~VTWEG,B~SPART,B~MVGR2,B~SHKZG,B~MTART, 14 C~EBELN,C~BSART,C~BSTYP,C~UNSEZ, 15 D~VBELN AS VBELN_SO,D~AUART,D~ZZTRANUM,D~VKBUR,D~ZZCHGROUP 16 FROM LIKP AS A 17 INNER JOIN LIPS AS B ON B~VBELN = A~VBELN 18 LEFT JOIN EKKO AS C ON C~EBELN = B~VGBEL 19 LEFT JOIN VBAK AS D ON D~VBELN = B~VGBEL 20 INTO TABLE @LT_LIPS 21 WHERE WADAT IN @S_WADAT AND A~VBELN IN @S_DN AND B~LGMNG > 0 22 AND C~EBELN IN @S_EBELN AND C~BSART IN @S_BSART 23 AND D~VBELN IN @S_VBELN AND D~VKBUR IN @S_VKBUR AND D~AUART IN @S_AUART.
3.在写for all entries in 的时候注意点
1.写全你要所要取数据的主键,来保证每条数据是唯一的,因为for all entries in 自带select distinct去重功能.(直接把所要取得表得主键都写上呗)
2.先判断下for all entries in itab 这个表是否为空,if itab[] is not initial 一定要有,这个ABAPer应该都知道
3.使用时可以将itab 按照for all entries in的条件排序去重一下,来尽可能缩小itab表,如下:
1 DATA(LT_DATA_MATNR) = GT_DATA[]. 2 SORT LT_DATA_MATNR BY MATNR. 3 DELETE ADJACENT DUPLICATES FROM LT_DATA_MATNR COMPARING MATNR. 4 SELECT A~MATNR A~MTART A~BISMT B~MAKTX INTO TABLE LT_MA 5 FROM MARA AS A 6 LEFT OUTER JOIN MAKT AS B ON A~MATNR = B~MATNR AND B~SPRAS = SY-LANGU 7 FOR ALL ENTRIES IN LT_DATA_MATNR 8 WHERE A~MATNR = LT_DATA_MATNR-MATNR.
4.for all entries in 非常消耗内存,当itab过大的时候不建议使用,若是你一定要用请这么操作:(当itab过大时,会引起资源瓶颈)
1 DATA LV_LINES TYPE I. 2 SORT LT_PARTNER BY TABLE_LINE. 3 DELETE ADJACENT DUPLICATES FROM LT_PARTNER COMPARING ALL FIELDS. 4 DESCRIBE TABLE LT_PARTNER[] LINES DATA(LV_LINES). 5 IF LV_LINES LE 3000. 6 SELECT PARTNER NAME_ORG1 FROM BUT000 INTO TABLE LT_BUT000 7 FOR ALL ENTRIES IN LT_PARTNER 8 WHERE PARTNER = LT_PARTNER-TABLE_LINE. 9 ELSE. 10 CLEAR : LV_TIMES,LT_PARTNER_TMP. 11 LOOP AT LT_PARTNER INTO DATA(LS_PARTNER). 12 LV_TIMES = LV_TIMES + 1. 13 APPEND LS_PARTNER TO LT_PARTNER_TMP. 14 IF LV_TIMES GE 3000. 15 CHECK LT_PARTNER_TMP[] IS NOT INITIAL. 16 SELECT PARTNER NAME_ORG1 FROM BUT000 APPENDING TABLE LT_BUT000 17 FOR ALL ENTRIES IN LT_PARTNER_TMP 18 WHERE PARTNER = LT_PARTNER_TMP-TABLE_LINE. 19 CLEAR:LV_TIMES,LT_PARTNER_TMP. 20 ENDIF. 21 AT LAST. 22 CHECK LT_PARTNER_TMP[] IS NOT INITIAL. 23 SELECT PARTNER NAME_ORG1 FROM BUT000 APPENDING TABLE LT_BUT000 24 FOR ALL ENTRIES IN LT_PARTNER_TMP 25 WHERE PARTNER = LT_PARTNER_TMP-TABLE_LINE. 26 CLEAR:LV_TIMES,LT_PARTNER_TMP. 27 ENDAT. 28 ENDLOOP. 29 ENDIF.
4.内表的使用方面
a) 尽量使用hash表,其次时sort表,然后再是standard表
注:尽量使用sort表吧,实际实施过程中,哈希表用的还是很少的,很多时候我们需要很灵活的对表进行各种字段排序,Sort表的插入数据会比标准表要耗时。
b) 使用 LOOP AT GT_OUT ASSIGNING FIELD-SYMBOL(

使用
c) 常用: read table 时 注意排序,然后使用binary search来提高效率
它的升级版就是提升双层loop的效率,这个在合计值和子表不止一个值和主表对应时比较好用。
1 SORT GT_OUT by vbeln. 2 3 SORT LT_DN BY VBELN. 4 5 LOOP AT GT_OUT ASSIGNING FIELD-SYMBOL(). 6 7 READ TABLE LT_DN TRANSPORTING NO FIELDS WITH KEY VBELN = -VBELN BINARY SEARCH. 8 IF SY-SUBRC EQ 0. 9 LV_TABIX = SY-TABIX. 10 LOOP AT LT_DN INTO LS_DN FROM LV_TABIX. 11 IF LS_DN-VBELN = -VBELN. 12 -MENGE = -MENGE + LS_DN-MENGE. 13 ELSE. 14 EXIT. 15 ENDIF. 16 ENDLOOP. 17 ENDIF. 18 19 ENDLOOP.
d) 对内表进行删除操作时,最好这么操作
1 LOOP AT LT_DATA ASSIGNING FIELD-SYMBOL(). 2 READ TABLE LT_DATA_1 TRANSPORTING NO FIELDS WITH KEY VBELN_DN = -VBELN_DN BINARY SEARCH. 3 IF SY-SUBRC <> 0. 4 -DEL_FLG = 'X'. 5 ENDIF. 6 ENDLOOP. 7 8 DELETE LT_DATA WHERE DEL_FLG = 'X'.
e) 合计值的时候使用collect
这个语句还是挺高效的。
1 SELECT A~VBELN AS VBELN_DN, B~ERDAT,A~POSNR AS POSNR_DN,A~MATNR,A~LFIMG 2 FROM LIPS AS A 3 INNER JOIN LIKP AS B ON B~VBELN = A~VBELN 4 INTO TABLE @LT_DATA. 5 * 6 SORT LT_DATA BY MATNR. 7 LOOP AT LT_DATA ASSIGNING FIELD-SYMBOL(). 8 LS_MATNR-MATNR = -MATNR. 9 LS_MATNR-LFIMG = -LFIMG. 10 COLLECT LS_MATNR INTO LT_MATNR. 11 ENDLOOP.
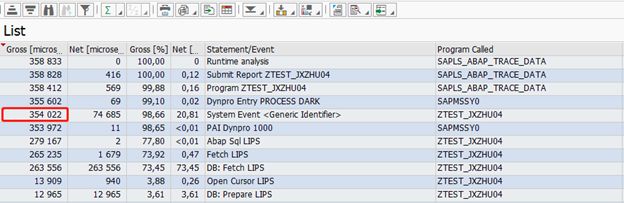
合计6W多条数据:

同时新语法:LOOP AT GROUP 在合计方面也是挺好使用得
1 LOOP AT LT_DATA ASSIGNING FIELD-SYMBOL() GROUP BY ( MATNR = -MATNR 2 SIZE = GROUP SIZE INDEX = GROUP INDEX ) ASCENDING ASSIGNING FIELD-SYMBOL(<GROUP>). 3 LS_MATNR-MATNR = <GROUP>-MATNR . 4 LOOP AT GROUP <GROUP> ASSIGNING FIELD-SYMBOL( ). 5 LS_MATNR-LFIMG = -LFIMG + LS_MATNR-LFIMG. 6 ENDLOOP. 7 APPEND LS_MATNR TO LT_MATNR. 8 CLEAR LS_MATNR. 9 ENDLOOP.
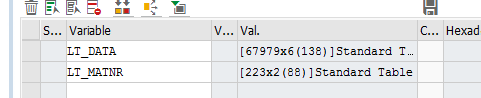
同样得数据,相对比collet还是要逊色一点
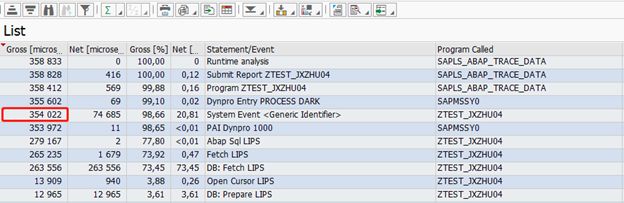
但是下面这个图就让我体会了一把HANA数据库的强大
它的代码是:
1 DATA:BEGIN OF LS_MATNR, 2 MATNR TYPE LIPS-MATNR, 3 LFIMG TYPE LIPS-LFIMG, 4 END OF LS_MATNR. 5 DATA LT_MATNR LIKE TABLE OF LS_MATNR. 6 7 SELECT MATNR, SUM( LFIMG ) INTO TABLE @LT_MATNR 8 FROM LIPS 9 GROUP BY MATNR.“听说网上都是避免使用group by,在HANA上不存在的
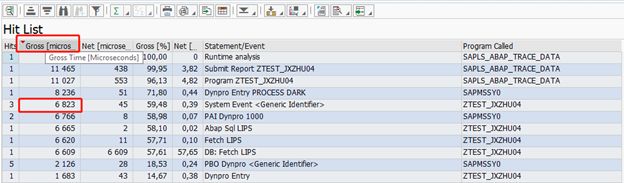
5.使用SE30和 ST05取分析程序各个部分的执行时间
进入SE30:选择OLD SE30,点击左下角得分析,你可以看到程序得ABAP时间和DB时间

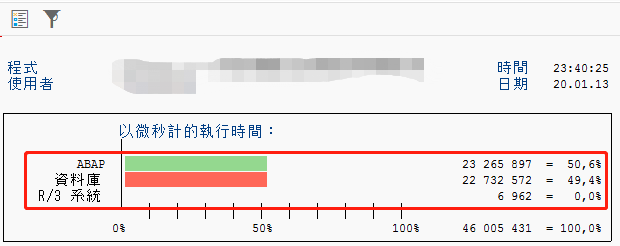
现在一般使用新得SE30,可以看到每个部分执行得时间,进而进行优化