使用python获取csv文本的某行或某列数据
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格:
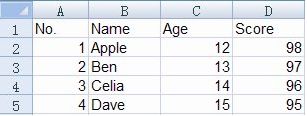
就可以存储为csv文件,文件内容是:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95假设上述csv文件保存为”A.csv”,如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Python自带的csv模块,有两种方法可以实现:
第一种方法使用reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows= [row for row in reader]
print rows得到:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]要提取其中某一列,可以用下面的代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
column = [row[2] for row in reader]
print column得到:
['Age', '12', '13', '14', '15']注意从csv读出的都是str类型。这种方法要事先知道列的序号,比如Age在第2列,而不能根据’Age’这个标题查询。这时可以采用第二种方法:
第二种方法是使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row for row in reader]
print column得到:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]如果我们想用DictReader读取csv的某一列,就可以用列的标题
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row['Age'] for row in reader]
print column:['12', '13', '14', '15']常见问题
1、_csv.Error: iterator should return strings, not bytes (did you open the file in text mode?)
这个在python3中常会遇到的,意思是迭代器应该返回字符串,不是字节,所以在打开csv文件的时候,建议用 ‘r’ 模式,而不是 ‘rb’
2、UnboundLocalError: local variable ‘f’ referenced before assignment(f.close())
这种情况是打开了csv文件没有及时关闭,只需要将其关闭即可。