JPA——ORM概述、JPA入门
目录
- 一、ORM概述
- 二、Hibernate与JPA的概述
- 三、JPA入门 (
重点)- 1、常用的注解
- 四、JPA中的主键生成策略
- 五、JPA、Hibernate、SpringDataJpa的关系
一、ORM概述
ORM(Object-Relational Mapping) 表示对象关系映射。在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中。只要有一套程序能够做到建立对象与数据库的关联,操作对象就可以直接操作数据库数据,就可以说这套程序实现了ORM对象关系映射
简单的说:ORM就是建立实体类和数据库表之间的关系,从而达到操作实体类就相当于操作数据库表的目的。
1.1、为什么使用ORM
跳转到目录

当实现一个应用程序时(不使用O/R Mapping),我们可能会写特别多数据访问层的代码,从数据库保存数据、修改数据、删除数据,而这些代码都是重复的。而使用ORM则会大大减少重复性代码。对象关系映射(Object Relational Mapping,简称ORM),主要实现程序对象到关系数据库数据的映射。
1.2、常见ORM框架
常见的ORM框架:Mybatis(ibatis)、Hibernate、Jpa(一种规范)
二、Hibernate与JPA的概述
跳转到目录
2.1、hibernate概述
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
2.2、JPA概述
JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。
JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
2.3、JPA与hibernate的关系
JPA规范本质上就是一种ORM规范,注意不是ORM框架——因为JPA并未提供ORM实现,它只是制订了一些规范,提供了一些编程的API接口,但具体实现则由服务厂商来提供实现。
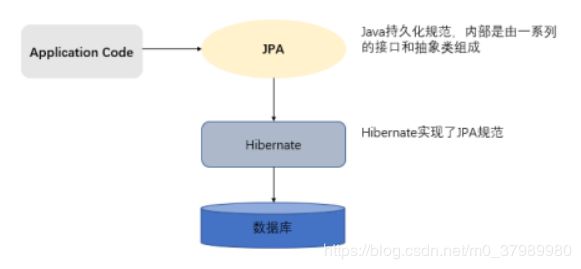
JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。JPA怎么取代Hibernate呢?JDBC规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
三、JPA入门
跳转到目录
1、搭建环境
- maven工程导入坐标
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.hibernate.version>5.0.7.Finalproject.hibernate.version>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-entitymanagerartifactId>
<version>${project.hibernate.version}version>
dependency>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-c3p0artifactId>
<version>${project.hibernate.version}version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.6version>
dependency>
dependencies>
2、创建客户的数据库表和客户的实体类
- 创建表
/*创建客户表*/
CREATE TABLE cst_customer (
cust_id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name varchar(32) NOT NULL COMMENT '客户名称(公司名称)',
cust_source varchar(32) DEFAULT NULL COMMENT '客户信息来源',
cust_industry varchar(32) DEFAULT NULL COMMENT '客户所属行业',
cust_level varchar(32) DEFAULT NULL COMMENT '客户级别',
cust_address varchar(128) DEFAULT NULL COMMENT '客户联系地址',
cust_phone varchar(64) DEFAULT NULL COMMENT '客户联系电话',
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- 创建实体类
public class Customer implements Serializable {
private Long custId; //客户的主键
private String custName;//客户名称
private String custSource;//客户来源
private String custLevel;//客户级别
private String custIndustry;//客户所属行业
private String custPhone;//客户的联系方式
private String custAddress;//客户地址
// 省略getter/setter方法
3、编写实体类和数据库表的映射配置[重点]
跳转到目录
常用的注解:
@Entity
作用:指定当前类是实体类。
@Table
作用:指定实体类和表之间的对应关系。
属性:
name:指定数据库表的名称
@Id
作用:指定当前字段是主键。
@GeneratedValue
作用:指定主键的生成方式。。
属性:
strategy :指定主键生成策略。
@Column
作用:指定实体类属性和数据库表之间的对应关系
属性:
name:指定数据库表的列名称。
unique:是否唯一
nullable:是否可以为空
inserttable:是否可以插入
updateable:是否可以更新
columnDefinition: 定义建表时创建此列的DDL
secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点]
/**
* 客户的实体类
* 配置映射关系
*
*
* 1.实体类和表的映射关系
* @Entity:声明实体类
* @Table : 配置实体类和表的映射关系
* name : 配置数据库表的名称
* 2.实体类中属性和表中字段的映射关系
*/
@Entity
@Table(name = "cst_customer")
public class Customer implements Serializable {
/**
* @Id:声明主键的配置
* @GeneratedValue:配置主键的生成策略
* strategy
* GenerationType.IDENTITY :自增,mysql
* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE : 序列,oracle
* * 底层数据库必须支持序列
* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
* @Column:配置属性和字段的映射关系
* name:数据库表中字段的名称
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId; //客户的主键
@Column(name = "cust_name")
private String custName;//客户名称
@Column(name="cust_source")
private String custSource;//客户来源
@Column(name="cust_level")
private String custLevel;//客户级别
@Column(name="cust_industry")
private String custIndustry;//客户所属行业
@Column(name="cust_phone")
private String custPhone;//客户的联系方式
@Column(name="cust_address")
private String custAddress;//客户地址
4、配置JPA的核心配置文件
- 在resources资源目录下创建
META-INF目录, 在该目录下创建persistence.xml文件
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0">
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProviderprovider>
<properties>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="1111"/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa?useUnicode=true&characterEncoding=UTF-8"/>
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="update" />
properties>
persistence-unit>
persistence>
5、实现保存操作
/**
* Description: 测试Jpa的test
*
* @author zygui
* @date 2020/5/5 08:53
*/
public class JpaTest {
/**
* 测试jpa的保存
* 案例:保存一个客户到数据库中
* Jpa的操作步骤
* 1.加载配置文件创建工厂(实体管理器工厂)对象
* 2.通过实体管理器工厂获取实体管理器
* 3.获取事务对象,开启事务
* 4.完成增删改查操作
* 5.提交事务(回滚事务)
* 6.释放资源
*/
@Test
public void testSave() {
//1. 加载配置文件创建工厂(实体管理器工厂)对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//2. 通过实体管理器工厂获取实体管理器
EntityManager em = factory.createEntityManager();
//3. 获取事务对象, 开启事务
EntityTransaction tx = em.getTransaction(); // 获取事务对象
tx.begin(); // 开启事务
//4. 完成增删改查操作: 保存一个客户到数据库中
Customer customer = new Customer();
customer.setCustName("gzy");
customer.setCustIndustry("learn");
// 保存到数据库的操作
em.persist(customer);
//5. 提交事务
tx.commit();
//6. 释放资源
em.close();
factory.close();
}
}
四、JPA中的主键生成策略
跳转到目录
使用方式: @GeneratedValue(strategy = GenerationType.XXX)
通过annotation(注解)来映射hibernate实体的,基于annotation的hibernate主键标识为@Id, 其生成规则由@GeneratedValue设定的.这里的@id和@GeneratedValue都是JPA的标准用法。
JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO。
- IDENTITY: 主键由数据库自动生成(主要是自动增长型)
- SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
- AUTO:主键由程序控制
- TABLE:使用一个特定的数据库表格来保存主键
五、五、JPA、Hibernate、SpringDataJpa的关系
跳转到目录
什么么是JPA?
全称Java Persistence API,可以通过注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中。
为我们提供了:
1)ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中;
如:@Entity、@Table、@Column、@Transient等注解。
2)JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。
如:entityManager.merge(T t);
3)JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
如:from Student s where s.name = ?
但是:
JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。
也就是说:
JPA是一套ORM规范,Hibernate实现了JPA规范!如图:
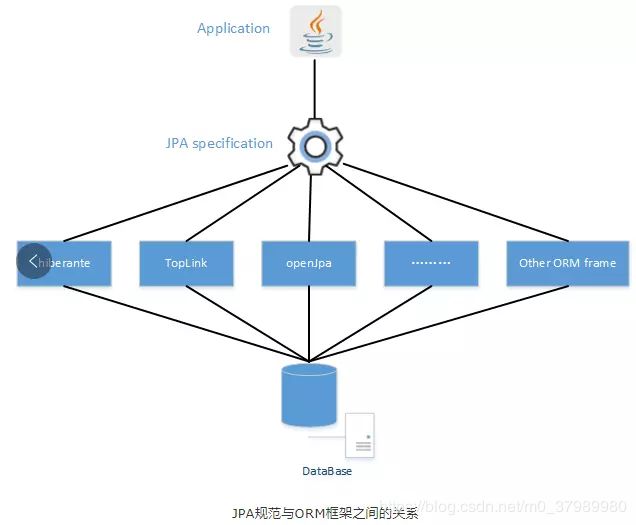
什么是spring data jpa?
spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现。如图:
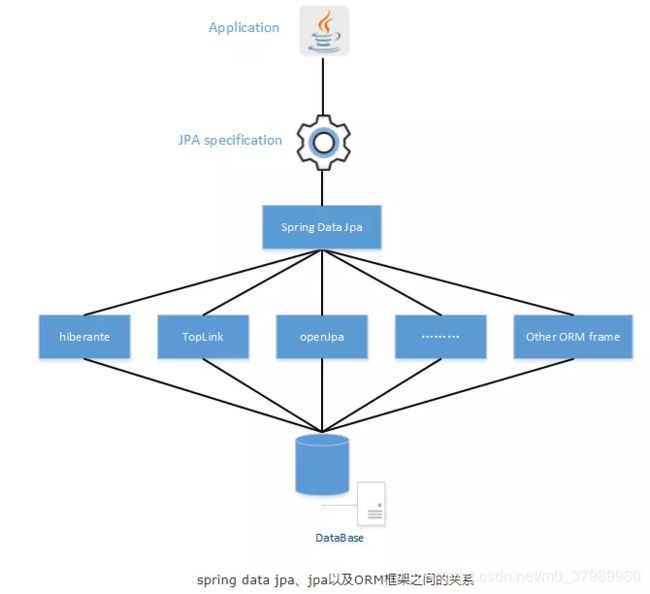
接口约定命名规则:
